1. Introduction
- BERT가 상당히 undertrained 되어있음
- BERT를 더 잘 학습시키기 위한 recipe를 제안
- Recipe
- training the model longer, with bigger batches, over more data
- 모델을 더 많은 데이터로, 더 큰 batch로 오래 학습
- removing the next sentence prediction objective
- NSP 학습 제거
- training on longer sequences
- 더 긴 문장들에 대해 학습
- dynamically changing the masking pattern applied to the training data
- Mask를 dynamic하게 바꿔줌
- training the model longer, with bigger batches, over more data
2. Background
- BERT에 대해 간단히 설명
3. Experimental Setup
3.1 Implementation
- 대체로 기존 BERT의 optimization hyperparameters을 그대로 사용
- peak learning rate & warmup steps는 별도로 조정
- Adam optimizer의 epsilon값이 학습에 매우 민감한 것을 발견하고 이 값을 조정했을때 성능 및 학습 안정성이 향상
- 대용량 배치에서 를 0.98로 설정했을 때 안정성이 향상됨
- 사전 학습
- Max token length = 512
- 첫 90%의 업데이트 동안 시퀀스 길이를 줄여서 학습하지 않음.
- 오직 풀-시퀀스(full-length sequences)만 사용하여 학습.
- Learning Rate
-
보통 학습 초기에는 낮은 학습률을 사용하고, 이를 점진적으로 증가시킨 뒤(Warmup) 다시 감소하는 방식(Cosine Decay)를 사용
-
왜 중요한가?
- 초기 학습에서 너무 큰 학습률을 사용하면 모델이 불안정해지고 수렴 속도가 느려질 수 있음
- 특히, Adam Optimizer과 같은 Adaptive Optimizer에서는 학습 초기에 과도한 업데이트를 방지하는 것이 중요
- Warmup 동안 학습률을 점진적으로 증가시켜서 모델이 안정적으로 학습되도록 함^ Learning Rate | . -> Peak Learning Rate | . . | . . | . . |--------|-------------------------> Warmup Decay
-
3.2 Data
- 5가지의 English-language corpora를 수집 (총 160GB)
- BOOKCORPUS + English Wikipedia (16GB)
- BERT의 원래 사전 학습 데이터셋
- BOOKCORPUS(Zhu et al., 2015)과 영어 위키백과(English Wikipedia) 데이터 포함.
- CC-NEWS (76GB)
- CommonCrawl News 데이터셋(Nagel, 2016)에서 영어 뉴스 기사 수집
- 2016년 9월 ~ 2019년 2월 사이의 6,300만 개 뉴스 기사 포함
- REALNEWS(Zellers et al., 2019)와 유사한 뉴스 데이터셋
- OPENWEBTEXT (38GB)
- Radford et al. (2019)의 WebText를 오픈소스로 재현한 데이터셋
- Reddit에서 최소 3개 이상의 업보트(upvote)를 받은 URL의 웹 콘텐츠를 크롤링하여 추출
- STORIES (31GB)
- CommonCrawl 데이터에서 "이야기(story-like)" 스타일의 텍스트를 필터링한 데이터셋
- Winograd Schema와 유사한 서술형 텍스트 포함 (Trinh & Le, 2018)
- BOOKCORPUS + English Wikipedia (16GB)
3.3 Evaluation
- 3개의 benchmarks에 대해 평가
| 데이터셋 | 설명 | 특징 |
|---|---|---|
| GLUE | NLU 평가 벤치마크 (9개 데이터셋) | 문장 분류 & 문장 관계 이해 |
| SQuAD | 질문-답변(QA) | 문맥에서 정답 추출 |
| RACE | Reading Comprehension | 긴 문맥 + 고난이도 질문 (4지선다형 문제) |
- GLUE (General Langauge Understanding Evalutation)
- 9개의 데이터셋으로 구성된 NLU 평가 벤치마크
- single-sentence classification (e.g., 문법, 감정분석), sentence-pair classification (e.g., 문장쌍 유사도, 관계 판단) 으로 구성
- SQuAD (Standford Question Answering Dataset)
- Question, Context가 주어지면 문맥에서 정답을 추출하는 Task
- RACE (ReAding Comprehension from Examinations)
- 대규모 독해 데이터셋으로 각 질문에 대해 4가지 선택지가 주어짐
4. Training Procedure Analysis
- BERT Architecture은 고정시키고 여러 option을 테스트
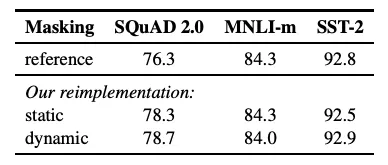
4.1 Static vs. Dynamic Masking
- Static Masking (Original BERT)
- 한개의 동일한 Masked data로 학습
- 각 training epoch에서 동일한 masked data를 학습
- Dynamic Masking
- 10개의 다른 Masked data를 생성
- 40 epochs 일때, 4번만 동일한 masked data를 학습
- Results
- Static Masking: 기존 BERT 모델과 유사한 성능을 보임.
- Dynamic Masking: 정적 마스킹과 유사하거나 다소 향상된 성능을 보임.
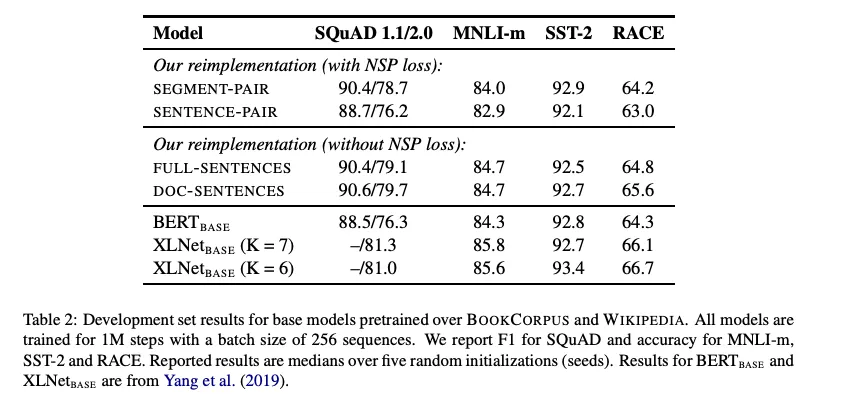
4.2 Model Input Format and Next Sentence Prediction
- 4가지 training formats을 비교
| Input Format | Description | NSP |
|---|---|---|
| SEGMENT-PAIR+NSP | 기존 BERT 형식 | |
| Segments의 Pair을 Input으로 사용 | O | |
| SENTENCE-PAIR+NSP | Sentences의 Pair을 Input으로 사용 | |
| 배치 크기 증가 | O | |
| FULL-SENTENCES | 512 token까지 Sentences를 채움 | |
| 다수의 Documents 사용 | X | |
| DOC-SENTENCES | FULL-SENTENCES와 유사하지만 문장 경계를 넘지 않음 | |
| 배치 크기 증가 | X |
- SEGMENT-PAIR+NSP (original BERT)
- segments의 pair을 input으로 사용
- NSP O
- SENTENCE-PAIR+NSP
- sentences의 pair을 input으로 사용
- sentences의 pair은 contiguous 문장 혹은 다른 문서에서 샘플링된 문장임
- 512 tokens보다 짧기 때문에 token 개수를 비슷하게 맞춰주기 위해 batch size를 늘림
- NSP O
- sentences의 pair을 input으로 사용
- FULL-SENTENCES
- 최대 token까지 거의 꽉 채워서 sentences를 input으로 사용
- 한개 document로 다 채우면, 다음 document로 나머지 token 채우고 separator 추가
- NSP X
- 최대 token까지 거의 꽉 채워서 sentences를 input으로 사용
- DOC-SENTENCES
- FULL-SENTENCES랑 비슷하지만 각 document를 개별적으로 input으로 사용
- 즉, 입력은 단일 문서 내에서만 구성됨
- 512 tokens 보다 짧기 때문에 token 개수를 비슷하게 맞춰주기 위해 batch size를 늘림
- NSP X
- FULL-SENTENCES랑 비슷하지만 각 document를 개별적으로 input으로 사용
- Results
- NSP를 없애도 성능이 유지되거나 오히려 소폭 좋아짐
- FULL-SENTENCES 보다 DOC-SENTENCES가 성능이 좋음
- batch sizes에 따라 성능이 달라져서 이후 실험에는 FULL-SENTENCES를 사용
- NSP를 없애도 성능이 유지되거나 오히려 소폭 좋아짐
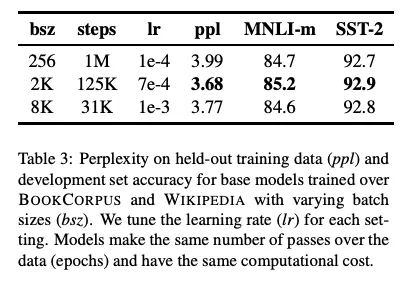
4.3 Training with large batches
| 실험 | Batch size | Steps |
|---|---|---|
| Original BERT | 256 Sequences | 1M |
| Experiment1 | 2K Sequences | 125K |
| Experiment2 | 8K Sequences | 31K |
- Results
- Batch size = 2K 일때, 가장 성능이 좋았음
- 이후 실험에서는 병렬화를 고려해서 8K로 실험
- Perplexity(PPL)란?
-
Perplexity는 언어 모델의 성능을 측정하는 대표적인 평가 지표
-
확률 모델의 예측 성능을 측정
-
값이 낮을 수록 예측력이 높음
-
1이면 모든 단어 시퀀스를 완벽하게 예측하는 것을 의미
-
여기서 는 언어 모델의 Entropy
-
N: 문장 내 token 개수
-
: 이전 단어들을 기반으로 단어 를 예측할 확률
-
: 평균적인 예측의 불확실성 (Entropy)
-
4.4 Text Encoding
- BERT는 unicode-level(character-level)에서 subword를 생성하는 BPE를 사용
- “나는 학생입니다” → “나” “는” “학” “생” “입” “니” “다”
- 문제점
- 약 10K~100K개의 많은 subword가 존재
- OOV(Out-of-Vocabulary) 문제 해결이 어려움. 즉, “unknown” token이 존재
- RoBERTa는 byte-level에서 BPE를 수행하는 BBPE를 사용
- “나는 학생입니다” → b'\xeb\x82\x98\xeb\x8a\x94 \xed\x95\x99\xec\x83\x9d\xec\x9e\x85\xeb\x8b\x88\xeb\x8b\xa4’
- subword 개수 50K로 감소
- 모든 단어에 대해 인코딩 가능
- 대신 parameter 크기 증가
- BERTBASE: 약 15M(1,500만) 개의 추가 파라미터(parameter) 증가
- BERTLARGE: 약 20M(2,000만) 개의 추가 파라미터 증가
- GPT-2에서 해당 방식 사용
- Subword Tokenizer *참고: https://wikidocs.net/22592
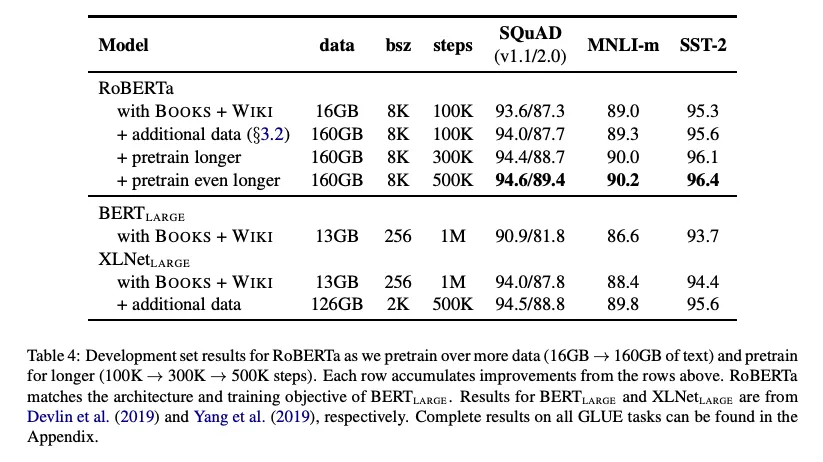
5. RoBERTa
- 그리고 해당 논문은 2가지의 중요성을 더 강조
- pre-training에 다양하고 많은 데이터가 사용되어야 함
- 데이터 학습 횟수
- Results
- 동일한 데이터로 학습했을 때에도 RoBERTa의 성능이 BERT 보다 좋음
- 더 다양하고 많은 데이터로 학습하면 성능 상승
- pretraining steps를 늘리면 더 성능 상승 (overfitting이 나타나지 않았다고 함)
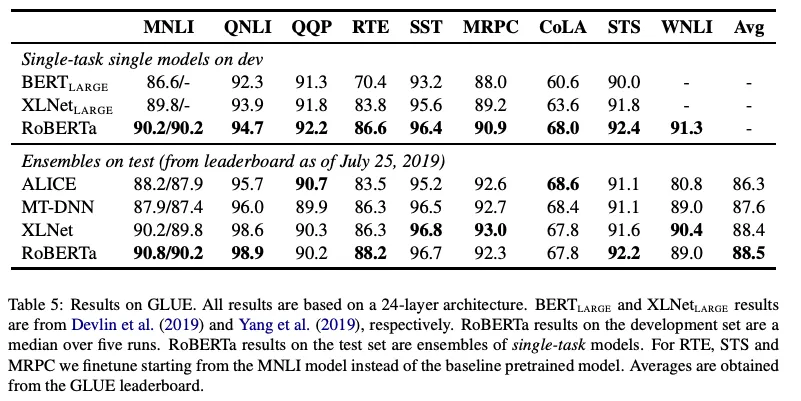
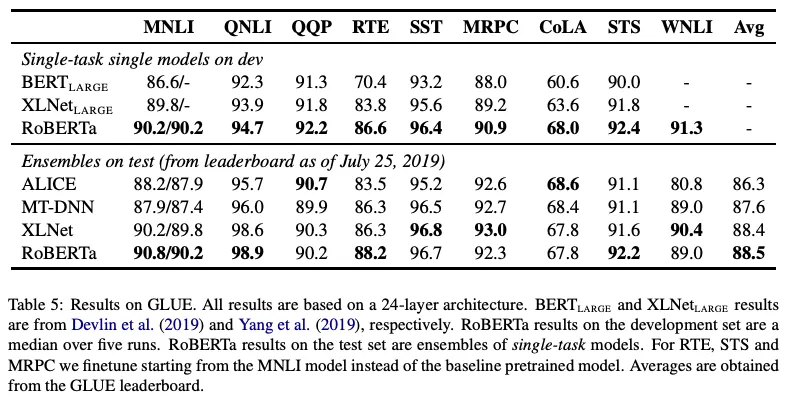
5.1 GLUE Results
- 각 task별로 fine-tuning (single-task fine-tuning)
- Results
- 모든 dev set에서 state-of-the-art 성능 달성
- 9개 중 4개 태스크에서 SOTA 기록 및 전체 최고 평균 점수 달성.
- 심지어 multi-task finetuning 시키지 않았는데도 최고 성능
5.2 SQuAD Results
- BERT, XLNET 보다 더 단순하게 훈련
- SQuAD training data만 사용
- 모든 layer의 learning rate를 공통으로 사용
- Results
- RoBERTa는 추가 train data를 사용하지 않았음에도 가장 좋은 성능을 보임
5.3 RACE Results
- candidate answer를 question, passage과 concat해서 입력하고, [CLS]를 fully-connected layer로 보내서 맞는지 예측
- Results
- state-of-the-art results를 보임
Conclusion
- Instruction의 4가지 recipe로 성능을 높일 수 있었으며, 이는 design decisions의 중요성을 보여줌

Data Scientist