이 글은 awskrug라고 aws소모임 참석해서 들은 강연글입니다.
오늘 강연 내용
0.SQL 쿼리 생성 엔지니어 슬랙봇 만들기 (이 글에서는 다루지 않음)
1.fine tuning이 왜 필요한지, fine tuning에서 어떤 경우에 임베딩 모델을 fine tuning 해야할지 ,
2 LLM모델을 fine tuning 해야할지
디테일한 내용은 다른 영상 , 인터넷, 허깅페이스, 미디엄 등등 참조!
영상 링크는 글 아래에 있음…ㅎㅎ
발표자: 김대근님 -AIML SA, AWS
2주전에 올라간 영상에서 딥한 얘기 참조하자(아래링크)
https://kr-resources.awscloud.com/kr-on-demand
최근에 책 번역하심
머신러닝 시스템 설계
머신러닝 엔지니어링 인 액션 책 번역하심
커리어
2001년에 웹개발자로 시작함, 지금은 다 까먹음
2008년부터 머신러닝과 비전에 관심을 갖고 공부를 시작함
전직장에서 데이터과학자로 반강제로 시작
생성형 ai에서 할루시네이션 제거를 위한 시도들
프롬프트엔지니어링 → 부족하면 RAG를 함
RAG의 과정
우리는 많은 데이터를 이용하는데 이를 벡터 DB에 입력하고 주어진 쿼리를 임베딩 변환하고 결과를다시 벡터 db에유사도를 찾는것 이를 토대로 문서의 context를 보완 한다
LLM에서 그 context를 기반으로 답변을 잘해준다
그럼에도 불구하고 여전히 할루시네이션이 해결이안됨 ←이는 생성형 ai의 어쩔 수 없는 특성
Embedding
한국어 토크나이저의 문제점: 컨텍스트 길이제한
대부분의 한글은 토큰화가 바로 안되고 유니코드로 되서 길이가 증가함(약 3배)
한국어 작업을 할 때 latency(메모리가 다음 명령을 처리할 때 까지 걸리는시간)를 고려해줘야한다
짧은 문맥(context)으로 인해 생성되는 답변은 본래 짧을 수밖에 없다. 따라서 짧은 지연시간(latency)으로 처리가 가능하다. 반면, 답변이 길어지는 경우 (여기서 '길어진다'는 문장 자체가 길어지는 것을 의미하는 것이 아니라, 한국어에서의 토큰화 문제로 인해 처리해야 할 데이터 양이 증가하는 것을 의미한다), 처리에 필요한 시간이 세 배로 늘어나면서 성능이 저하될 수 있다.
도메인 특화 지식 대응의 어려움(ex. 사내정보, 의학정보, 법률정보…)
현재까지는 모델을 학습시킬 때 정말 방대한 지식까지 모은다고 해도 도메인까지 모으진 않는다
따라서 도메인 특화 정보는 대답을 제대로 못하는 이슈가 있다.
도메인 특화 데이터가 안들어가면 아무리 chat gpt를 쓰더라도 원하는 정확도가 안나온다. 이때 정확도가 40%정도에 머무른다. 이를 메꾸기 위해 rag, fine-tuning등이 필요하다
우리가 SOTA 같은 것에서 높은 정확도가 나오는걸 보고 “다른 도메인에서도 이 정도 정확도가 나오겠네” 라고 생각하는데 절대 그 수치가 안나온다.
⇒도메인 특화 데이터를 넣어줘야한다.(우리 프로젝트도 그런 이유가 아닐까?)
토큰 길이에 관하여
토큰 길이가 많으면 좋냐? —>아니다
토큰의 길이가 길다고 해서 그 토큰에 있는 모든 문맥을 같은 정확도로 파악하지 않는다.
연구결과로 컨텍스트길이가 19k 정도에서는 어느 정도 정확도를 보장하는데 20k부터는 급격히 정확도가 떨어짐. 20k 이상은 상징적인 수치일 뿐이다(현재까지는)
따라서 토큰길이를 무조건 늘리는 것 보다는 가장 높은 정확도가 나오는 토큰의 스레스를 찾아서 chunking을 하는게 더 중요함
fine tuning은 언제필요한가?
fine tuning을 항상 쓰는것이 아니다.
처음부터 fine-tuning하는 것은 반대한다
단계에 따르는 것을 추천한다
- 프롬프트엔지니어링 먼저하자. 그래도 부족하면
- RAG하자. 그래도 부족하면
- fine-tuning까지 검토한다.
이것들은 각각 쓰는 것이 아니고 결국 다 결합 해야한다. 따라서 정말 fine-tuing이 필요한지부터 검토해야한다.
이를 위해서 평가가 필요하다. 평가를 할때 LM에 대한 평가수치가 정형화 된 것은 없지만 아래 지표가 주로쓰인다.
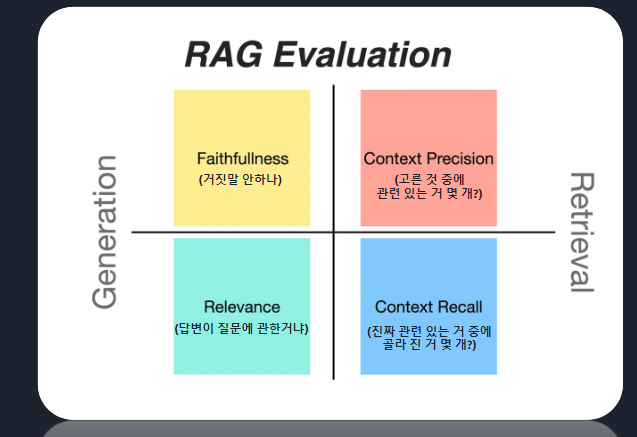
fine tuning을 고려할 때
1.임베딩 모델에서 context를 잘 못가져왔을 때: 고민해봐야 한다. ← 도메인 특화
2.context를 잘 가져왔는데 문장을 잘 생성 못했을때: 이건 LM의 역할, 임베딩 문제가 아님 <-LM을 fine tuning 해야한다.
3.두가지가 다 안될 때: 두개를 다 손봐야되고 특정 한 개가 안되면 한 부분에 치중하면 된다.
임베딩 모델에 대하여
임베딩 모델이 무거울 필요는 없다
임베딩 모델이라고 해서 거대모델이나 무거운 모델을 쓰려는 분들있는데 이런 모델이 무조건 SOTA를 찍지 않는다. 지금 SOTA를 찍는 모델의 base가 transformer의 encoder모델인데 이것만 쓰더라도 왠만큼 성능이 나온다. bert가 512의 컨텍스트 길이로 짧은데 어떻게 좋은 성능을 내냐 라는 말을 하곤한다. 그래서 chunking이 중요하다. 문장길이가 길더라도, LLM에서 컨텍스트 지원을 잘해도 chunking을 제대로 안하면 문제가 발생할 수 있다.
fine tuning을 할때 아래와 같은 많은 오해가 있었다.
- 수학 역량이 필요하다
- 최신 모델링 기법이 중요하다
- GPU가 수십장 필요하다
- 데이터가 무조건 많으면 좋다
- 코딩이 어렵다
⇒ 다 아니다(강연자님 입장…ㅠㅠ)
과거에는 수식을 진짜 이해해야 했다. 기본적인 알고리즘 같은 경우도 수식을 다 이해하고 구현하고 간단한 메소드로 구현했지만 지금은 왠만한 모델이 오픈소스로 되어있거나 파이토치로 되어있다.
또 요즘 논문은 수학수식이 있는게 아니라 선실험 혹은 코드 공개가 된다.
application 측면
application 연구보다 개발이 더 중요하다고 생각한다.
연구하는 분들도 능력이 있는데 발전 속도가 너무빨라서 간극이 있다.
따라서 취직하는데 application 개발을 더 잘하는게 더 중요하다
그래서 자기는 뭐먹고 살까에 대한 고민을 지금도 한다 ←…?
embedding model training
contrastive learning - (자세한건 찾아보자)
bert는 임베딩을 해주는데 왜 다른모델을 써야하는가?
RAG에서 주어진 쿼리에서 가장 비슷한 문서를 찾을 때 코사인 유사도를 주로 사용한다. 근데 bert모델은 코사인 유사도에 최선이 된게 아니다. 그래서 코사인 유사도를 잘 계산할 수 있게 bert 계열이나 roberta 모델을 fine-tuning 해준다. (항상 그런건 아니긴하다.) 그때 정말 많은 데이터가 필요하진 않다. 2018년 bert가 처음 나왔을때는 bert가 무거운 모델이었는데 지금은 아니다
이때 데이터는 어떻게 가공해야하나
contrastive learning 에서 사용되는 비지도 학습기법이 있다. 비지도라서 빡쌔게 가공할 필요가 없다. 물론 데이터를 잘 가공하면 가공할 수록 좋다. 근데 우리가 처음부터 SOTA를 보는게 아니라 가능성을 보는것이기 때문에 괜찮다.
baseline을 꼭봐라. 이걸 기준으로 더 높이기 위해 노력해라
SimCSE - 논문 한번 찾아봐라(유명함)
여기에 superviese SimCSE이랑 Unsuperviese SimCSE 두가지가 있다.
이때 Unsuperviese SimCSE가 중요하다.
성능은 당연히 지도학습이 좋은데 지도학습 데이터를 만들기 번거롭다
동일한 문장을 복사한다. (positive pair로 사용, dropout으로 augmentation효과)이게 딥러닝 네트워크를 거치면서 약간씩 변조된다.
앞단에서 부더 augmentation하면 되지 않냐?
NLP 중에서 한국어가 augmentation이 어렵다. data를 naming하는게 힘들어 실제로 만건 정도를 노가다해서 만들고 10만건을 augmentation해서 만들었는데 다 실패했다.
특히 한국어가 augmentation이 생각보다 힘들다.
영어는 나름 괜찮고 그것들에 대한 논문도 있다 . 한국어가 근본적으로 영어와 다른 언어적인 특성이 있다. 흔히 교착어 같은 특성들로 인해 발생한다.(ex) 아버지가 방에 들어가신다.) 그래서 어렵다.
우선 동일한 문장을 사용한다는건 네트워크 안에서 조금씩만 바꿔준다는 뜻이니까 이건 좀더 강건하게 soft augmentation을 할 수 있다. hard soft차이는 hard는 명시적으로 우리가 문장을 바꿔주는건 soft는 적당히바꿔주는 것이다.
supervised simcse는 명시적으로 레이블을 만들어주는것 - 좋긴한데 걍 노가다이다.
SimeCSE Dataset구축방법(unsupervised)
생각보다 간단하다.
→위키피디아 말뭉치 크롤링해서 문장 단위로 자르자.
이걸 한국어를 문장단위로 자르는 코드가 생각보다 많다.
Tokenizer기반으로 하는 오픈소스도 많으니 찾아보길 바란다.
왠만하면 문장이 잘 쪼개지니깐 이걸 잘 쪼개서 특정 도메인에 적합한 여러분만의 말뭉치를 준비하여 fine tuning 해보길 바란다.
GPU는 많아야 4장 적으면 1장이면된다. Bert가 그렇게 무겁지 않기 때문이다.
supervised가 당연히 더 좋겠지만 unsupervised도 괜찮게 성능이 나온다.
발표 자료 기준으로는 85, 80정도의 차이였다. 따라서 데이터의 레이블 없이도 충분한 성능이 나온다고 볼 수 잇고 supervised에 사용되는 많은 비용을 줄일 수 도 있다.
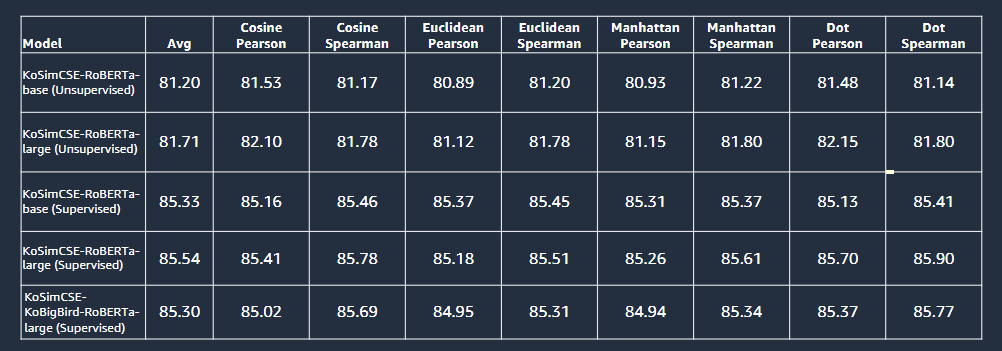
SimCSE Training는 훌륭한 코드이지만 구현이 복잡하다.
KoSimCSE(공식 코드보다 간결하지만,unsuptervised 미구현)
KoSimCSE-SageMaker (이분이 변경해서 공개함)
로직위주로 간결하게 초심자도 쉽게 실험가능
/모두구현, 분산 훈련(데이터 병렬화)로직 추가 ,아마존에서 운영하는거 아니라 돈내는거아니니 한번 써봐라
허깅페이스의 베이스라인을 써도되고 나만의 모델을 갖고 싶으면 도메인 데이터로 fine tunin하면된다.
여기까지 임베딩 모델 만들기
LLM Fine-tuning
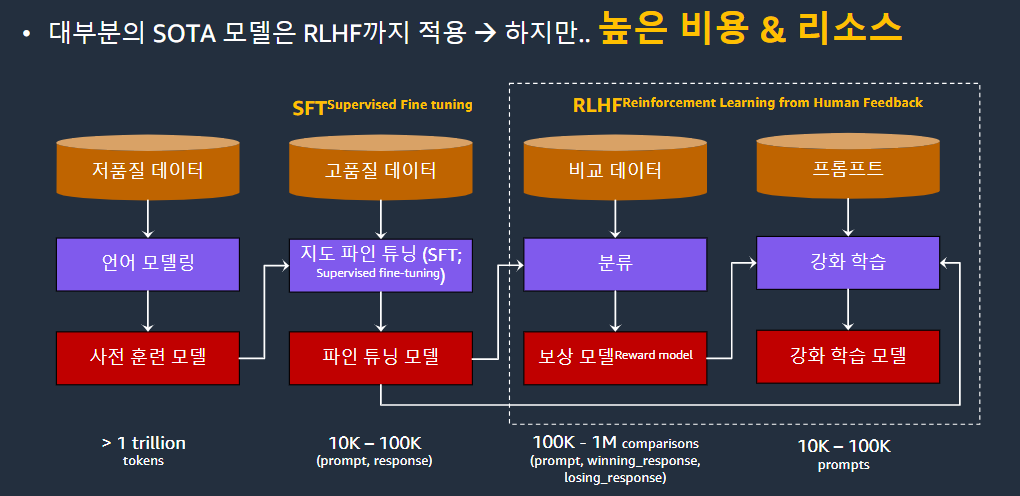
가장왼쪽은 우리의 고려사항이 아니다. open AI 같은데서나 할 수 있다.
또 저품질 데이터라고 적혀있는데 지금은 그렇지 않다.
고품질의 데이터가 중요하다는 것이 입증되면서 이 단계에서도 데이터 가공을 한다
따라서 너무 많은 리소스가 들어가서 처음부터 이런 모델을 빌드하는건 권장하지 않음
오픈소스로 공개된 베이스라인들을 사용하여 RAG를 적용하면 특정 도메인에 한해서는 GPT4의 성능까지도 낼 수 있다
SFT - 우리가 주목해야할것
프롬프트로 지침을 잘 줘야한다.
또 데이터가 많으면 좋겠지만 단순히 많은 것 보다 고품질 데이터만 있으면 천 건으로도 충분하다.
오르카란 논문이 있다. -MS꺼임
여기서 중요한게 LLM한테 생각할 시간을 주는 것이다. → 좀 더 구체적인 지침과 Q&A를 주면 답변을 더 잘한다.
모델링 기법은 코드에 있는것은 공개 되어있는 것이고 중요한건 고품질 데이터를 가공하는것임
이 방법론들은 현재까지는 심플하고 공개가 되어 있다.
근데 혼자할 수 있는건 아니고 현업에서 데이터 잘 다뤄본 분들이랑 얘기를 많이 해야한다.
강화학습이 왜 필요한가?
완전히 없앨 수는 없지만 강화학습이 할루시네이션을 어느정도 완화해준다. 올해 상반기에 개인들이 개발한 모델들은 가운데 모델인데 4분기인 지금은 다른걸 쓴다.
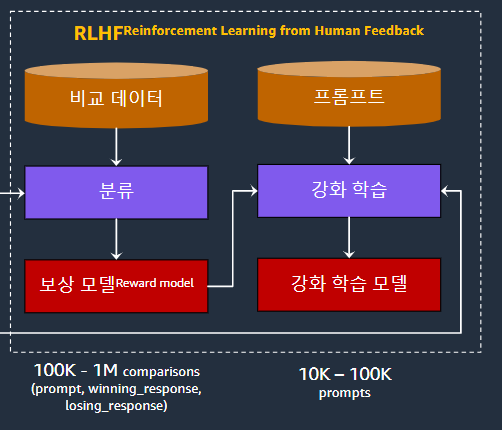
강화학습은 좀 복잡하고 많은 리소스가 들어간다. 이 사진만 보상모델을 만드는 과정을 거치고 이걸 토대로 강화학습을 거치고 보상모델로 강화학습을 함으로써 최종적인 강화학습 모델을 만든다. 이처럼 복잡하여 지금은 좀 단순화시켰다. 지금은 이처럼 단순화 해서 그 성능에 준하게 만든 모델을 사용한다. 그래서 상당히 많은 연구자나 스타트업들은 그 모델을 기반으로 fine-tuning을 한다. (그 모델은 바로 뒤의 모델. 구어체입니다...)
최근 트랜드: DPO(Direct Preference Optimization)의 대두
SFT 튜닝 모델에서 생성한 문장들에 랭크 부여한다.
생긴이유: 강화학습은 생보다 많은 시간과 비용 노력이 들어감 근데 그걸 DPO가 좀 줄여준다.
방법
기본적으로 통용된 모델을 가지고 문장을 만든다. SOTA급 LLM이나 전문가들이 평가를 해서 결과가 좋냐 나쁘냐를 레이블을 매긴다. 상대적으로 정확하면 1로 매긴다. 이렇게 할루시네이션을 억제한다.
이 또한 세상이 좋아져서 허깅페이스에서 짧은 코드로 사용할 수 있다.
물론 빡쌔게 쓰려면 밑바닥부터 해야되긴한다.
이게 LLM에서는 사용불가능하다. (메모리 부족의 이유로…, 7B에서는 됨)
또 레퍼런스 모델 사본이 필요하므로 SFT보다 더 많은 GPU메모리를 요구한다.
???: 방법론과 코드는 알겠는데 부족한 GPU메모리는 A100 80GB은 선택받은자만 쓸 수 있지않나…?

우리학교 감동실화: 실제로 학교 서버 GPU RTX4090은 메모리가 24GB이다. Llama2 -7b을 바로 못돌린다…
아마존 직원은 GPU 리소스가 빵빵하게 지원되지 않냐?
아니다… 직원들에게 나오는 리소스가 따로없다. 나도 써본게 24GB가 최대이다.gpu메모리가 없어서 슬프다….
GPU 메모리

16GB GPU메모리는 7B모델 파라미터 로드도 매우어렵다
16bit를 사용하면 계산정확도가 줄어든다. 그래서 32bit를 써야한다.
이러한 문제로 fine-tuning할때 LoRA를 사용한다. (찾아보기)
r: low-rank 차원(r이 작을수록 모델 훈련이 더 빠르고 메모리를 절감하지만 정확도가 저하된다)
이건 대부분 파라미터를 고정시켜놓고 r=4,d=512일 경우 종래대비 1.56%의 파라미터만 사용한다.
만약 LoRA를 안쓰면 파라미터와 같은 메모리를 쓰는데 사용하면 메모리가 줄어든다.
이것보다 더 줄이기 위해 가장 많이 쓰는게 QLoRa이다.(찾아보기)
정확도는 더 줄어들 수 있다.
특징
4-bit Normal Float 양자화: LoRA가중치를 -1~1범위의 정규분포로 비대칭 양자화
그냥 비트를 줄이면 정확도가 확떨어지는데 4-bit Normal Float 양자화를 통해 정규분포 내의 연산은 촘촘히 하고 그 외의 범위는 덜 촘촘하게 하는것이다.
이중양자화: 블록 별 양자화 상수들을 한번 더 양자화 → 파라미터 당 0.37비트씩 절약한다.
Paging optimizer: Optimizer state오프로딩
중간에 임시메모리가 들어가는데 이 메모리는 CPU나 SSD에서 떼와서 거기서 관리하게 하는것이다.
이렇게 함으로써 메모리를 줄일수 있다. 근데 데이터를 주고받는 속도가 느리기 때문에 학습은 느려진다.
Flash Attention
transformer의 attention에는 굉장히 많은 연산이 들어간다. 그걸 한번에 처리하는게 아니라 작은 블록으로 쪼개서 하나의 gpu 메모리로 처리하지 않고 sram이라는 작은 규모의 ram에서 빠르게 처리하는 것
설명
어텐션의 Memorybound를 완화하기 위한 기법
Q,K,V를 HBM에서 SRAM으로 로드하고 어텐션 메커니즘의 핵심연산을 수행
pytorch같은 고레벨 툴킷이 아닌 cuda구현으로 v100같은 구 아키텍쳐는 미지원
GPU메모리 절감예시: LLM 7B

ZeRo 스스로 공부해보기
Deep speed 스스로 공부해보자
아마존 서비스를 이용하면 장점이라고 한다
fine-tuning 데이터가 100만건이라면?
GPU1장으로 훈련
single node로 훈련
EC2/EKS multi-node를 설정해서 훈련
sagemaker로 쉽고 빠르게 훈련
LLM모델 훈련환경-amazon sagemaker
대표적인 오해:훈련 코드를 변경하는 것이 아니다
Leaderboard 개인적인 경험
이분은 기술지원 직무임 연구자나 개발자가아님
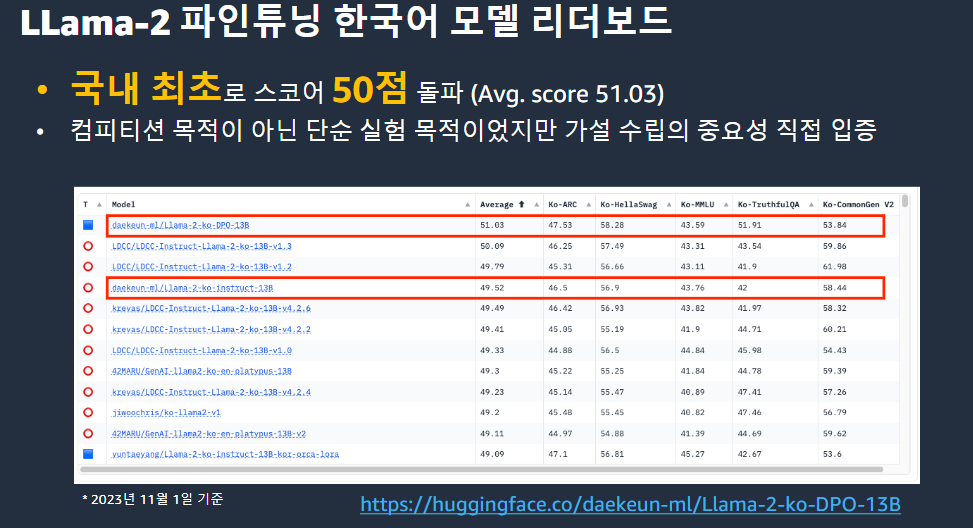
LLam-2 파인튜닝 한국어 모델 리더보드
국내최초로 스코어 50점 돌파
컴피티션 목적이 아닌 단순 실험 목적이었지만 가설수립의 중요성 직접 입증
코드는 중요하지않고 노하우가 중요하다
별거 아닌데 일부 기업에서 특별한척 한다. 좀만 찾아보면 금방 할 수 있다.
아래에 대한 신뢰성을 위해 만든 페이지이다.
꿀팁1. 데이터품질 >>데이터볼륨
LiMA논문참조
Llama2에 적합한 프롬프트 실험 Orca논문참조

프롬프트에 순수 한국말보다 영어를 섞는게 더 좋다.
llama에 한국어는 거의 안들어갔다.
완전히 한국어 기반 모델은 추천안한다, 영어모델이 훨씬 낫다.
그래도 능력자 분들이 만든 한국어로 fine tuning한 llama모델을 가지고 finetuning을하면 잘나온다.
꿀팁 2. Myth타파
Adam vs SGD →묻지마 Adam X
Epoch이 많을수록 좋다 X(한번으로도 충분하다. 최대 4번정도만하자-open ai 피셜)
LoRa rank가 높을수록좋다?→X
parameter 수가 무조건 많으면 좋다 →X
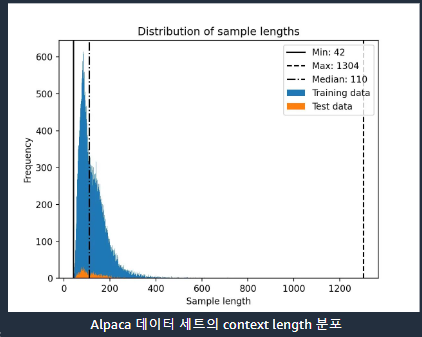
Context길이를 무조건 모델의 최대치로 고정해야한다? → X
- context 길이를 최대로 하면 메모리도 부족하고 학습속도도 느려진다. LLM 모델을 fine tuning 할 때 꼭봐야하는게 context length 분포이다. 아래 사진처럼 context length가 아래처럼 적으면 500으로 놔도된다. 굳이 최대로 할필요없다. 메모리 낭비일 뿐이다.
꿀팁3 .SFT
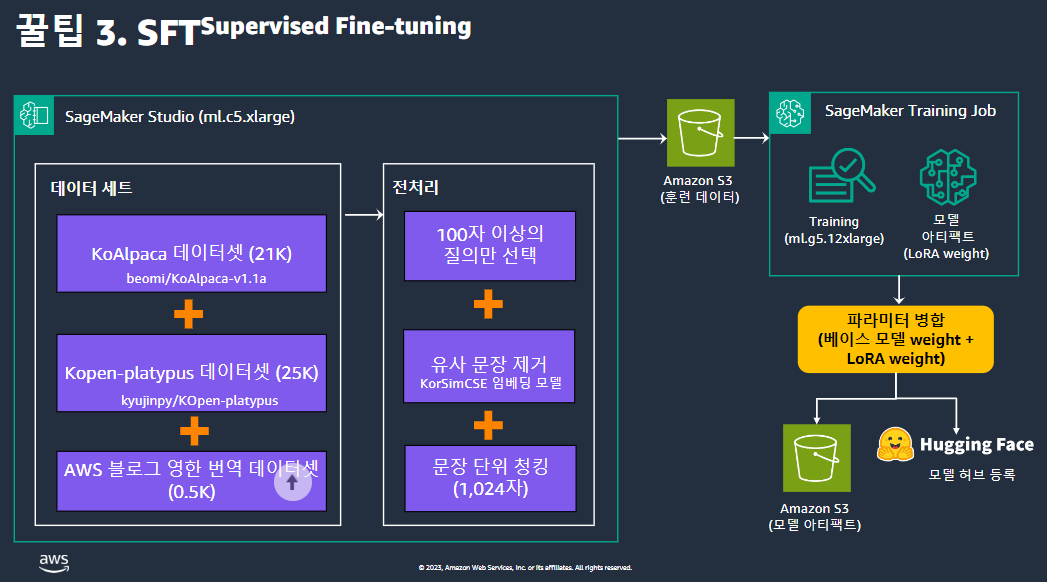
데이터셋을 보면 오픈소스 데이터를 쓴건데 부족해 보여서 AWS 블로그 영한 번역 데이터셋 사용했다.
이분이 AWS 영어 블로그를 직접 한국어로 번역한게 있다. 나름 정성들여 번역한 것이라 양질의 데이터라고 판단하여 사용했다. 실제로 효과적이었다.
다시한번 강조하지만 양질의 데이터가 중요하다
데이터전처리
전처리때 너무길거나 너무짧은것 지우자, 특히 너무 짧은 것
너무 의미적으로 유사한 문장 제거하자
chunking을 잘하자
KorSimCSE임베딩모델
꿀팁4 DPO
SOTA급의 LLM모델을 이용하여 만든 프롬프트로 모방학습하자
이분은 AWS직원이니 Amazon Bedrock Claude-2에서 생성한 문장을 chosen으로채택 →더 좋았다.
꿀팁5 24GB GPU메모리 짜내기

꿀팁6.Tokenizers for Korean Language

사람들이 많이 간과하는 부분이다
사람들이 SOTA급 모델 찍는거만 생각하는데 여기있는 사람들은 실제 업무에서 latency를 봐야한다. 근데 아무리 성능이 좋아도 한국어가 나오는 순간에 context length가 영어보다 줄어들고 latency도 확 늘어난다. 이때 custom하게 한국어 토크나이저를 학습시켜야한다. 이것도 쉽다. 데이터를 모으고 허깅페이스에 오픈소스가 있다. 이걸 그냥 돌리면된다.
Train%Merge Tokenizers
15GB 분량 데이터는 CPU써도 (위키피디아,채팅 데이터 샘플링)훈련시 약 20분 소요된다.
영어기준으로 토큰 수가 Llama모델이 많으면 3만 2천개인데 영어에 맞춰서 3만개정도를 쓰려고 하는데 토큰의 갯수가 많으면 임베딩메트릭스 계산을 할때 속도가 엄청 느려진다.
따라서 한국어 토크나이저를 무조건 많이 추가하는건 좋지않다.
Initializing new word embeddings
토크나이저 확장 후 임베딩 행렬 수정
기존 토크나이저 확장 전의 임베딩 행렬의 통계치를 활용하여 확장 전과 확장 후 토큰 분포 간의 KL divergence 발산을 제한하는 것을 권장
결론은 한국어 토크나이저는 3000개 정도만 추가를 하고 기존의 토크나이저와 중복된 토큰을 제거하고 병합하자
꿀팁7.LLM Evaluation
묻지마 리더보드 업로드가 능사가 아님 실제로 사용하는게 더 중요다
LLM모델평가 vs LLM시스템 평가(협업)

자세한 내용은 아래 내용을 참고해라
https://www.youtube.com/playlist?list=PLORxAVAC5fUULZBkbSE--PSY6bywP7gyr
후기

날짜: 12/08
시험기간에 시험 잘 보는것 보다 가치 있을 것 같아서 갔는데 정말 유익했다.
우선 선릉역에 처음 가봤는데 여의도를 증권가를 처음 갔을 때 만큼의 충격을 받았다.
건물들에 압도되는 느낌을 오랜만에 받았고 내가 알던 기업들 로고가 붙어 있는게 신기했다.
이 모임에 어떤 사람들이 오는 지에 대한 인식도 없이 그냥 생활 반경에 없는 사람들을 만나는게 목적이 었는데 정말 대단하신 분들이 많이 참석하여 목적은 충분히 이루었다. 아쉽게도 대학생은 나 밖에 없어서 좀 위축되긴 했다. 다양한 기업에서 일하는 데이터분석가들, 데이터엔지니어들, it 기업 종사자들, 어디 연구원, 스타트업 대표님들 등 많은 사람들이 있었다. 기억에 남는 분들은 내 왼쪽에는 생성형 ai 관련된 책 쓰신 분이 계셨는데 이 책 서점에서 베스트셀러였던 것 같은데 제목이 기억이 안나서 소개를 못하겠다…ㅋ 근데 it 종사자 답지 않게 되게 잘생기셔서 놀랐다. 또 오른쪽에는 LG전자 무슨 사업부에서 오신분이 계셨는데 직무는 처음 들어보는거라 기억을 못하겠다. 또 뒷자리에서 snowflake 라는 회사의 영업대표이자 이사를 맡고 계신분이 명함도 주셨고 오늘 이 강연을 해주신 aws직원 분도 계셨다. 첫 강연은 원티드에서 일하시는 분이 해주셨는데 그건 너무 sql 지식이 많이 들어가서 이해를 못해서 추후에 다루도록 하겠다.
중간에 치맥타임이 있어서 먹으면서 간단한 얘기를 했다. 물론 낯가리고 이런 자리도 처음이고 여기있는 사람들에 비해 난 아무것도 아는게 없는 지잡대생이란 생각에 위축되어있어서 어버버버 거리다 오긴했는데 그분들 얘기를 듣는 것 만으로도 정말 도움이 많이 되었다. 특히 그 중 옆에 lg전자에서 일하시는 분이 다른 제조회사에서 일하는 분과 하시는 얘기를 듣는게 큰 도움이 되었다.
그분께서는 현재 LG전자에서 일함에도 윗분들이 데이터분석에 대해 아는게 너무 없다고 하셨다. 그냥 분석하면 되지않냐 이런식으로 말해서 답답하다고 하셨다. 그래서 지원도 제대로 못받는다고 하셨다. 제조업이다 보니 오작동 이런걸 위주로 하시는것 같은데 윗분들께 보고를 할 때 멜스펙트럼 어쩌구저쩌구 해도 절대 못 알아 듣고 관심도 없다 라고 하셨다. 그래서 이걸 이해시키는게 굉장히 어렵다고 하셨다. 이분께서 첫번째 강연자 분이 발표하셨을 때 만드신거 테스트할 때 평가지표를 어떻게 사용하셨냐라는 질문을 하셨는데 확실히 현업에 있으신 분들의 시선은 날카롭다고 느꼈다. 나는 그냥 듣고 우와 신기하다 란 생각 밖에 못했는데 말이다.
이분이랑 얘기하면서도 느낀게 내가 데이터과학부를 복전하면서 '이렇게 데이터분석을 진행해야되는데' 라고 당연히 여기던 프로세스를 경영학과 친구들이랑 얘기하면 전혀 모른다는 점이다. 이게 단순히 우리학과의 문제가 아니라 실무까지도 적용된다는 것이다. 요즘 ai가 너무 빨리 발전하고 자극적인 기사가 쏟아져서 내가 취직을 위해 뭘 준비해야지와 이걸 준비하는게 맞나 라는 생각을 자주 했는데 그냥 방향 설정해서 열심히 하면 될 것 같다는 확신이 들었다.
+SQL이 진짜 중요하다
다음에 소모임에 또 참석 해야 할 것 같다. 여러분들도 그러길 바란다!


좋은 글 감사합니다.