이번에는 Hugging Face Pipeline에 대해 알아보겠다.
Pipe line은 추론을 위해 모델을 사용하는 간단한 방법이다.
pipe = pipeline("text-classification")
pipe("This restaurant is awesome")
#[{'label': 'POSITIVE', 'score': 0.9998743534088135}]위와 같이 하고자하는 작업을 pipeline으로 묶어준 후 변수(pipe) 선언을 하여 간단하게 실행할 수 있다.
from transformers import pipeline
text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
translator = pipeline(task="translation", model="google-t5/t5-small")
translator(text)
#[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]위와 같이 번역작업에도 사용될 수 있고 텍스트 관련 작업뿐만 아니라 비전, 오디오 등 다양하게 쓰인다.
다음은 내가 겪은 오류이다
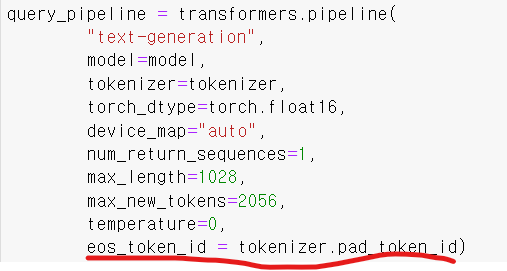
파이프라인을 이렇게 작성한 후 실행시키니

이런 처참한 결과가 나왔다.

이 문제는 eos_token(문장을 마무리 짓는걸 의미하는 토큰) 의 문제인걸 알았는데 도무지 해결이 안되었다. 그러다 혹시나 하는 마음에 pipeline 공식문서에 들어가 보았다.
공식문서 제공

이 문서를 보니 pipeline은 eos_token을 입력으로 받지 않았다. 그냥 내 개인적인 생각으로 모델선언할때 넣는 eos_token을 넣어도 되겠지란 생각에 넣었다고 위와같은 문제가 발생한 것이다.
eos_token_id 같은 경우는 모델마다 선언하는 방법이 다르기 때문에 모델과 토크나이저를 직접 사용하는 저수준 API에서 사용하길 권했다. 즉, 내가 사용하는 모델에서는 eos_token_id = tokenizer.pad_token_id가 사용되지 않았던 것 같다.
다음은 빨간 밑줄 친 부분을 제거하고 실행한 결과이다.

원래 계획한대로 추론을 잘 하는 것을 알 수 있다.
다음엔 프롬프트 엔지니어링을 하러 가야겠다.
