koala 프로젝트
1.lstm과 llm의 sequence 차이

요즘 텍스트 임베딩을 하는 프로젝트를 하는데 팀원분이 sequence length에 대한 질문을 했다. 어렴풋이 알고는 있었는데 명확하게 문장형태로 설명해주지 못했다. 남에게 설명해줄 수 있어야 아는것 이라고 했다. 결론적으로 말하자면 sequence를 처음 알게된게
2.워드임베딩으로 유사도를 구할 때 유의사항
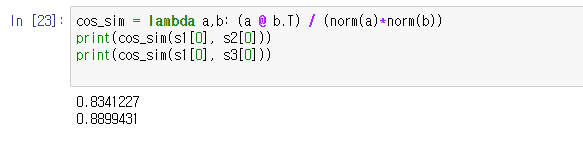
개요 지금 하고 있는 프로젝트가 특정 문장과 논문 간의 유사도를 구해서 논문을 바로 찾아주는 챗봇을 만드는 프로젝트를 하고 있다. 프로젝트를 하면서 좋은 모델을 사용하면 임베딩 성능이 좋다고 알고 있어서 조금 무거운 모델을 사용해서라도 임베딩을 진행했었다. 하지만
3.Quantization

Post-Training Quantization(PTQ)Quantization-Aware Training(QAT)Accelerate - LLM을 sharding 해주는 패키지이때 LLM을 sharding 한다는 것은 모델을 여러 조각으로 나눈다는 것을 의미하고 OOM을
4.Hugging Face Pipeline을 사용하면서 겪은 문제

이번에는 Hugging Face Pipeline에 대해 알아보겠다.Pipe line은 추론을 위해 모델을 사용하는 간단한 방법이다.위와 같이 하고자하는 작업을 pipeline으로 묶어준 후 변수(pipe) 선언을 하여 간단하게 실행할 수 있다. 위와 같이 번역작업에도
5.torch.float16 과 bfloat16의 차이
양자화로 로드하는 방법을 공부하던 중 torch.float16과 bfloat16의 차이가 궁금해져서 공부해보았다.이들은 모두 데이터 사이즈를 줄이는 방식이다. 기존 32-bit로 표현하던 숫자들을 torch.float16과 bfloat16와 같은 저정밀도 부동 소수점
6.PEFT - LoRA
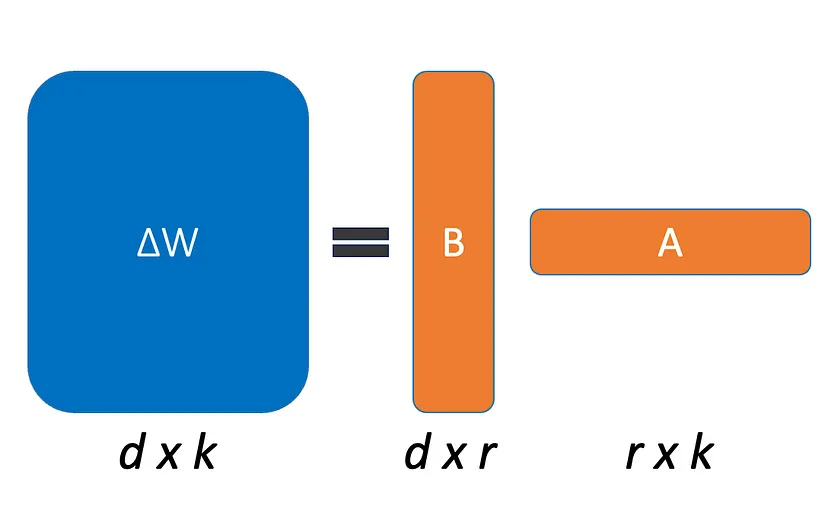
PEFT(parameter-efficient fine tuning)는 사전학습된 LLM의 대부분의 파라미터를 프리징하고 일부의 파라미터만을 파인튜닝함으로써 저장공간과 계산능력을 대폭 줄인다. 파인튜닝할때 발생하는 문제점중 하나인 catastrophic forgettin
7.Error tokenizing data. C error: Buffer overflow caught - possible malformed input file.
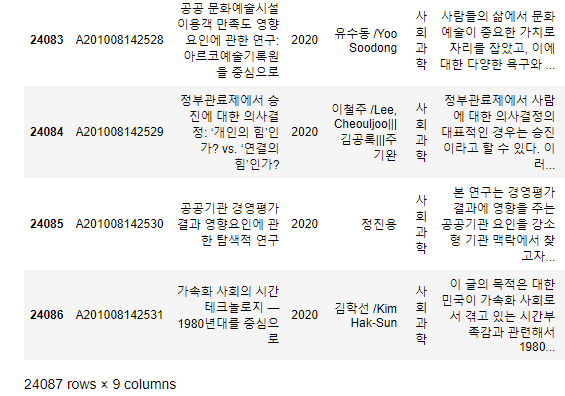
프로젝트를 진행하던 중 데이터를 합치는 과정에서 저장 후 다시 불러오면 데이터 양이 증가하는 문제가 발생했다.마지막 데이터를 살펴봐도 이상한 부분이 없었다.정말 불행하게도 데이터를 아무리 확인해도 문제를 찾을 수 없었고 정말 수많은 시도 끝에 이유를 알게 되었다.바로