PEFT(parameter-efficient fine tuning)는 사전학습된 LLM의 대부분의 파라미터를 프리징하고 일부의 파라미터만을 파인튜닝함으로써 저장공간과 계산능력을 대폭 줄인다. 파인튜닝할때 발생하는 문제점중 하나인 catastrophic forgetting또한 극복한다.
catastrophic forgetting: AI가 새로운 정보를 학습할 때 이전에 학습한 정보를 갑자기 급격하게 잊어버리는 경향
이때 catastrophic forgetting의 경우 Full finetuning보다는 LoRA 등 adapter를 이용한 PEFT가 더 많이 보존된다. 물론 100% 보존되지는 않는다.
이 글에서는 PEFT 방식 중 LoRA의 파라미터를 다룬다
LoRA의 개념
LoRA(Low-Rank Adaptation of Large Language Models)는 사전 훈련된 모델의 가중치를 직접 수정하는 fine tuning 방법이 아니다. LoRA는 사전 훈련된 모델의 특정 층에 추가적인 낮은 랭크(rank)의 행렬을 도입하여 모델의 출력을 수정하는 것이다. 이 추가적인 행렬은 학습 가능하며 downstream task(최종적으로 해결하고자 하는 작업)에 대한 학습 과정에서 최적화된다. 즉, LoRA를 적용한 모델은 원래 모델의 가중치와 이 추가적인 학습 가능한 행렬의 조합을 통해 새로운 출력을 생성한다.
Tip: rank란?
rank는 linear independence인 row 또는 column의 최대 개수를 말한다.
첫번째 예제 사진
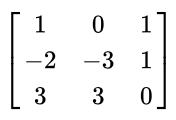
해당 metrics의 rank는 2이다. 첫 번째와 두 번째 열은 서로 linear independence 라고 볼 수 있다. 하지만, 세 번째 열의 경우에는 첫 번째 열에서 두 번째 열을 빼주게 되면 세 번째 열이 된다. 즉, 선형적으로 의존적인 관계가 성립한다. 따라서, 이 행렬의 Rank는 2가 된다.
[출처][기초 선형대수] 행렬에서 Rank (랭크) 란?|작성자 PN
두번째 예제 사진
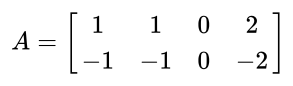
첫 번째 열은 정확히 두 번째 열과 같고, 네 번째 열은 첫 번째 열의 두 배와 정확히 같기 때문이다. 그런데 세 번째 열이 0의 값을 가지므로, 랭크에서는 제외되지만, 결국 세 번째 열을 제외한 나머지 세 개의 열들은 하나의 기저로 역할을 할 수 있으므로, 하나의 랭크를 가진다고 볼 수 있겠다. 따라서, 위의 행렬의 랭크는 1이다.
[출처][기초 선형대수] 행렬에서 Rank (랭크) 란?|작성자 PN
그럼 낮은 rank를 사용하는 이유는 뭘까?
Low Rank를 사용하는 이유
Low Rank metrics를 사용하는 주된 이유 중 하나는 데이터의 본질적인 구조를 보존하면서 데이터를 압축하고 요약할 수 있다는 점이다. 이는 불필요한 정보를 제거하고, 중요한 정보를 보다 효율적으로 표현하는 데 도움이 된다.
코드
우리가 프로젝트에서 사용할 코드이다.
peft import LoraConfig
config = LoraConfig(
r=8,
lora_alpha=32,
#target_modules=["query_key_value"],
target_modules=[
"q_proj",
"up_proj",
"o_proj",
"k_proj",
"down_proj",
"gate_proj",
"v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
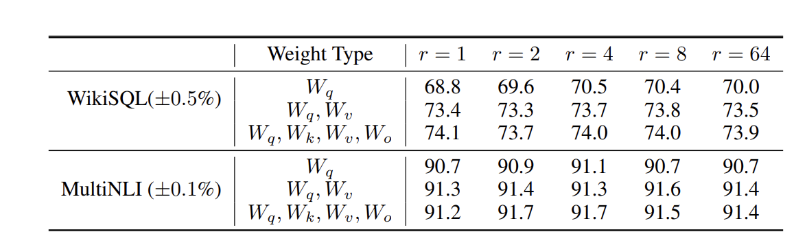
)이 중 두 개의 하이퍼파라미터인 r과 target_modules는 경험적으로 adaptation 품질에 큰 영향을 미치는 것으로 나타났다.
r
r은 미세 조정 과정에서 학습된 낮은 순위 행렬의 순위를 나타냅니다. 이 값이 증가하면 낮은 순위 적응 중에 업데이트해야 하는 매개변수의 수가 증가한다. 즉, r이 낮으면 속도가 빨라지는 대신 성능 저하가 있을 수 있다. 대신 r이 크게 증가한다고 해서 성능이 크게 증가하지는 않는다.
lora_alpha
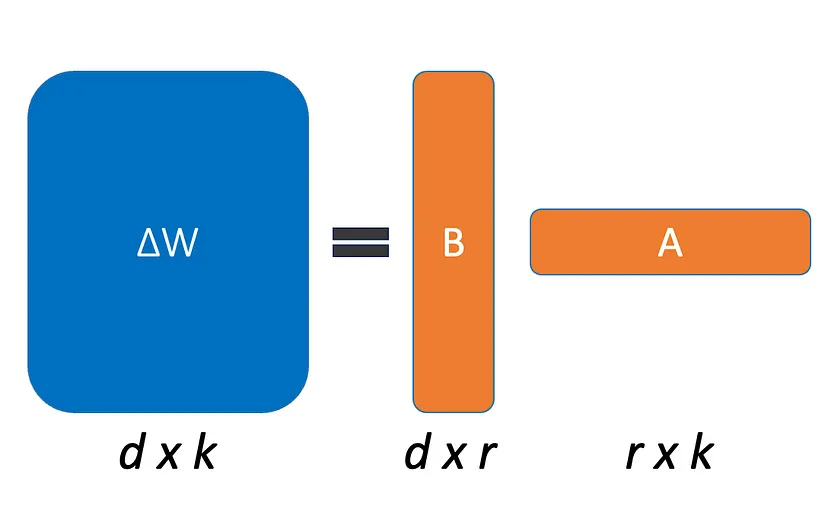
ΔW 는 α / r 에 의해 조정된다. Adam으로 최적화할 때 α 조정은 초기화 크기가 적절하게 조정된 경우 학습 속도를 조정하는 것과 거의 동일합니다. 그 이유는 매개변수의 수가 r 에 따라 선형적으로 증가하기 때문입니다 . r 을 늘리면 ΔW 의 항목 값 도 r 에 따라 선형적으로 확장됩니다 . 즉, lora_alpha는 학습 속도 또는 학습률 조정 계수이다.
target_modules
앞서 LoRA 개념 파트에서 특정 층에 추가적인 낮은 랭크 행렬을 도입한다는걸 기억하자. 하이퍼파라미터가 특정 층을 선택하는 파라미터이다.
우선 "q_proj","o_proj","k_proj","v_proj"는 attention 층에서 사용되는 층이다.
또 "gate_proj","up_proj","down_proj"는 MLP(다층 퍼셉트론)에 사용되는 층이다.
결론적으로 모델마다 target_modules는 상이하니 확인해보자
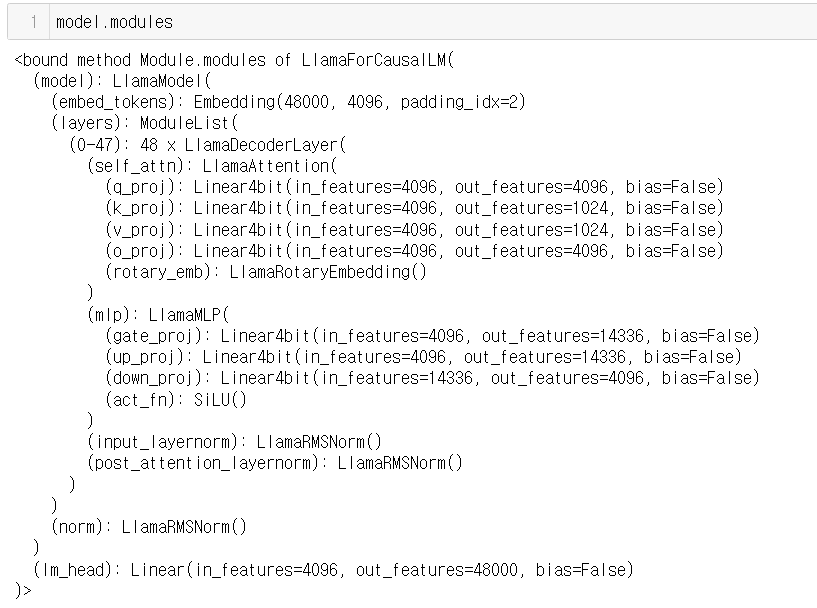
lora_dropout
lora_dropout은 lora에 dropout을 적용하는 비율에 관한 것이다.
dropout이 적용되면 해당 뉴런들은 순방향 전달에서 일시적으로 제거되고, 역방향 전달에서는 가중치 업데이트가 뉴런에 적용되지 않습니다. lora_dropout 의 기본값은 0 입니다 .
bias
bias는 ‘none’, ‘all’ , ‘lora_only’ 셋 중 하나이다. 'all' 또는 'lora_only'인 경우 해당 편향은 훈련 중에 업데이트된다. 댑터를 비활성화하더라도 모델은 적응하지 않은 기본 모델과 동일한 출력을 생성하지 않는다. default는 none 이다 .
task_type
task_type을 지정하지 않아도 모든 것이 잘 작동하는 것 같습니다. 가능한 작업 유형에는 CAUSAL_LM, FEATURE_EXTRACTION, QUESTION_ANS, SEQ_2_SEQ_LM, SEQ_CLS 및 TOKEN_CLS가 포함됩니다.
'r'의 상황과 유사하게, LoRA 적응 과정에서 더 많은 모듈을 타깃팅하면 훈련 시간이 늘어나고 컴퓨팅 리소스에 대한 수요가 증가합니다. 따라서 트랜스포머의 주의 블록만 타깃팅하는 것이 일반적인 관행입니다. 그러나 최근 Dettmers 등의 QLoRA 논문에서 볼 수 있듯이 모든 선형 레이어를 타깃팅하면 적응 품질이 향상된다는 연구 결과가 있습니다.
Supervised fine-tuning은 본질적으로 사전 학습된 모델이 제공된 프롬프트에 따라 조건이 지정된 텍스트를 생성하도록 추가 학습하는 것입니다.프롬프트-응답 쌍이 일관된 방식으로 형식이 지정된 데이터 세트에서 모델을 미세 조정한다는 점에서 감독을 받습니다.
(생각해보니 데이터셋과 예제는 걍 허깅페이스에서 찾으면 되는듯)
https://www.databricks.com/kr/blog/efficient-fine-tuning-lora-guide-llms
다음 코드는 허깅페이스 허브에서 데이터셋을 메모리로 로드하고, 필요한 필드를 일관된 형식의 문자열로 프롬프트를 변환한 다음, 바로 뒤에 응답(즉, 설명)을 삽입합니다. 이 형식은 대규모 언어 모델 연구계에서 '알파카 형식'으로 알려져 있는데, 이는 메타에서 원래의 LlaMA 모델을 미세 조정하여 널리 배포된 최초의 명령어 추종 대규모 언어 모델 중 하나인 알파카 모델을 생성하는 데 사용된 형식이기 때문입니다(상업용으로 라이선스가 부여되지는 않음).
다운스트림 작업을 위해 외부 모듈을 학습하거나 몇 개의 범위만 적응하는 방식이 제안되도록, 각자의 작업을 수행하기 위해 사전 훈련된 모델에 정도 양의 작업별 매개변수를 저장하고 로드하는 것을 제안
참고 자료들
https://www.databricks.com/kr/blog/efficient-fine-tuning-lora-guide-llms
https://ai.atsit.in/posts/1900838081/
https://medium.com/@manyi.yim/more-about-loraconfig-from-peft-581cf54643db
