주파수가 처음이해하면 어려울 수 있는데 얼마나 빠르게 반복하냐가 제일 이해하기 쉬운것같음
튜토리얼 코드 해보기
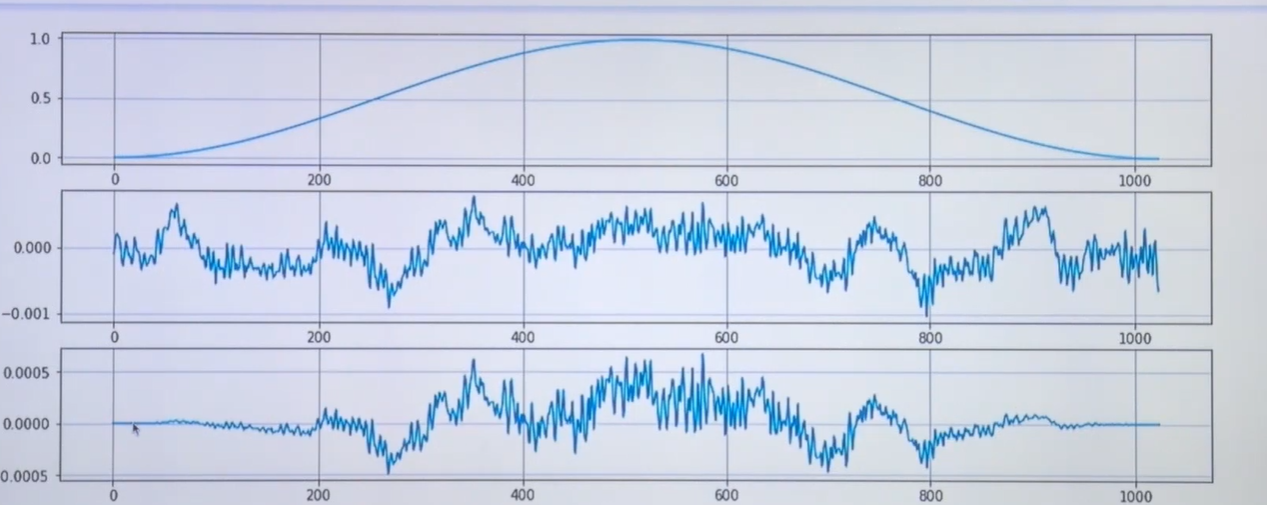
time domain- waveform을 만드는것 해보기
import librosa.display
audio_np = audioData.numpy() #-> numpy로 바꾸기
fig = plt.figure(figsize = (14,5))
librosa.display.waveshow(audio_np, sr=sr, color="blue")이 코드 또한 베이스 코드로 돌리면 돌아가지 않는다.
함수 이름이 librosa.display.waveshow로 바뀌었고 color를 지정해 줘야한다.
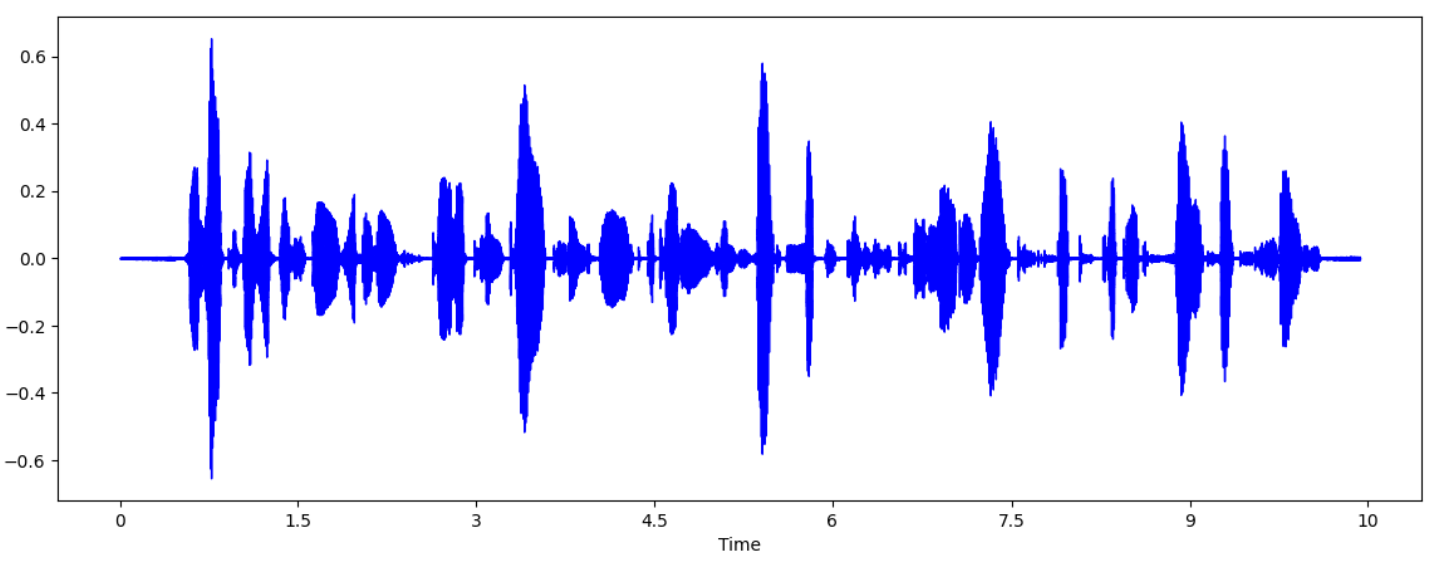
x축인 Time을 살펴보면 10초 가량인 것을 알 수 있다.
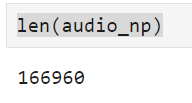
10초 되는 파형중에서 audio_np[:100000]을 하면 기존 길이 대비 60%만 사용하는 것이고 아래 x축을 보면 6초 가량인 것을 알 수 있다.
Q.음성데이터 학습할때 normalization이랑 mu- law encoding을 하냐??
normalization은 경험상 하면 확실히 성능이 좋아진다. 근데 mu- law encoding은 잘못느끼겠다.
실험해보는걸 추천함
440이 294보다 주기를 훨씬 빠르게 반복하더라
hz값을 얻으려면 어떻게 해야하나
=>푸리에 변환
임의의 입력 신호를 다양한 주파수를 갖는 주기함수(복소수 지수함수)들의 합으로 분해하여 표현하는것
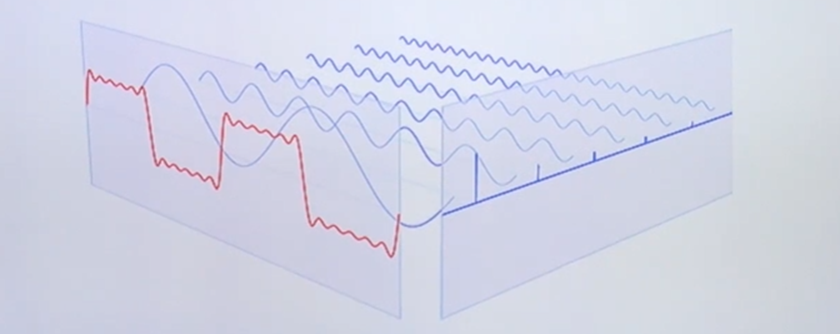
ex) 사진 속 빨간색을 분해한다고 가정해보자. 이건 고주파나왔다 저주파나왔다 고주파나왔다 저주파나왔다 하는것이다. 이걸 분해해서 보면 어떠한 frequency 영역대에서 활발하게 신호의 세기가 나오는지를 조회할 수 있다라고 이해하면된다.
정현파는 복소주기함수라고 했는데 왜 푸리에 변환은 주기함수라고 바뀌나? 무슨 연결성이 있나
둘 사이의 관계를 나타내는게 오일러 공식이다. 오일러 공식에 따르면 우리가 지수를 코사인과 사인으로 풀어낼수있다는것에서 기인함. 근데 이해 못해도될듯. 입력신호가 어떤 주기성을 갖는 함수의 합으로 표현된다.
푸리에 변환을 하면 결과적으로 나오는건 주기함수를 갖는 시퀀스가 나오게 된다.
푸리에변환을 하면 실수부와 허수부가 나온다. 걍 ppt보자 ㅋ 수학 어렵다

소리는 세기,주파수 ,위상이 있다는건데 주파수 안에 강도까지 포함되어 나오는게 spectrum magnitude-복소수의 절대값(주파수의 강도), 복소수가 가지는 phase는 phase spectrum(주파수의 위상)이라고 부른다.
정리하면 소리를 푸리에 변환을 하면 실수부와 허수부로 리턴이 되는데 보통 실수부가 frequency 영역대의 magnitude(진동의 절대치)를 뜻하고 허수부가 phase를 뜻한다.
DFT(Discrete Fourier Transform)
우리가 sampling한건 discrete한 영역인데 위에서 말한 signal은 연속적인 것 처럼 얘기한다. 그래서 discrete한 영역에서 Fourier 변환을 하기 위해 DFT가 나왔다.

def DFT(x):
N = len(x)
X = np.array([])
nv = np.arange(N)
for k in range(N):
s = np.exp(1j*2*np.pi*k/N*nv) #어떤 frequency 영역들을
X = np.append(X, sum(x*np.conjugate(s))) #append로 concate 한다. 어떤 히스토그램을 봐도 이런식으로 주파수와 시간의 축으로 표현된
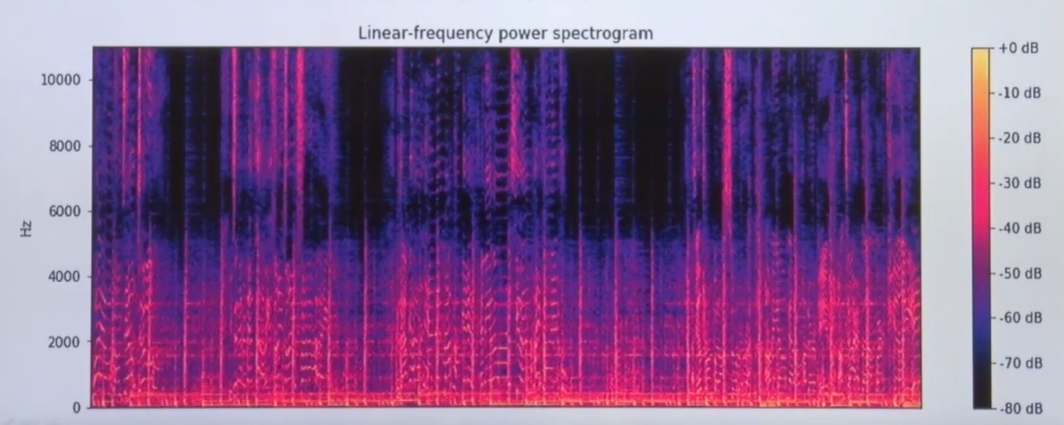
return X그래서 스펙토그램을 보면 어떤걸 봐도 이런식으로 주파수와 시간의 축으로 표현된다. 어떤 소리가 시간에 따라 진행되는데 이전의 wave form은 amplitude만 시각화됨 근데 지금은 어떤 frequency 영역대가 강한지 시각화하는게 스펙토그램이고 이게 푸리에 트랜스폼으로 얻어진다
dft를 클론코딩하고 이해안되면 질문해보고 위에서 만든 인풋 시그널을 넣어보자(audio_np)를 dft 돌려보자
q. dft를 돌리면 frequency 여역대에서 active 되는걸 볼 수 있는데 소리를 실제로 들으면 중요한 frequency영역대가 바뀌는데 사람들이 frequnency를 인지적인 영역에서 processing을 돌릴때 어떤 time bin을 가지고 소리를 듣는다는건데 지금처럼 DFT를 돌리면 한번에 소리를 처리하는 듯한 인상을 받는다. 그래서 나온게 STFT(Short time fourier transfrom)이다.
인간이 한번에 소리를 들을 때 한번에 5초를 듣는게 아니라 짧게 0.25초 정도 듣는다고 알려져있다. 사람처럼 컴퓨터도 frequecy가 시간에 따라 변하는 값을 가지게 해야한다. 그래서 하는게 STFT(Short time fourier transform)이다. 입력시간을 0.25초 단위로 인식한다면 컴퓨터도 같은 시간의 bin을 만들어서 그걸 frame이라고 지칭하고 프레임단위로 푸리에 변환을 하는것이다.
STFT는 시간에 따라 변하는 신호의 frequency 성분을 분석하는 방법으로, 푸리에 변환을 통해 얻어진 각각의 동일한 frequency 영역을 연속적으로 결합함으로써, 소리를 시간-주파수 영역의 매트릭스 형태로 표현할 수 있습니다.
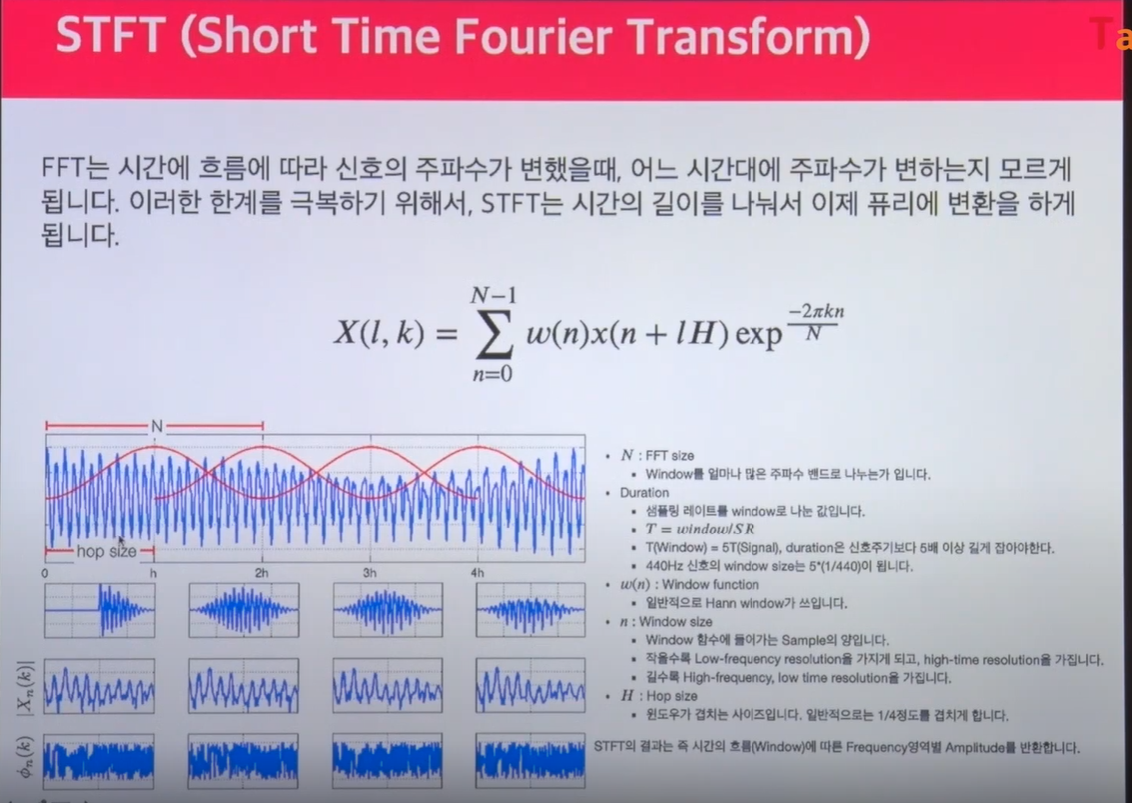
N은 FFT size이다. N은 amplitude를 얼마나 많은 주파수 밴드로 나누는가 이다(사진 참조). 이는 추후에 n_fft라는 매개변수로 사용된다.
Duration은 SR를 window로 나눈 값이다.
hop size는 window가 겹치는 사이즈이다. short time fourier transform을 하게 되면 일정한 시그널들이 겹치게 푸리에변환을 한다. 그래야 소리에 대한 풍부한 정보를 매트릭스 속에 담을 수 있다. 예를 들어 어떤 소리가 5초 짜리가 있다고 가정하면 0~1의 정보와 0.5~1.5와 1~2의 정보를 겹쳐서 처리하면 더 풍부한 정보를 매트릭스 속에 담을 수 있다. 그래서 fourier transform을 특정 시간의 bin으로 나누는게 STFT이다 라고 보면된다.
=>STFT의 결과는 즉 시간의 흐름(Window)에 따른 Frequency영역별 Amplitude를 반환합니다.
[실습]
S = librosa.core.stft(audio_np, n_fft=1024, hop_length=512, win_length=1024)
S.shape, len(S[0]), S[0][0]
#input shape 중요!
파라미터
audio_np: 오디오 데이터
n_fft(number of fft): frequency 영역대를 한번에 얼마만큼 볼 것이냐
hop_length: 각각 샘플을 쪼개서 볼텐데 어느정도로 쪼개서 볼거냐, 실습코드를 보면 n_fft를 1024로 보고 있는데 (ppt 기준으로 n이 1024)라는 뜻이다.
1024개를 볼때 hop_length는 얼마나 겹치게 할것이냐이다 win_length는 window function이라는게 적용이 된다. 이건 나중에 설명한다.
audio_np를 세보면 206720이 나온다. 이게 1024개씩 푸리에 트랜스 폼에 들어가게 되고 512개씩 겹치게 된다. 그럼 이제 length가 프레임 단위로 보는거니깐 시간축이 frame 단위로 바뀐다.
그래서 513개의 frequency 축에 404개의 시간축이 나온다.
513(주파수 구성요소의 수)= 1+1024/2(n_fft/2)
403(프레임 수) = 1+ (206720(오디오 신호 길이)- 1024(n_fft))/512(hop_length)<- 여기에 올림 적용
실제로 데이터를 찍어보면 실수부와 허수부가 같이 있다.
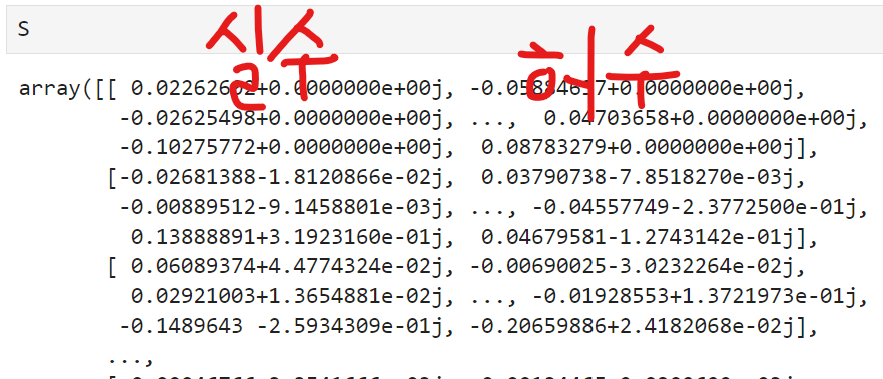
오디오 딥러닝에 적용할 때는 허수부를 날린다. 이는 소리를 인지하는데 큰 정보가 없다고 여겨지기 때문이다. 근데 phase(허수부)가 잘 안맞는 경우 음성학습할 때 사람같지 않게 들릴 때가 있다. phase를 날릴 때 절대값에 제곱하는 방식으로함
STFT는 시간 축에 따른 주파수 축의 변화를 확인할 수 있게 해줍니다.
이 과정에서 오디오 신호는 미리 정의된 길이(window_length)의 여러 구간(프레임)으로 나누어지고, 각 프레임은 독립적으로 푸리에 변환됩니다.
결과적으로, 이러한 변환을 통해 시간에 따른 주파수 성분의 변화를 분석할 수 있으며, 이 데이터는 딥러닝 모델의 입력으로 사용될 수 있습니다.
window_length: stft를 하면 시간축에 따라 흘러가는 frequency축의 변화를 확인할 수 있고 이 친구가 보통 우리가 딥러닝에서 인풋에서 사용하는 데이터이다
window_function는 아래와 같은 장점이 있다.
1.주된 기능은 main-lobe의 width와 side-lobe의 레벨의 Trade-off 를 제어해 준다는 장점이 있다.
1.1 main-lobe: 특정 주파수 성분의 강도를 나타낸다.
1.2 side-lobe: 신호에는 존재하지 않지만 주파수의 성분을 나타낸다.
2.깁스 현상을 막아주는 장점이 있다.
2.1 깁스현상: signal을 우리가 임의의 frame단위로 자를 때 연속성이 깨질 수 있음. 이걸 보완하기 위해서 window_function은 시작부분과 끝부분이 0으로 끝나도록 만든다. 매트릭스 멀티플리케이션을 하면 끝과끝이 맞춰져서 연속적인 함수를 만들 수 있다.
이 사진을 보면 1과 3은 끝이 일치하는걸 볼 수 있지만 2는 일치하지 않는다.
Q. n_fft를 몇으로하면 좋을까?
연산효율을 위해 1024로 하고 win_length를 일치시키는게 보통 좋다고한다. 바꾸다보면 shape이 조금씩 바뀐다
ex)hop_size=256으로하면 타임도메인이 늘어난다. 이건 파라미터의 영역이라 테스트해보는게 좋다.
1024개가 하나의 프레임이라고 지정한거니깐 예를 들어 frequency rate가 1초에 16000개다 라고하면 1024/16000하면 몇초정도가 들어오는지 알 수 있음
사람들이 오디오 인풋을 인지할때 그정도를 인지하는가? tastk마다 다르다
일반적인 외부소리이면 빠르게 프로세싱을 거치는데 음악이면 코드진행을 ㅗㅂ면서 느끼는게 다르다 그래서 frequency를 어느정도 사이즈를 넣고 frame이 어떻게 정의되는지 아는게 중요하다.
librosa.power_to_db란?
실제 음악에서는 db(데시벨) 단위를 사용한다. 우리가 사용하던 amplitude는 샘플링할 때 쓰는 단위이기 때문에 실제 음악에서 쓰는 db로 바꿔서 사용하면 시각화가 더 잘된다. 해당 변형을 위한 코드이다.
S = librosa.core.stft(audio_np, n_fft=1024, hop_length=512, win_length=1024)
D = np.abs(S)**2
log_S = librosa.power_to_db(S, ref=np.max) #소리의 단위를 db로 바꿈
plt.figure(figsize=(12,4))
librosa.display.specshow(log_S, sr=16000, x_axis='time')사람들이 소리를 인지할 때 저주파에서 소리에 정보가 더 많다.
음성이나 음악을 공부할때 fundamental frequency라는게 있음 f0라고 한다. 이걸 제거했을 떄 소리에 대한 인식률이 확 떨어짐. 가장 낮은 음을 이루는 친구들이 펀더멘탈을 이루게됨. 그곳에 정보가 많다
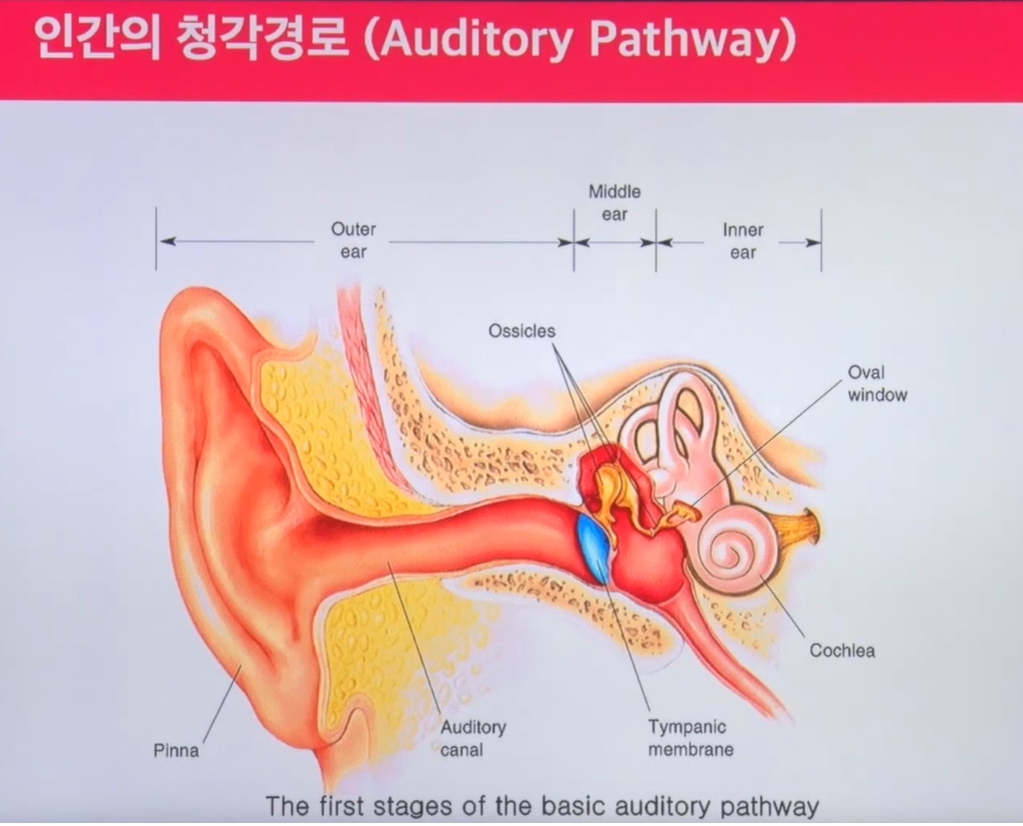
인간의 청각경로를 살펴보면 Cochlea라는 영역에서 basilar membrane이라는 영역이 있다. 그 페이지어 멤브리어 영역대에서 반응하는 귀의 부분이 있다. 여기서 보면 linear한 scaling으로 매핑이안된다.
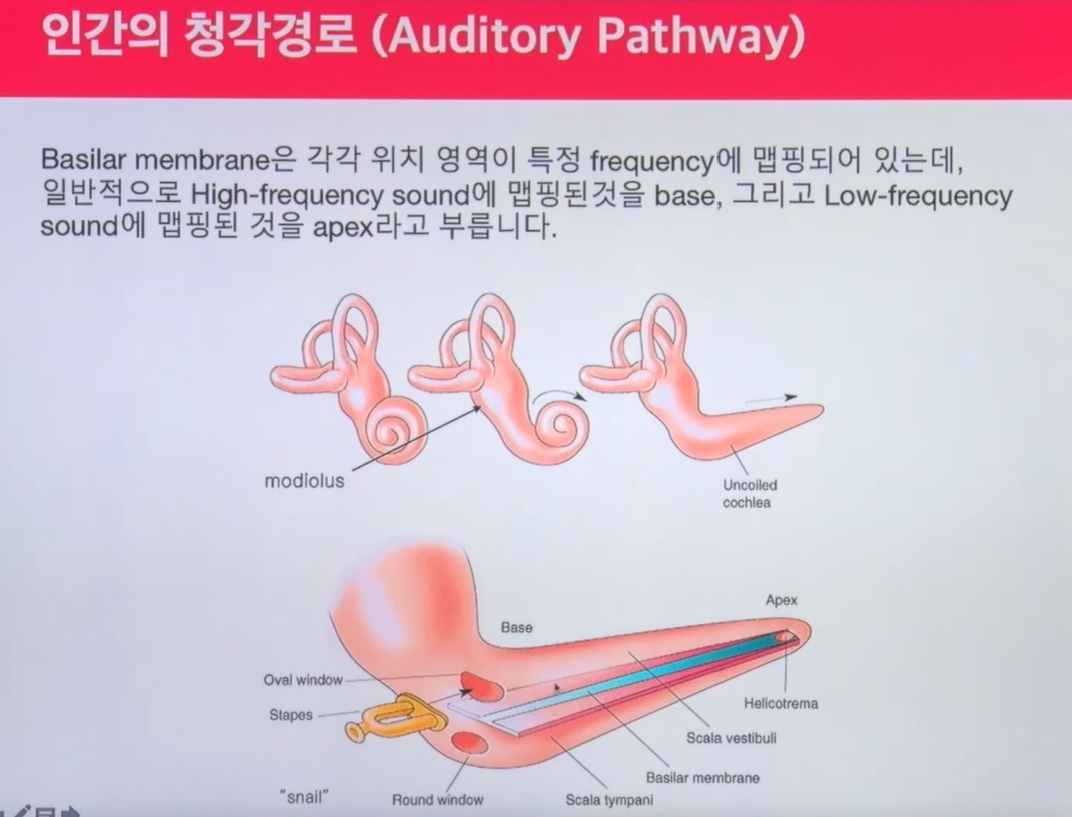
우리가 소리를 인식할 때 여기서부터 1cm는 100hz 2cm는 200hz이렇게 인지하는게 아니다. 일단 인간은 소리 frequency를 categorical하게 인지하게됨.(ex 100hz 120hz...) 연속적인 frequency임에도 우리가 100hz 101hz를 인지하지 못한다. 인지하는 영역도 window가 다르다. 저주파에 대한 정보를 더 크게 인지하는 영향이 있다. 오디오 인식 연구에서 사람이 소리를 인지할 때 어떤 영역대의 인지가 더 높은지 실험하는데 사진에서 high frequency에 대한 영역이 base고 low frequency에 대한 영역이 apex인데 apex의 영역 대가 더 크게 소리를 인지한다.-음악인지과학
Mel-Filter Bank
위의 내용을 착안한 것이다
사람은 인접한 주파수를 크게 구별하지 못한다 + low한 frequency에서 더많은 정보를 얻는다 를 고려한 것이다.
이는 우리의 인지기관이 categorical한 구분을 하기 때문이다.
멜 스펙트럼은 주파수 단위를 멜 단위로 바꾼 것을 의미한다.이 멜 필터 저주파 주변에서 얼마만큼 에너지가 있는지를 알려준다. 아래 그림에 노란색으로 그린것이 멜 필터뱅크의 bin이다. n_mels는 이 멜필터뱅크를 몇개 설정하느냐이다.

filter bank
spectogram이 linear한 scale로 input이 들어가는게 아니라 저주파를 더 반영하는 영역으로 들어가야되지 않나 라는개념으로 들어간게 frequency의 filter bank개념이다. 이게 neural net이나 tts, stt 모형들에서도 더 좋지 않을까 라고 봤고 실제로 멜스펙트로를 쓰는게 성능이 더 좋았다.
그래서 음악도 그렇고 오디오도 그렇고 보통 input으로 mel-scale의 filter bank를 적용해서 스케일링한것을 input으로 넣는다.
Q. mu-law 인코딩을 하는편이냐? no
사람귀가 amplitude에 대해 log적으로 반응한다. 이런 특성을 잘 반영하기 위해 로그스케일로 반영한게 mu-law인데 이는 amplitude에 대한 전처리이다. 멜필터뱅크는 frequency에 대한 전처리이다. 경험상 mu-law 인코딩을 하나 안하나 비슷한데 한번 테스트 해보는걸 추천한다.
지금은 사람이 소리를 어떻게 인식하냐를 따라가고있다.
frequency 영역대의 bins을 보겠다는 것
1263 bin으로 가까이 갈 수록 weight가 쌔진다. 노이즈적인 정보를 뺴고 사람 인지적으로 중요한 정보를 캐치한다. 기본적으로 8000hz는 0에 가까워진다. 2500대는 rich한 정보가 반영된다. neural net 모형이나 머신러닝 모형이 좀 더 노이즈가 제거된 정보를 반영하기 위해 이런 모형을 만듬
[melspectrogram 구현에 관하여]
librosa에 구현되어있다. n_mels: 멜 bin을 몇개로 볼거냐
멜빈은 1263 같은 숫자임
보통 쓰는건 40, 92, 128 을 사용하낟
frequency 영역대가 전에는 512 왜냐면 n_fft를 1024로하면
513개의 frequency bin이 생긴다 근데 이게 mel 영역으로 가면 데이터가 차원이 낮아진다.128이나 40이나 92나 . 논문들을 보니 음성쪽은 40만 쓰는 경우도 많고 음악쪽은 92나 128쓰는 경우도 많음
mel frequency bin은 튜닝할때 쓸 요소 중 하나이다.
어느정도로 만들까가 이슈이다
mel bin은 fft사이즈보다 무조건 작게만들어야함
멜스펙트로그램을 보면 1024의 freuqnecy영역대가 40으로 줄어든다
실습코드 확인해라
멜 빈이 128일때랑 92일때랑 어떻게 스펙토그램이 바뀌는지 확인하자
40으로가면 계단현상이 보임.정보가 압축되엇꼬 압축된만큼 노이즈가 적음
128로 했을때 전반적인 경계선을 꾸준히 유지됨 데이터가 바뀌지는 않고 중요한 정보가 압축된다.
Q. mel bin크기를 문제에 맞게 정의할 수 있냐?
추천방법은 데이터 클래스별로 스펙토그램을 뽑아내서 평균값을 봐라
했던것 중에서 악기 맞추는 테스크가 잇었는데 각 클래스 별로 wave form이랑 스펙토그램을 찍어보면 어떤 frequency 영역대에서 얘네가 분별력이 생기겠따라는 감이 좀 보인다. 그러면 그것에 맞춰서 mel bin을 잡는것도 방법이다.
예를 등러 플룻은 8000까지 올라가는 소리강 ㅣㅆ다. 그럼 멜빈을 설계할 댸 8000까지 커버되는 멜빈을 짜는게 좋다. 고민할 시간에 직접 테스ㅌ 해보는게 더 좋음
배치는 스몰배치로 해서 거기서 학습이된다는 전제하에 대략적으로 나오면 쓰면됨
ex 지하철의 경우 high frequency 영역대의 소리도 중요할 것 같은데 하이 영역을 커버할 수 잇께 빈을 잘게 쪼개야지 이런생각할 수 있다. 그래서 태스크 도메인을 이해해야지 파라미터 튜닝이 쉬운건 맞다. 일단 스몰데이터셋을 구성하고 튜닝돌리면서 좋은 퍼포먼스를 찾아서
Q. Wave form과 스펙토그램의 차이는 뭔가?
wave form은 그냥 sampling한 amplitude값만(물리량)만 찍히는 친구다.
스펙토그램은 퓨리에 트랜스폼을 거쳐서 어떤 frequnecy영역대에 활성화되었는지를 시간축에 따라보는것
=> 둘다 시간축을 따라 보는건데 wave축은 amplitude만 있고 스펙토그램은 frequency와 앰플리튜드가 같이 있다. 사실 phase도 있는데 phase는 잘안쓴다.(음성합성할 떄는 사용한다)
결론 classification이나 auto- tagging같이 뭔가를 감지해야되면 phase는 안중요하다. 근데 음색이 중요한 영역에서는 phase가 중요하다
나중가면 input shape 맞추는게 어려워진다.
컨볼루션 레이너 진행되면 그다음 쉐입이 어떻게 되는지 계산해야되서 인풋이 중요해진다. 오디오를 자른다는 개념을 알면 좋다.
추가적인 말: 요즘 추세는 low한 모형들을 쓰기도 한다. wavenet의 경우는 그냥 wave signal을 그대로 쓴다. 근데 end to end로 가면서 mel filter bank나 스펙토그램에서 보고싶어하는 주파수 영역대를 end to end로 학습할 수 있지 않나라는 생각을 학계에서 하는 것 같다. 아직까지는 스펙토그램으로 인풋이 들어가고 wave form 레벨로 내려가려는게 추세인것 같다 2020기준. 최대한 피처엔지니어링이 적을수록
컨트리뷰션이 있다가 학계 움직임인것 같다.
