본 글은 [토크ON세미나] 디지털신호처리 이해 1강 - 디지털신호처리(DSP) 기초 I - Sampling, Quantization | T아카데미를 참조한 글이다.
강연자님께 좋은 설명해주셔서 감사하다는 인사와 함께 시작하겠다.
Deeplearning에서 오디오와 관련된 영역은 크게 sound와 speech로 나눌 수 있다
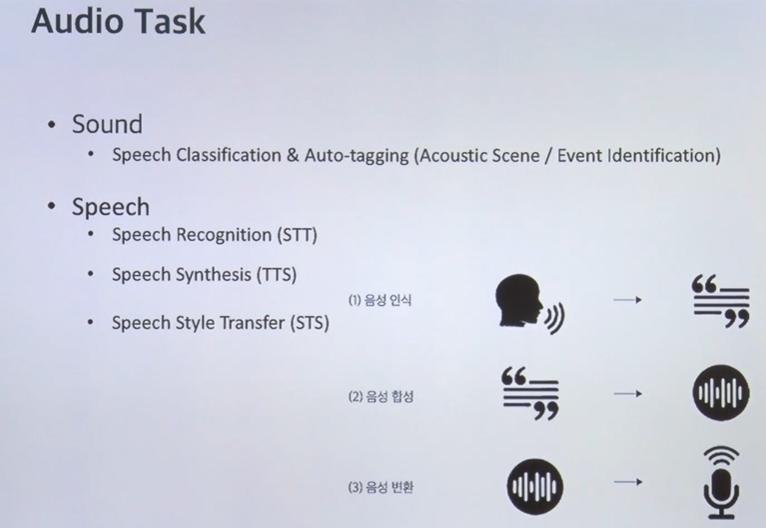
Sound
speech 분류 & 태깅 기차소리가 나는 소음 task ex) 기차소음 크기 예측, 사고현장에서 나는 소리 감지
speech
1) STT(speech to text) - 음성인식
2) TTS(Text to speech) - 음성합성 (tacotron논문)
3) STS(speech style transer) -음성변환
[응용할 수 있는 사례들]
스마트폰으로 들어오는 input 사운드를 듣고 위치를 파악한 다음에 추천도 해줌
소리를 듣고 기차인걸 알면 기차탈 때 좋은걸 추천해줌
과거와 현재 음성데이터를 이용한 딥러닝 방식이 바뀌었다.
과거에는 input speech -> feature extraction -> 의 순서였는데 딥러닝 이후로 바뀌었다.
( 먼지 모르겠땅 ㅋ) => 결국에 인풋으로 스펙트로그램을 사용한다
computer가 소리를 인식하는 방식
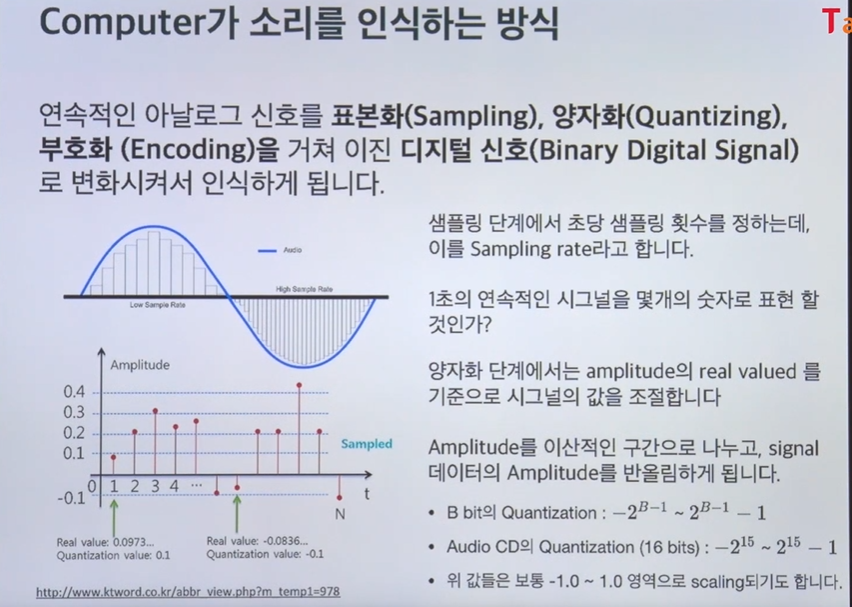
컴퓨터는 연속적인 아날로그 신호를 표본화(Sampling), 양자화(Quantizing), 부호화(Encoding)을 거쳐 이진 디지털 신호(Binary Digital Signal)로 변화시켜서 인식하게 된다
샘플링은 1초에 연속적인 시그널을 몇개의 소리로 저장할 것이냐
샘플링 단계에서 초당 샘플링 횟수를 정하는데 이를 sampling rate이라고 한다
sr=16000은 1초에 16000개의 데이터를 넣었다 라는 의미
자료형의 경우 float32로 할수 잇고 다양하게 할 수 있는데 의미가 전달되고 가장 효율적인 아키텍쳐로 표현하고 싶으면 양자화하는게 좋음
양자화 단계에서 amplitude를 이산적인 구간으로 나누고 signal 데이터의 amplitude(진폭)를 반올림한다
해당 강의에서는 torch audio를 사용한다
토치오디오의 특징
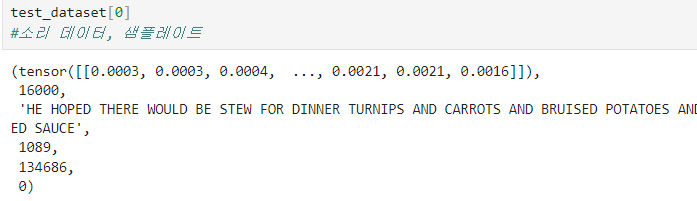
tensor를 주목하자!
토치오디오의 데이터셋은 array가 한번 더 묶여있다. 그래서 벗겨야됨test_dataset[0][0]으로 한번 더 벗겨 내야한다.
audioData의 길이에 sr을 나누면 duration이 나온다
duration: 음성데이터 길이(초)
토치오디오쓰는이유는 간편성을 위해 쓴다.
나중에 딥러닝 아키텍쳐를 짜면 repository가 모듈화된다. datalog, train,data augmentation 등등으로 모듈화되는데 토치오디오가 간편화에 큰 역할을 한다.
그럼 sampling rate가 높으면 좋을까? -> 연산효율은 떨어진다
그렇다면 어떻게 Sampling Rate를 설정할 것인가

나이키스트- 쌔넌 표본화 이론 를 참고하면 maximum sampling rate는 Maximum frequency/2 가 원칙이다. 일반적으로 이것보다 더 쉽게하는 방법은 오픈 데이터셋의 특징을 보면 된다. 4000이하로 내려가면 좋지 않다.
코드에서 audiodata는 텐서로 형성되어있어서(파이토치때문) .numpy()를 붙여서 넘파이 어레이로 핸들링해야됨

y_8k = librosa.resample(audioData.numpy(), orig_sr=sr, target_sr= 8000) #torch에서 바로 import 해서 tensor로 되어 있음 -> numpy 붙이기
ipd.Audio(y_8k, rate=8000)추가적으로 강의가 20년도 강의이다 보니 resample에 관한 파라미터가 바뀌었다.
기존에는 매개변수를 지정하지 않고 .resample(audioData.numpy(),sr,4000) 이렇게 사용한것 같은데 지금은 .resample(audioData.numpy(), orig_sr=sr, target_sr=4000) 이렇게 sr명을 지정해 줘야한다.
Q. sr=16000과 8000이 인지적으로 큰 차이가 없는데 학습시킬때 어떤차이가 있냐
그렇게 큰 차이가 나지는 않는다. 근데 sr을 큰 수로 해야 예측 성능이 조금이라도 더 좋아짐, 시간차이도 그렇게 크지도 않음
scipy.io의 librosa.load함수의 경우 파일이름을 인자로 받아서 sample rate와 data를 return 해준다. float32이고 sampling rate의 디폴트는 22050이다
sr, y = librosa.load('경로')+시각화할때 matplotlib과 librosa 패키지를 같이씀
잠깐 뛰어넘어서 sound reptresentation을 보자
ndarray에 있떤건 소리의amplitude (소리의 크기)이다
Normalization & Quantization

normalization
보통 -1,1사이에서 스케일링함
[정규화 코드]
audio_np = audioData.numpy()
normed_wav = audio_np / max(np.abs(audio_np))
ipd.Audio(normed_wav, rate =sr)Quantization
Quantization은 input을 받으면 바로 스펙트로그램으로 변형하기 때문에 잘 안하는데 큰 데이터 다룰 때 필요할 수 있다.
[양자화코드]
#quantization 하면 음질은 떨어지지만 light한 자료형이 된다.
Bit = 8
max_value = 2 ** (Bit-1)
quantized_8_wav = normed_wav * max_value
quantized_8_wav = np.round(quantized_8_wav).astype(int)
quantized_8_wav = np.clip(quantized_8_wav, -max_value, max_value-1)
ipd.Audio(quantized_8_wav, rate=sr)양자화가 되면 음원에 기계음이 생기게된다
소리는 amplitude가 전부일까? -> 아니다 다음을 살펴보자
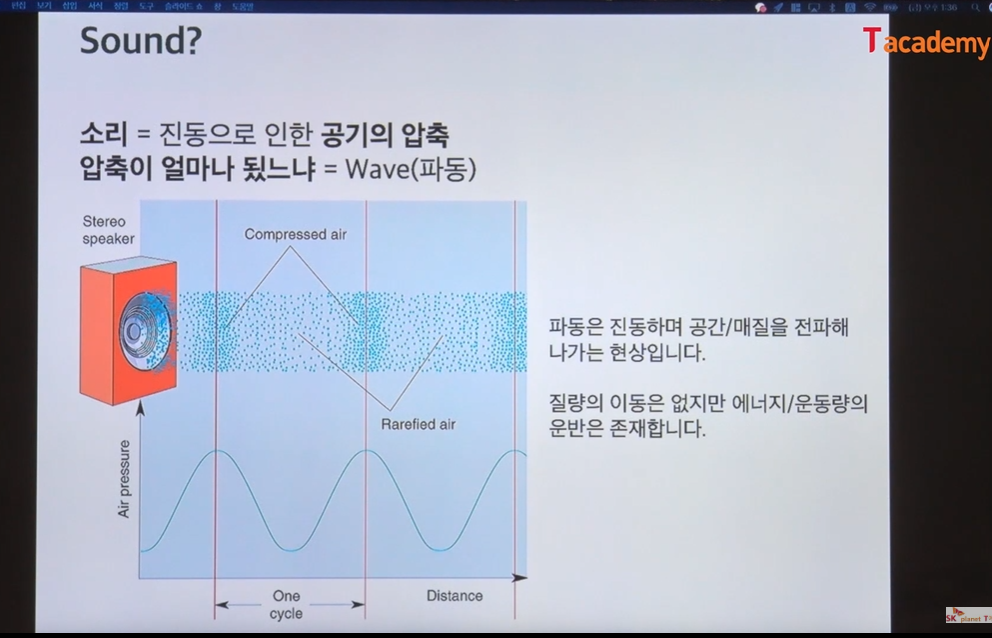
인간은 이러한 소리를 어떻게 인지할까?
소리 = 진동으로 인한 공기의 압축
압축이 얼마나 됬느냐 = WAVE(파동)

파동은 물리량인데 이걸로 아래 항목들을 얻을 수 있다.
Amplitude(Intensity):진폭
Frequency: 주파수
Phase(Degress of displacement) : 위상
물리음향
intensity: 소리 진폭의 세기
Frequencey:소리 떨림의 빠르기
Tone-Color: 소리파동의 모양
심리음향
Loudness: 소리의 크기
Pitch: 음정, 소리의 높낮이/ 진동수
Timbre:음색, 소리감각
=>결국 우리는 파동의 모양, 높낮이, 얼마나 빠른지 를 봐야됨
Frequency는 The number of compressed

Frequency의 단위는 Hertz를 사용하고 1hz는 1초에 몇번 진동하냐 이다.
주기와 주파수
주기(period): 파동이 한번 진동하는데 걸리는 시간, 또는 그 길이, 일반적으로 sin함수의 주기는 2pi/w이다
주파수(frequency): 1초동안의 진동 횟수이다.
air pressure 그래프를 주목하자
소리의 높낮이는 음원의 주파수에 의해 결정되고 주파수가 높으면 높은 소리가, 낮으면 낮은 소리가 난다. sr이 frequency와 연관 되어있다는걸 기억하자.
딥러닝 인풋으로 들가는건 amplitude랑 hz 이다.
complex wave
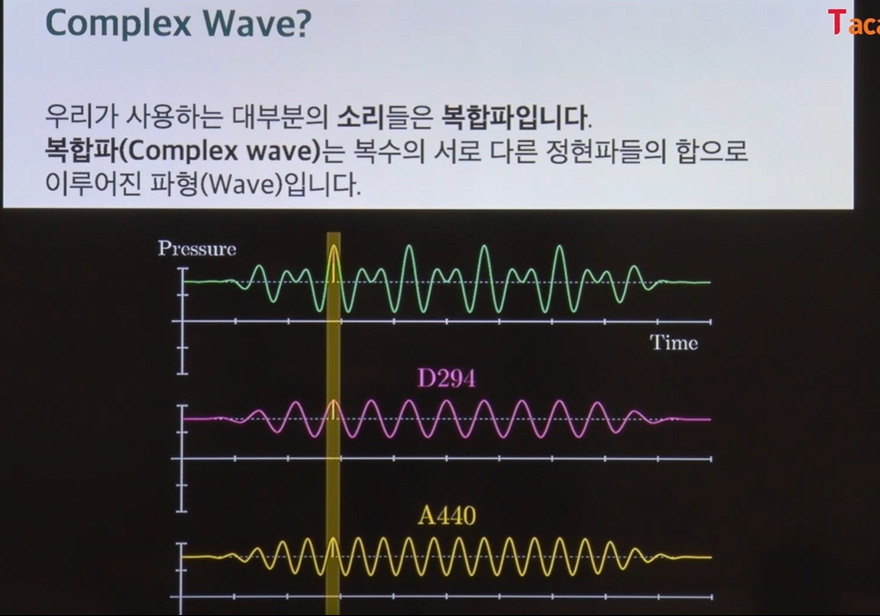
우리가 듣는 소리는 대부분 complex wave이다.
Complex wave는 복수의 서로 다른 정현파들의 합으로 이루어진 파형이다
정현파: 일종의 복소수 주기함수(따로 찾아보자 ㅠㅠ)


f=440이면 '라' 다
파라미터 수정하면서 테스트해봐라
그리고 두개정도 만든다음에 같은 시간으로 넣으면 length는 같으니 더해서 들어봐라
실제로 복합파가 정현파의 합으로 나타는걸 볼 수 있다.
그럼 두개의 정현파가 합쳐져서 두개 영역이 나오는거 확인가능하다.
=> 테스트 사진은 영상을 다 시청후에 올릴예정...
