librosa은 음악 및 오디오 분석을 돕기위해 만들어진 파이썬 패키지이다.
멜 스펙트로그램(mel spectrogram)을 설명하기 이전에 원형인 스펙트로그램(spectrogram)을 먼저 설명하겠다.
Spectrogram이란?
오디오의 데이터를 X축은 시간, Y축은 주파수, Z축은 강도에 맞게 바꿔주는 것이다. 이를 시각화 하면 아래와 같다.
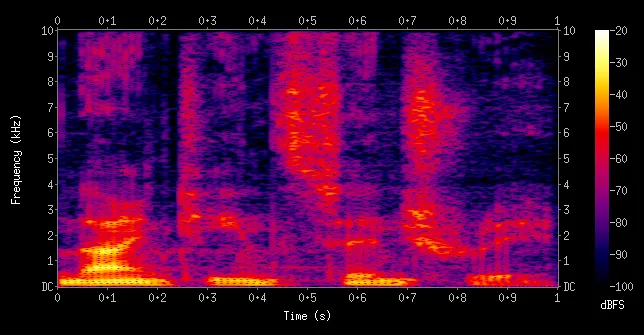 [출처: 나무위키]
[출처: 나무위키]
Mel Spectrogram이란?
멜 스펙트로그램은 스펙트로그램의 변형으로 주파수 축이 멜 척도로 변환된 것이다. 멜 척도는 인간의 귀가 저주파를 잘 인식한다는 점을 고려해 만들어진 척도이다. 따라서 멜 스펙트로그램은 저주파에서 더 높은 해상도를 제공하여
인간의 청각 특성을 더 잘 반영한다.
[사용코드]
코드 사용 예시이다
import librosa
audio, sr = librosa.load('경로', sr=None , mono=False)librosa.load: 시계열로 오디오를 로드하고 디코딩한다.
audio: 오디오의 초당 샘플이 벡터화 된 것이다.
audio.shape을 했을 때 (8,16000) 이면
8개의 채널을 가지고 있는 것이다.
sr: sampling rate(샘플링 속도)
시계열의 초당 샘플 수 이다. None일 때 원래 sr을 유지한다. (8,16000)에서 16000이 바로 sr에 해당한다.
mono: 단일 채널을 사용할지 여부이다. (default는 True)
mono를 True로 설정할 시 채널들의 데이터가 평균되어 하나의 데이터로 나온다.
mono를 False로 설정할 시 각 채널이 분리되어 array로 나온다.
채널이 정보가 중요한 경우는 False로 설정해서 나눠야한다.
이렇게 librosa.load를 통해 추출된 audio(y)와 sr은
melspectrogram의 매개변수로 사용된다

매개변수 설명
sr과 y는 위에서 설명했으므로 생략한다
n_mels: 멜 스펙트로그램에서 사용할 멜 필터 뱅크의 수,주파수 영역의 해상도를 결정하고 더 많을 수록 더 세밀한 주파수 정보를 얻는다
frames: 각 벡터가 포함할 연속적인 프레임 수 ,오디오의 시간적 해상도에 영향을 미치며 더 많은 프레임을 사용하면 더 긴 시간범위의 정보를 포함한다
n_fft: 고속 푸리에 변환(Fast Fourier Transform, FFT)의 윈도우 크기, 고속푸리에변환의 해상도를 결정한다.n_fft가 크면 더 세밀한 주파수 해상도를 얻을 수 있지만, 계산 비용이 증가하고 시간 해상도가 감소합니다. 즉, n_fft는 주파수 해상도와 시간 해상도 간의 트레이드오프를 제공합니다.
hop_length: 연속적인 프레임 간의 샘플 수,이는 오디오 신호에서 얼마나 많은 샘플을 건너뛰면서 FFT를 수행할지 결정합니다.작을수록 프레임겹침 증가,시간해상도 증가,데이터양 증가가 발생한다.
power: 멜 스펙트로그램을 계산할 때 사용할 파워 지수,각 스펙트럼 빈(bin)의 에너지를 스케일링하는 데 사용됩니다. power 값을 변경하면, 스펙트럼의 에너지 분포가 어떻게 스케일링되는지에 영향을 미칩니다. 예를 들어, power=1.0은 선형 스케일로, power=2.0은 파워 스케일로 계산됩니다.
이를 응용한 코드 리뷰는 다음 페이지에서 진행하겠다.
