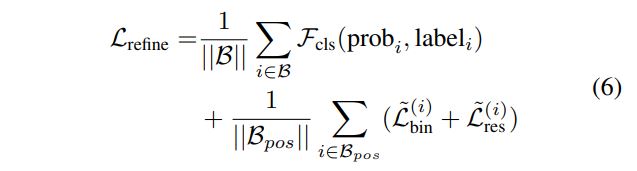0. Abstract
Point RCNN은 raw 3D Point Cloud로부터 3D object detection을 하도록 한다. (흔한 object detection처럼 stage1: 3D Proposal prediction → stage 2: Proposal Refinement의 과정을 거친다.)
- Stage 1: Bottom-up 3D proposal generation
- point cloud를 voxelize한다거나 BEV로 바꾸지 않고 raw point cloud를 그대로 전체 scene에서 배경과 객체 point를 segment함으로서 3D proposal을 generate하게 된다.
- Stage 2: Refining proposals in the canonical coordinates to obtain the final detection results
-
각 proposal의 pooled points를 canonical coordinate로 변형시킨다.
⇒ canonical coordinate는 정준 좌표라는 개념에서 물리학에서 사용하곤 하는데, 본 논문에서는 앞서 구한 box proposal의 중점을 원점으로 바꿔주면서 동시에 proposal 내의 point들의 좌표를 바꿔줌으로써 local spatial feature을 더 잘 학습하도록 하기 위함이라고 한다.
-
2단계에서 보통 하는 box refinement와 confidence score estimation을 위하여 stage1에서 학습한 point별 global semgmentic feature을 canonical coordinate와 combine한다.
-
그래서 결과적으로 proposal에 포함된 점의 feature을 만들기 위해서
- canonical coordinate로 변환한 좌표
- point의 reflection intensity
- stage 1에서 가져온 배경과 객체의 segmentation mask
- LiDAR 원점까지의 거리 (왜냐면 canonical transformation을 하여서 depth 정보를 잃었는데, LiDAR에서 멀리 떨어져 있으면 point가 매우 sparse한데 그 정보를 잃은 것이기 때문이다.)
위의 4가지 정보를 concatenate한 뒤에 fully-connected layer을 통과시킴으로서 인코딩을 한다.
-
1. Related Work
- 3D object detection from 2D images
- 3D와 2D bounding box사이의 geometry constraints를 leverage하였다.
- object들의 3D geometric information을 energy function으로 formulate해서 사전에 정의된 3D box에 가중 점수를 붙이는 방법도 있았다.
- 그러나 당연하게 depth정보가 없다보니 coarse한 3D detection만 가능하였다.
- 3D object detection form point clouds
- LiDAR로부터 얻을 수 있는 point cloud를 사용하는 방법이 많은데, BEV로 바꾸어서 2D CNN을 적용해 point의 feature을 얻는다거나 voxelize를 하여서 3D CNN을 거티는 경우도 있다.
- 그러나 BEV와 voxelization모두 data quantization을 하는 과정에서 정보의 손실이 많다보니 효과적이지 못하고, 3D CNN은 연산량이나 메모리를 많이 잡아먹는다. 이런 문제를 해결하기 위한 일환으로 이미지에 2D detector을 적용해 2D proposal을 구하고 각 RoI 영역에 그 부분의 point들을 PointNet layer에 넣어 3D box proposal을 구한다.(Frustum-PointNet)
Point RCNN은 point cloud로부터 직접적으로 3D proposal을 구한다. (segmentation mask를 사용해서!)
- Learning point cloud representations
- point cloud의 feautre을 어떻게 얻는지에 대해서는 voxelize해서 voxel의 feature로 나타내는등의 방법이 있지만, 제일 대표적인 것은 PointNet이다. 이 모델로 point cloud segmentation, classification을 위한 높은 퀄리티의 feature을 얻어낼 수 있었고, 나아가서 PointNet++에서는 set abstraction을 통해 receptive field의 크기도 늘리고 local structure정보도 확보할 수 있었다.
2. PointRCNN for Point Cloud 3D Detection
1. Bottom-up 3D Proposal Generation
- Learning point cloud representations
PointNet++의 경우에는 encoder-decoder처럼 point cloud space를 downsampling했다가 다시 upsampling하는 과정을 거친다. 따라서 downsampling-upsampling하는 과정에서 mutli-scale grouping이 가능하다.- 이 외에도 backbone으로
VoxelNet을 사용하는 것도 가능하다.
- Foreground point segnentation
- 전체 point들에서 foreground와 background을 segment하는 방법을 학습할 수 있기 때문에 더 point-wise feature을 정확하게 얻어 내는 것을 강제할 수 있다.
- 앞서 feature extraction을 위한 backbone에서 얻은 point-wise feature vector을 2개의 branch (Bin-based 3D Box Generation, Foreground Point Segmentation)에 넣어준다.
-
이때 Point Segmentation의 경우 foreground point가 background point에 비해서 훨씬 적기 때문에 Focal Loss를 사용한다.
-
-
Bin-based 3D bounding box generation
loss를 크게 localization loss, estimation loss, 그리고 로 나눌 수 있다.
- 축의 loss를 계산하기 위해서는 각 축을 discrete한 bin으로 쪼개야 한다. 우선 어떤 bin에 속하는지 찾은 뒤에 bin 내에서의 미세조정을 하게 된다.
- 즉,
bin based classification이란 물체의 중심이 현재 연산중인 foreground point를 중심으로 하는 grid상에서 어디에 존재하는지를 classify 하는 것이고,residual regression은 선택된 bin안에서의 정확한 위치를 맞추는 것이다. - 축의 경우에는 축에 비해서 적은 범위 내에서 변동을 하기 때문에 단순히
directly regressed parameter을 사용한다.
- 역시나
L1 Loss를 사용한다. - 나중에 refine을 할 것이기 때문에 우선은 각 class별 물체의 평균 크기에 회귀하도록 한다.
- 역시나
- , 즉 를 총 개로 나누어서 (여기선 12)각 각도의 bin안에서의 residual regression을 하게 된다. (축과 마찬가지로 bin classification도 한다.)
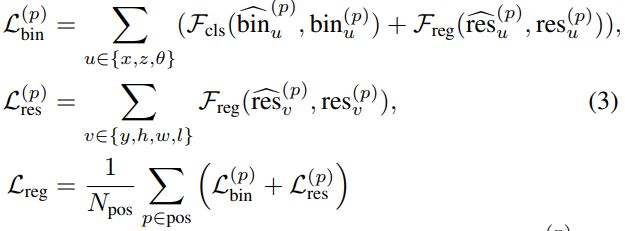
2. Point Cloud Region Pooling
3D bounding box proposal을 구한 뒤에, 예측하는 box location 정보를 refine하고자 한다. 이를 위해서 각 proposal영역의 specific feature을 얻어야 하기 때문에 stage 1에서 구한 point wise feature을 사용하고자 한다.
- 처음에 구했었던 3D box proposal은 로 표현할 수 있다. (LiDAR coordinate system에 의해서) 여기서 는 object center location, 은 object의 크기이고, 는 BEV에서 볼때의 object의 orientation이다.
- 그러나 이 단계에서는 box enlarging을 위해서 box proposal을 라고 바꿔서 나타냄으로서 context로부터의 추가 정보를 encoding라기로 한다.
- 모든 point에 대해서 새롭게 enlarge한 box의 내부에 있다면 해당 box의 refinement를 위해서 feature을 사용하게 된다.
- 여기서 feature이라 하면
-
3D point coordinate
-
laser reflection intensity
-
predicted segmentation mask (배경과 객체 영역중 구분하기 위해)
-
C-dimensional learned point feature representation (3D Backbone을 통해)
이다.
-
- 여기서 feature이라 하면
3. Canonical 3D Bounding Box Refinement
-
Canonical transformation
stage 1에서 얻은 high-recall box proposal을 효과적으로 사용하기 위해서 3D proposal의 canonical coordinate system으로 proposal내부에 있는 point를 transform한다.
-
Feature Learning for box proposal refinement
- 앞선 canonical transformation으로 depth정보를 잃게 된다. 그런데 LiDAR 센서로 측정한 경우에 멀리 있는, 즉 depth가 크면 point가 적을수 밖에 없다. 따라서 proposed box와 (변경 전) 원점 사이의 거리를 1차원 상수로 추가해 준다.
- 이렇게 3정보 (segmentation map, (x,y,z), depth)를 concatenate하여 Fully connected layer을 거침으로서 stage 1의 point net에서 point-wise로 얻은 feature vector의 차원 크기로 바꿔준다. 이렇게 얻은 local feature과 global structure feature인 stage 1의 feature vector을 다시 concat해서 PointNet++를 통과하게 하여 다시금 discriminative feature vector을 얻도록 한다.
- 이렇게 얻은 feature vector은
confidence prediction과box refinement를 수행하는 network에 들어가게 된다.
-
Losses for box proposal refinement
- 각 proposal마다 ground truth와의 IoU를 계산해서 0.55가 넘는 ground truth box를 해당 proposal의 target으로 지정해 준다.
confidence prediction에서는 GT가 할당된 proposal을 positive, 아닌 애를 negative로 설정해Cross Entropy Loss를 계산한다.box refinement는 GT box가 할당된 proposal에 대해서만 수행한다.- center refinement는 proposal의 center에서 GT box center로의 regression을 stage 1에서의 bin based localization과 동일한 방법으로, search range 만 줄여서 계산한다.
- 도 동일하게 average object size에 대한 residual을 regreission한다.
- orientation은 각도 residual을 로 한정하여 bin-based regression을 수행한다.
- 최종적으로는 BEV IoU threshold 0.01로 oriented NMS를 수행하여 3D Bounding box를 만든다.
- 이때 NMS는 soft NMS로, IoU threshold를 명확히 정하는 것이 어렵다. 왜냐면 임계값에 따라서 mAP score이 낮아지는 경우가 있기 때문이다.
- confidence score이 제일 높은 proposal과 다른 proposal들의 IoU를 계산해서 threshold(여기선 001) 보다 크면 점수를 로 바꿔준다. 즉, score을 낮추는 것이다. 결과적으로 일정 비율 이상으로 겹쳐진 proposal의 confidence를 0으로 만들어 제거하지 않고 confidence를 줄여서 유지하는 것이다.