[논문 공부] CTPN: Detecting Text in Natural Image with Connectionist Text Proposal Network

Abstract
- natural scene image에서 text localization을 하기 위해서는 특히나 주변 배경 무늬나 다양한 글씨체, image distortion등으로 인한 어려움을 극복할 수 있어야 한다.
- text localization(=detection)을 위해서는 고전적인 알고리즘과 딥러닝 기반의 알고리즘이 모두 존재하는데,
- 고전적인 알고리즘
- 이미지 내에서 문자 단위로 검출을 하고 각각의 검출된 component별로 text인지 아닌지를 구분하도록 한다.
- 이렇게 한 뒤에도 component를 조합을 해서 text line construction을 해야 한다.
- 딥러닝 기반의 알고리즘
- 위의 고전적인 알고리즘과 달리 이미지를 넣어주면 그대로 text box를 도출하는 과정을 end-to-end로 학습 할수 있다.
- 물론
Faster RCNN과 같이 object detection task에 사용된 모델을 응용한 시도도 있었으나, 객체나 물체는 일종의 "덩어리"느낌으로 감지를 한다면 문자의 경우에는 (1) 문자가 맞는지의 여부 (2) 이어져 있는 sequence 감지 등 더 accurate한 localization을 필요로 하게 된다.
Introduction
- 논문의 저자들은
CTPN: Connectionist Text Proposal Network라는 모델을 제안한다. 사실 이 논문은 2016년에 공개 되었기 때문에 이후에 나온 arbitrary text 를 감지하는데 효과적인EAST,CRAFT등과 같은 논문과 달리 horizontal text인식에 강력하다.
- text detection -> localizing a sequence of fine scale text proposals
- convolutional feature map에서의 sequential text proposal을 GRU,BILSTM등의 sequential model을 사용해서 연결한다.
- 추가적인 post refinement없이도 multi scale, multi lingual text를 end-to-end로 학습 가능한 모델로 검출해 낸다.
Connectionist Text Proposal Network
(1) Text Detection
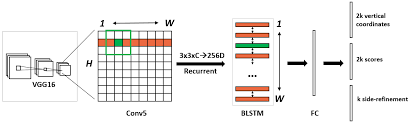
- 사실 CTPN모델의 구조는 Faster R-CNN과 매우 유사하지만 추가적인 LSTM layer이 있다는 점에서 차이가 있다. 이와 동시에 Region Proposal Network와는 유사하게, 상이한 크기의 input image를 입력으로 받을 수 있다. Convolutional model (논문에서는 VGG16)의 5번째 layer의 output feature map에 small window를 slide해서 sequence를 얻어낸다.
- 서비스에 적용할 OCR Text Detection 모델을 개발해야하기 때문에 해당 논문을 읽었었는데, 아무래도 원본 이미지를 그대로 입력으로 받을 수 있다는 점이 좋았다.
-
VGG16의 마지막 convolutional layer의 output feature map에
Conv2d 3x3을 적용한다. feature map의 크기는 input image의 크기에 따라 다르지만,stride = 16 receptive field = 228로 고정되어 있다. -
원래 sliding window 알고리즘을 사용한다고 하면 각각의 서로 다른 크기의 window는 각각에 맞는 크기의 object를 detect하도록 한다. 이렇게 여러 크기의 window를 통해서 multi scale detection이 가능했었다. 하지만 CTPN 모델에서 사용하는
anchor regression mechanism을 통해서 single window만으로도 다수의 flexible anchor에 의해서 다양한 scale이나 aspect ratio를 갖는 object predict가 가능하다.--> 논문에서 주장하는 text와 object의 결정적인 차이는 text가 뚜렷한 boundary가 존재하지 않는다는 것이다. 다른 물체의 일부를 문자로 착각할수도 있고, text sequence는 stroke, character, word등 분할이 여러가지로 가능하다. -
그래서 논문의 저자들은 Region Proposal Network를 사용하게 되면 horizontal 방향의 text box를 예측하기가 힘들며, 문자 하나하나가 사실은 분리되어 있기 때문에 sequence의 시작과 끝을 찾는데에 어려움을 갖는다는 점에 집중한다.
--> 논문의 저자들은 16px크기의 text proposal 각각이 character의 일부, 혹은 다수의 character을 포함하고 있을 것이라고 한다. 따라서 예측하기 어려운 horizontal location은 고정을 하고 각각의 proposal의 vertical location을 예측하도록 모델을 설계한다. - 결과적으로 CTPN은 text 영역의 Y_min, Y_max을 predict하는 것이다. -
RPN이 4개(=X_min,Y_min, X_max, Y_max)를 예측하는 것과 달리 CTPN은 Y_min, Y_max만을 predict하게 되어서 search space도 줄일 수 있다.
(2) HOW IT WORKS
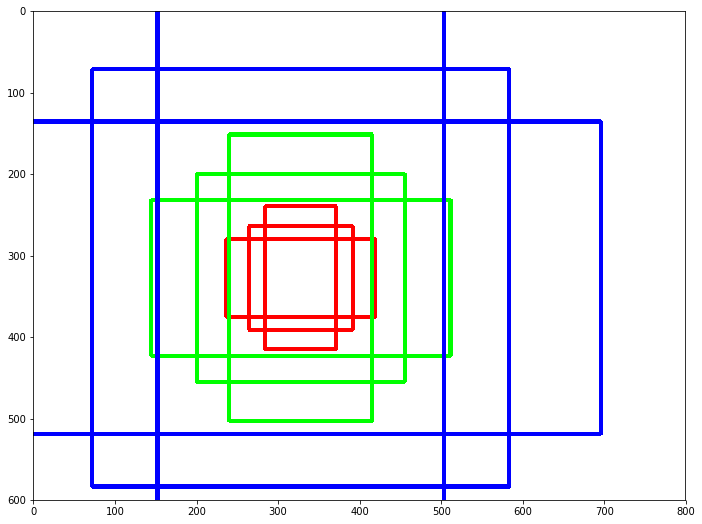
위와 같이 horizontal, vertical 방향 모두에 대해서 다른 값을 갖는 anchor box를 예측하는 RPN과 달리 CTPN은 하나의 Region proposal에서 총 10개의, 높이가 11~273px까지 다양하다. Region proposal box의 가로길이는 16, 세로 길이는 h이기 때문에 원래 유용한 receptive field의 크기로 간주되는 228x228에 비해서 연산량이 적게 필요하다.
- start_x, end_x는 고정 (16px의 가로 길이를 갖고 bounding box의 중심점의 y축 좌표값과 height를 예측하도록 한다.)
-
RPN도 역시나 input으로 pretrained CNN 모델의 convolutional layer의 output feature map이다. 그런데 Text는 순서가 있는 sequence이기 때문에 이전의 hidden state에 대한 정보도 저장하며, backpropagation이 잘 되는 LSTM layer을 사용하고 이 256D의 output
-
감지된 text proposal영역은 text score > 0.7인 영역에 대해서 non-maximum suppression을 사용해서 모델의 output을 통해서 구해진다.
