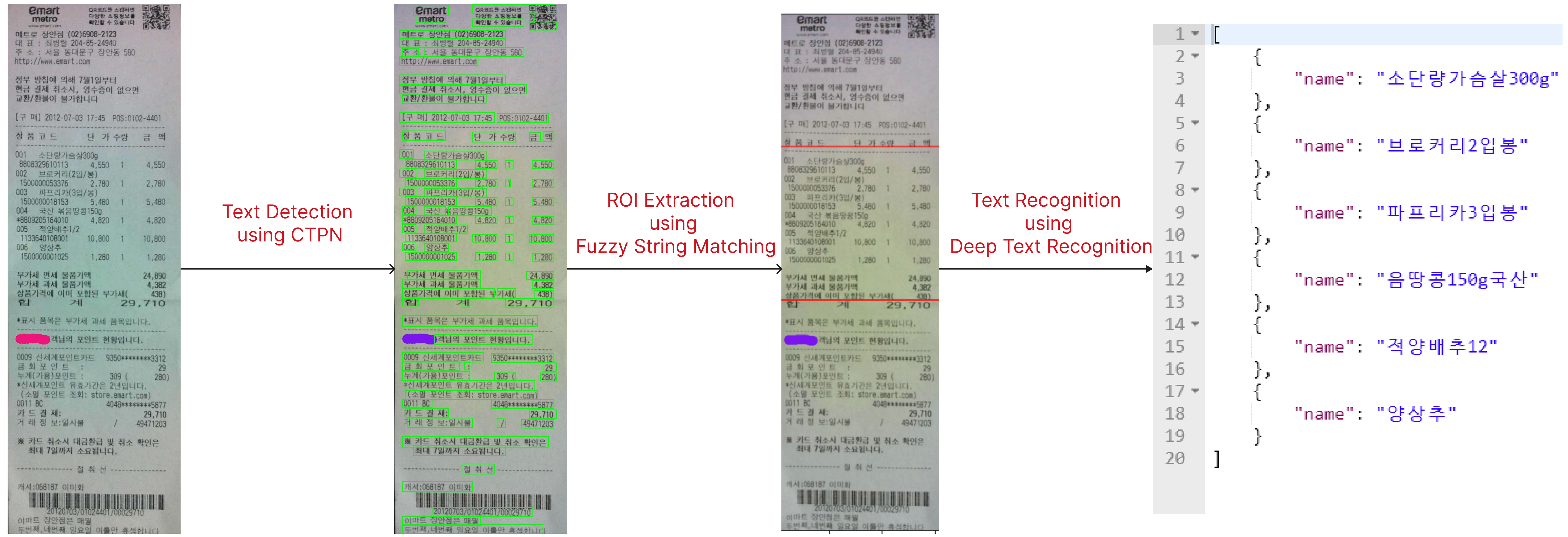
Dataset
- 사용할 데이터의 source: AIHub의 인쇄체 데이터셋 (syllable, word, sentence) + AIHub의 야외 촬영 이미지 데이터셋 (가로 간판만 사용)
{'annotations': [{'bbox': [406, 659, 1082, 246],
'id': 1,
'text': '치유하는 교회',
'image_id': 1},
{'bbox': [97, 682, 298, 184], 'id': 2, 'text': 'xxx', 'image_id': 1}],
'cropLabels': [],
'images': [{'file_name': '간판_가로형간판_000990.jpg',
'date_created': '20210109',
'width': 1600,
'id': 1,
'height': 1200}],
'info': {'date_created': '20210111',
'name': '간판_가로형간판_000990',
'description': ''},
'metadata': [{'area': '수도권',
'wordfont': '활자체',
'outline': '상',
'illuminance': '중간',
'wordsize': '소',
'light': '간접광',
'wordconnection': '빈공간으로나뉨',
'subclass': '가로형간판',
'weather': '맑음',
'device': '스마트폰',
'wordcolor': '단색',
'class': '실외간판',
'wordorientation': '가로'}]}'annotations': [{'attributes': {'font': '만화진흥원',
'type': '글자(음절)',
'is_aug': False},
'id': '00000000',
'image_id': '00000000',
'text': '궶'},- 왼쪽과 오른쪽의
json예시를 통해 어떤 구조로 각각의 이미지당 text와 bounding box의 정보를 알아내는지 확인이 가능하다. - 사실 이미지 파일의 경로와 정답 라벨 파일의 경로가
csv파일 같은 형태로 저장이 되어 있었다면 사용하기에 편했을수도 있었을 것이라고 생각한다. - 이미지에 어떤
transformation을 적용해서 실제 영수증 이미지가 지저분하거나 해상도가 낮은 등의 문제를 해결할 수 있을지 고민이 되었었다.
Model Configurations
-
1차 시도
- Hangul Net논문에 나와 있는 그대로의 설정을 사용하였다.
- 이미지는
(32, 128)의 크기로 resize를 하였고ResNet45의 의 크기는 로 정하였다. (그냉 논문 설정 그대로이다.) - 그리고
Attentional Decoder을 위한Mini-UNet의 경우에는 이렇게 중간 channel크기는 로 정하였다. Position Encoding은 그냥 순서대로 나열을 해서 그대로 더해준다. 그리고 원래는query에 더해주거나query와 key의 을 수행한 결과에 position vector을 더해주지만 이Hangul Net은 그냥 position encoding이 query 자체로 사용이 된다.
-
2차 시도
- 나중에 실제 영수증 데이터가 crop된 text의 영역이 더 클수도 있고, 글자의 수도 많을 수 있기 때문에 이미지의 resize 크기를
(64, 256)으로 늘리면서 동시에 수렴을 할수 있도록 하기 위해서 모델의 을256으로 바꿔 보았다. - 결과: 오히려 loss가 더 줄지를 않았다. 사실 생각해보면 말이 안될수 밖에 없는게
ResTransformer의 output으로[Batch Size, 256, 16 x 64]의 크기가 나오게 되고 이를
- 나중에 실제 영수증 데이터가 crop된 text의 영역이 더 클수도 있고, 글자의 수도 많을 수 있기 때문에 이미지의 resize 크기를
-
3차 시도
- 원래는
AIHub 데이터의한글 인쇄체 데이터를 사용해서 학습을 진행하고 있었다. 이유는 흰 문서 종이에 검은색 글끼로만 이루어진 해당 데이터셋이 제일 현재 서비스의 타겟이 되는 영수증의 데이터 형태와 제일 비슷하다고 생각했기 때문이다. 하지만 결과적으로는 전혀 수렴을 할 생각을 하지 않았으며, 그 이유가 모델의 학습해야하는 parameter의 수가 너무 많기 때문이라면 앞선 2차 시도가 잘 되었어야 했다. 하지만 그렇지 않았기 때문에 모델이 AIHub의 야외 촬영 이미지 같이 글씨가 좀 두꼐감이 있는(?) 형태여야 잘되는 것이라고 판단을 하였다.- 실제 논문의 저자들은
AIHub의 야외 촬영 한글 이미지를 사용하였기 때문에 그 해당 데이터셋으로 학습을 해보기로 한다. - 모든 나머지 설정은 논문과 동일하게 가도록 한다.
- 실제 논문의 저자들은
- 혹시나
Position Encoding부분에 문제가 있을까 하여 시각화도 해보고 다시 구해 보았는데 position embedding vector의 경우에는 이 모델에서Max Sequence Length, 즉 전체 가능한 초성, 중성, 종성의 개수인데 만약 으로 설정한거하면 개의 음절로 구성되어 있다는 뜻이다.- 따라서 각 마다 위치의 정보를 알게 해서 매 순간마다 첫번째
character위치에 집중하라는 의미이다. 그래서 이 character은 1번째이고, 그러니까 초성자리에 집중해라..! 뭐 이런 의미이다.
- 따라서 각 마다 위치의 정보를 알게 해서 매 순간마다 첫번째
- 또, 수럼이 되기 위한 처리 방법들을 찾아 보았는데
- 모델이 너무 heavy 한건 아닌지…
Dropout을 추가하거나Dimension을 줄여보자 (근데Transformer을 scratch부터 학습 시키려면 parameter의 수가 많을수록 수렴속도가 빠르고, 예측 정확도도 높아진다. → 결국Transformer은 연산량에 비례한, 매우 비효율적인 모델이 아닌지..) Data Normalization- 또 실제 데이터 이미지에 비해서 를 위한 크기가
(32, 128)로 너무 가로 너비가 작았기 때문에(32, 192)로 크기를 키워서 사용하기로 하였다.
- 모델이 너무 heavy 한건 아닌지…
- 결과:
-
Loss값이 계속 일정하다가 을 해 주니 드디어 손실함수가 감소하면서 수렴하는 듯 보였다. 이때 Mean, STD값은 직접 구하여 사용을 했고,
MEAN: [0.5,0.1,0.4] STD: [0.3,0.5,0.3] ## 야외 촬영 데이터셋
-
Tanh 사용해야 할 떄
MEAN: [0.5,0.5,0.5] STD: [0.5,0.5,0.5] ## 한글 인쇄체 데이터셋 -
ReLU 사용해야 할 때
MEAN: [0.0,0.0,0.0] STD: [1.0,1.0,1.0] ## 한글 인쇄체 데이터→ 위와 같은 평균과 표준편차 값이 적절했다. → `STD, MEAN`을 바꾸면 수정해야 하는 부분
[resnet.py](http://resnet.py)[transformer.py](http://transformer.py)[encoder.py](http://encoder.py)[decoder.py](http://decoder.py)
-
- 원래는
-
4차 시도
AIHub의 인쇄체 데이터셋으로 학습을 시키는것이 영수증 OCR을 해야 하는 졸업 프로젝트의 주제와 맞는 것으로 판단이 되었다.Adam,SGD + Momentum을 optimizer로 주로 사용을 하는데, 각각에 맞는 최적의 가 있었다. 우선 모델 자체가 너무 큰 학습률에는 잘 수렴을 하지 않기 때문에Adam기준으로는 를 사용하고,SGD기준으로는 정도에서 시작하는 것이 적당했다.- 그래서
printed_data.yaml파일을 사용해서 학습을 시켰고, loss function이 감소하지 않는 상황을 해결하기 위해서 미리 학습 코드 등에 변화를 주었다.-
Adamoptimizer 대신에SGDoptimizer으로 바꿔 사용하기 -
Cross Entropy Loss를 계산하기 전에Log Softmax를 예측값에 적용하고 있는건 아닌지 확인하기 -
더 작은 learning rate를 사용하거나 학습중에 learning rate가 자동적으로 감소할 수 있도록
learning rate scheduler을 사용해 본다.Cross Entropy loss is not decreasing
⇒ 위의 사이트에서 보면 loss가 거의 랜덤하게 생성이 되고 학습이 되지 않는 local minima에 빠진 상황이라고 한다. 이를 확인하기 위해서 model parameter을 뽑아 보았다.
What’s actually happening: negative parameters and ReLU activation, altogether cause the outputs of the middle layers to be all zeros, which means the parameters’ gradients become zero too (think about the chain rule). That’s why the parameters stop upgrading and the output is just a random guess. In this case, the bias of the last fully connected layers is the only parameter tensor that could have a “normal” gradient (which means not all zeros), so it gets updated every batch, causing the small ups and downs.
Therefore, one of the main solutions to this problem is to use a smaller learning rate so that our parameters don’t easily end up in such an “extreme” or “remote” area in the parameters space.
-
- 어쨌든 나도 학습 시키면서 loss function이
1.60xx ~ 1.66xx사이를 왔다 갔다하는 LOCAL MINIMA에 빠진게 확실했다.
⇒ 우선 현재 사용하는 모델 구조가 데이터 학습에 적합한지 판단하기 위해서 작은 데이터셋에 대해서 OVERFITTING이 되는지 판단해 보라고 했었다.
- 그리고 역시나 우리가 학습하고자 하는 바가 target label에 잘 반영이 되어있는가 도 당연히 너무나 중요한 부분이다. 그래서 이부분을 다시 확인했더니 이상하게도 종성이 비어있는 경우에 None, 즉 공백으로 나타나지 않고 그냥 바로 다음 글자로 넘어가게
Hangul Label Encoder이 작동하고 있음을 확인할 수 있었다.- 이 부분을 올바르게 수정하기 위해서는
jamo_utils/split_syllables부분에서None을 padding하기 위해서 ‘ ‘, 즉 공백을 용하겠다고 바꿔 놓았다.
- 이 부분을 올바르게 수정하기 위해서는
-
5차 시도
- 이쯤 되면 코드를 제대로 짠것이 맞나?????? 하는 의문을 갖게 된다. 뭔가 동작을 제대로 하지 않는 것 같아 모듈별로 한번씩 짚고 넘어가기로 한다.
- 또, 논문에선 어떤
Loss Function을 사용하였는지 명시하지 않았다. 단순Cross Entropy로 하진 않았을 것 같다는 의심이 든다. - 혹시나 초성은 초성에 해당하는 character class, 중성은 중성에, 종성은 종성에 각각 대응되는 prediction을 하지 않는다면 penalty를 주는 방법을 선택하였을 수도 있을 것이다.
- 또, 논문에선 어떤
layer 수,image shape,optimizer, learning rate, batch size, loss function, normalization, activation function,등에도 variation을 적용하고target label도 역시나 올바르게 바꾸었지만 ⇒풺쪦쮒캬 퀴 ㅋ이런 결과만 어떤 input에도 동일하게 만들어 내고 있음을 확인할 수 있었다.- 이런 문제가 나만 겪는 문제는 아닐 수 도 있다. 보통 이런 경우는 network is not complex enough라고 한다. input vector과 output vector 간의 복잡한 관계성을 찾아낼 수 없는 것이다. 따라서 어찌 보면 마지만 output layer이 dataset의 모든 평균 vector에 수렴하는 상황인 것이다.
⇒ 이 문제를 해결하기 위해 다음과 같은 해결책이 존재한다.
- input preprocessing을 한다 (예를 들면 PCA)
- Layer들을 시각화 해 보자. 한 layer이 주구장창 같은 vector만을 내뱉고 있을 수도 있다. → 결과적으로 higher level neuron에 문제가 되는 것이다.
- Learning rate를 줄여보자
- Batch size를 줄여보자
- Layer을 늘려보자
- 모델이 학습하고 있는지부터 확인해보자. (그냥 random noise를 데이터랍시고 넣어주었을때 모델 loss가 줄고 있으면 안된다.)
- 이쯤 되면 코드를 제대로 짠것이 맞나?????? 하는 의문을 갖게 된다. 뭔가 동작을 제대로 하지 않는 것 같아 모듈별로 한번씩 짚고 넘어가기로 한다.
DEBUGGING THE MODEL
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
attention_decoder.unet.k_encoder.0.1.weight | Parameter containing:
tensor([1.0055, 0.9974, 0.9960, 1.0049, 1.0022, 1.0069, 0.9943, 1.0026, 0.9984,
1.0000, 1.0042, 1.0031, 1.0004, 1.0007, 0.9994, 1.0060, 0.9934, 1.0099,
0.9987, 0.9994, 1.0120, 0.9920, 1.0005, 0.9988, 0.9982, 1.0117, 1.0052,
1.0032, 0.9991, 0.9951, 1.0063, 1.0068, 1.0062, 1.0003, 1.0105, 1.0059,
1.0052, 1.0144, 1.0005, 1.0002, 0.9998, 1.0077, 1.0029, 1.0072, 0.9958,
1.0031, 1.0033, 1.0014, 1.0164, 0.9976, 1.0083, 0.9948, 1.0045, 1.0057,
1.0010, 1.0089, 1.0008, 0.9998, 1.0028, 1.0005, 0.9960, 0.9955, 1.0029,
1.0044], device='cuda:6', requires_grad=True)
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
attention_decoder.unet.k_encoder.1.1.weight | Parameter containing:
tensor([0.9907, 0.9972, 0.9957, 1.0002, 1.0062, 1.0007, 1.0069, 0.9949, 1.0019,
1.0000, 1.0024, 0.9978, 1.0000, 0.9948, 1.0043, 0.9982, 1.0010, 0.9964,
0.9985, 1.0013, 1.0002, 0.9988, 0.9995, 0.9994, 1.0077, 0.9988, 1.0011,
1.0016, 1.0063, 1.0025, 0.9962, 0.9972, 0.9984, 0.9982, 1.0011, 1.0009,
0.9953, 1.0042, 1.0052, 1.0005, 0.9930, 0.9998, 1.0019, 1.0030, 0.9955,
0.9998, 1.0015, 1.0031, 1.0059, 0.9946, 0.9989, 0.9973, 0.9977, 0.9984,
0.9966, 1.0013, 1.0001, 1.0010, 1.0005, 1.0021, 0.9995, 0.9990, 1.0033,
0.9969], device='cuda:6', requires_grad=True)
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
attention_decoder.unet.k_encoder.2.1.weight | Parameter containing:
tensor([0.9995, 0.9965, 0.9992, 1.0018, 0.9991, 0.9954, 0.9964, 1.0009, 1.0037,
1.0010, 1.0009, 0.9957, 1.0016, 0.9998, 0.9973, 1.0050, 1.0004, 1.0012,
1.0020, 1.0002, 0.9980, 1.0054, 1.0010, 1.0014, 1.0005, 1.0013, 0.9991,
0.9968, 0.9987, 0.9990, 1.0021, 0.9997, 0.9994, 0.9987, 0.9988, 1.0028,
1.0029, 1.0000, 0.9983, 0.9989, 1.0009, 1.0036, 0.9991, 1.0033, 1.0005,
0.9951, 1.0006, 1.0037, 0.9995, 0.9997, 0.9955, 1.0029, 1.0004, 0.9999,
0.9982, 0.9976, 0.9999, 0.9972, 1.0022, 1.0025, 0.9990, 0.9967, 1.0012,
1.0009], device='cuda:6', requires_grad=True)
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
attention_decoder.unet.k_encoder.3.1.weight | Parameter containing:
tensor([0.9976, 0.9895, 1.0010, 0.9998, 1.0004, 1.0003, 1.0002, 1.0032, 1.0028,
0.9948, 1.0011, 0.9992, 1.0000, 1.0053, 1.0031, 1.0015, 0.9976, 0.9976,
0.9986, 1.0038, 0.9949, 0.9932, 1.0040, 1.0019, 0.9986, 0.9954, 0.9972,
1.0002, 1.0025, 0.9966, 1.0036, 0.9991, 0.9994, 1.0017, 1.0059, 0.9950,
1.0036, 1.0011, 0.9973, 1.0004, 0.9989, 1.0016, 1.0032, 1.0011, 1.0004,
0.9993, 1.0056, 0.9987, 0.9970, 0.9968, 0.9982, 1.0066, 1.0024, 0.9996,
1.0034, 0.9957, 1.0021, 0.9993, 0.9994, 0.9951, 1.0007, 0.9960, 1.0044,
1.0050], device='cuda:6', requires_grad=True)
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------→ 위와 같이 Mini UNet의 parameter이 저렇게 거의 다 1이라는 것을 확인할 수 있었다.
결론적으로는 아래와 같이 성공적으로 OCR FLOW를 완성시킬 수 있었다.