2022.7.26 차량,번호판 오브젝트 디텍션 프로젝트 7일차
실행결과




detect.py를 수정해서 이미지와 bbox값을 가진 txt, bbox에 따라 크롭된 차량과 번호판 이미지를 저장하도록 하였다.
학습한내용
from PIL import Image
import pytesseract
print(pytesseract.image_to_string(Image.open('./yolov5/runs/detect/exp6/crops/plate/img_2.jpg')))
print(pytesseract.image_to_string(Image.open('./yolov5/runs/detect/exp6/crops/plate/img_2.jpg'), lang='kor',config='--psm 4 --oem 3'))
실행결과
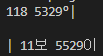
tesseract ocr을 이용해 기본과 한글로 인식하였을때 각각 다음과같고
정답은 11보 5329로 정확도가 아직 낮은 모습을 보인다.
학습한내용
import io
import time
import sys
import numpy as np
import platform
from PIL import ImageFont, ImageDraw, Image
from matplotlib import pyplot as plt
import cv2
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from msrest.authentication import CognitiveServicesCredentials
def plt_imshow(title='image', img=None, figsize=(8 ,5)):
plt.figure(figsize=figsize)
if type(img) == list:
if type(title) == list:
titles = title
else:
titles = []
for i in range(len(img)):
titles.append(title)
for i in range(len(img)):
if len(img[i].shape) <= 2:
rgbImg = cv2.cvtColor(img[i], cv2.COLOR_GRAY2RGB)
else:
rgbImg = cv2.cvtColor(img[i], cv2.COLOR_BGR2RGB)
plt.subplot(1, len(img), i + 1), plt.imshow(rgbImg)
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
else:
if len(img.shape) < 3:
rgbImg = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
else:
rgbImg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(rgbImg)
plt.title(title)
plt.xticks([]), plt.yticks([])
plt.show()
def put_text(image, text, x, y, color=(0, 255, 0), font_size=22):
if type(image) == np.ndarray:
color_coverted = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = Image.fromarray(color_coverted)
if platform.system() == 'Darwin':
font = 'AppleGothic.ttf'
elif platform.system() == 'Windows':
font = 'malgun.ttf'
image_font = ImageFont.truetype(font, font_size)
font = ImageFont.load_default()
draw = ImageDraw.Draw(image)
draw.text((x, y), text, font=image_font, fill=color)
numpy_image = np.array(image)
opencv_image = cv2.cvtColor(numpy_image, cv2.COLOR_RGB2BGR)
return opencv_image
SUBSCRIPTION_KEY = "8d06cd8651fd43f2bf392c71478a6d67"
ENDPOINT_URL = "https://platestr.cognitiveservices.azure.com/"
computervision_client = ComputerVisionClient(ENDPOINT_URL, CognitiveServicesCredentials(SUBSCRIPTION_KEY))
path = './yolov5/runs/detect/exp6/crops/plate/img_4.jpg'
with open(path,'rb') as f:
data=f.read()
sbuf = io.BytesIO(data)
response = computervision_client.read_in_stream(sbuf, raw=True)
operationLocation = response.headers["Operation-Location"]
operationID = operationLocation.split("/")[-1]
while True:
read_result = computervision_client.get_read_result(operationID)
if read_result.status not in ['notStarted', 'running']:
break
time.sleep(1)
if read_result.status == OperationStatusCodes.succeeded:
img = cv2.imread(path)
roi_img = img.copy()
for text_result in read_result.analyze_result.read_results:
for line in text_result.lines:
text = line.text
box = list(map(int, line.bounding_box))
(tlX, tlY, trX, trY, brX, brY, blX, blY) = box
pts = ((tlX, tlY), (trX, trY), (brX, brY), (blX, blY))
topLeft = pts[0]
topRight = pts[1]
bottomRight = pts[2]
bottomLeft = pts[3]
cv2.line(roi_img, topLeft, topRight, (0,255,0), 2)
cv2.line(roi_img, topRight, bottomRight, (0,255,0), 2)
cv2.line(roi_img, bottomRight, bottomLeft, (0,255,0), 2)
cv2.line(roi_img, bottomLeft, topLeft, (0,255,0), 2)
roi_img = put_text(roi_img, text, topLeft[0], topLeft[1] - 10, font_size=30)
print(text)
plt_imshow(["Original", "ROI"], [img, roi_img], figsize=(16, 10))
# import cv2, io, time
# from PIL import Image
# path = './test_image.jpg'
# img_cv = cv2.imread(path)
# img_pil = Image.open(path)
# binary_cv = cv2.imencode('.PNG', img_cv)[1].tobytes()
# output = io.BytesIO()
# img_pil.save(output, 'PNG')
# binary_pil = output.getvalue()실행결과
azure ocr 을 이용한 결과 정확하게 읽어낸다.

학습한 내용 중 어려웠던 점 또는 해결못한 것들
해결방법 작성
학습 소감
읽은 ocr결과로 어떤 정보를 제공하는게 좋을지 고민된다.
