학습내용
tesseract ocr 정확도 향상을 위한 grayscale과 gaussian blur 처리
azure ocr, tesseract, eazyocr 결과 출력 및 비교
import os
import warnings
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
warnings.filterwarnings("ignore", category=UserWarning)
import torch
from PIL import Image,ImageFilter
import easyocr
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract'
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from azure.cognitiveservices.vision.computervision.models import VisualFeatureTypes
from msrest.authentication import CognitiveServicesCredentials
import time
path = './crops'
def easy_ocr (path) :
reader = easyocr.Reader(['ko', 'en'], gpu=False)
result = reader.readtext(path)
read_result = result[0][1]
read_confid = int(round(result[0][2], 2) * 100)
print("===== Crop Image OCR Read - Easy ======")
print(f'Easy OCR 결과 : {read_result}')
print(f'Easy OCR 확률 : {read_confid}%')
print("=======================================")
def tess_ocr (path) :
image = Image.open(path)
text = pytesseract.image_to_string(image, lang='kor',config='--oem 3 --psm 6')
text = text.split('\n')[0]
print("=== Crop Image OCR Read - Tesseract ===")
print(f'Tess OCR 결과 : {text}')
print("=======================================")
def azure_ocr(path):
subscription_key = "key"
endpoint = "endpoint"
computervision_client = ComputerVisionClient(endpoint, CognitiveServicesCredentials(subscription_key))
print("\n===== Crop Image OCR Read - Azure =====")
img = open(path, "rb")
read_response = computervision_client.read_in_stream(img, language="ko", raw=True)
read_operation_location = read_response.headers["Operation-Location"]
operation_id = read_operation_location.split("/")[-1]
while True:
read_result = computervision_client.get_read_result(operation_id)
if read_result.status not in ['notStarted', 'running']:
break
time.sleep(1)
if read_result.status == OperationStatusCodes.succeeded:
for text_result in read_result.analyze_result.read_results:
for line in text_result.lines:
print(f'Azure OCR 결과 : {line.text}')
# print(line.bounding_box)
print("=======================================")
# 학습된 모델 호출
model = torch.hub.load('ultralytics/yolov5', 'custom', path='./yolov5/best.pt', force_reload=True)
# 이미지 불러오기
img = Image.open('./yolov5\de\images\img_5.png').convert('L') # PIL image
img = img.filter(ImageFilter.GaussianBlur(radius =1))
# 모델에 이미지 입력
results = model(img, size=640)
# results를 pandas로 정리
df = results.pandas().xyxy[0]
'''
xmin ymin xmax ymax confidence class name
0 116.761169 208.202805 1044.926025 767.356384 0.976881 0 car
1 359.405090 608.750916 566.712891 660.803223 0.876195 1 plate
2 1051.030151 484.713440 1102.585327 516.971680 0.750280 1 plate
'''
crops = results.crop(save=False)
# conf = (crop[0]['conf'].item() * 100)
for num, crop in enumerate(crops) :
if 'plate' in crop['label'] and crop['conf'].item() * 100 > 50 :
image = crop['im']
im = Image.fromarray(image)
im.save(os.path.join(path, f'plate_{num}.png'), 'png',dpi=(300,300))
plate_name = df['name'][1]
plate_conf = int((round(df['confidence'][1], 2)) * 100)
print("====== Crop Image Plate predict =======")
print(f'{plate_name} 예측 확률 : {plate_conf}%')
print("=======================================")
file_list = os.listdir(path)
for num, file in enumerate(file_list):
azure_ocr(f'{path}/{file}')
easy_ocr(f'{path}/{file}')
tess_ocr(f'{path}/{file}')
실행결과

다음과 같은 이미지를 불러와서
grayscale, gaussianblur처리
yolov5 학습모델에 넣어서 detect한 번호판을 저장

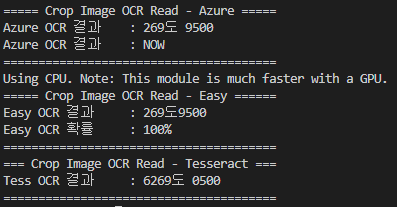
azure,easyocr,tesseract를 각각 실행한 결과
azure ocr이 매우 정확하고 번호판 왼쪽의 NOW글씨도 읽어낸다.
easy ocr도 정확한 편이며
tesseract ocr은 약간 정확도가 떨어진다.
학습한 내용 중 어려웠던 점 또는 해결못한 것들
해결방법 작성
학습 소감
이제 읽어낸 번호판으로 주차정산을 해보려고 하는데 재미있을 것 같다.
