오늘과 내일은 컴퓨터 공학 기초를 공부하는 시간이라서 배운 개념들을 가볍게 정리하는 식으로 기록 하겠다.
ASCII
아스키코드는 American Standard Code for Information Interchange의 약자로 미국 정보 교환 표준 부호라는 뜻이다.
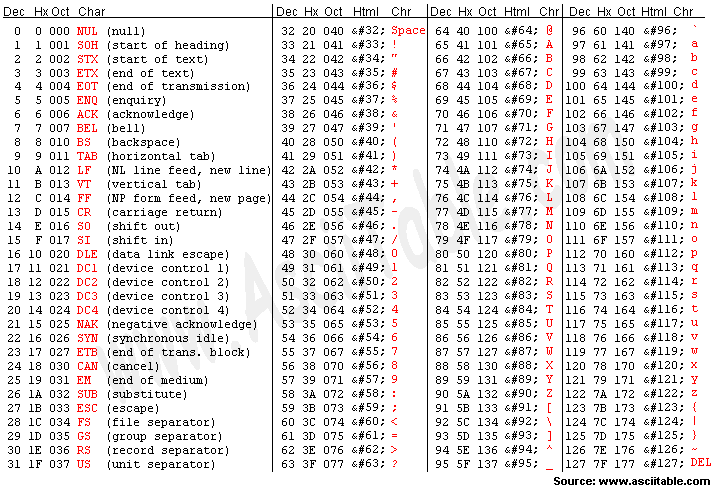
사진 출처: 나무위키 - 아스키 코드
아스키 코드는 1960년대 미국 국립 표준 협회에서 표준화한 정보교환용 7비트 부호체계이다. 000부터 127까지 총 128개의 부호가 사용된다.
컴퓨터의 기본 저장 단위는 1바이트인데 왜 7비트만 사용했을까?
그 이유는 1비트는 통신 에러 검출을 위해 사용하기 때문이다.
아스키 코드는 영문 키보드로 입력할 수 있는 모든 기호들이 할당되어 있는 부호체계이다.
그런데 영문 키보드로 입력할 수 있는 모든 기호들을 할당 했다면, 다른 나라 언어들은 표현을 못한다는 말과 같다.
Unicode
유니코드는 전 세계의 거의 모든 문자를 다루도록 설계된 표준 문자 전산 처리 방식이다.
ASCII코드 보다 용량을 확장해서 2바이트를 사용한다.
1바이트와 2바이트는 표면적으로 많이 차이가 나 보이지는 않지만 1바이트는 2의 8제곱 인 256개를 담을 수 있지만, 2바이트는 2의 16제곱이어서 65536개를 담을 수 있다.
그런데 이마저도 부족해서 유니코드 3.0 버전부터는 보충언어판을 정의했다.
기본다중언어판의 영역 중 일부를 상위대행(1024) 하위대행(1024)으로 정의한 뒤 두 대행의 조합으로 1,048,567(1024*1024)개의 문자를 추가로 정의할 수 있게 만들었다.
UTF-8
유니코드의 대표적인 인코딩 방식이다.
UTF-8은 유니코드 한 문자를 나타내기 위해 1바이트에서 4바이트까지 사용한다.
가변을 구분하기위해서 첫 바이트에 표식을 넣는다.
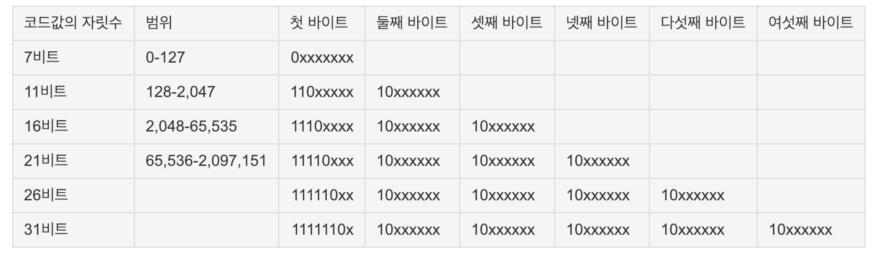
1바이트 영역은 아스키 코드와 하위 호환성을 가지고 가변 길이를 선언하기 위해 꽤 많은 비트를 사용해도 2,097,151까지 인코딩할 수 있어서 4바이트만 사용해도 충분하다.
이러한 장점으로 인터넷 사이트에서 가장 많이 쓰이는 인코딩이다.
UTF-8에서는 한글은 3바이트를 차지한다.
