규모문제
건강에 관련된 데이터(기, 몸무게, 혈압)
- 1.885m 와 1.525m는 33cm나 차이가 나지만 특징값 차이는 불과 0.33
- 65.5kg과 45.0kg은 20.5라는 차이
- 첫 번째와 두 번째 특징은 양수, 100배규모차이
 편차규모가 큰 항목에 대해 가중치가 크게 실림
편차규모가 큰 항목에 대해 가중치가 크게 실림
백프랍 진행할때 몸무게 미분값이 크니까 수치가 빠르게 갱신되지만
편차가 적은 키는 미세하게 변형되므로 느린계산이 이뤄짐
모든 특징이 양수인 경우

- 그래디언트가 전달될때 방향성이 서로 정반대인 경우가 발생
- 최저점을 찾아가는 경로가 갈팡질팡해 느린 수렴
- 수치가 양수, 음수등 다양하다면 같은 방향이지만 약간 다른 위촐의 수렴도 가능
정규화
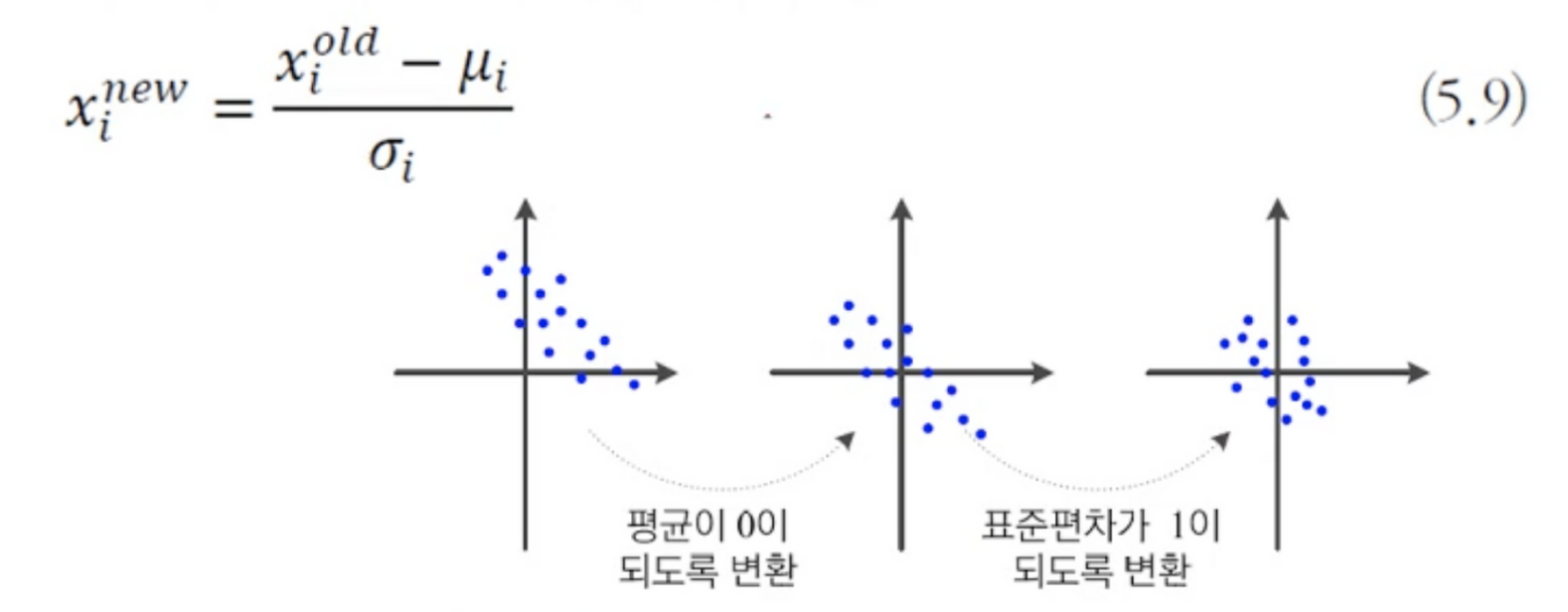

- 특징별로 독립적으로 사용
- 정규화를 통해 표준편차가 서로 다른 특징들에 문제가 발생하는 규모문제 해결
- 양수만 있는 경우 발생하는 양수문제도 해결 가능
명목변수 원핫코드 변환


- 각 숫자가 거리를 나타내는 것이 아니라 국가 분류 같이 명목상 수치가 사용되는 경우 원핫 코드를 통해 위 그림과 같이 또하나의 벡터화를 시켜줌

컴퓨터가 좋아