딥러닝
1.[딥러닝] 퍼센트론(신경망)

각 뉴런이 신호를 받는다다음 뉴런으로 보낼 신호의 양을 증폭, 감쇄해서 다음 뉴런으로 보냄여러 뉴런들로부터 전달된 신호로 최종 결정을 함inputs 값을 받고wights 값으로 증폭/감쇄 받아서다음층으로 넘길지 말지 threshold 값에 따라서 결정
2.[딥러닝] 신경망의 종류
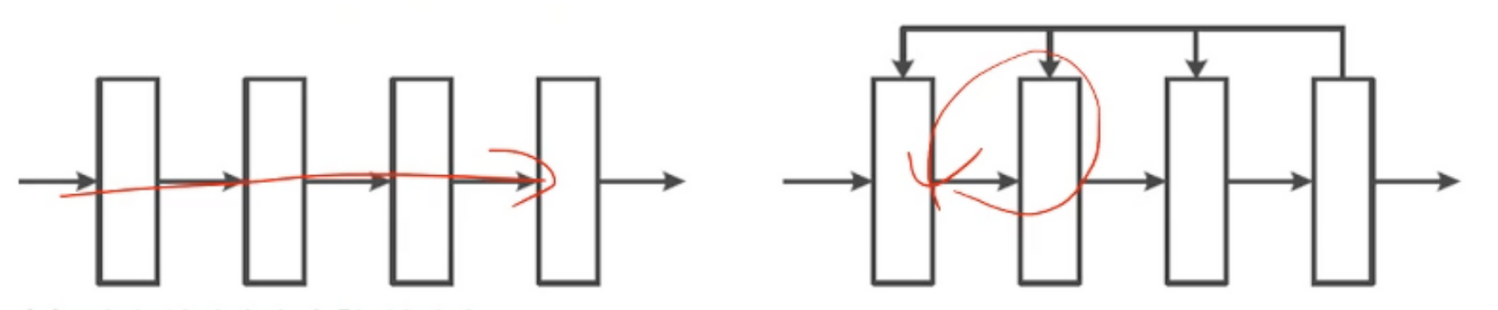
단방향으로 쌓여있는 전방신경망전방으로반 진행하는것이 아니라 이미 지나온곳을 갱신하며 지나가는 순환 신경망신경망 층이 몇개되지 않는 얕은신경망층이 두껍게 쌓인 깊은신경망층이 무조건 깊다고 해서 좋은 성능을 보이진 않음overfitting 문제가 발생할 수 있음Model
3.[딥러닝] 퍼셉트론의 구조
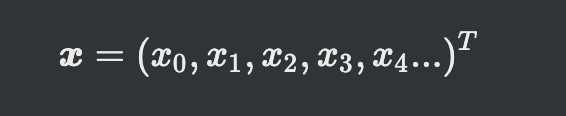
일반적으로 출력을 위한 입력값입력과 w 가중치를 연산하는 과정 수행함내적한 결과값이 y로 나옴입력 x와 가중치w 를 연산한 결과 yy의 값의 정도에 따라 다음 신호를 어떻게 보낼지 결정하는 활성함수위 그림은 일정값 미만이면 -1 이상이면 +1를 곱해주게 됨w0은 w와
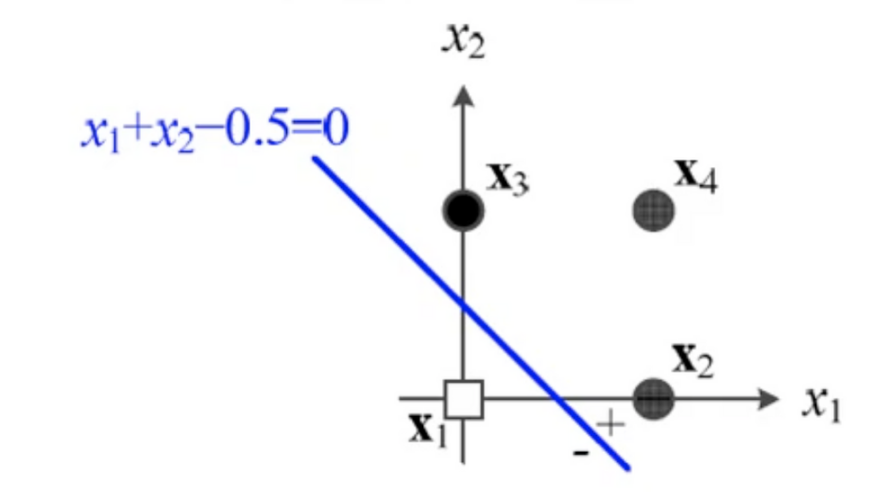
4.[딥러닝] 퍼셉트론 동작
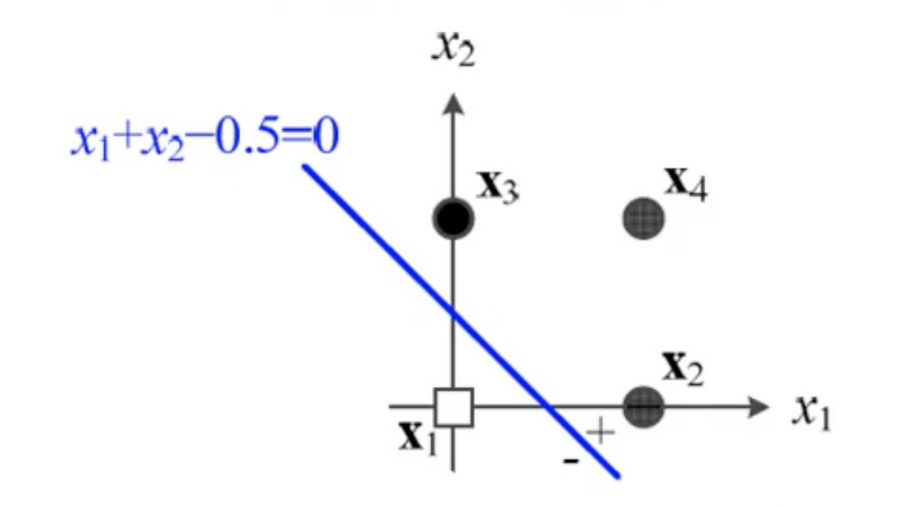
입력값x 와 가중치w 를 연산하는 식 직선의 방정식으로 표현됨위 사진처럼 입력값의 분포 어딘가에 생기는 직선으로 안쪽은 - ,바깥쪽은 + 로 분류 됨2차원: 결정 직선, 3차원: 결정 평면, 4차원 이상: 결정 초평면하지만 입력값이 딱 떨어지게 구역을 나눠서 위치하지
5.[딥러닝] 다층 퍼셉트론
집합이 선형으로 분리가 가능하지 않을 때 선형 분류기의 정확도가 현저하게 떨어짐퍼셉트론 2개를 사용해 (-,+), (+,+), (+,-)영역으로 나눠주고선형변환을 통해 공간을 이동시켜줌그렇게 선형변환으로 이동된 공간에서 3번째 퍼셉트론을 통해 분류를 진행해주면 여기에서
6.[딥러닝] 활성함수
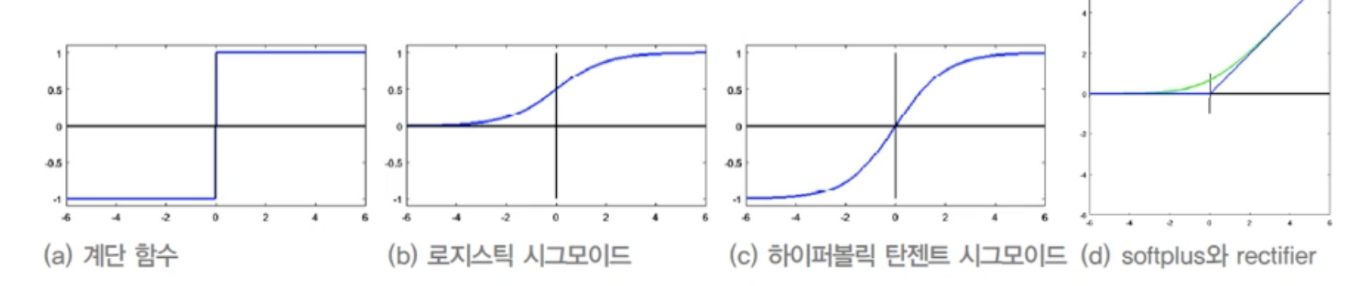
입력값과 가중치를 내적한 값을 다음 신경망으로 보낼때 얼마나 증폭/감쇄 할지 결정해주는 활성함수여러타입의 활성함수 형태가 있는데학습과정에서 그래디언트 계산상 문제가 발생logistic sigmoid, tanh sigmoid 같은 경우 미분값을 보면 양 끝단에서 그래디언
7.[딥러닝] 다층 퍼셉트론 구조
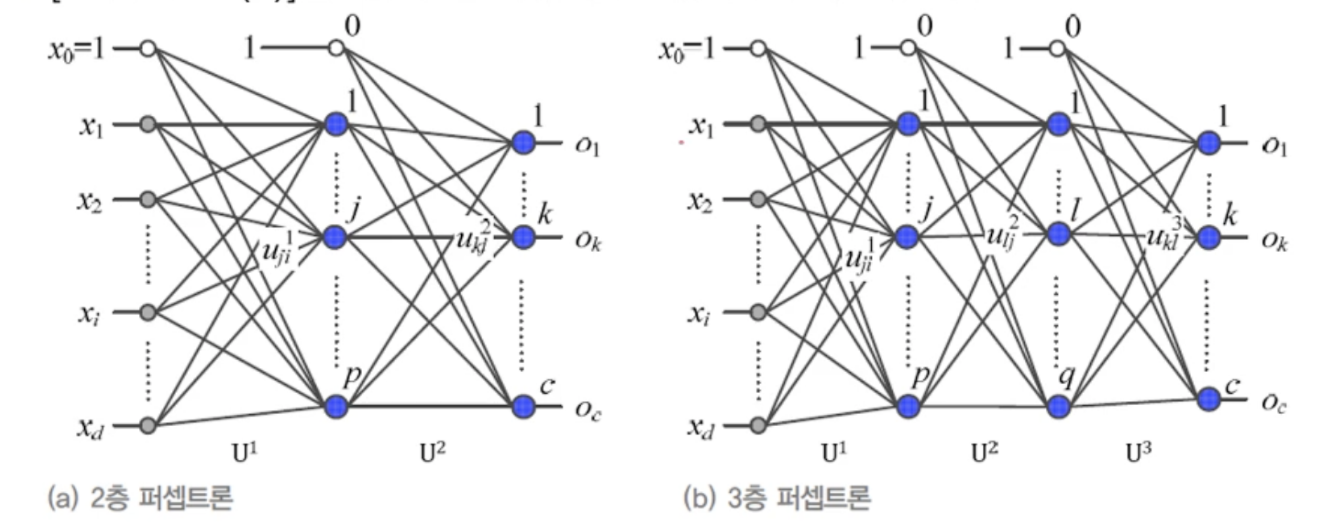
다층의 퍼셉트론은 분할이 어려운 샘플들을 공간변형을 통해 분류가 쉬운 형태로 변형시켜줌층이 깊어질수록 정확한 분류가 가능해짐층수가 너무 깊어지면 과잉적합문제가 발생그래디언트 값을 얼마나 적용할지 정해주는 p값 같은 하이퍼 매개변수 등의 적절한 조정이 필요퍼셉트론이 쌓인
8.[딥러닝] 오류 역전파
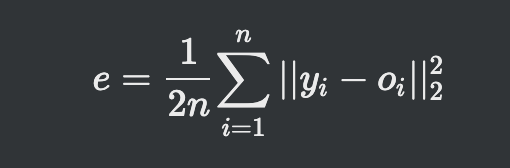
오류 역전파 알고리즘 순방향으로 매개변수, 활성함수 등을 거쳐서 아웃풋이 나오게 됨 이과정을 식으로 풀면 
1980년대 이미 아이디어 등장시그모이드, 계단함수 등의 활성함수 경사소멸문제작은 훈련집합 데이터과다한 연산(컴퓨터 성능 낮음)학습률 도입해 그래디언트 최적값 진입ReLU같은 활성함수 개선을 통해 경사소멸문제 해결규제 기법을 통해 Overfitting 문제 감소컴퓨터
10.[딥러닝] 깊은 신경망
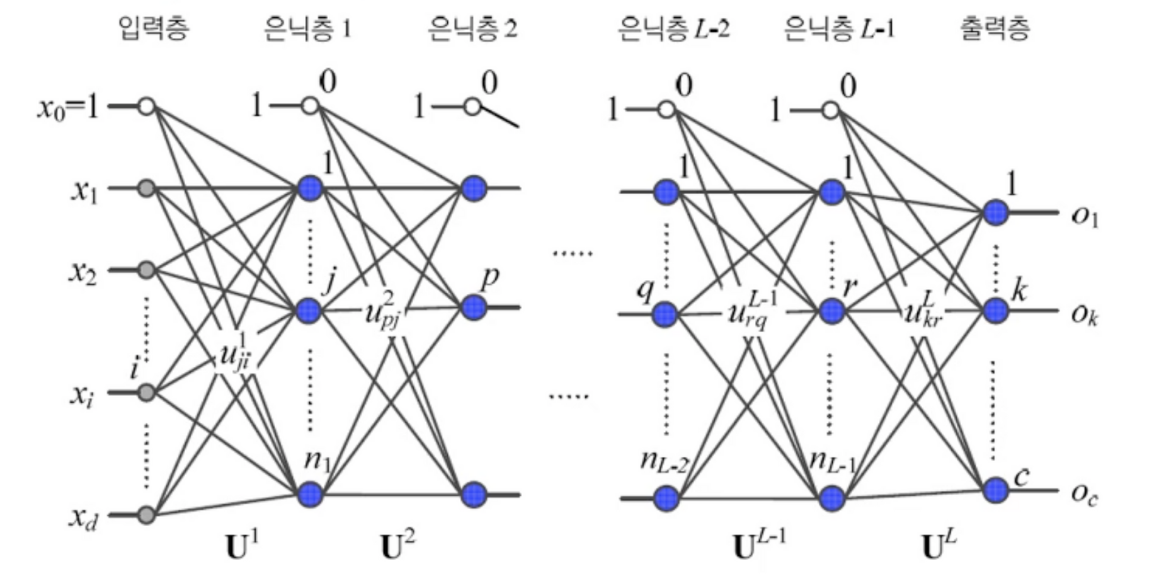
L-1개의 은닉층마지막 L층은 분류층각 노드별로 연결되는 모든 경우의 수가 행렬에 담김목적함수로부터 각 출력층에 대한 그래디언트 산출아웃 그래디언트를 그 전 단계 층 가중치 행렬에 대한 그래디언트 산출그 아래층부터 그 또 아래층 그래디언트 계산
11.[딥러닝] 컨볼루션 신경망(CNN) 구조
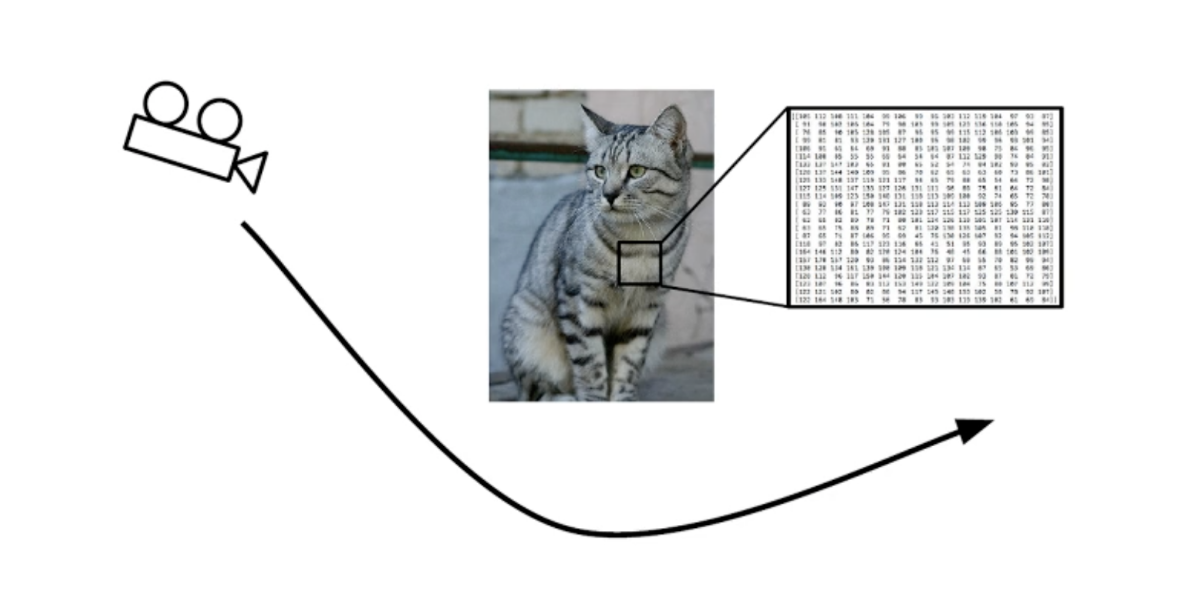
정해진 물체가 움직이면 전체적인 픽셀값 변경됨경계색이 모호한경우 구분이 어려움밝기, 조명에 따라서 강조되는 포인트 다름일부가 가려진 영상 분류 어려움선형함수인 컨볼루션과 비선형 함수인 활성함수의 조합컨볼루션의 얻어진 특징을 통계적으로 압축전체적으로 결합해 층을 쌓고 사
12.[딥러닝] CNN 특성
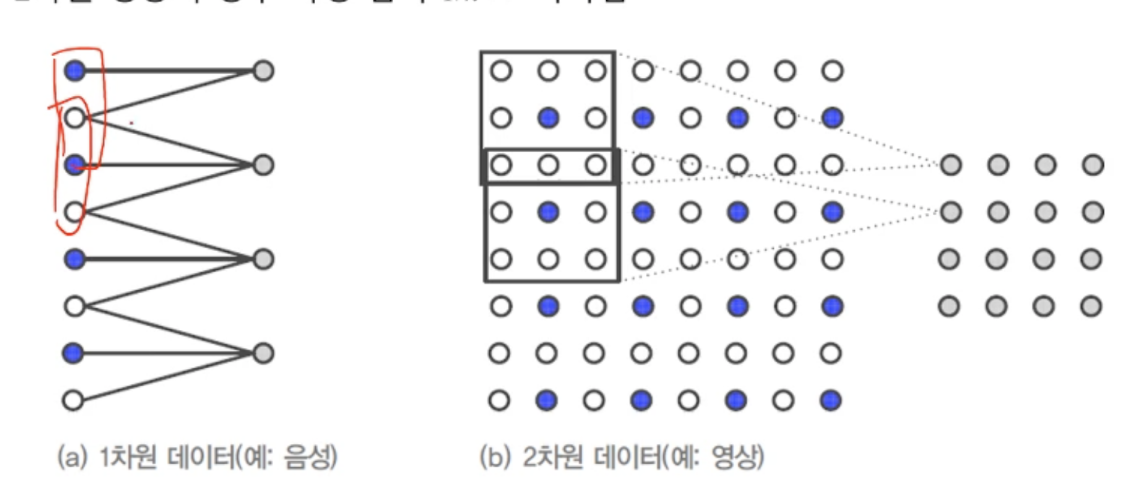
물체가 이동하면 이동 정보가 특징맵에 그대로 반영병렬분산 구조보폭이 커질수록 출력되는 특징맵 크기가 작아짐다운샘플링을 통해 연산해야할 양이 적어짐3차원 영상을 2차원의 특징맵으로도 정리4차원 영상을 3차원으로도 정리입력데이터 -> 입력데이터 차원과 같은 차원의 커널 -
13.[딥러닝] AlexNet
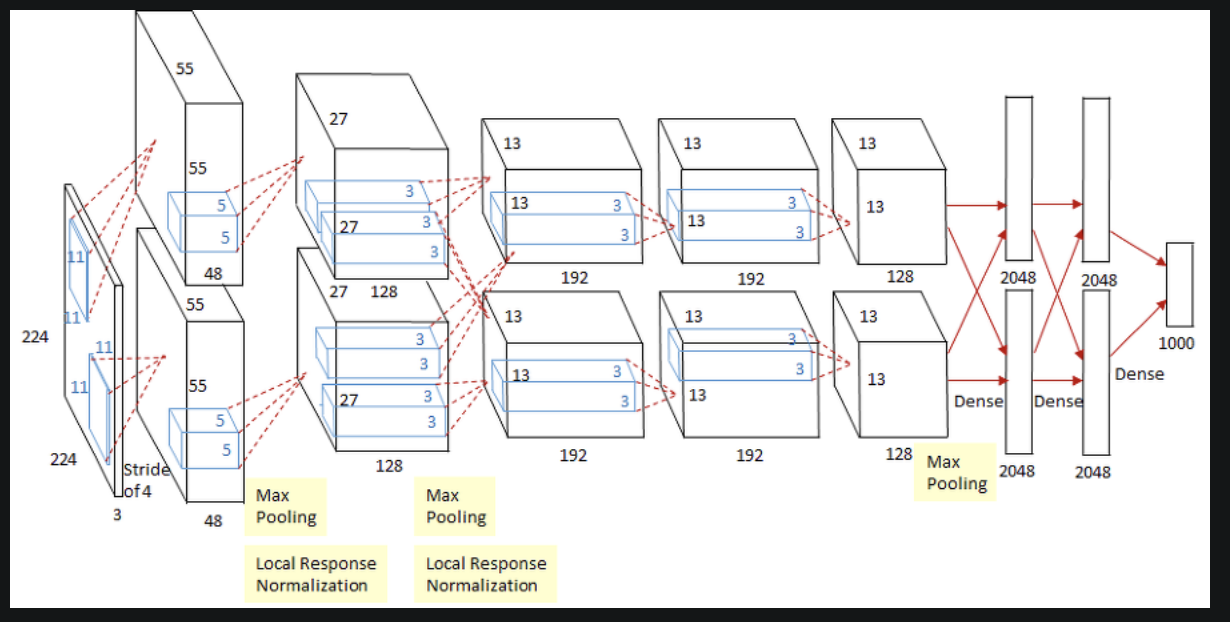
컨볼루션 5개, 완전연결층3개로 구성컨볼루션층 200만개, 완전연결층 6500만개 매개변수완전연결층의 매개변수를 줄이는 방향으로 발전2-3번째 컨볼루션은 윗층 아랫층 두개 연결이고 3번째 이후로 병렬적인 연산 진행됨그래픽카드 성능이 충분하지 않은 상황에서 연산을 여러개
14.[딥러닝] VGGNet
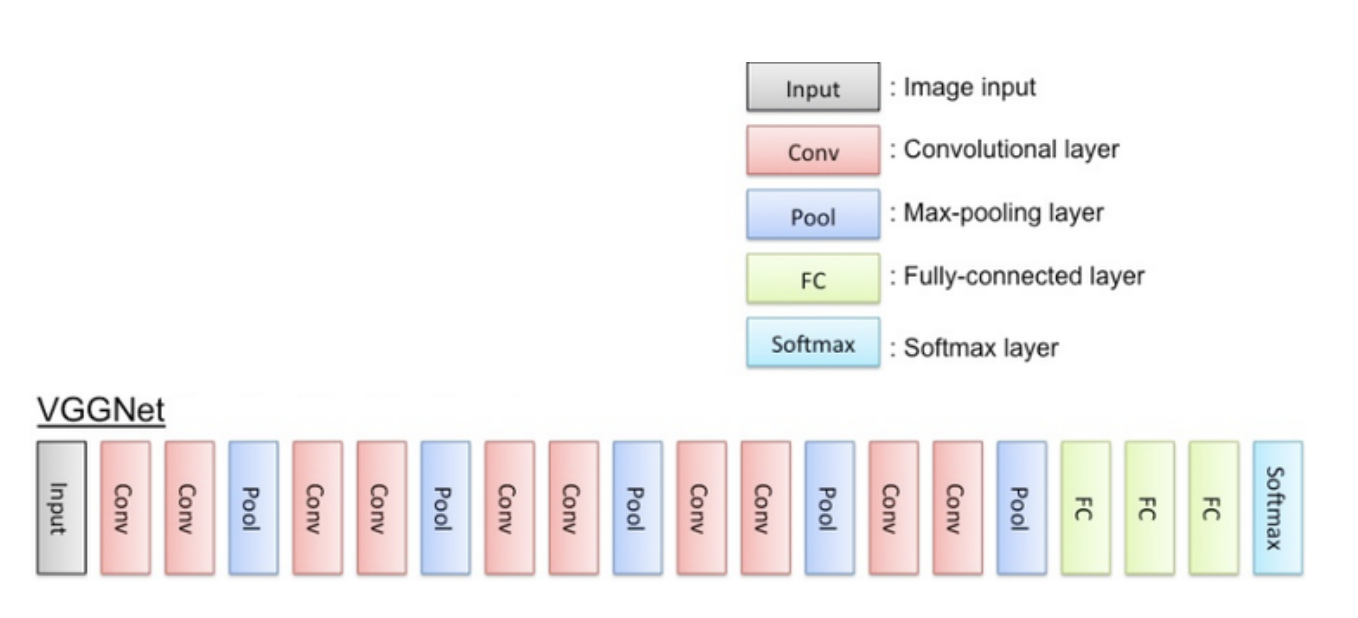
신경망을 깊게 설계컨볼루션층이 8~16개로 AlexNet 5개와 비교해 2~3배 깊음3\*3 작은 커널을 사용한 컨볼루션큰 커널을 작은 커널 여러개로 분해 -> 매개변수가 줄어듬n \* n커널은 1 \* n커널과 n \* 1커널로 분해 n사이즈가 커질수록 매개변수차이가
15.[딥러닝] GoogLeNet
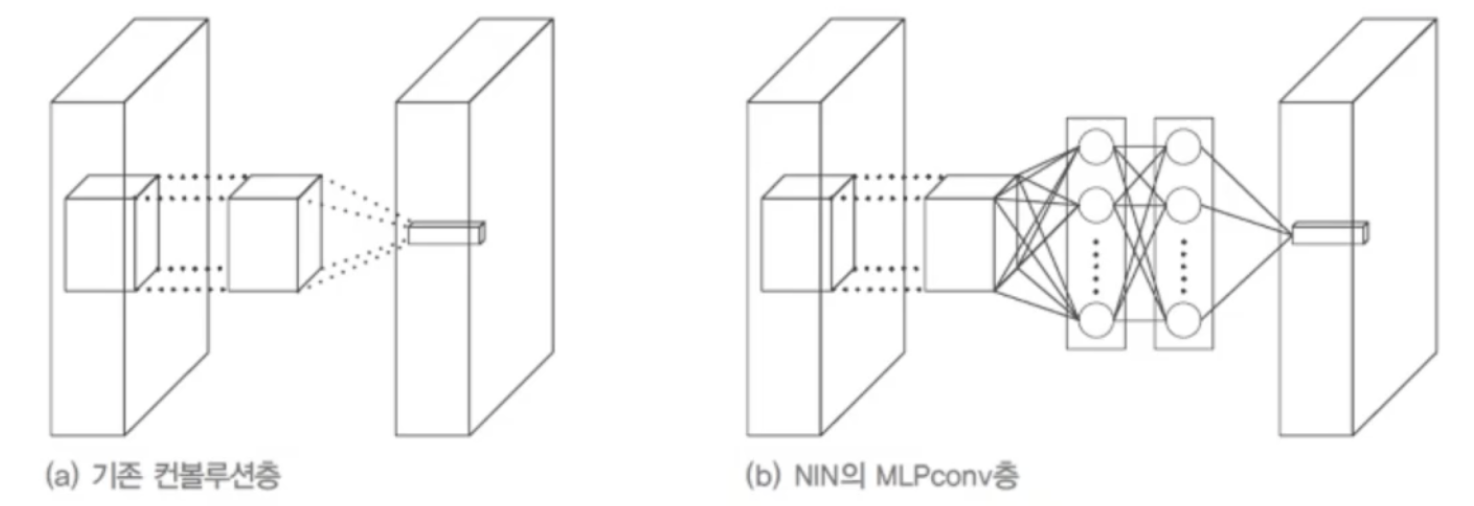
기존 컨볼루션 연산(커널을 통한 연산)을 MLPConv 연산을 대체(비선형 함수를 활성함수로 포함하는 MLP 사용)신경망의 미소 신경망이 주어진 수용장의 특징 추상화전역 평균 풀링 사용VGGNet의 완견 연결층은 1억2천2백만개 매개변수를 가짐많은 매개변수로 과잉적합
16.[딥러닝] ResNet
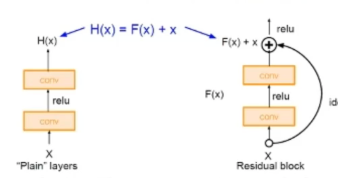
신경망이 깊어질수록 정확도가 올라감하지만 신경망이 깊어지면 연산량이 대폭 증가해 성능 저하 발생과잉적합문제 발생경사소멸 문제 발생컨볼루션과 활성함수를 거친 값과 처음 인풋값을 합쳐줌역전파 과정에서 발생하는 깊은 신경망 경사소멸문제를 해결덧셈 연산만 증가해 매개변수 개수
17.[딥러닝] 목적함수(교차엔트로피)
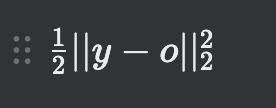
e가 클수록 개선할 점이 많다는 것실제적으론 오른쪽 e값이 큰데 경사도 갱신은 적게 일어남목적지로 가는 속도가 느려짐왼쪽 시그모이드 함수, 오른쪽 시그모이드 함수의 도함수가로축의 양쪽에서 경사도가 매우 낮음학습이 더딘 부정적 효과정답 y가 {0, 1}에 속할때 P는 정
18.[딥러닝] 소프트맥스&로그우도
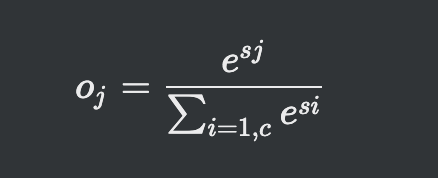
max 함수를 모방한 개념로지스틱 시그모이드 같은경우 기준값을 넘지 못하면 0 기준을 넘으면 무조건 1이 되버림확률적 판단에는 시그모이드 함수는 적합하지 않음소프트맥스느 정규분포 형태로 합쳐서 1인 수치로 확률을 계산MSE, 교차 엔트로피와는 달리 하나의 노드에만 적용
19.[딥러닝] 성능향상(데이터 전처리)
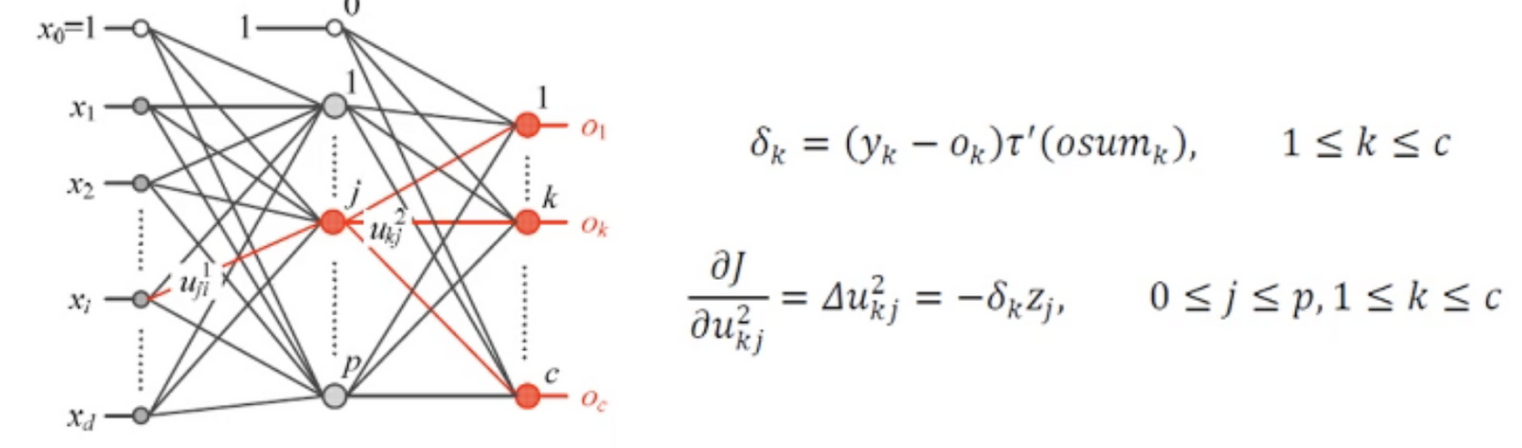
1.885m 와 1.525m는 33cm나 차이가 나지만 특징값 차이는 불과 0.3365.5kg과 45.0kg은 20.5라는 차이첫 번째와 두 번째 특징은 양수, 100배규모차이편차규모가 큰 항목에 대해 가중치가 크게 실림백프랍 진행할때 몸무게 미분값이 크니까 수치가 빠
20.[딥러닝] 성능향상(가중치 초기화)
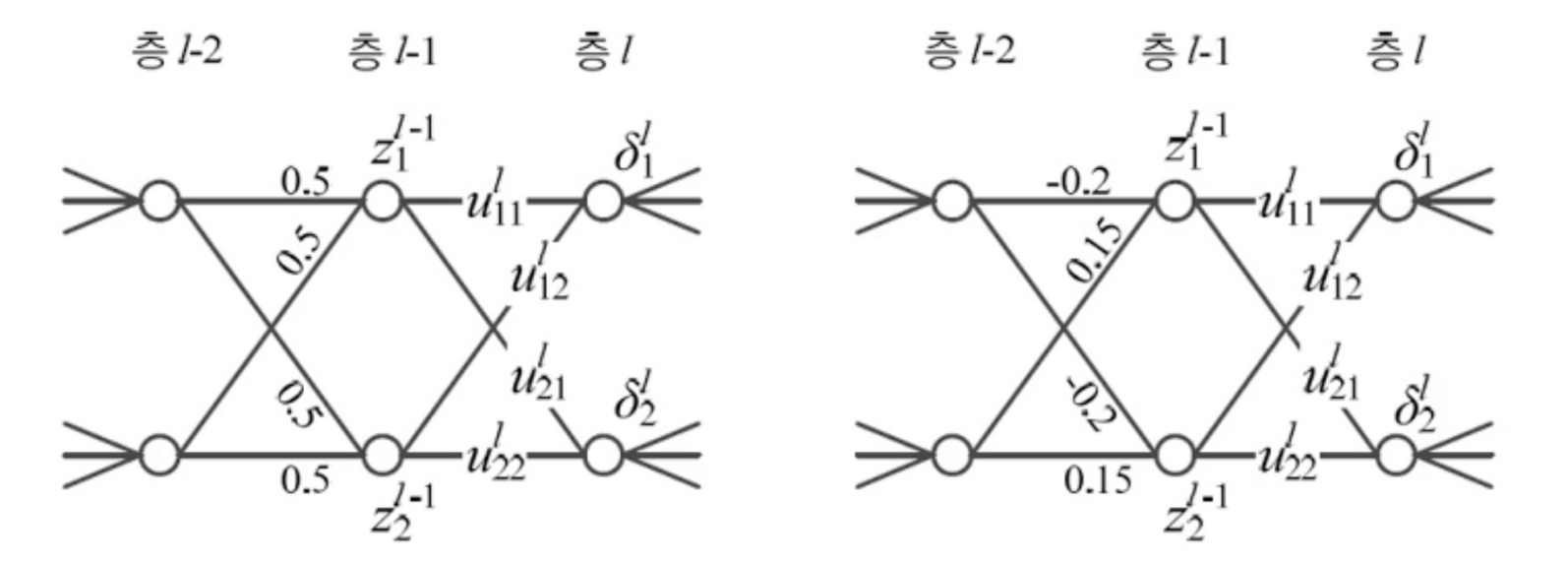
왼쪽 연산과정에서 두개의 가중치가 같음경사도가 같기 때문에 같은 값으로 갱신됨두 노드가 같은 일을 함난수로 가중치를 초기화해 중복노드를 야기하는 대칭을 파괴(오른쪽 그림)가우시안, 균일분포에서 난수 추출, 두 분포의 성능 차이는 거의 없음AlexNet: 평균 0, 표준
21.[딥러닝] 성능향상(탄력 momentum (가속도, 관성))
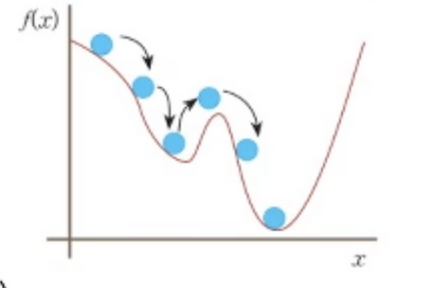
기계 학습은 훈련집합을 이용해 매개변수 경사도를 추정하므로 잡음 가능성 높음전역 최저치로 접근해야하는데 로컬 최저치에서 머무를 가능성 높아짐탄력(가속도, 관성)momentum은 경사도에 부드러움을 가하여 잡음 효과 줄임\- 관성(가속도): 과거에 이동했던 방식을 기억하
22.[딥러닝] 성능향상(적응적 학습률)
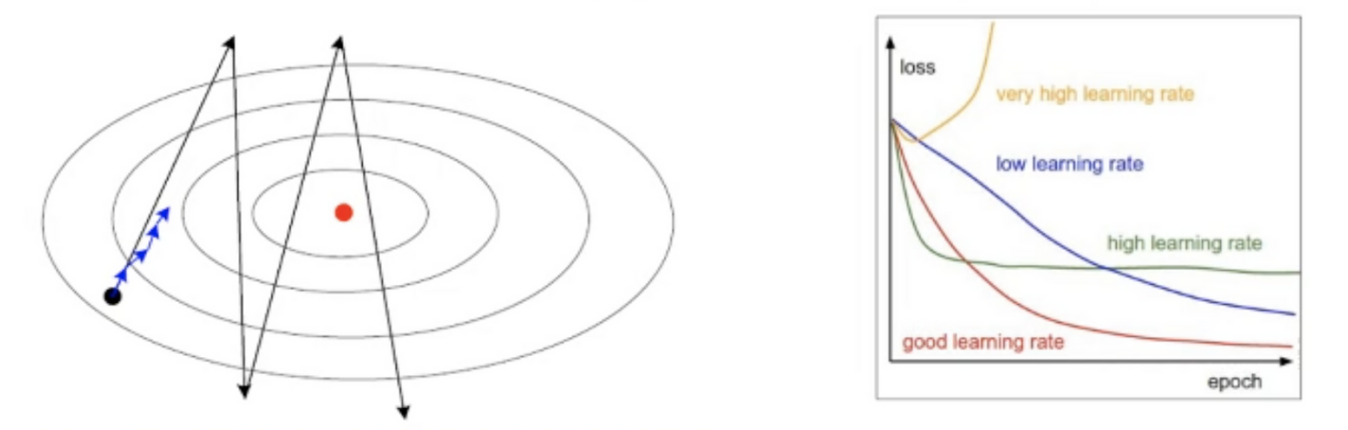
너무 크면 최저점을 지나쳐가서 최저점 수렴속도가 느려지는 현상 발생경사도에 학습률을 곱하면 최저점에 대한 방향성을 보존하며 수렴할 수 있음일관된 경사도는 모든 매개변수에 같은 크기의 학습률을 사용하므로적응적 학습률을 사용해 매개변수마다 자신의 상황에 다라 학습률을 조절
23.[딥러닝] 성능향상(활성함수)
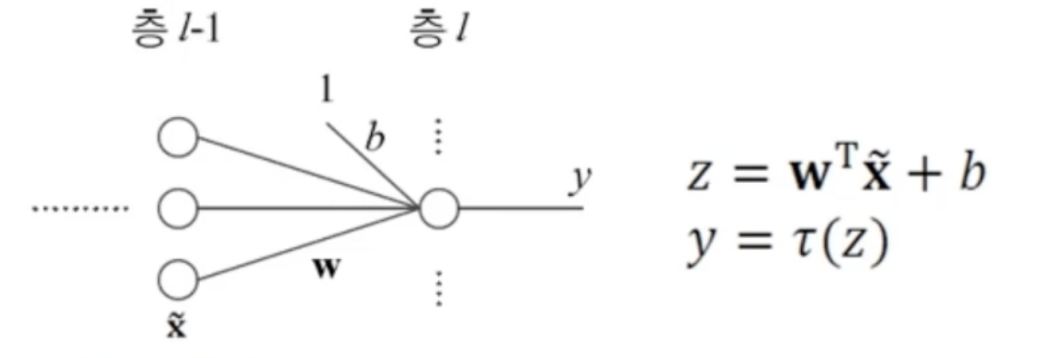
입력값과 가중치를 곱해주고 활성함수를 위한 b(bias)를 더해준 값을 활성함수에 입력함활성함수는 입력에 가중치가 곱해서 나온값의 정도를 결정해서 다음으로 넘겨줌!선형함수에서 ReLU까지 활성함수가 발전해온 과정sigmoid와 계단함수 같은 경우 값이 너무 작거나 너무
24.[딥러닝] 성능향상(배치 정규화)
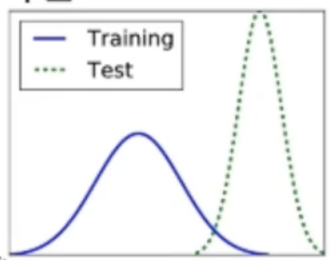
트레이닝셋과 테스트셋의 확률분포가 다름학습이 두세번 진행되면서 첫번째 층의 매개변수가 변화함에 따라 분포가 달라짐그 달라진 분포가 다음층으로 넘어가면서 또 변화가 일어남층2, 층3, ...으로 깊어짐에 따라 더욱 심각학습을 방해하는 요인으로 작용공변량 시프트 현상을 누
25.[딥러닝] 성능향상(규제)
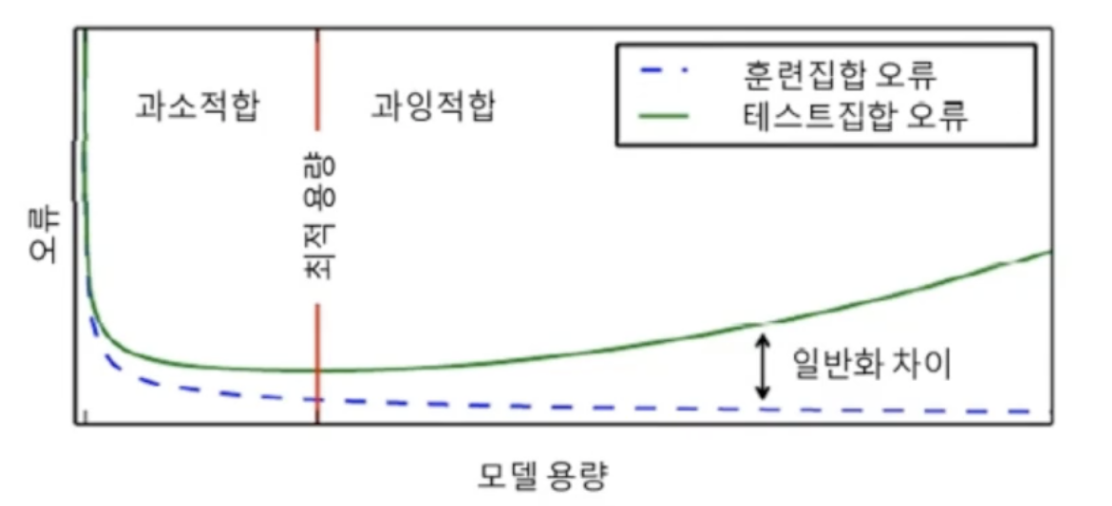
가지고 있느 데이터에 비해 훨씬 큰 용량의 모델을 사용VGGNet은 분류층에 1억 2천 1백만 개의 매개변수훈련집합 안에서만 높은 정확도가 나오는 과잉적합에 주의해야함충분히 큰 용량의 모델을 설계한 다음, 학습 과정에서 여러 규제 기법을 적용모델 용량에 비해 데이터가
26.[딥러닝] 성능향상(규제-가중치벌칙)

규제항은 훈련집합과 무관하며, 데이터 생성 과정에 내재한 사전 지식에 해당규제항은 매개변수를 작은 값으로 유지하므로 모델의 용량을 제한하는 역할규제항 R(theta)로 L2놈이나 L1놈을 사용(큰 가중치에 벌칙, 작은 가중치 유지)규제 항 R로 L2놈을 사용하는 규제
27.[딥러닝] 성능향상(규제-조기 멈춤)
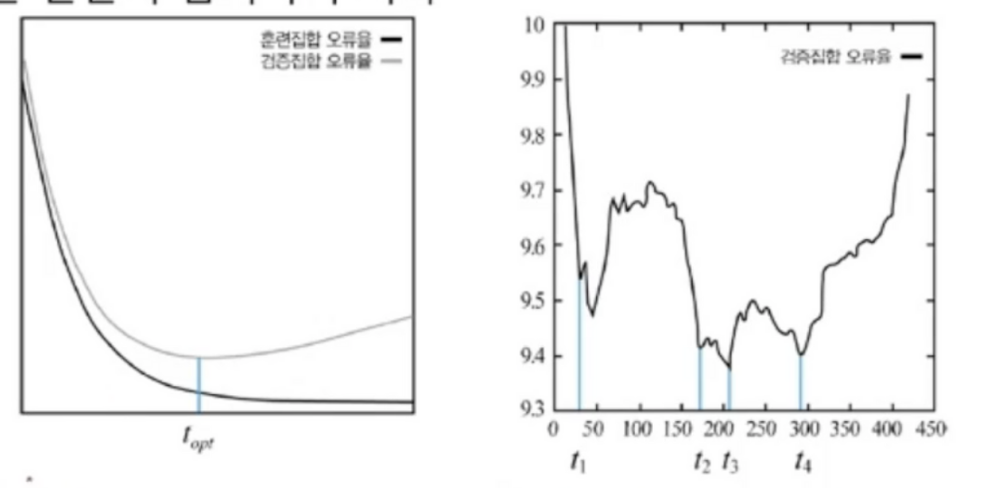
훈련이 오랜 시간이 지나면 훈련집합에선 오류율이 내려가지만 검증집합에선 오류율이 올라감과잉적합 문제 발생검증집합의 오류가 최저인 점에서 학습을 멈춤하지만 상황에 따라 오류율이 벌어졌다가 다시 좁혀지는 현상이 발생하는데 이 부분을 해결하지 못함일단 사이가 벌어지는 지점에
28.[딥러닝] 성능향상(규제-데이터 확대)
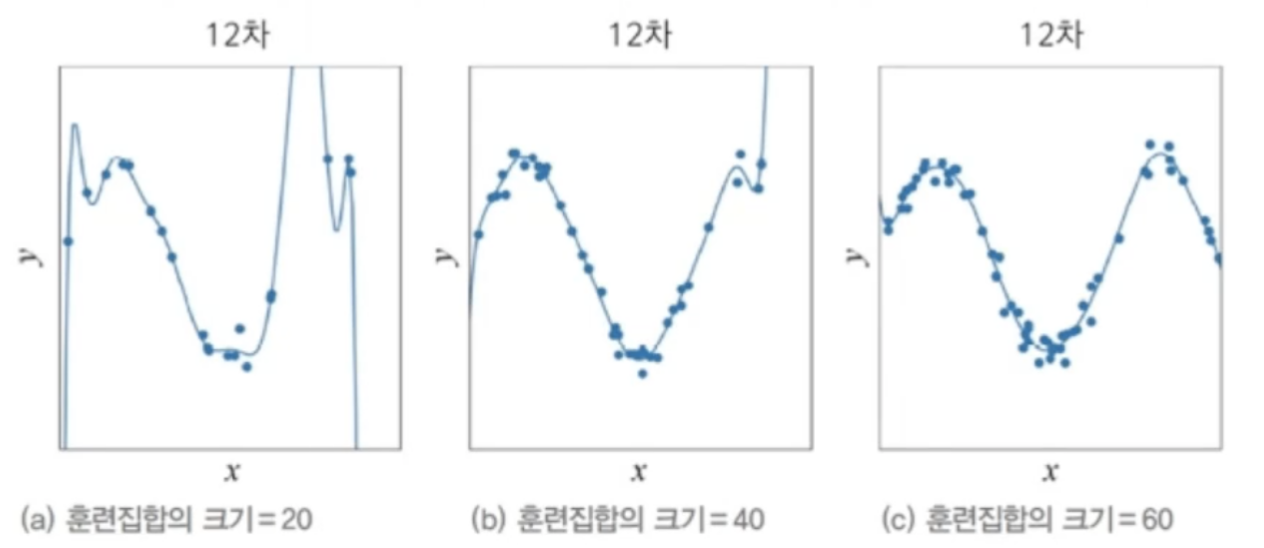
과잉 적합을 방지하는 가장 확실한 방법은 큰 훈련집합을 사용하는 것!다른 규제나 모델의 성능 향상을 꾀하지 않아도 훈련집합이 많으면 과잉적합으로부터 자유로워짐MNIST 에서 같은 숫자 사진을 이동, 회전, 반전시켜 데이터량을 증강수작업 변형, 모든 부류가 같은 변형이
29.[딥러닝] 성능향상(규제-드랍아웃)

완전연결층의 일정 비율을 임의 선택해 제거하는 기법중복 노드들을 제거배치 노멀라이제이션을 실시하면 데이터 쏠림 현상이 해소되기에 드랍아웃을 할 필요성이 없어짐역전파도 드랍아웃된 상태로 진행파이는 boolean(참,거짓)배열로 제거된 노드 여부를 표시파이는 미니배치 샘플
30.[딥러닝] 성능향상(규제-앙상블기법)
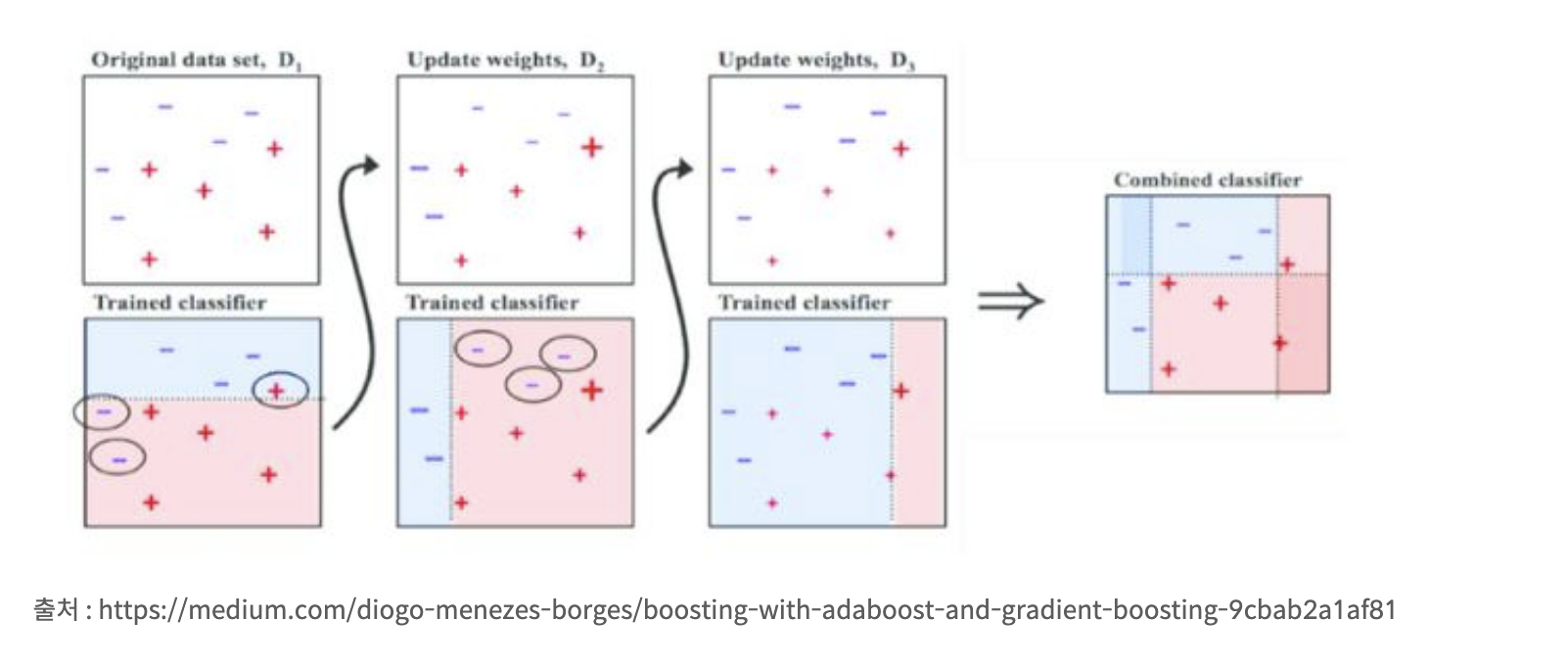
서로 다른 여러 개의 모델을 결합해 일반화 오류를 줄이는 기법현대 기계 학습은 앙상블도 규제로 여김서로 다른 신경망 여러 개를 학습같은 구조를 사용하지만 다른 초기값과 하이퍼 매개변수를 다르게 설정하고 학습배깅bagging (훈련집합을 여러 번 샘플링하여 서로 다른 훈
31.[딥러닝] 성능향상(규제-하이퍼매개변수 최적화)
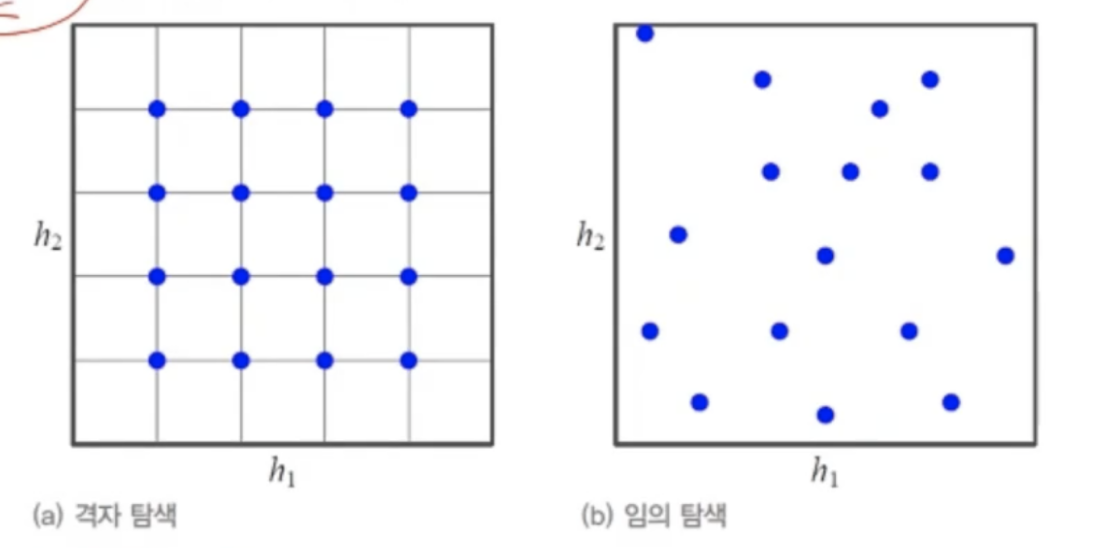
신경망의 경우 쎼타로 표기학습 알고리즘이 최적화함모델의 외부에서 모델의 동작을 조정(러닝레이트, 은닉층 개수, 커널크기, 보폭 등)표준 참고 문헌이 제시하는 기본값 사용후보가 제시돼있다면 돌려보고 최적인 값 선택변수들의 경우의 순을 격자형태로 탐색하는 격자 탐색아무거나
32.[딥러닝] 성능향상(2차 미분)
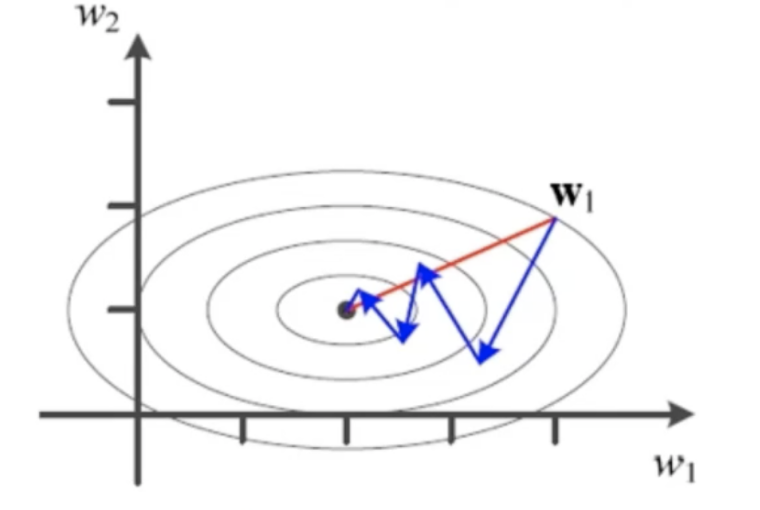
SGD 방법은 1차 미분을 활용한 경사 하강법현재 기계 학습의 주류 알고리즘경사도에 잡음이 있는 문제가 잇음위 문제를 2차 미분 정보를 활용하려고 함파란 경로는 현재 경사하강법이 해를 찾아가는 과정1차 미분으로는 빨간 경로를 찾을 수 없음도달한 다음 도착지에 대한 기울
33.[딥러닝] 성능향상(2차 미분-뉴턴방법)
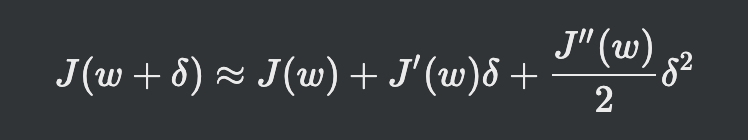
테일러 급수주어진 함수를 정의역에서 특정 정의 미분계수들을 계수로 가지는 다항식의 극한(멱급수)으로 표현함변수가 여러개일때 (H는 헤시언Hessian행렬)델타로 미분하면 이런 식이 나오게 되고w + 델타 값을 최소점이라고 가정한다면기울기는 0값으로 판단식을 델타에 대한
34.[딥러닝] 성능향상(2차 미분-켤레 경사도 방법)
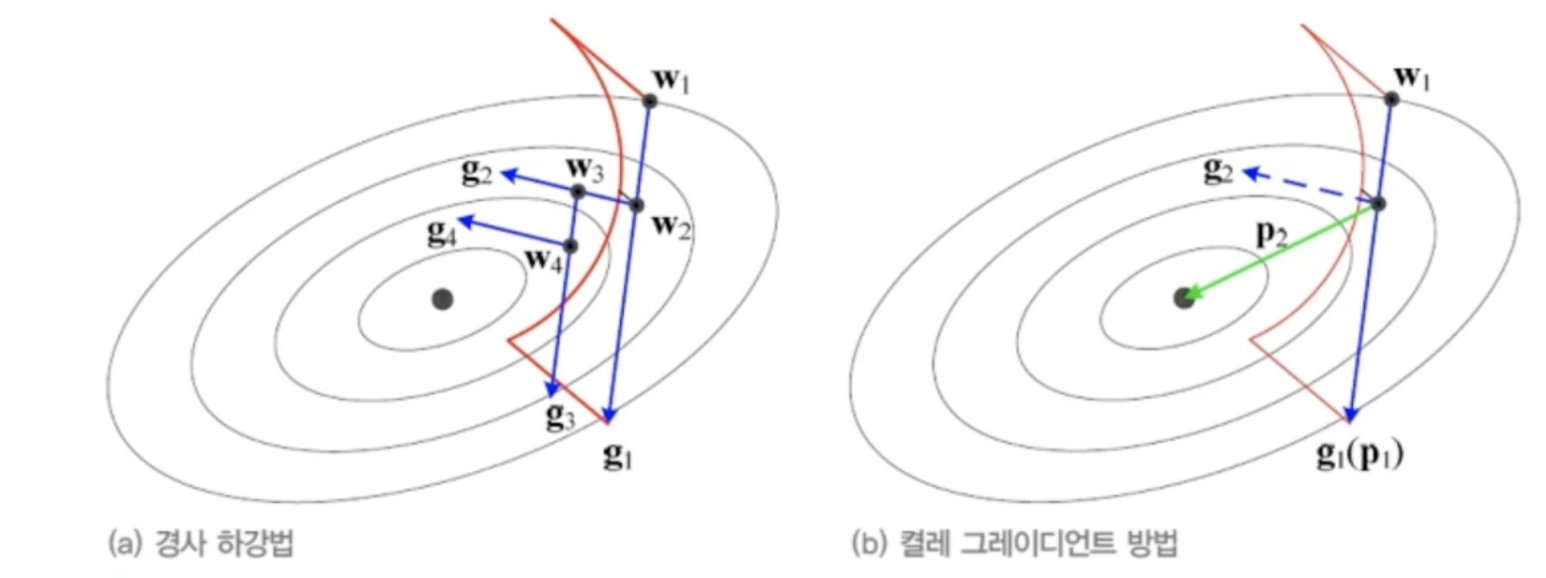
이동 크기를 결정하기 위해 직선으로 탐색하고, 미분기존 경사 하강법은 g2로 직선 탐색할 때 직전에 사용한 g1 정보를 전혀 고려하지 않음결레 경사도는 직전 정보를 사용해 해에 빨리 접근경사 하강법: 수렴 효율성 낮음뉴턴 방법: 헤시안 행렬 연산 부담 -> 헤시언 H의
35.[딥러닝] 순환신경망
특징이 순서를 가지므로 순차 데이터라 부름순차 데이터는 동적이며 보통 가변 길이임순환 신경망은 시간성 정보를 활용하여 순차 데이터를 처리하는 효과적인 학습모델매우 긴 순차 데이터(예, 30단어 이상의 긴 문장)를 처리에는 장기 의존성(앞에것을 기억했다가 뒤에것과 엮어
36.[딥러닝] 순환신경망(순차 데이터)
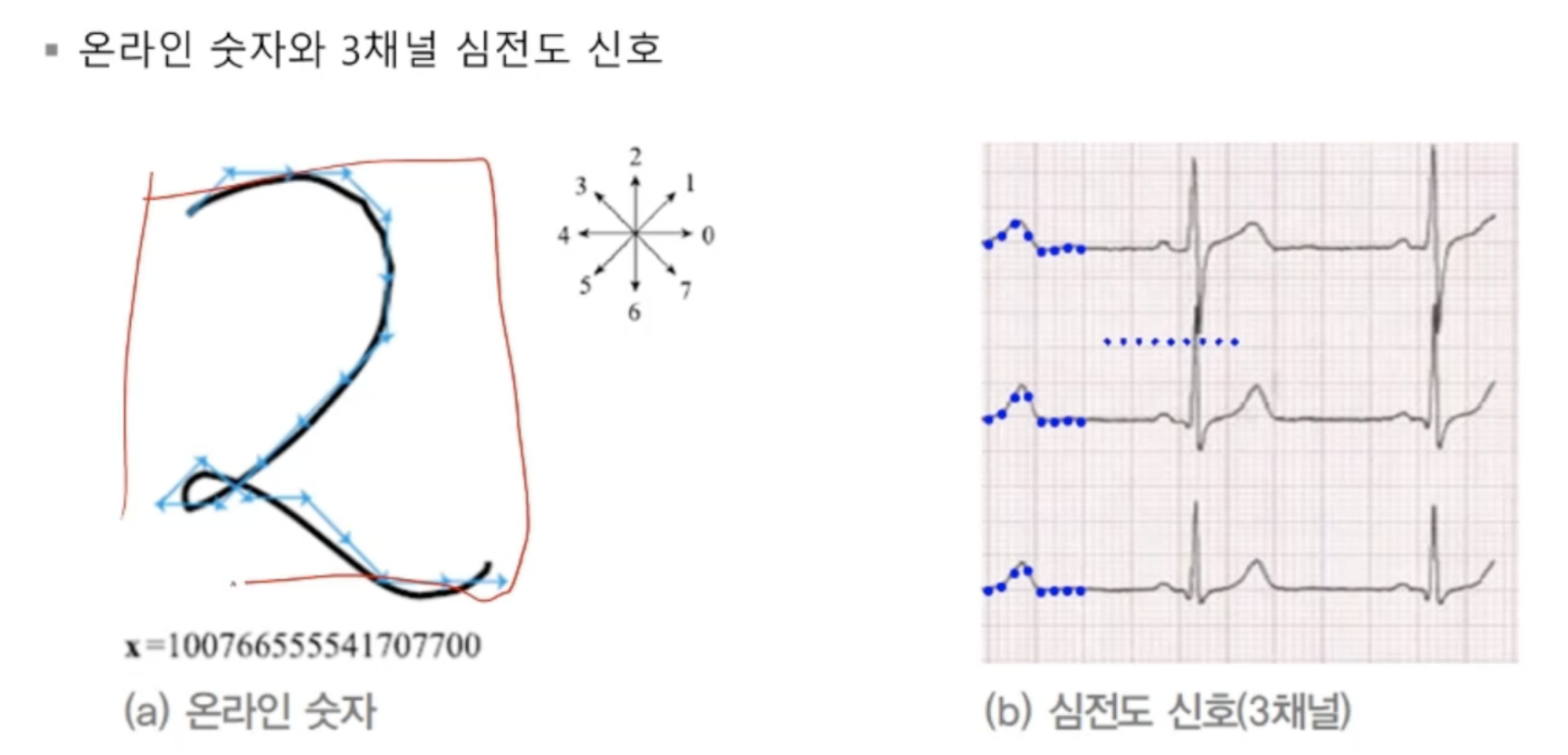
진행 방향을 담은 데이터데이터들이 시간 순서대로 기록돼있음데이터 벡터 요소가 벡터'온라인 숫자'의 요소는 1차원, '심전도'의 요소는 3차원심전도 요소는 시간당 3개의 데이터가 생성되므로 3차원훈련집합은 위와 같이 표현x = "Aprill is the cruelest
37.[딥러닝] RNN(구조)
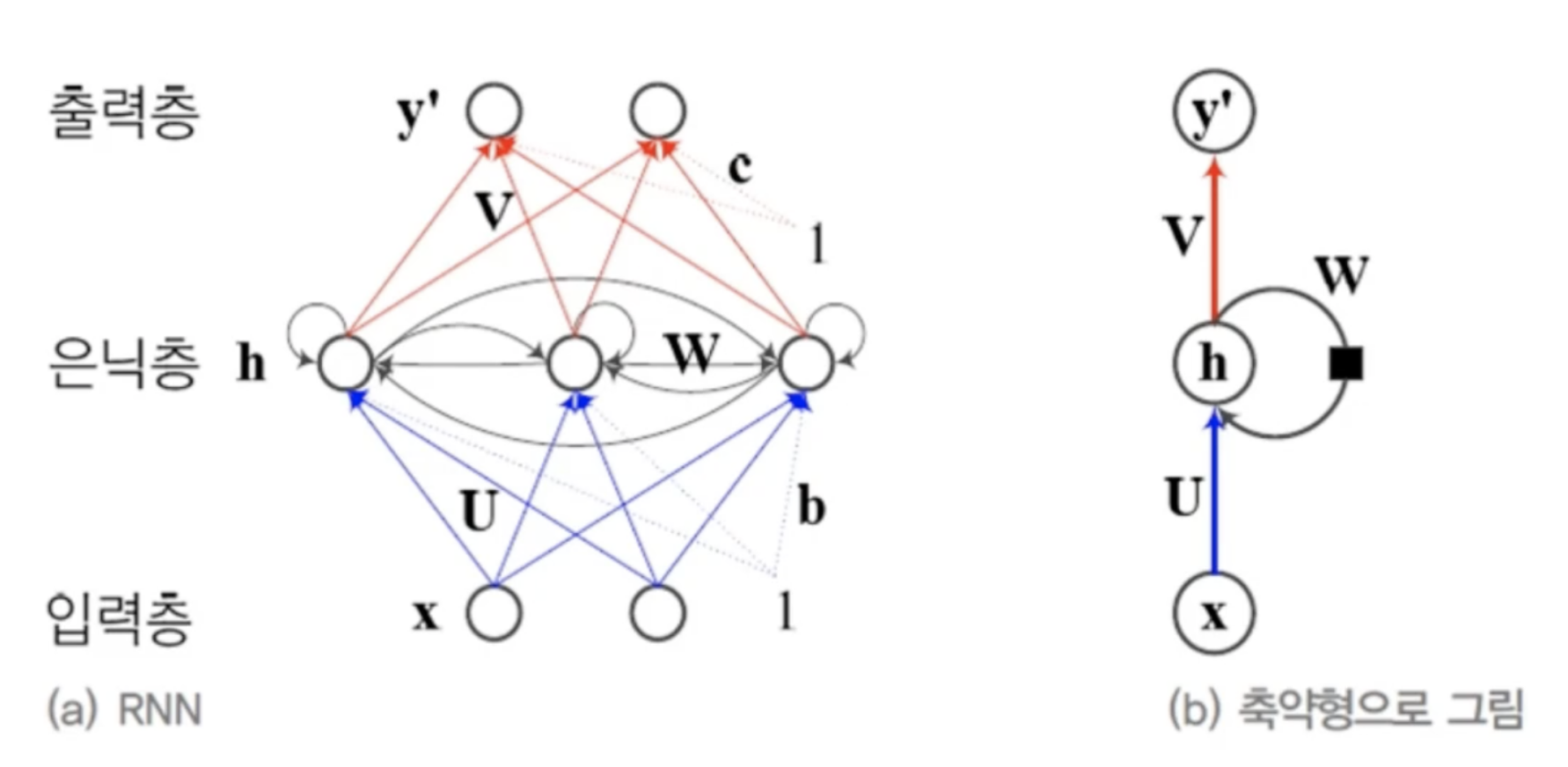
특징을 순서대로 한 번에 하나씩 입력해야 한다.길이가 T인 샘플을 처리하려면 은닉층이 T번 나타나야 한다. T는 가변적이다.이전 특징 내용을 기억하고 있다가 적절한 순간에 활용해야 한다.입력층, 은닉층, 출력층을 가짐은닉층이 순환 연결(recurrent connecti
38.[딥러닝] RNN(동작- 연산)

입력층에서 은닉층으로 가는 과정에서 필요한 u은닉층에서 은닉층으로 보내는 과정에서 필요한 w두 행렬의 같은 행이 연산에 필요함현재입력과 입력 가중치를 연산한 값에 직전 은닉층 결과에 은닉층 가중치를 연산하고 바이어스텀을 더한 결과 값에 활성함수의 결과가 다음 연산에 넘
39.[딥러닝] RNN(동작- 백프랍)
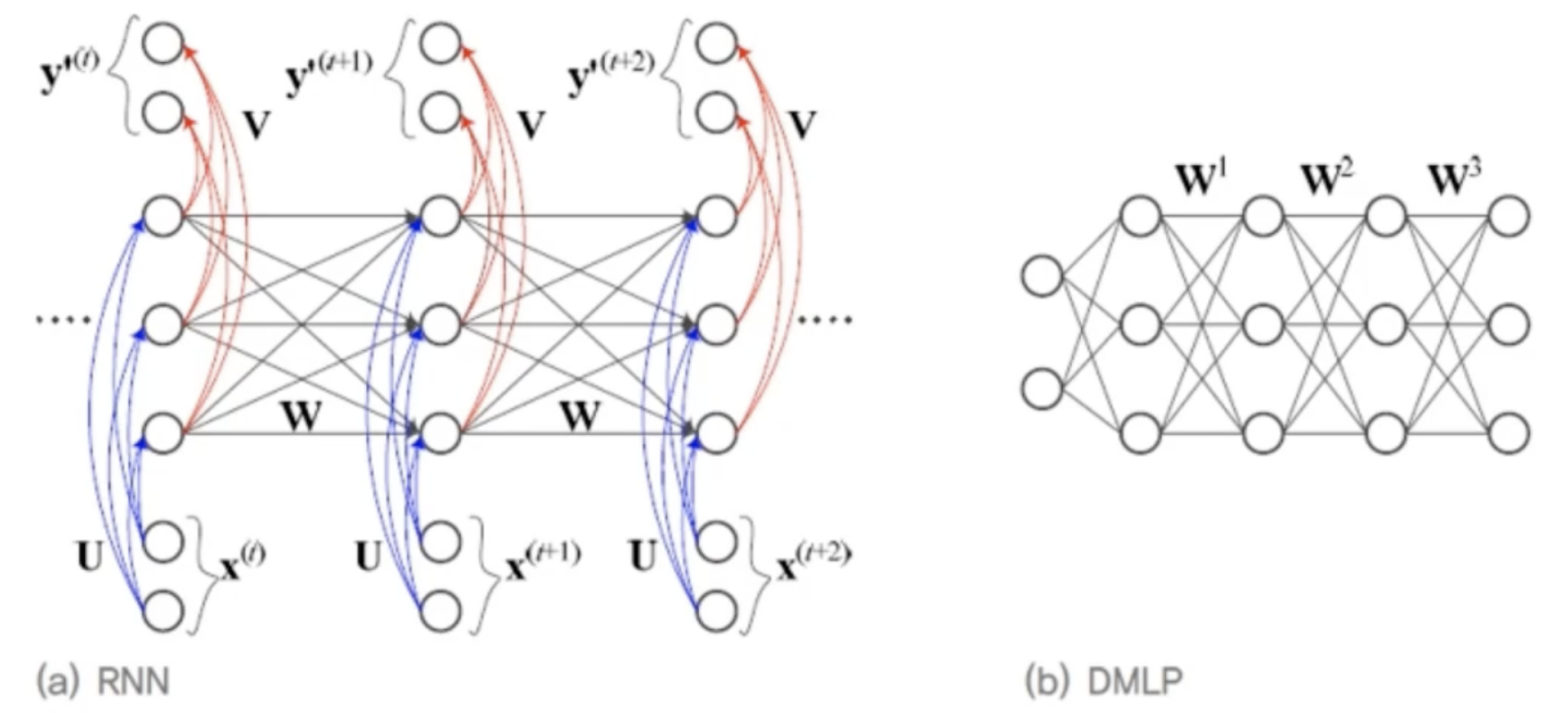
둘 다 입력층, 은닉층, 출력층을 가짐왼쪽 그림은 노드를 DMLP와 비교하기 쉽게하기 위해 수직으로 배치한것!RNN은 샘플마다 은닉층의 수가 다름DMLP는 왼쪽에 입력, 오른쪽에 출력이 있지만, RNN은 매 순간 입력과 출력이 있음RNN은 가중치를 공유함DMLP의 가중
40.[딥러닝] RNN(양방향)

왼쪽에서 오른쪽으로만 정보가 흐르는 단방향 RNN 한계위에서 "거지"와 "지지"를 구별하기 어려움(문맥상 정보가 필요한것)t순간의 단어는 앞쪽 단어와 뒤쪽 단어 정보를 모두 보고 처리됨기계번역에서도 BRNN 활용
41.[딥러닝] RNN(장기 문맥 의존성)
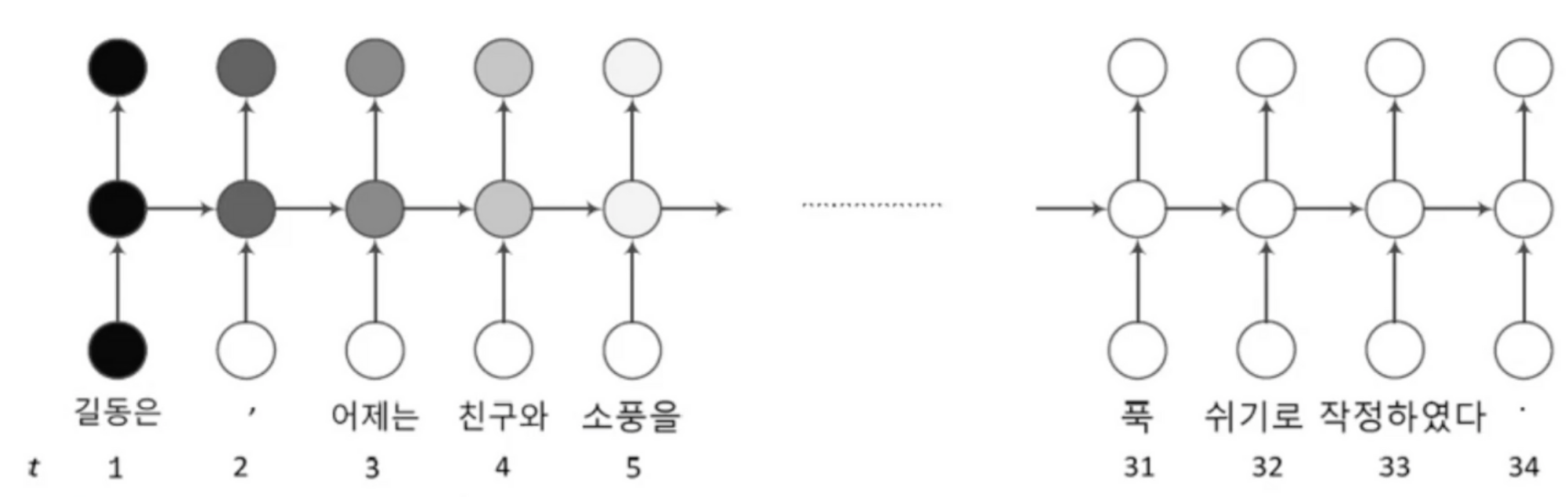
위 문장에서 첫번째 '길동은'과 32번째 '쉬기로'는 아주 밀접한 관련이 있음관련된 요소가 멀리 덜어진 상황경사 소멸(W요소가 1보다 작을 때)경사 폭발(W요소가 1보다 클때)RNN은 DMLP,CNN보다 심각하게 발생\- 긴 입력 샘플이 자주 발생하기 때문\- 가중치
42.[딥러닝] RNN(LSTM)
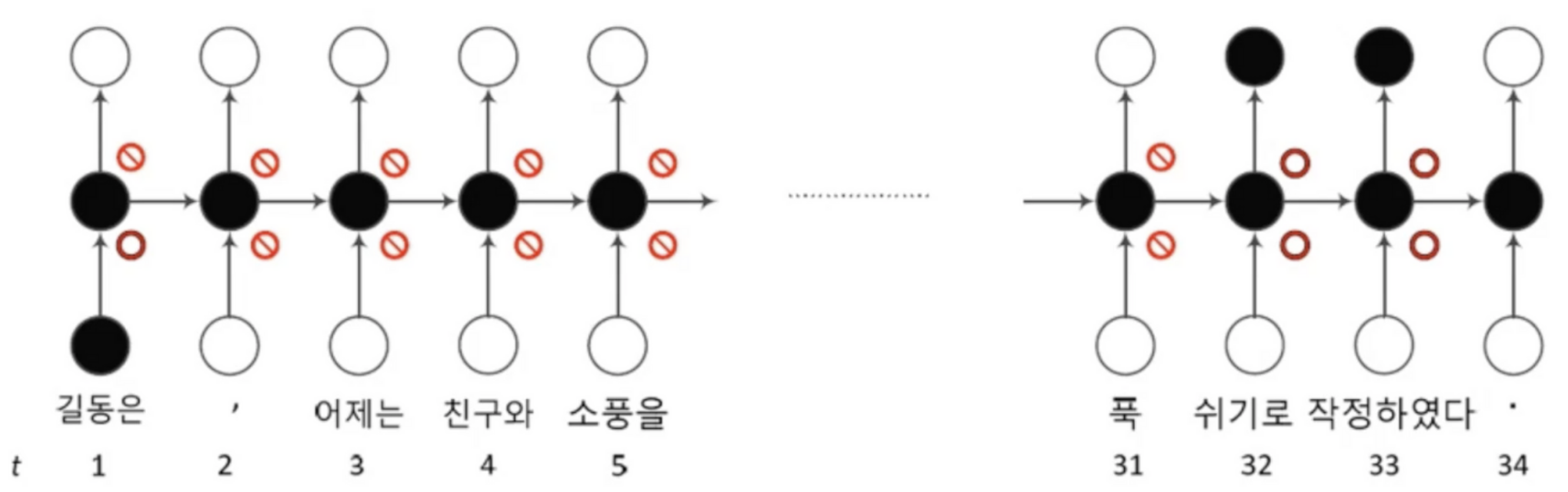
개패구를 열면 신호가 흐르고, 닫으면 차단됨위 사진을 보면 t=1에서 입력만 열렸고 t=32,33에서는 입력과 출력이 모두 열림0,1 사이 실수 값으로 개폐정도를 조절 <- 이 값은 학습으로 알아냄메모리 블록(셀): 은닉 상태(hidden state) 장기 기억망
43.[딥러닝] RNN(LSTM-동작)
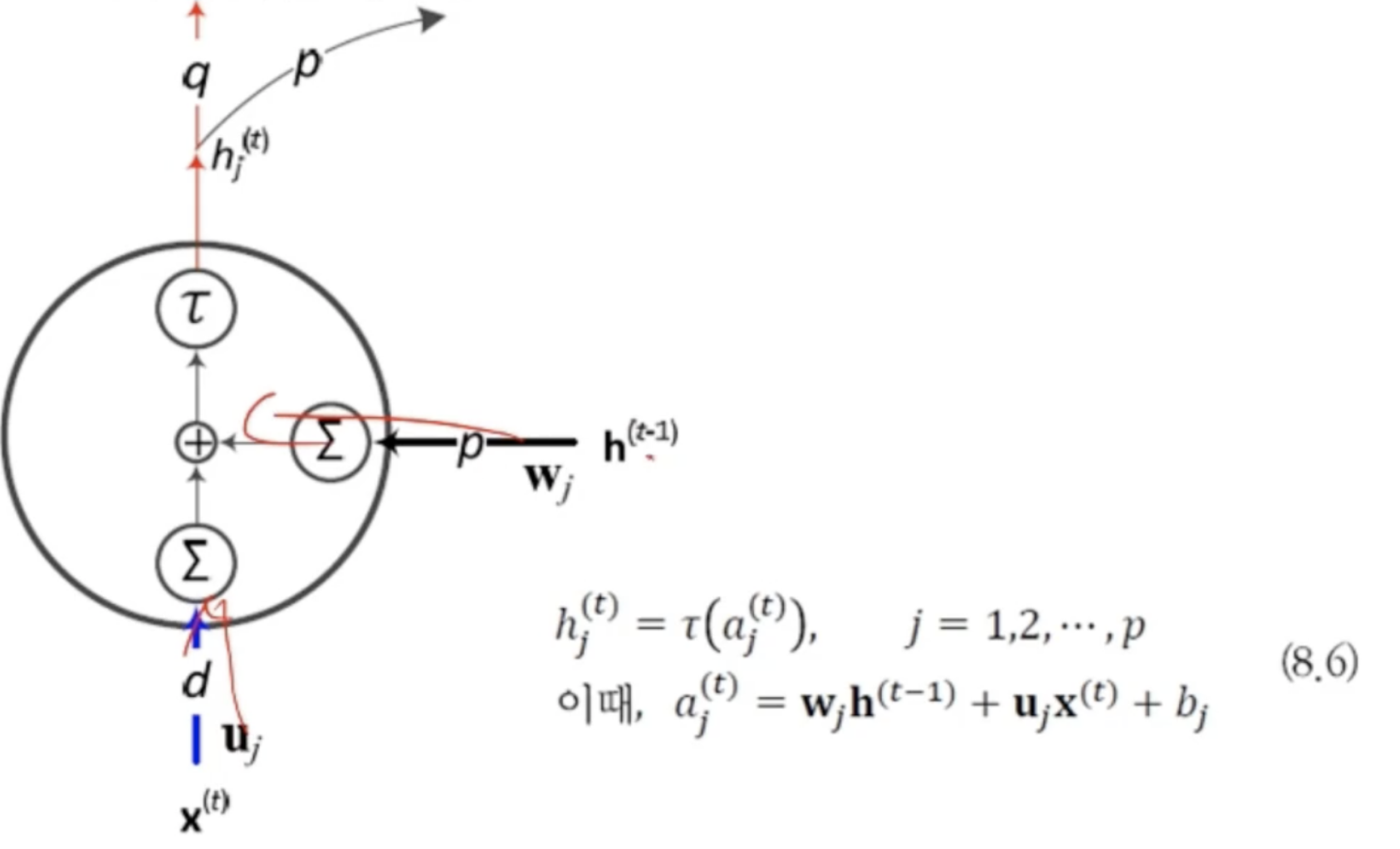
기본적인 RNN의 구조입력에서 은닉층연산을 할때 그동안 누적된 은닉층 값을 받아서 연산을 진행LSTM에서 출력 게이트와 입력 개폐구 값이 1.0으로 고정되면 RNN과 다를게 없음이 값들은 가중치와 신호 값에 따라 정해지고 개폐 정도를 조절함(RNN과 차별성)g,i,o
44.[딥러닝] RNN(LSTM-망각개폐구)
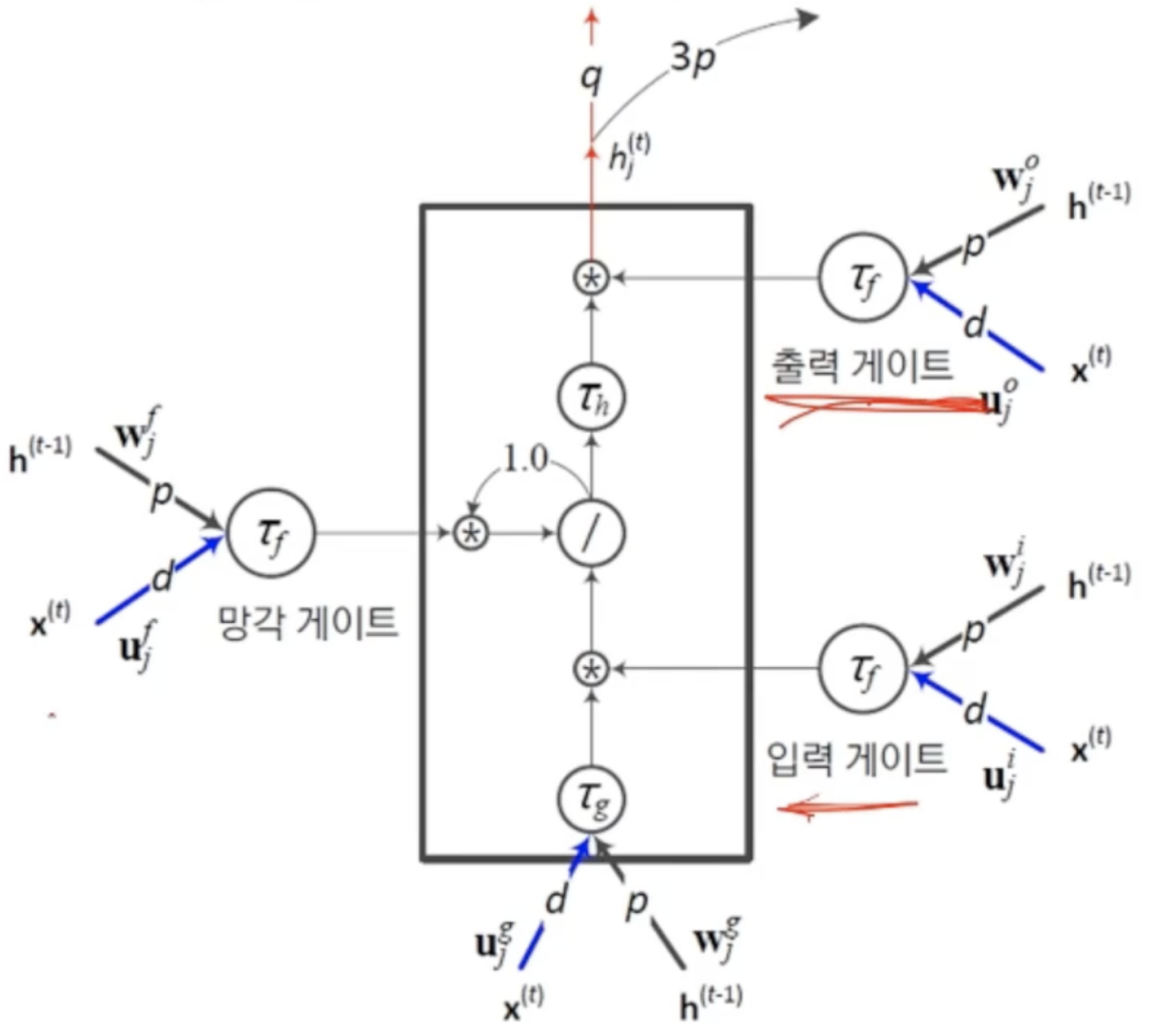
이전 순간의 상태 h^(t-1)를 지우는 효과노란색 선은 블록의 내부 상태를 3개의 개폐구에 알려주는 역할순차 데이터를 처리하다가 어떤 조건에 따라 특별한 조치를 취해야 하는 응용에 효과적-> 하나를 저장해놓고 특정 단어가뒤에 발견되면 지정된 행위를 수행
45.[딥러닝] RNN(응용사례- 언어모델)
.gif)
순환 신경망은 분별 모델뿐 아니라 생성 모델로도 활용됨장기 문맥을 처리하는 데 유리한 LSTM이 주로 사용됨문장, 즉 단어 열의 확률분포를 모형화P(자세히, 보아야, 예쁘다) > P(예쁘다, 보아야, 자세히)같은 표현들이 사용됐지만 주로 사용되는 확률분포를 따진다는것!
46.[딥러닝] RNN(응용사례- 기계번역)
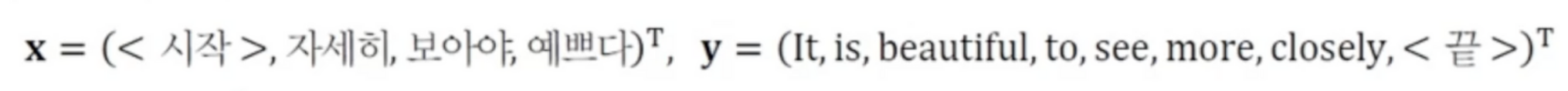
기계 번역 훈련 샘플의 예언어 모델은 입력 문장과 출력 문장의 길이가 같은데 비해 기계 번역은 길이가 서로 다른 열 대 열 문제어순이 다른 문제고전적인 통계적 기계 번역 방법의 한계로 현재 심층학습 기반 기계 번역 방법이 주류다대일 인코더 -> 일대다 디코더로 해결LS
47.[딥러닝] RNN(응용사례- 영상 주석 생성)

영상 속 물체를 검출하고 인식물체의 속성과 행위, 물체 간의 상호 작용을 알아내는 일의미를 요약하는 문장을 생성함예전에는 물체 분할, 인식, 단어 생성과 조립 단계를 따로 구현한 후 연결하는 접근방법현재는 딥러닝 기술을 사용하여 통째로 학습CNN은 영상을 분석하고 인식