순차 데이터
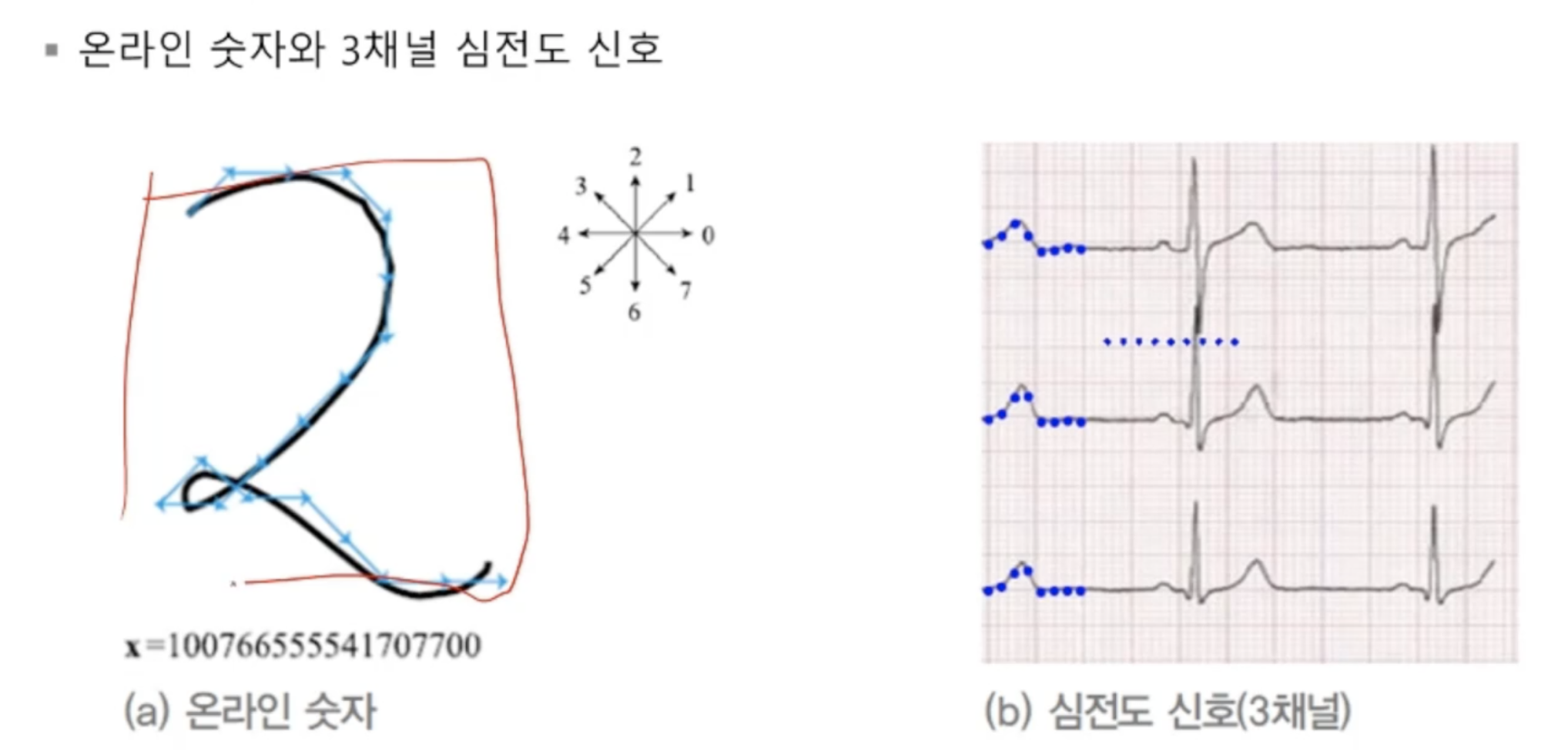
- 진행 방향을 담은 데이터
- 데이터들이 시간 순서대로 기록돼있음
순차 데이터의 일반적 표기

- 데이터 벡터 요소가 벡터
- '온라인 숫자'의 요소는 1차원, '심전도'의 요소는 3차원
- 심전도 요소는 시간당 3개의 데이터가 생성되므로 3차원
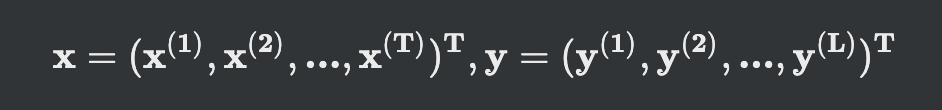
- 훈련집합은 위와 같이 표현
- x = "Aprill is the cruelest month"
- y = "사월은 가장 잔인한 달"
순차 데이터인 문자열의 표현 방법
사전(dictionary or term)을 사용하여 표현
- 사람이 많이 사용하는 단어를 키값으로 구축된 딕셔너리
- 주어진 데이터를 분석해 데이터에 등장한 단어 추출해 구축
- 결국 단어의 수만큼의 차원을 만들어둠(원핫코드랑 비슷한느낌)
- 사전을 사용한 데이터 표현 방법
- 단어가방
- 원핫코드
- 단어 임베딩
단어 가방

- 데이터에 등장하는 단어 각각의 빈도수를 세어 m차원의 벡터로 표현 m은 차원의 크기
- 단순 빈도수를 계산하기 때문에 문장의 시간성에 담긴 정보를 파악할 수 없음
- 한마디로 시간성 정보가 사라짐
원핫 코드
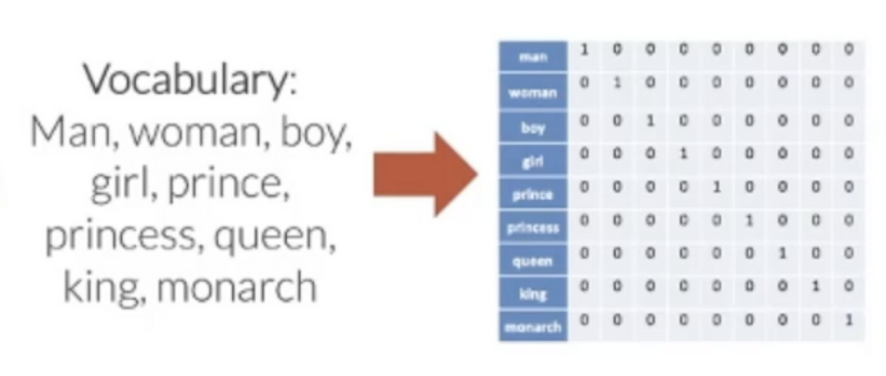
- 한 단어를 표현하기 위해 m차원 벡터를 사용해야함(비효율)
- 단어 간의 유사성 측정 불가
단어 임베딩

- 단어 사이에 상호작용을 분석, 새로운 공간으로 변환
- 변환 과정은 학습이 말뭉치를 훈련집합으로 사용해 알아냄
- 어느 한 단어와 유독 같이 등장하는 빈도가 잦은 단어를 관련 단어라고 하는 개념?
순차 데이터의 특성
특징이 나타나는 순서가 중요
- 대표적으로 "아버지가 방에 들어가신다."를 "아버지 가방에 들어가신다."로 바꾸면 의미가 크게 훼손
- 비순차 데이터에서는 순서를 바꿔도 무방
샘플마다 길이가 다름
- 입력 차원이 샘플마다 다름
- 순환 신경망은 은닉층에 순환 연결을 부여하여 가변 길이 수용
문맥 의존성
- 비순차 데이터는 공분산이 특징 사이의 의존성을 나타냄
- 순차 데이터에서는 공분산은 의미 없고, 대신 문맥 의존성이 중요함
- "그녀는 점심때가 다 되어서야 ... 점심을 먹었는데, 철수는 ..."에서 "그녀는"과 "먹었는데"는 강한 문맥 의존성을 가짐
- 특히 이 경우 둘 사이의 간격이 크므로 장기 의존성이라 부름 <-LSTM으로 처리

컴퓨터가 좋아