
ERD
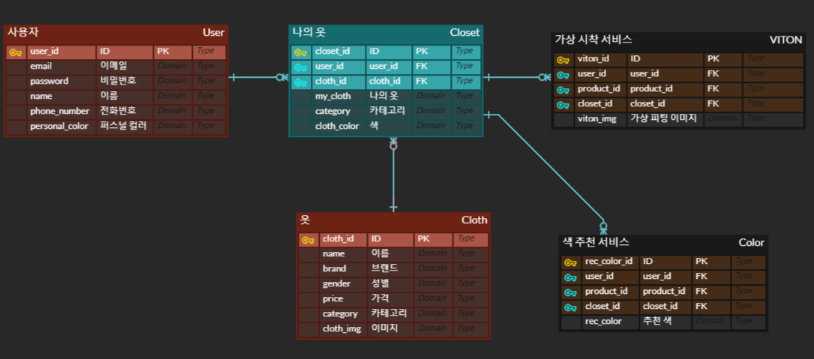
사용자와 옷 엔티티 사이에 옷장(나의 옷) 엔티티를 추가해 Cross Entitiy를 구성했다. (다대다 관계이기 때문에)
- 사용자 테이블
- 옷 테이블
- 옷장 테이블
- 가상시착 테이블
- 색 추천 테이블
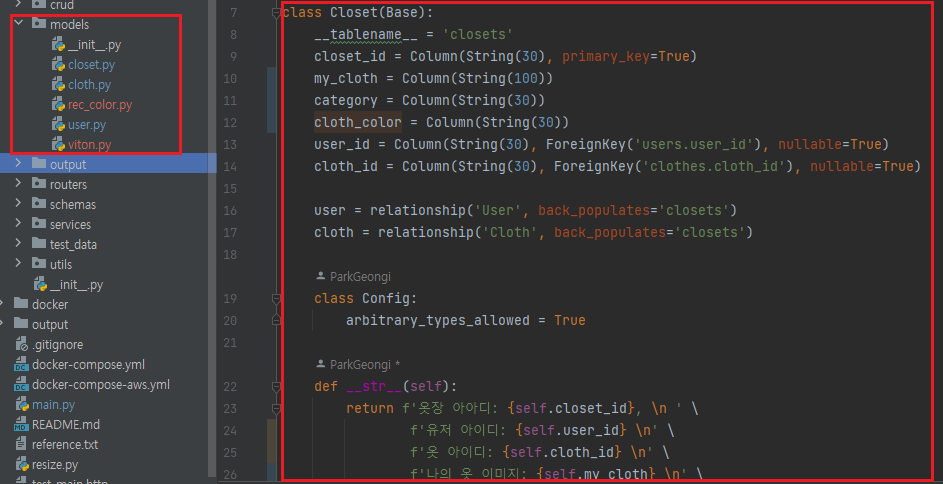
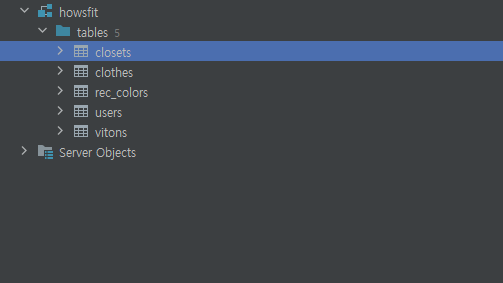
테이블 생성
가상 피팅 서비스
출처
https://github.com/sangyun884/HR-VITON
http://www.ekais.or.kr/sub03/sub07.php가상 피팅 기술에는 컴퓨터 비전 기술과, Gan 기술이 접목된 Virtual Try On(VITON) 기술이 사용된다.
가상 피팅을 위해 사용한 모델은 HR-VITON 모델이다.
HR-VITON은 condition generator와 Try-On Image Generator 두가지로 구성되어 있다.
condition generator을 통해 옷이 의복될 영역과, 워핑된 옷 이미지가 생성된다. 의복될 영역이란 상의를 바꾼다고 했을 때 바뀔 상의의 영역을 나타내며, 또한 워핑된 옷이란 바뀔 영역에 맞게 옷이 변형되는 것을 말한다.
Image Generator는 condition generator의해 생성된 영역에 옷을 생성하는 모델로 최종 이미지가 생성된다.
더 자세한 설명은 출처를 통해 확인가능하다.
Dataset
Dataset 출처: AI-Hub 패션 상품 및 착용 영상
AI-Hub 패션 상품 및 착용 영상을 사용해 VITON 모델을 한국 패션 시장에 존재하는 의상에 더욱 알맞은 모델이 되도록 Fine Tuning 시킬 예정이다.구축 내용 및 제공 데이터량
스튜디오 패션 영상(모델 사진) 6,741,328건
스튜디오 패션 영상 모델 키포인트: 120,936건
스튜디오 패션 영상 모델 semantic영역: 120,936건
패션상품 및 패션영상 페어: 117,270건
패션 상품 대표 사진(제품 사진) 40,036건
패션 상품 키포인트 : 40,036건
패션 상품 semantic 영역: 40,036건
import glob
import os
import json
import shutil
class MatchCloth:
def classification(self):
img_dir = os.listdir('./Model-Image_deid')
for img_name in img_dir:
if img_name.split('_')[-1] == '000.jpg':
shutil.copy(f"./Model-Image_deid/{img_name}", f"./Model-Image-deid-front/{img_name}")
def process(self):
img_dir = os.listdir('./Model-Image-deid-front')
with open("wearing_info_train.json") as f:
wearing_infos = json.load(f)
for fname in img_dir:
for wearing_info in wearing_infos:
if wearing_info["wearing"] == fname:
cloth_name = wearing_info["main_top"]
shutil.copy(f'./Item-Image/{cloth_name}_F.jpg', f'./cloth/{str(i).zfill(5)}.jpg')
shutil.copy(f'./Model-Image_deid/{fname}', f'./image/{str(i).zfill(5)}.jpg')모델 정면 이미지를 추출하고, “wearing_info_train.json” 데이터를 참고하여 상품 이미지과 모델 이미지의 파일 명을 일치시키는 방법으로 데이터셋을 재구성하였다. 그 결과, 트레인 세트 19,289쌍 및 테스트 세트 2,383쌍을 구축할 수 있었다.
VITON 기술을 구현하기 위해 크게 3가지 단계로 작업을 나누어 진행하였다.
1. Data Preprocessing
2. Train
3. Test
1. Data Preprocessing
Data Preprocessing은 6가지로 구분하여 진행된다.
1.1 Image Resize
HR-VITON 훈련 사용됬던 이미지 해상도는 768X1024로 고 해상도 이미지를 사용하여 훈련을 진행하였다. AI 허브에서 받아온 이미지를 전처리하는 과정이 필요했다.
AI 허브 이미지는 720X1280 이었기 때문에 opencv 라이브러리를 활용해 img를 resize 해주었다.
추가: 768X1024 해상도는 너무 고 해상도 이미지라 훈련에 하드웨어적 한계가 있었다. 더 낮은 해상도에서 훈련이 가능하도록 코드 수정 중이다. ->더 낮은 해상도에서 VITON TEST가 가능하다는 것을 알았다. 하지만 Train은 아예 새로 훈련시키는 것이 아니면 최조 들어가는 이미지는 768X1024 이어야 한다.
1.2. Openpose
출처 : https://github.com/CMU-Perceptual-Computing-Lab/openpose
HR-Viton Preprosessing 파일을과 Openpose 공식 Github를 참고했다.
Openpose는 인간 자세 예측(Human Parse Estimation)의 한 분야로 실시간으로 인체의 움직임을 추출하고 추적하는 라이브러리이다. 쉽게 이야기하면 인간의 스켈레톤을 감지하고 추정하는 작업을 하는 것이다. 이를 통해, 인간의 신체 부위에 대한 좌표, 크기, 방향 등의 정보를 담은 스켈레톤과 관련된 정보를 포함하는 이미지 파일과 이후의 전처리 과정인 agnostic 이미지 추출을 위한 json 파일을 얻을 수 있다. openpose는 사용하는 OS에 맞는 빌드를 구축할 수 있다.
Windows 환경에서 Openpose 빌드하기 위한 방법은 다음과 같다.
a. 기본 환경 설정
- cuda 환경 세팅
- cmake 다운로드 https://cmake.org/download/
- Microsoft Visual C++ 14.0
b. Build In Powershell
git clone -q --branch=master GitHub - CMU-Perceptual-Computing-Lab/openpose: OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation c:\openpose
cd openpose
git checkout -qf 2034f9c07526b885c16ba94eec4a4bd6cc8787c3
mkdir build
cd build
cmake -DGPU_MODE=CUDA -G "Visual Studio 16 2019" -A x64 ..
cmake --build . --config "Release”
mkdir artifacts
mkdir artifacts/bin
mkdir artifacts/examples
mkdir artifacts/examples/media
mkdir artifacts/include
mkdir artifacts/lib
Get-ChildItem -Path build/x64/Release/.exe -Recurse -File | Copy-Item -Destination artifacts/bin
Get-ChildItem -Path build/x64/Release/.dll -Recurse -File | Copy-Item -Destination artifacts/bin
Get-ChildItem -Path build/bin/.dll -Recurse -File | Copy-Item -Destination artifacts/bin
Get-ChildItem -Path examples/media/ -Recurse -File | Copy-Item -Destination artifacts/examples/media
Copy-Item include/openpose -Recurse -Destination artifacts/include/
Copy-Item 3rdparty/windows/opencv/include/opencv2 -Recurse -Destination artifacts/include/
Get-ChildItem -Path build/.lib -Recurse -File | Copy-Item -Destination artifacts/lib
Get-ChildItem -Path 3rdparty/.lib -Recurse -File | Copy-Item -Destination artifacts/lib
Copy-Item models -Recurse -Destination artifacts/c. 결과
CLI
openpose.exe --image_dir {image_path} --hand --disable_blending --display 0 --write_json {save_path} --num_gpu 1 --num_gpu_start 0
Origin Output Json 파일
총 25 Keypoints로 구성된 Json파일과, 이미지를 얻을 수 있다.



d. 추가 사항
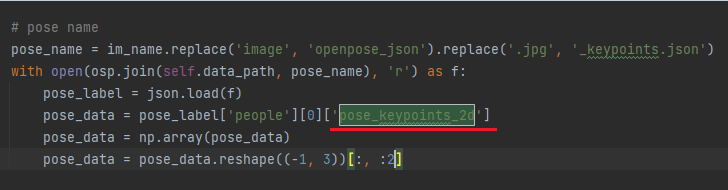
Viton의 cp_dataset.py 코드를 보면
pose_keypoints_2d가 사용되기 때문에 CLI 명령어의 --hand는 생략해도 된다.
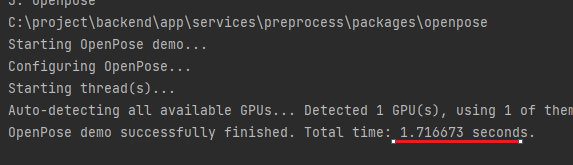
2080 GPU 1개를 사용했을 때 1초에 1장씩 Openpose 전처리가 가능하다.
현재 에러 사항
Openpose를 진행할 때 Windows로 Openpose를 실행하는 방법으로 이미지 전처리하여, AWS 리눅스 환경에서 실행이 안되는 문제가 발생했다.
3. Densepose
a. 기본설정
Densepose 기능을 지원하는 detectron2의 공식 버전은 Windows를 지원하지 않는다.
하지만 다음 링크의 방법과 아래의 추가적인 조치를 따르면 Windows에서도 사용할 수 있다.
https://dgmaxime.medium.com/how-to-easily-install-detectron2-on-windows-10-39186139101cMSVC를 설치가 필요하다. Visual Studio를 통해 설치가 가능하다. 아래 따론 MSVC 14 버전만 받을 수도 있다.
MSVC 14.00
b. Build In Powershell
공식 Git Hub를 통해 Densepose 사용이 가능하다. 아래와 같이 실행하면 된다.
git clone https://github.com/facebookresearch/detectron2.git
cd detectron2
pip install -e .git clone 후 코드 수정이 필요하다.
참조 : Dense pose 코드 수정
For getting same input as HR-VITON, change ./densepose/vis/densepose_results.py in line 320
change ./densepose/vis/base.py, line 38
To save file with name kept and in directory, change apply_net.py, line 286 and 287 to below
위의 3가지 코드를 수정해야 viton을 위한 densepose 이미지가 만들어 진다.
c. 결과
python ./apply_net.py show ./configs/densepose_rcnn_R_50_FPN_s1x.yaml https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl image_path dp_segm -v --opts MODEL.DEVICE cpuapply_net.py를 실행하여 Dense pose 이미지를 얻을 수 있다.
Origin Output
2080 GPU 사용시 약 1~2초 시간이 소요된다.


4. Human parse
사람 영역을 신체부위나 의류 부분과 같은 세부 영역으로 나누어 분리하는 Segment 기술 중 하나이다.
a. 기본설정
python=3.6
CUDA 10.0
-> 지금까지 python 3.9, CUDA 11.2 환경에서 개발을 진행하였는데 Human parse를 위해서는 아예 다른 설정값이 필요했다. 전처리를 하나의 환경에서 처리 못하기 때문에 나중에 dokcer와 AWS 안에서 문제가 발생 할것이라고 예상되어 다른 Parse 방법을 찾아 보았지만 찾기 힘들었다.
git clone https://github.com/Engineering-Course/CIHP_PGN.git
cd CIHP_PGN
pip install -r requirements.pipREADME.md Inference를 참고하여 pre-trained model을 저장하고 test_pgn 실행 시 나타나는 경로 오류를 잡아주면 ~/output 경로에 자료가 저장된다.
b. 결과
| Origin | Output |
|---|---|
|  |

왼쪽 output이 컬러라 24bit인줄 알았는데 8bit 이미지 였다.
따라서 CIHP_PGN의해 만들어진 parse이미지를 gray로 변환해 주었다.
| gray |
|---|
|

c. 추가
human parser는Graphonomy을 통해 똑같은 가상 환경에서 전처리가 가능했다. 하지만 GPU를 사용해야 정확한 parse 이미지가 나오기 때문에 AWS에서는 사용이 불가능 할 것 같다.
5. Parse agnostic
HR-VITON의 get_parse_agnostic.py 파일을 통해 전처리가 가능하다.
openpose와, human parse data를 사용하기 때문에 위의 전처리 과정 후 data 생성이 가능하다.
a. 결과
Gray Color 옷 입은 부분을 제거하고 제거한 부분을 Gan을 통해 생성해 낸다.


6. Cloth Mask
참조
https://blog.csdn.net/weixin_42815846/article/details/128510223
https://github.com/OPHoperHPO/image-background-remove-tool
cloth_mask_test.py 코드로 생성했다.
옷 이미지에서 옷 부분만을 mask하는 작업이다.
a. 결과
Origin Output


b. 추가
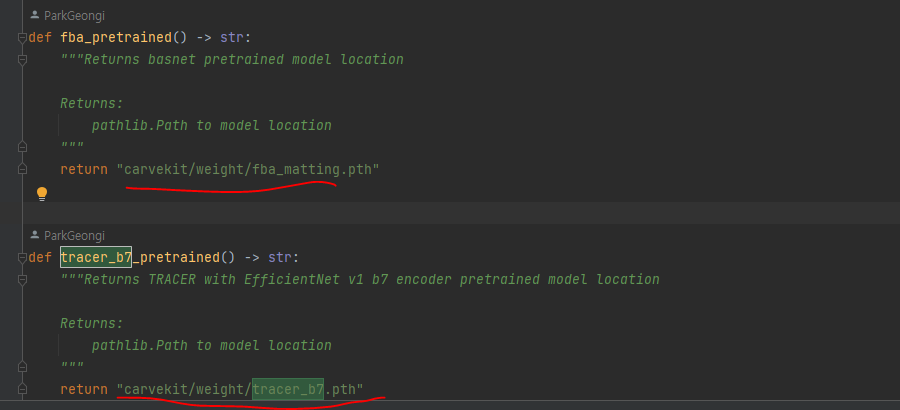
weight 파일을 다운로드 받아 사용해 로딩 시간이 너무 길어져 미리 pth 파일을 받아 경로를 잡아주었다.
tracer_b7.pth
fba_16.pth
2. HR-VITON Training
HR-VITON은 condition generator와 Try-On Image Generator 두가지로 구성되어 있다.
condition generator을 통해 옷이 의복될 영역과, 워핑된 옷 이미지가 생성된다. 의복될 영역이란 상의를 바꾼다고 했을 때 바뀔 상의의 영역을 나타내며, 또한 워핑된 옷이란 바뀔 영역에 맞게 옷이 변형되는 것을 말한다.
Image Generator는 condition generator의해 생성된 영역에 옷을 생성하는 모델로 최종 이미지가 생성된다.
| txt 파일 |
|---|
 |
Train을 위해서는 앞서 전 처리한 사진, Json파일과, train_pairs.txt가 필요한데, train_pairs.txt에는 사람 이미지와, 옷 이미지의 .jpg 이름이 쌍으로 써 있다.
1. Condition generator
- 하이퍼 파라미터 설정
HR-VITON은 Argparse를 이용해 하이퍼 파라메터를 설정해 주고 있다.
G,D lr: 0.0002 , batch size: 1, train step: 1000 으로 설정하고 나머지는 default 로 설정해 준 값을 이용했다. - CLI
공식 git hub에 나와있는 CLI 명령어로 학습을 진행했다.
python3 train_condition.py --cuda {True} --gpu_ids {gpu_ids} --Ddownx2 --Ddropout --lasttvonly --interflowloss --occlusion-
결과
pth tensorboard 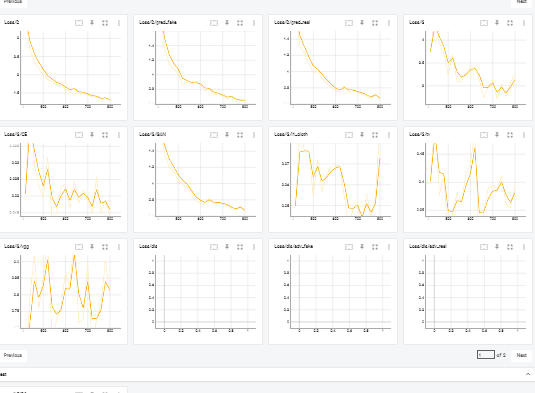
정상적으로 학습이 진행되는 것을 확인 할 수 있었다.
2. Image Generator
-
하이퍼 파라미터 설정
마찬가지로 Argparse를 이용해 하이퍼 파라미터를 설정했다. bath_size와 workers 는 1로 수정하였고, dataset 경로를 잡아주고, 나머지는 default를 사용하였다.
-
CLI
tocg_checkpoint는 앞서 condition generator에서 학습 시킨 tocg_final.pth를 사용해 학습했다.
--fp16 파라미터를 사용하기 위해서 밑의 링크를 참조했다.
참조 : fp16python3 train_generator.py --cuda {True} --name test -b 4 -j 8 --gpu_ids {gpu_ids} --fp16 --tocg_checkpoint {condition generator ckpt path} --occlusion -
오류
참조 : CUDA 메모리부족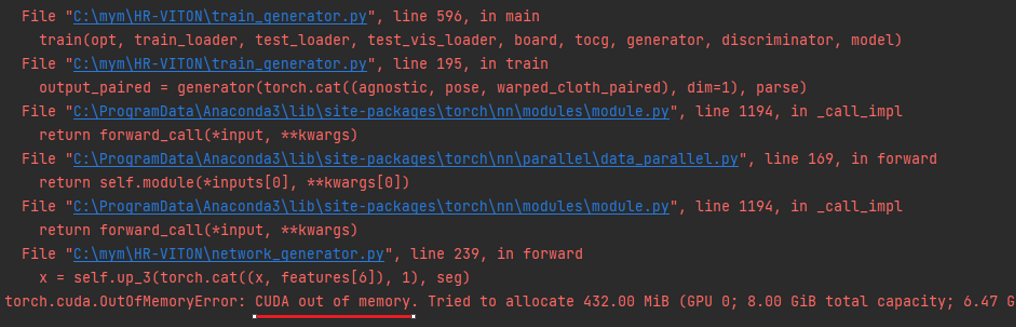
GPU를 사용해 학습을 진행하려 했지만, CUDA 메모리 부족 오류가 발생했다.
사용하고 있는 GPU의 메모리가 8GB인데 8GB를 넘게 사용해서 발생하는 오류였다.
해결 법으로 torch.no grad(), model.eval(), 배치 사이즈 조절 등을 통해 메모리 부족 현상을 해결할 수 있다고 했지만 현재 배치 사이즈도 1로 최소화 시키고, torch.no grad()와 같은 코드도 모두 적혀 있었기 때문에 해결할 수 없었다.
Train 코드의 문제인지, 정말 CUDA 메모리 문제 인지를 알기 위해 CPU 만으로 학습이 가능하도록 코드를 수정하였다.
- CPU를 사용해 학습
딥러닝 모델을 학습할 때는 GPU나, CPU 둘 중 하나 만을 이용해 학습 시켜야 한다. GPU의 하드웨어 적 성능 문제로 학습이 불가능 하기 때문에 CPU만으로 학습을 진행 시킬 수 있도록 코드를 수정했다.CPU만으로 학습하기 위해서는 학습 코드에 정의 되어있는 모델, 텐서가 모두 같은 device로 정의되어 있어야 한다.
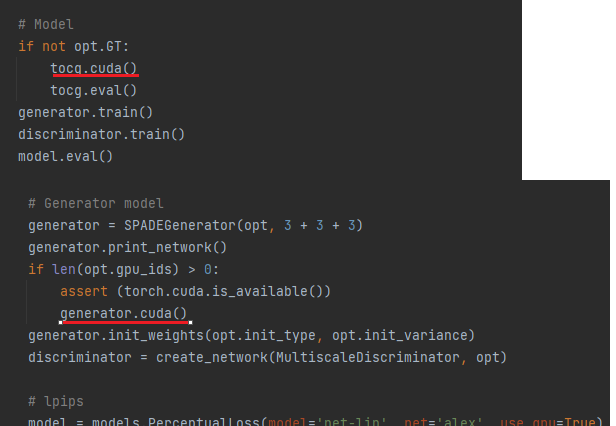
위의 사진과 같이 .cuda()를 통해 GPU에 할당 되어 있는 것들을 모두 제거해 CPU로 할당되도록 코드를 수정 하였다.
위와 같은 에러가 나오지 않을 때까지 코드를 수정해주었다.

- 결과
| pth | tensorboard |
|---|---|
 | 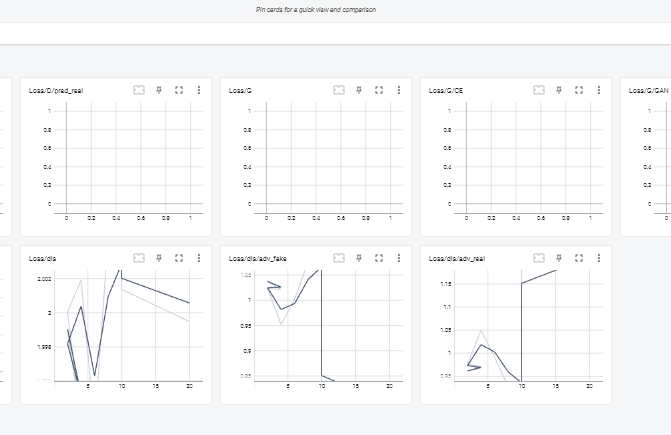 |
Train 코드가 오류 없이 진행되는지 확인하기 위해 dataset은 450개, save count 파라미터를 5으로 train step을 20으로 줄이고 train 시켰다.
image generator로 gen.pth가 생성 되는 것을 확인했고, tensorboard를 통해 Loss를 확인할 수 있었다.
이미지 1장 당 약 40초가 걸려 학습하는데 너무 오랜 시간이 걸렸다. CPU 환경으로 학습을 진행하기는 너무 어려웠다.
어쩔 수 없이 HR-VITON 공식 깃허브에 있는 미리 학습된 pth 모델을 통해 가상 피팅 서비스를 제공하기로 했다.
3. HR-VITON Test
초기 목표는 fine tuning 시킨 tocg.pth 와 gen.pth를 가지고 Test 하려고 했지만, PC 하드웨어적인 문제로 공식 Git hub에 pretrain 된 모델을 받아와 사용해 Test를 진행하였다.
- 평가 지표
- SSIM(Structural Similarity Index Map)
- LPIPS(Learned Perceptual Image Patch Similarity)
LPIPS는 2개 이미지의 유사도를 평가하기 위해 사용되는 지표 중 하나.- FID(Frechet InceptionDistance)
- KID (Kernel Inception Distance)
Git hub에 제공된 이미지, ai hub에 제공된 이미지, 나의 이미지 총 3번을 Test 했다.
- Git hub에 제공된 이미지

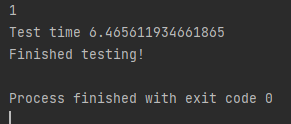
 2080 GPU 사용 환경에서 VITON을 Test하는데 약 6~7 초가 소요된다.
2080 GPU 사용 환경에서 VITON을 Test하는데 약 6~7 초가 소요된다.
- Aihub 이미지


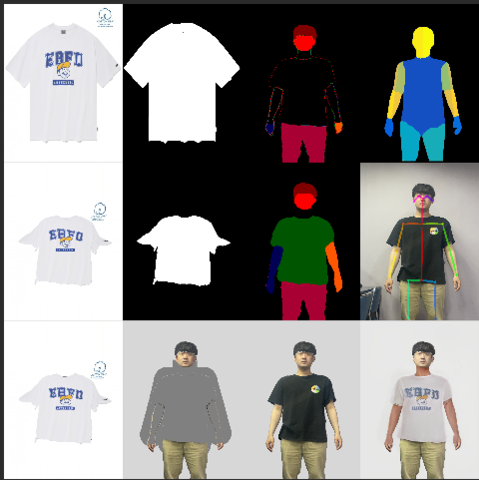
fine tuning을 하지 못해 제공된 이미지보다 Ai hub이미지의 결과물은 퀄리티가 떨어지는 것이 보였지만 어느정도 옷의 형태, 무늬 등은 생성해 냈다.
마지막으로 무신사의 옷 이미지와, 내 사진을 이용해 VITON을 테스트한 결과이다. 결과물을 확인해 보면 어느정도 가상 피팅이 이루어 진 것을 확인 할 수 있었다.
색상기반 추천 서비스
출처
https://github.com/gjtjdtn201/ShawcheckRedemption
https://github.com/ultralytics/yolov5
- 사용자가 입은 옷을 토대로 상/하의의 색 조합이 어울리는지 판단
- 사용자의 퍼스널 컬러와 옷 색이 어울리는지 판단
- 어울리지 않는 옷을 입었다면 다른 색의 옷을 추천해 주며, 사용자가 추천해준 옷 중 한 개를 선택하면, 그 옷을 가상 피팅 기술을 이용해 직접 입어본 것처럼 사진으로 보여주는 기능
전체 흐름도
현재 사용자가 입고 있는 옷을 핸드폰으로 사진 찍어 업로드 한다.
→ 사용자의 피부색, 머리 색, 눈썹 색을 통해 퍼스널 컬러(봄, 여름, 가을, 겨울)을 구분한다.
→ 업로드 한 사진에서 object detection(yolov5)를 통해 상 하의를 구분 한다.
→ 구분한 옷의 색상을 추출한다.
→ 상 하의의 색 조합을 판단한다.
→ 사용자의 퍼스널 컬러와 어울리는 색이 무엇인지 알려주고, 지금 입고 있는 옷이 어울리는 지 판단한다.
→ 사용자에게 새로운 옷을 추천하고, 가상 피팅을 할 수 있도록 한다.
1. Object Detection
사용자가 입은 옷의 색을 추출하기 전 먼저 사용자가 어떤 옷을 입었는지 확인하기 위해 yolov5 객체 탐지 모델을 사용했다.
무신사 크롤링
yolov5 학습 전 옷 이미지를 크롤링 해야했다. 무신사 사이트를 이용해 이미지를 저장 시켰다.
soup in soup.find_all('img', attrs={'class': 'lazyload lazy'}): url_list.append('https://' + soup['data-original'][2:-7] + '500.jpg')img 테그에 있는 주소에 뒤 부분을 500으로 바꾸면 500x600 해상도의 이미지를 얻을 수 있었다.
class는 총 5가지
상의 → 반팔 / 셔츠 / 니트
하의 → 청바지 / 면바지이다.
Yolov5 train
출처
https://sssbin.tistory.com/163
https://hemon.tistory.com/m/59
- labelImg를 이용해 Data 전처리
크롤링한 data들을 yolov5 형식에 맞게 전처리 해주었다.
Img Label
- Train
class 마다 100개씩 약 500개의 data로 학습을 진행해 보았다.
bachsize : 2, epoch : 100
yolov5s(가장 가벼운 모델) 모델을 사용했다. (성능은 낮지만 학습과 추론 속도가 빠르기 때문)
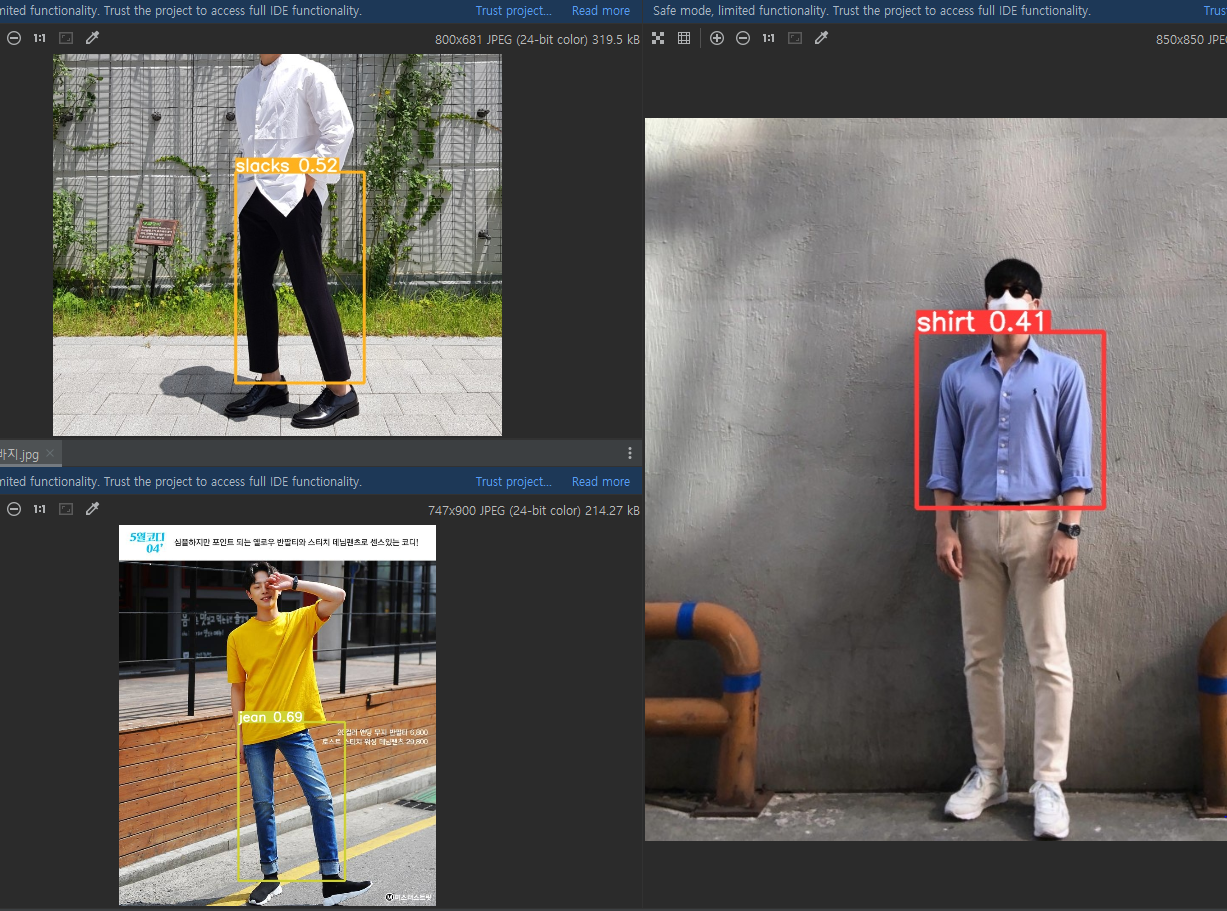
- Test
GOOD
BAD
dectect 할 때 --save-crop 파라미터를 추가해 검출한 옷을 따로 저장시켰다.
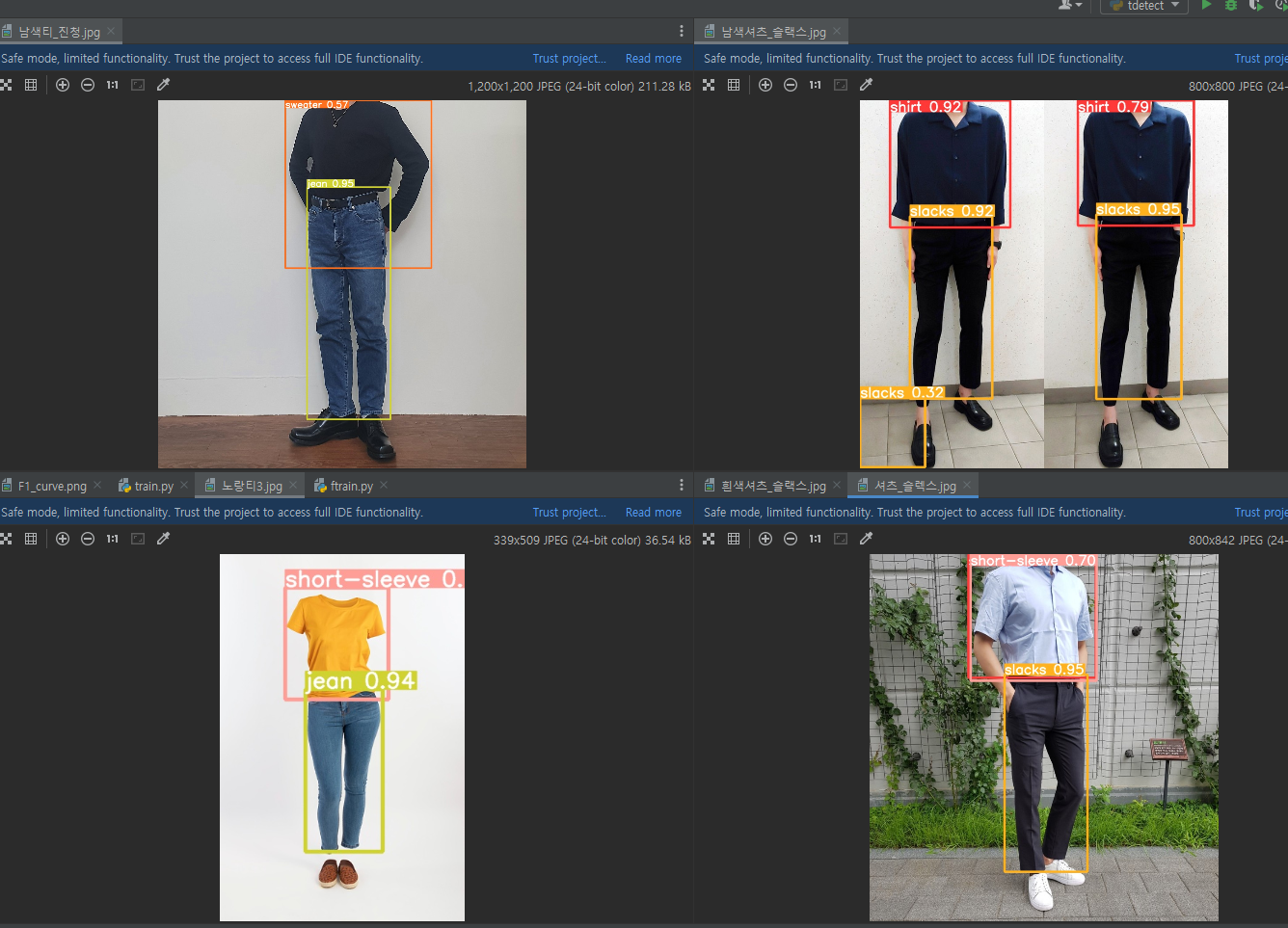
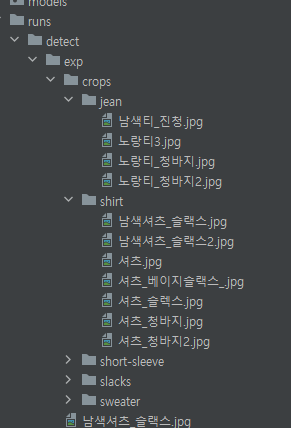
2. Color Detection
- KMeans 알고리즘을 사용해 옷 이미지에서 5가지 주요 색상을 클러스터링하고, 가장 빈도가 높은 주요 색상을 찾았다.

- Kmeans에서 나온 rgb값을 이용해 가장 가까운 CSS3 색상을 찾아낸고, 가장 가까운 색이 무슨 색인지 text로 변환하였다.
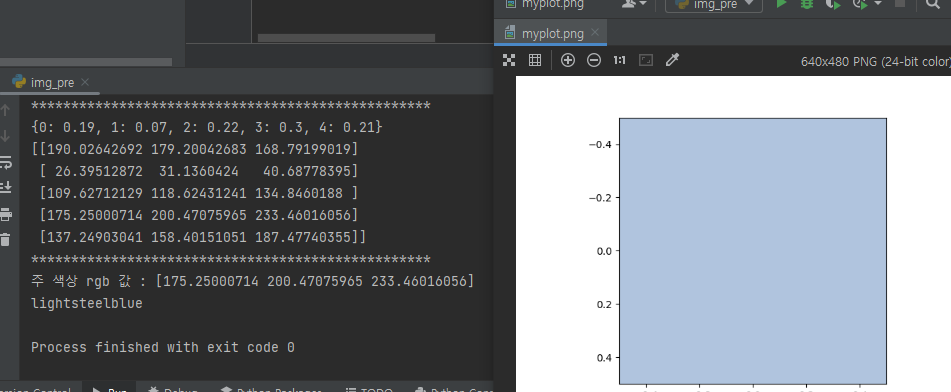
3. Personal Color
참조 https://github.com/starbucksdolcelatte/ShowMeTheColor
git clone 해 가져와 사용했다.
- OpenCv와 Dlib 라이브러리를 통해 사용자 사진에서 눈동자, 머리카락, 뺨 영역을 인식해 K-means 알고리즘으로 대표 색상을 추출한다.
- Lab 색공간의 b 값을 통해 웜톤, 쿨톤으로 분류한다.
- HSV 색공간의 S 값을 통해 봄/가을 , 여름/ 겨울을 분류한다.
4. 색 조합
색 조합
위 링크를 참고하여 기준을 세웠다.
VITON with Docker
AWS에서 서비스를 배포하기 전
Docker를 이용해 VITON 서비스를 이미지화 해 정상적으로 서비스가 진행되는지 확인하였다.
Docker 사용을 위해선 Requirement, Dockerfile, docker-compose.yml들을 정의해 주어야 했다.
- Dockerfile
FROM python:3.9
WORKDIR /app
ADD requirements.txt .
RUN python -m pip install --upgrade pip
RUN apt-get update
RUN apt-get install -y default-jdk
RUN pip install -U pip wheel cmake
RUN pip install --trusted-host pypi.python.org -r requirements.txt.txt
EXPOSE 8000
CMD ["uvicorn", "main:app", "--reload","--host", "0.0.0.0", "--port", "8000"]
- docker-compose.yml
version: "3.8"
services:
api:
container_name: "api-howsfit"
build: ./docker/api
ports:
- "8000:8000"
volumes:
- .:/app
shm_size: 3GB
command: uvicorn main:app --reload --host 0.0.0.0 --port 8000
networks:
- local-net
networks:
local-net:
driver: bridgePreprocessing in docker & fastapi
cloth mask, densepose는 docker를 사용해 이미지 처리가 가능했지만, openpose, Human parse에서 오류가 발생했다.
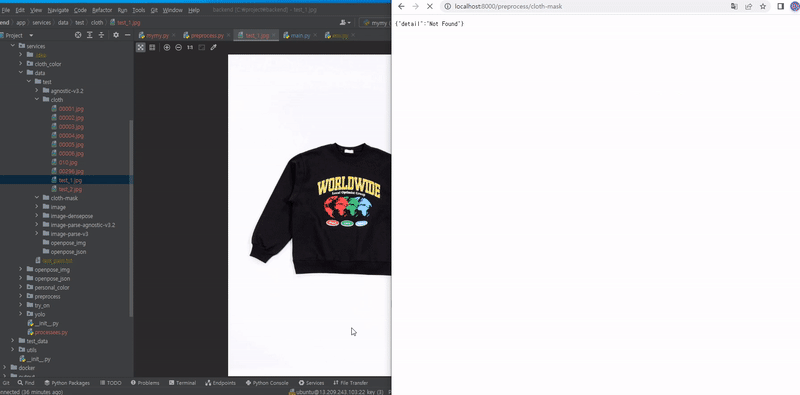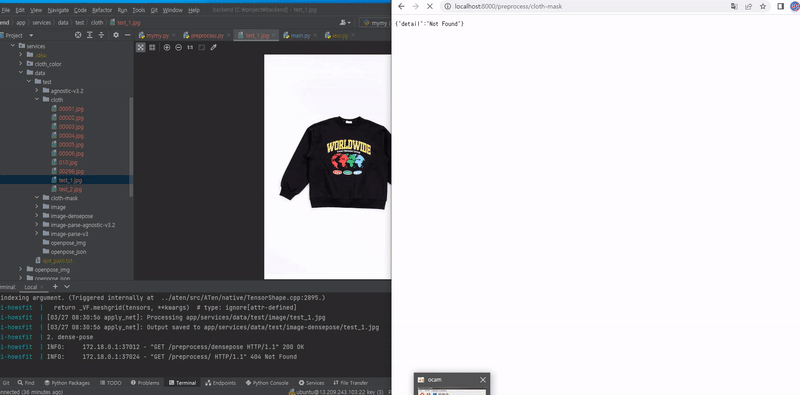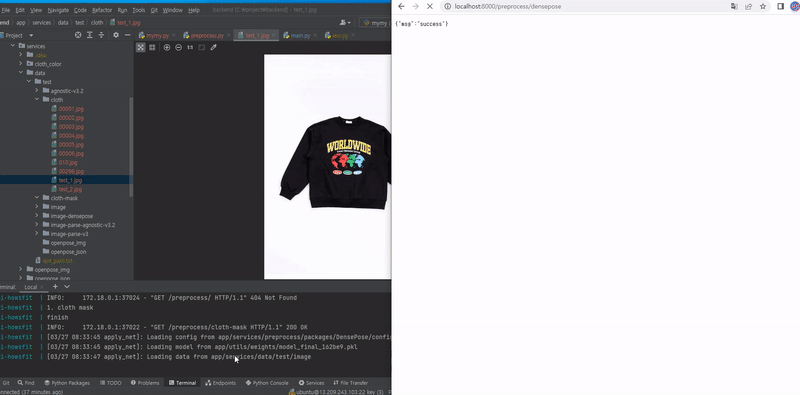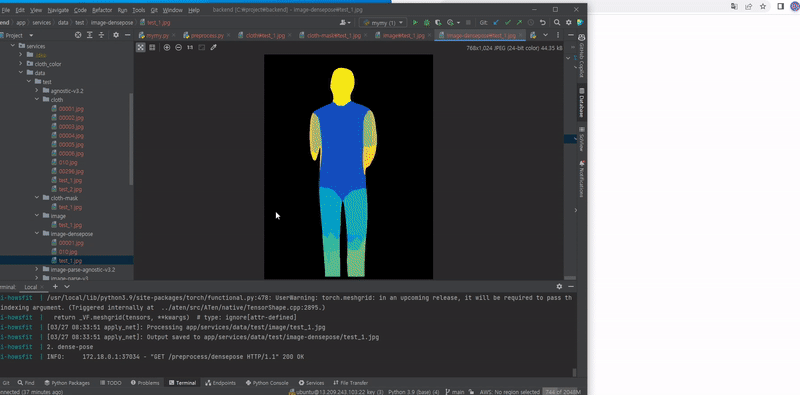
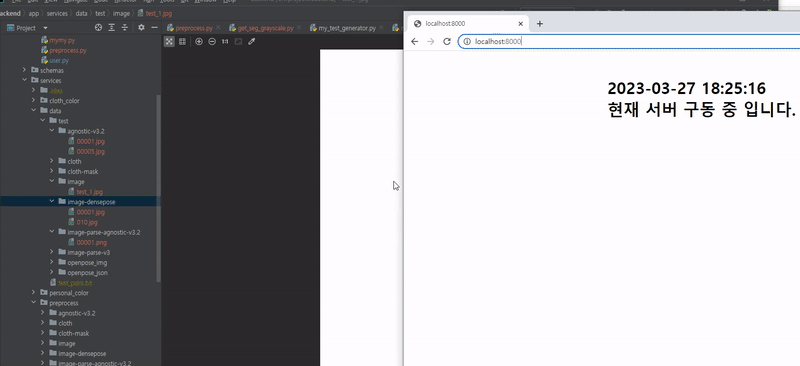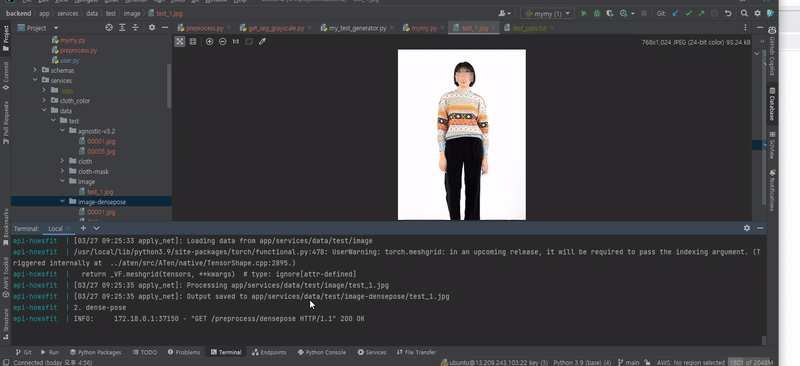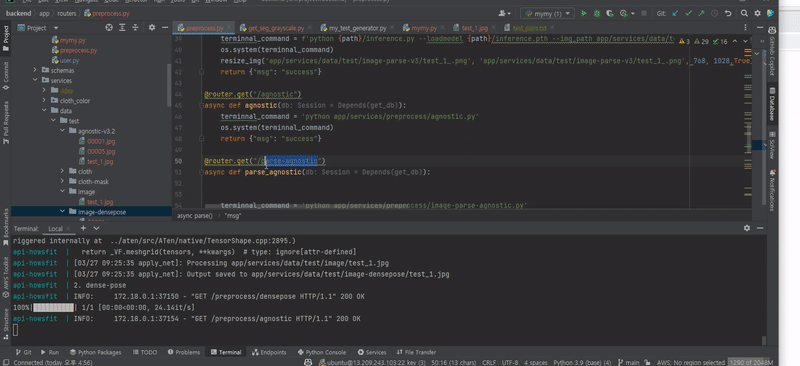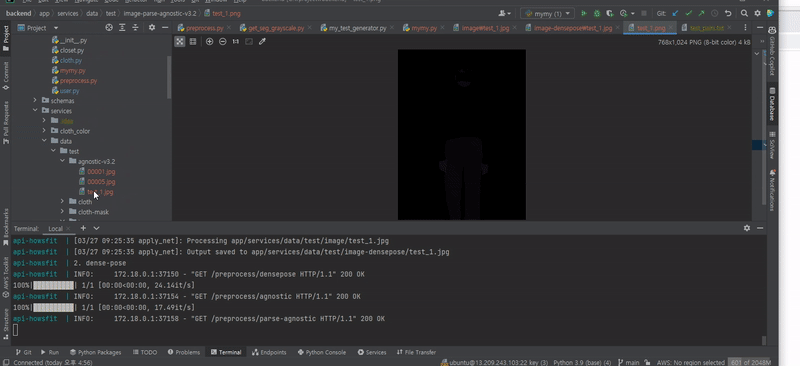
cloth mask와 densepose, agnostic을 docker로 빌드해 전처리를 하는 영상이다.


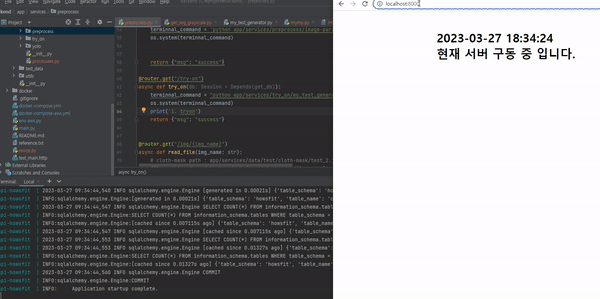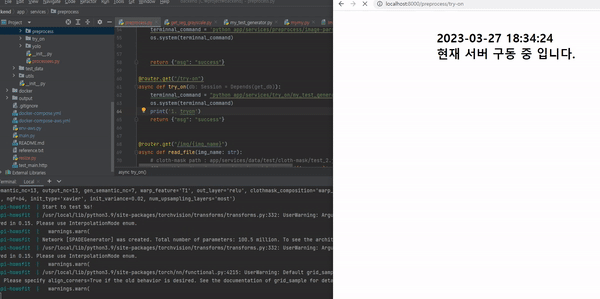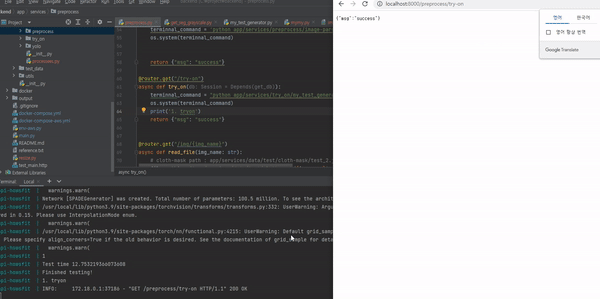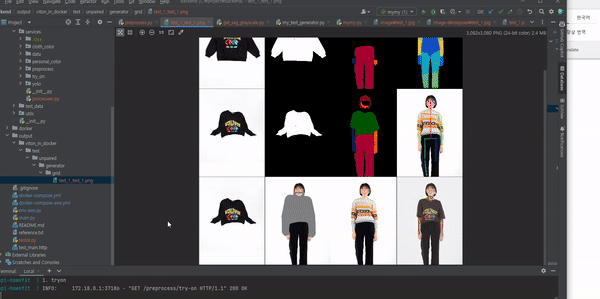
Openpose를 윈도우에서 빌드하는 방법으로 전처리했기 때문에 문제가 발생했다.
리눅스 환경에서 build하려 했지만 아직 까지 성공하지 못했다.
또한 Human parse 는 python 3.7을 사용해야 했기 때문에 설정값이 달라지는 문제가 발생했다.
일단 로컬에서 나머지 전처리 데이터를 만들고 vition을 docker 에서 진행했다.
-> openpose를 posenet으로, human parse를 Graphonomy-maste로 바꾸어 한가지 도커 이미지 안에서 모든 전처리가 가능하도록 전처리 라이브러리를 바꾸었다.
Graphonomy-master
마지막 가상피팅 viton을 docker에서 돌려봤다.
AWS Lightsail을 활용할 예정이라 GPU에서 약 6초면 가상피팅 되었던 서비스가 50초로 늘어나게 되었다. GPU가 사용가능한 EC2를 사용할지 고민중이다. -> 똑같은 전처리 사진들로 test를 한번더 했는데 50초 걸리던 가상피팅 과정이 12초로 줄어들었다. 아마도 로그가 남아있어서 그런것 같다.
