PostgreSQL의 테이블 접근 방법: 순차 스캔 분석
서론
PostgreSQL은 다양한 테이블 접근 방법을 제공하여 데이터베이스의 성능을 극대화합니다. 이전 블로그 포스트에서 PostgreSQL의 테이블 접근 방법 API와 힙 튜플과 튜플 테이블 슬롯(TTS) 간의 차이를 살펴보았습니다. 이번 포스트에서는 순차 스캔을 구현하는 데 필요한 주요 API 호출들에 대해 자세히 분석하겠습니다.
1. 순차 스캔이란?
순차 스캔은 데이터베이스에서 테이블의 모든 행을 차례대로 읽는 방법입니다.
이 방법은 테이블이 작거나 모든 데이터를 읽어야 할 때 유용합니다.
PostgreSQL은 이 순차 스캔을 구현하기 위해 몇 가지 API를 사용합니다.
예를 들어, 당신이 도서관에서 모든 책을 살펴보는 상황을 상상해 보세요. 당신은 첫 번째 책부터 시작하여 마지막 책까지 한 권씩 확인하고 있습니다. 이것이 바로 순차 스캔의 기본 개념입니다.
2. 순차 스캔에 사용되는 API
PostgreSQL에서 순차 스캔을 수행하기 위해 호출되는 주요 테이블 접근 방법 API는 다음과 같습니다
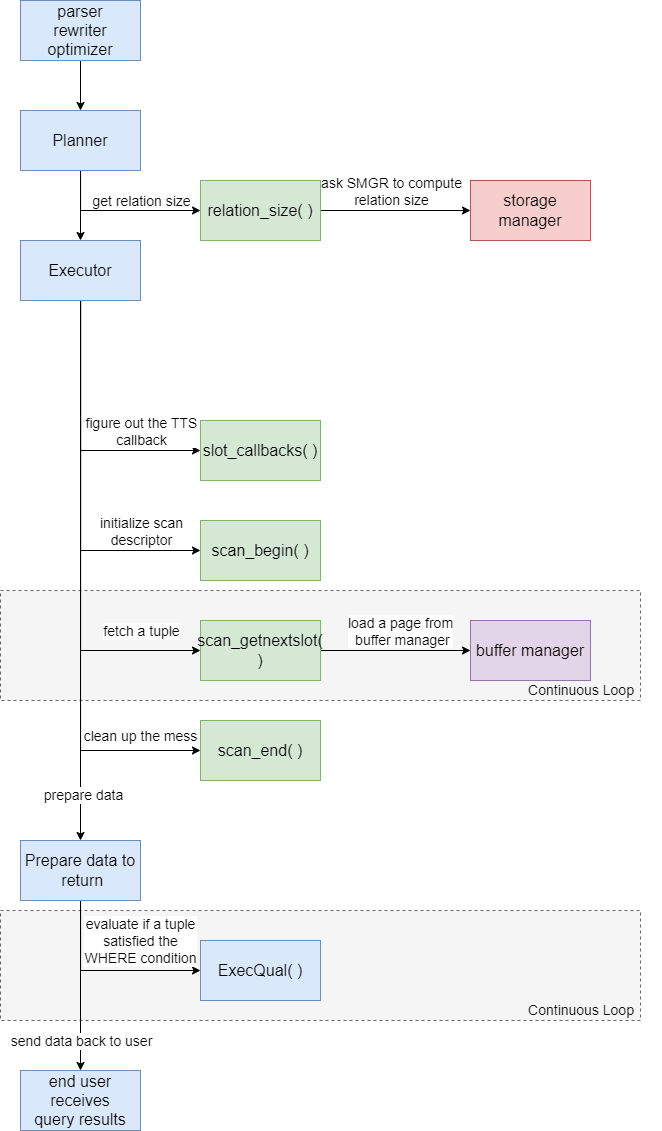
- relation_size()
- slot_callbacks()
- scan_begin()
- scan_getnextslot()
- scan_end()
이 API들은 PostgreSQL의 힙 접근 방법을 기반으로 구현되어 있으며, 각각의 역할과 기능에 대해 깊이 살펴보겠습니다.
src/backend/access/heap/heapam_handler.c에 자세히 있습니다.
2-1. table_block_relation_size(Relation rel, ForkNumber forkNumber)
이 함수는 쿼리 계획 단계에서 가장 먼저 호출되는 함수로, 주어진 관계의 물리적 크기를 확인합니다.
입력 파라미터
- Relation rel: 테이블, 인덱스 또는 뷰를 나타내는 관계.
- ForkNumber forkNumber: 관계 내 데이터 섹션을 지정합니다.
- MAIN_FORKNUM (0): 사용자 데이터를 저장.
- FSM_FORKNUM (1): 자유 공간 맵 데이터를 저장.
- VISIBILITY_FORKNUM (2): 가시성 데이터를 저장.
- INIT_FORKNUM (3): WAL-로그된 테이블을 재설정하는 데 사용.
출력
총 블록 수(기본적으로 8KB 크기)를 반환하여 쿼리 최적화에 도움을 줍니다.
2-2. heapam_slot_callbacks()
이 함수는 적절한 TTS 작업을 반환하여 실행자가 힙 튜플을 TTS로 변환할 수 있도록 합니다.
const TupleTableSlotOps TTSOpsBufferHeapTuple = {
.base_slot_size = sizeof(BufferHeapTupleTableSlot),
.init = tts_buffer_heap_init,
.release = tts_buffer_heap_release,
.clear = tts_buffer_heap_clear,
.getsomeattrs = tts_buffer_heap_getsomeattrs,
.getsysattr = tts_buffer_heap_getsysattr,
.materialize = tts_buffer_heap_materialize,
.copyslot = tts_buffer_heap_copyslot,
.get_heap_tuple = tts_buffer_heap_get_heap_tuple,
/* A buffer heap tuple table slot can not "own" a minimal tuple. */
.get_minimal_tuple = NULL,
.copy_heap_tuple = tts_buffer_heap_copy_heap_tuple,
.copy_minimal_tuple = tts_buffer_heap_copy_minimal_tuple
};반환 값
- TupleTableSlotOps 구조체로, TTS에 대한 다양한 동작을 정의합니다.
주요 구성 요소
- .base_slot_size: 슬롯의 기본 크기.
- .init: 슬롯 초기화 함수.
- .release: 슬롯 자원 해제 함수.
- .clear: 슬롯을 지우는 함수.
- .getsomeattrs: 일부 속성을 가져오는 함수.
- .getsysattr: 시스템 속성을 가져오는 함수.
- .materialize: 슬롯을 물리화하는 함수.
- .copyslot: 슬롯을 복사하는 함수.
- .get_heap_tuple: 힙 튜플을 가져오는 함수.
- .copy_heap_tuple: 힙 튜플을 복사하는 함수.
2-3. scan_begin()
이 함수는 실제 순차 스캔을 시작하기 전에 호출되며, HeapScanDesc 구조체를 초기화합니다.
입력 파라미터
- Relation rel: 스캔할 관계.
- Snapshot snapshot: 현재 스냅샷 정보를 포함.
출력
스캔 상태에 대한 설명을 포함하는 HeapScanDesc 포인터를 반환합니다.
구성 요소
현재 블록 번호, 총 블록 수, 스캔 모드 등.
2-4. scan_getnextslot()
이 함수는 순차 스캔의 핵심으로, 저장 엔진에서 튜플을 검색하는 역할을 합니다.

입력 파라미터
- HeapScanDesc scanDesc: 현재 스캔 상태 정보.
- TupleTableSlot *slot: 검색된 튜플을 저장할 슬롯.
출력
- 데이터가 남아 있을 경우 true, 스캔이 종료된 경우 false를 반환합니다.
세부 사항
- 함수는 버퍼 관리자 모듈에 튜플을 요청하여 메모리 버퍼에서 튜플을 읽거나 물리적 저장소에서 읽을 수 있습니다. 이는 사용자가 자신의 데이터베이스 저장 엔진을 만들 수 있는 이유이기도 합니다. API를 통해 메모리에서 직접 튜플을 읽고 쓸 수 있어 인메모리 데이터베이스를 구성할 수 있습니다.
2-5. scan_end()
이 함수는 순차 스캔을 종료할 때 호출되며, scan_begin()에서 생성된 HeapScanDesc를 정리합니다.
입력 파라미터
- HeapScanDesc scanDesc: 종료할 스캔 상태 정보.
세부 사항
- 함수는 스캔 중에 할당된 자원을 해제하고, 메모리 누수를 방지하기 위해 모든 관련 구조체를 정리합니다.
결론
PostgreSQL의 순차 스캔은 데이터베이스 쿼리 성능에 중요한 역할을 합니다. 위에서 설명한 API들은 PostgreSQL이 데이터를 효과적으로 검색할 수 있도록 돕습니다. 다음 블로그에서는 삽입, 업데이트, 삭제, 트렁케이트와 같은 다른 DML 명령을 처리하는 API를 탐구할 예정입니다.
Reference
https://www.highgo.ca/2023/11/17/explore-table-access-method-capabilities-sequential-scan-analyzed/
