개요
PostgreSQL은 강력하고 확장 가능한 오픈 소스 데이터베이스로, 그 내부 아키텍처는 효율적인 데이터 저장과 검색을 위해 매우 정교하게 설계되어 있습니다. 그중에서도 테이블 액세스 메서드는 PostgreSQL의 핵심적인 요소로, 데이터가 디스크에 어떻게 저장되고 조회되는지를 결정합니다.
이 블로그에서는 테이블 액세스 메서드의 기본 개념부터 시작하여, PostgreSQL의 기본 저장 형식인 Heap을 이해하고, 내부적으로 데이터를 처리하는 Tuple Table Slot(TTS)과 Heap Tuple의 상호작용에 대해 심도 있게 다루고자 합니다. 이를 통해 PostgreSQL 아키텍처에 대한 명확한 이해를 돕고, 데이터 저장 방식의 핵심 개념을 파악할 수 있도록 하겠습니다.
본문
1. 테이블 액세스 메서드란 무엇인가?
테이블 액세스 메서드는 PostgreSQL이 데이터를 저장하고 읽는 방식을 결정하는 인터페이스입니다. PostgreSQL 12 이전까지는 이 부분이 고정된 형태였지만, 12부터는 사용자가 필요에 따라 커스터마이징할 수 있도록 확장되었습니다. 이를 통해 사용자는 PostgreSQL 코어의 기본 기능을 바탕으로 자신만의 테이블 액세스 메서드를 정의하고, 이를 통해 데이터를 고유한 방식으로 저장할 수 있게 되었습니다.
테이블 액세스 메서드를 통해 수행되는 작업에는 여러 가지가 있습니다. 예를 들어, 다음과 같은 작업이 테이블 액세스 메서드를 통해 이루어집니다
-
순차 스캔(Sequential Scan): 테이블의 모든 데이터를 순차적으로 읽어오는 작업입니다.
-
병렬 스캔(Parallel Scan): 여러 스레드를 활용하여 데이터를 병렬로 스캔하는 작업입니다.
-
인덱스 기반 데이터 가져오기(Index Fetch): 인덱스를 활용하여 데이터를 빠르게 조회하는 작업입니다.
-
쿼리 추정(Query Estimate): 쿼리의 실행 계획을 세울 때 필요한 데이터를 추정하는 작업입니다.
-
삽입, 업데이트, 삭제, 트렁케이트(Insert, Update, Delete, Truncate): 테이블에 데이터를 삽입하거나 수정, 삭제하는 작업들입니다.
-
테이블 생성 및 관리(Table Creation, Vacuum, Vacuum Full): 테이블을 생성하고 관리하며, VACUUM 작업을 통해 불필요한 공간을 정리하는 과정이 포함됩니다.
기본 테이블 액세스 메서드인 Heap
PostgreSQL에서 기본으로 제공되는 테이블 액세스 메서드는 Heap입니다. Heap은 PostgreSQL에서 사용하는 디스크 기반의 저장 엔진으로, 모든 데이터를 힙 구조로 저장하고 관리합니다. 이때, PostgreSQL의 기본 테이블 액세스 메서드는 Heap뿐이므로, 다른 테이블 액세스 메서드를 사용하려면 별도의 커스터마이징이 필요합니다.
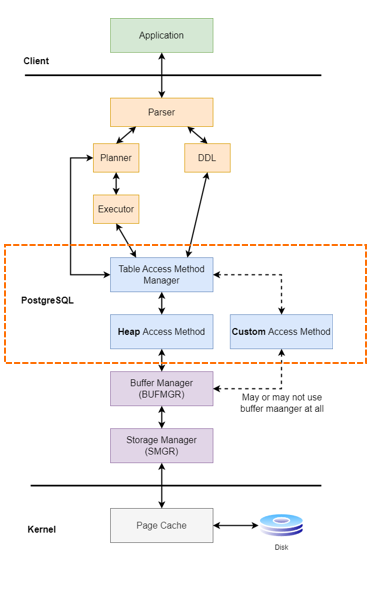
기본적으로 PostgreSQL은 Heap이라는 저장 방식을 사용하여 데이터를 관리합니다. Heap은 디스크에 데이터를 저장할 때 기본적으로 사용하는 테이블 액세스 메서드이며, PostgreSQL의 Multi-Version Concurrency Control (MVCC) 시스템과 연동되어 각 트랜잭션이 일관된 데이터 스냅샷을 사용할 수 있게 합니다.(자세한 설명은 아래에서 진행합니다.)
테이블 액세스 메서드 인터페이스 API
테이블 액세스 메서드의 API는 PostgreSQL의 소스 코드 중 src/include/access/tableam.h 파일에 정의되어 있습니다. 이 파일은 테이블 액세스 메서드를 정의하기 위한 다양한 콜백 함수들을 포함하고 있으며, 기본 Heap 액세스 메서드의 구현은 src/backend/access/heap/heapam_handler.c 파일에 위치해 있습니다.
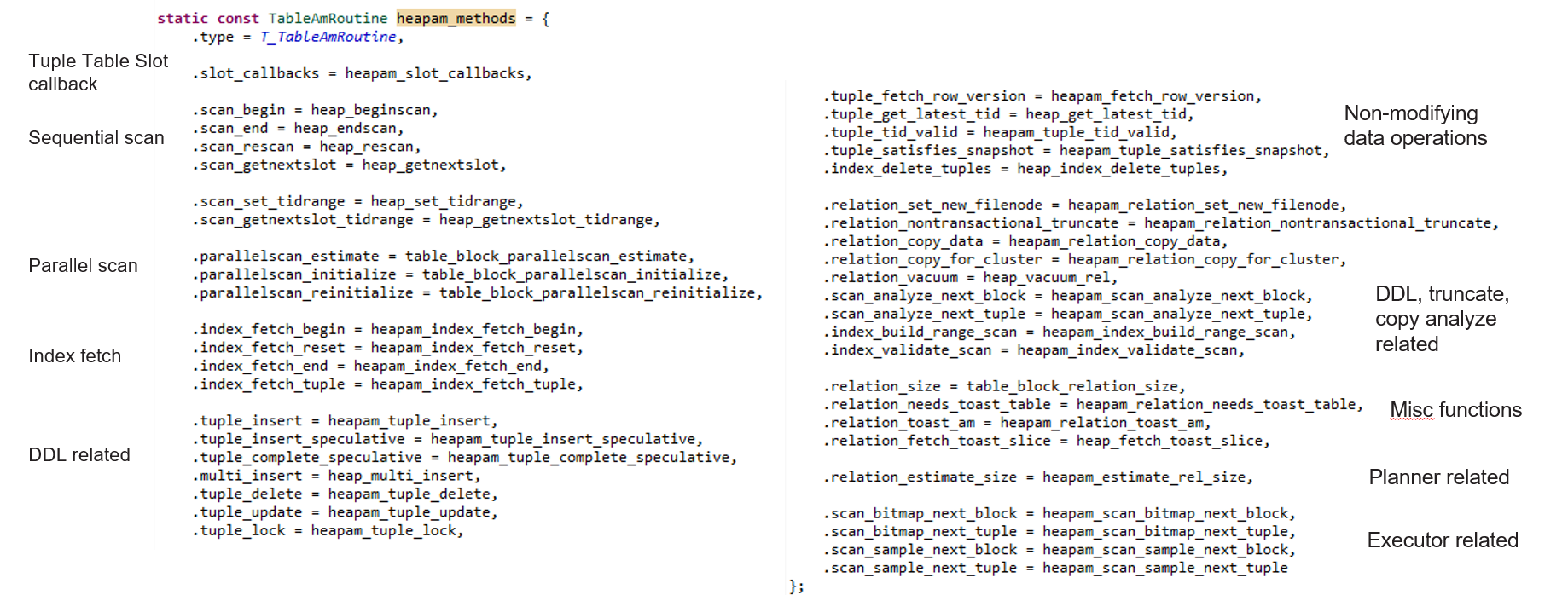
Defined in src/include/access/tableam.h, and heap access method’s implementation is located in src/backend/access/heap/heapam_handler.c.
이러한 작업은 PostgreSQL의 다양한 기능들을 지원하기 위한 복잡한 과정이 포함되어 있으며, 이를 제대로 구현하기 위해서는 PostgreSQL 내부 구조에 대한 깊은 이해가 필요합니다.
테이블 액세스 메서드에는 데이터를 삽입하거나 조회할 때, PostgreSQL 코어가 데이터를 처리하는 방식을 제어하는 함수들이 포함되어 있습니다. 예를 들어, PostgreSQL 코어는 데이터를 삽입하거나 조회할 때 Tuple Table Slot(TTS)라는 데이터 구조를 사용하여 데이터를 처리합니다. 테이블 액세스 메서드를 구현할 때, 이러한 TTS 구조를 이해하고 이를 적절히 변환하여 디스크에 데이터를 저장하거나, 디스크에서 데이터를 조회하여 다시 TTS로 변환하는 작업이 필요합니다.
2. Tuple Table Slot(TTS)란 무엇인가?
Tuple Table Slot(TTS)는 PostgreSQL 내부에서 사용하는 데이터 구조로, 데이터의 한 행을 처리할 때 사용됩니다. TTS는 PostgreSQL의 Executor(실행기) 모듈에서 사용되며, 쿼리 처리 과정에서 매우 중요한 역할을 합니다. 기본적으로 TTS는 다음과 같은 상황에서 사용됩니다.
- 쿼리 결과로 반환된 행을 저장
- 테이블에 삽입되거나 업데이트될 행을 저장

TTS는 PostgreSQL 실행기 모듈과 테이블 액세스 메서드 간에 데이터를 주고받기 위한 공통된 형식을 제공합니다. 이를 통해, 테이블 액세스 메서드는 데이터를 디스크에 저장하는 형식과 상관없이 TTS를 사용하여 데이터를 주고받을 수 있습니다.
TTS의 생명 주기는 쿼리 처리 과정과 밀접하게 연관되어 있으며, 쿼리가 실행될 때 TTS는 PostgreSQL 코어에서 테이블 액세스 메서드로 전달되어 데이터를 처리하게 됩니다. 이 과정에서 테이블 액세스 메서드는 TTS를 Heap 튜플 또는 다른 유형의 튜플 데이터 형식으로 변환하고, 다시 TTS로 변환하는 작업을 수행하게 됩니다. TTS와 관련된 작업은 PostgreSQL 소스 코드의 src/include/executor/tuptable.h 파일에 정의되어 있습니다.
3. Heap Tuple이란 무엇인가?
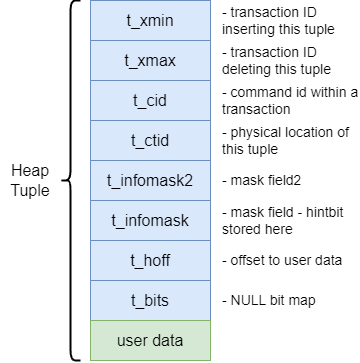
Heap Tuple은 PostgreSQL에서 데이터를 디스크에 저장하는 형식입니다. Heap 튜플은 각 행의 실제 데이터 값을 포함하며, 이 데이터를 저장할 때 추가적인 메타데이터도 함께 저장됩니다. Heap 튜플의 주요 구성 요소는 다음과 같습니다.
-
행 표현(Row Representation): Heap 튜플은 테이블의 각 행을 저장하는 물리적 표현입니다. 각 열의 데이터 값이 포함되어 있습니다.
-
가시성 정보(Visibility Information): Heap 튜플은 xmin, cid, hintbit flag 등의 메타데이터를 포함하여, PostgreSQL의 MVCC(다중 버전 동시성 제어) 시스템에서 데이터를 일관되게 관리할 수 있도록 지원합니다. 이를 통해 각 트랜잭션은 자신만의 일관된 데이터 스냅샷을 사용할 수 있습니다.
-
업데이트 지원(Support for Updates): PostgreSQL에서 행이 업데이트되면, 기존 행은 '죽은' 것으로 표시되고(xmax 값을 할당), 새로운 버전의 튜플이 생성됩니다. 이를 통해 PostgreSQL은 데이터의 일관성을 유지하면서도 다양한 버전의 데이터를 관리할 수 있습니다.
-
인덱싱을 통한 효율성(Indexed for Efficiency): Heap 튜플은 ctid라는 값을 포함하고 있으며, 이 값은 해당 튜플의 물리적 위치(페이지 번호와 오프셋)를 나타냅니다. 인덱스는 이러한 tid 값을 사용하여, 테이블을 전체 스캔하지 않고도 빠르게 해당 튜플을 조회할 수 있도록 돕습니다
4. Tuple Table Slot과 Heap Tuple의 차이점
Tuple Table Slot (TTS): TTS는 PostgreSQL의 실행기 모듈에서 사용하는 데이터 형식으로, 쿼리 결과를 처리하고 데이터베이스에 데이터를 삽입하거나 업데이트할 때 사용됩니다. TTS는 PostgreSQL 코어와 테이블 액세스 메서드 간에 데이터를 주고받기 위한 공통 형식입니다.
Heap Tuple: Heap 튜플은 PostgreSQL의 기본 테이블 액세스 메서드인 Heap에서 사용하는 데이터 형식으로, 데이터를 실제로 디스크에 저장할 때 사용됩니다. Heap 튜플은 각 행의 데이터 값뿐만 아니라 가시성 정보와 물리적 위치 정보도 함께 저장합니다.
테이블 액세스 메서드는 이러한 TTS와 Heap 튜플 간의 변환을 담당하며, PostgreSQL 코어와 데이터 저장소 간의 상호작용을 조정하는 역할을 합니다. 이 메서드는 PostgreSQL 시스템의 중요한 부분으로, 데이터를 효율적으로 저장하고 조회하는 데 필수적입니다.
결론
PostgreSQL의 테이블 액세스 메서드는 데이터베이스 시스템의 효율적인 데이터 저장과 처리를 위한 매우 중요한 개념입니다. 특히, Tuple Table Slot과 Heap Tuple 간의 상호작용을 이해하면, PostgreSQL이 데이터를 어떻게 처리하고 저장하는지에 대한 깊은 통찰을 얻을 수 있습니다. PostgreSQL 12 이후 도입된 사용자 정의 테이블 액세스 메서드를 통해 데이터 저장 방식을 보다 유연하게 관리할 수 있게 되었지만, 기본적인 Heap의 구조와 기능은 여전히 PostgreSQL에서 핵심적인 역할을 합니다.
이 블로그를 통해 PostgreSQL의 내부 구조를 깊이 있게 이해하고, 테이블 액세스 메서드가 데이터베이스 시스템의 성능과 확장성에 어떤 영향을 미치는지 알아보는 좋은 기회가 되었기를 바랍니다. PostgreSQL의 복잡한 내부 구조를 파악함으로써, 데이터베이스 성능 최적화와 커스터마이징에 더욱 유리한 포지션을 차지할 수 있을 것입니다.
Reference
https://www.highgo.ca/2023/10/20/quick-overview-of-postgresqls-table-access-method/
