PostgreSQL 16 및 pg_cron 설치 및 설정 가이드
이 블로그 포스트에서는 PostgreSQL 16을 설치하고 pg_cron 확장을 설정하는 방법에 대해 다룰 것입니다. 또한, 사용자를 생성하고 작업을 예약하는 방법도 설명합니다. 참고 자료: pg_cron_github
Chapter 1: AWS EC2 프리티어 설정
Red Hat 9 서버 할당
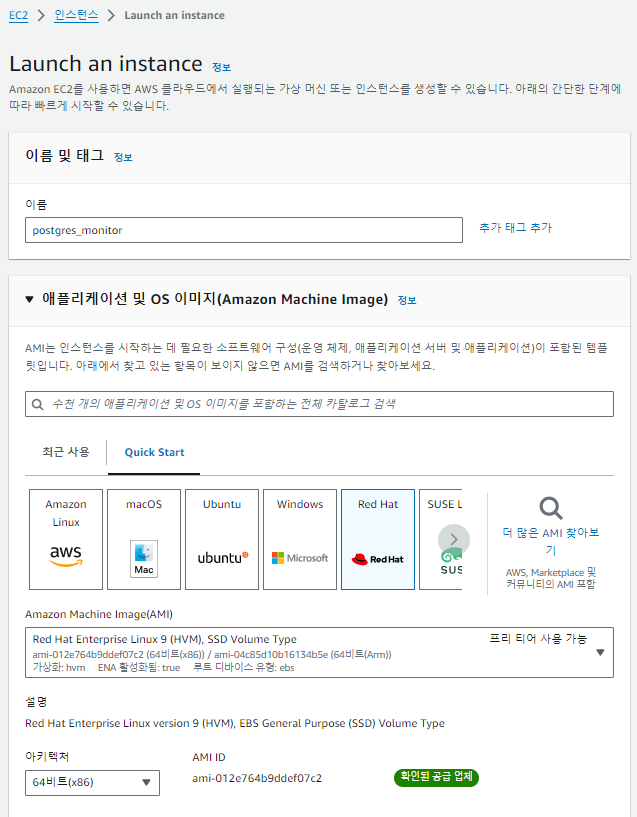
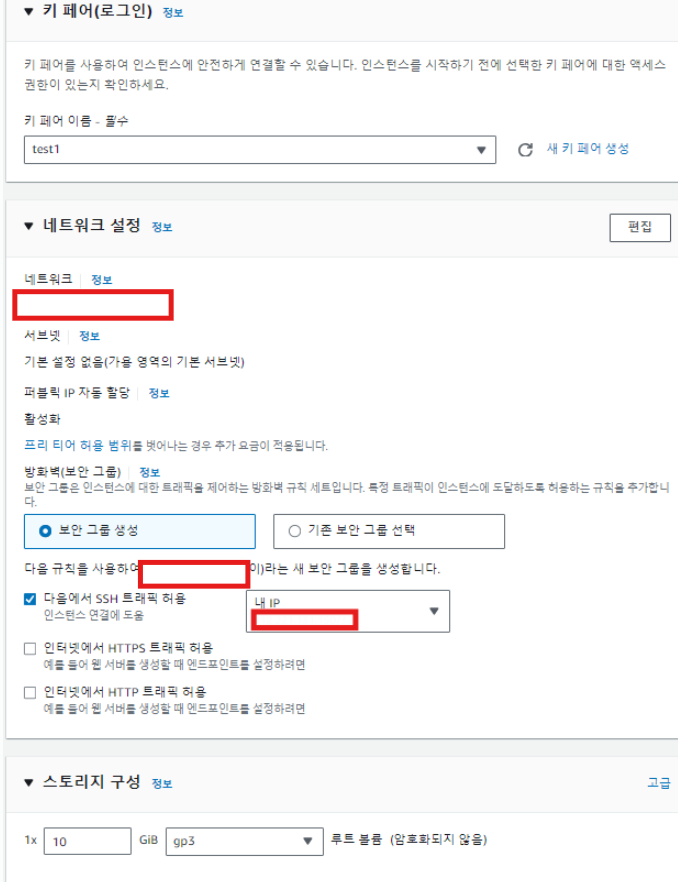
키 페어, 보안 그룹 설정
1. 키 페어 (Key Pair)
-
접근 제어: EC2 인스턴스에 SSH를 통해 안전하게 접속하기 위해 키 페어를 사용합니다. 키 페어는 공인 키와 개인 키로 구성되며, 개인 키는 안전하게 보호되어야 합니다.
-
보안 강화: 비밀번호 대신 키 페어를 사용함으로써 brute-force 공격에 대한 저항력을 높일 수 있습니다. 개인 키는 외부에 노출되지 않으므로 보안성이 향상됩니다.
2. 보안 그룹 (Security Group)
- 네트워크 접근 제어: 보안 그룹은 EC2 인스턴스에 대한 트래픽을 필터링하는 가상 방화벽 역할을 합니다. 인바운드 및 아웃바운드 규칙을 설정하여 어떤 IP 주소와 포트에서 트래픽을 허용할지를 정의합니다.
- 상태 기반 필터링: 보안 그룹은 상태 기반으로 작동하므로, 요청이 수신되면 응답에 대해 자동으로 허용됩니다. 이를 통해 보다 유연한 네트워크 관리가 가능합니다.
- 보안 정책 구현: 특정 서비스(예: 웹 서버, 데이터베이스 서버)와 관련된 포트만 열어두어 최소한의 접근만 허용함으로써 보안을 강화할 수 있습니다.
Chapter 2: EC2 접속 후 PG16 설치
EC2 접속
vi /etc/ssh_config 접속 후
#User ""
ForwardAgent no
Compression yes
PreferredAuthentications hostbased,publickey,password,keyboard-interactive
ForwardX11 yes
ForwardX11Trusted yes
NoHostAuthenticationForLocalhost yes
StrictHostKeyChecking no
CheckHostIP no
UseRoaming no
wq!
ssh -i <pem.key path> ec2-user@<퍼블릭 DNS>Postgresql 설치
Postgresql 다운로드 링크 :클릭
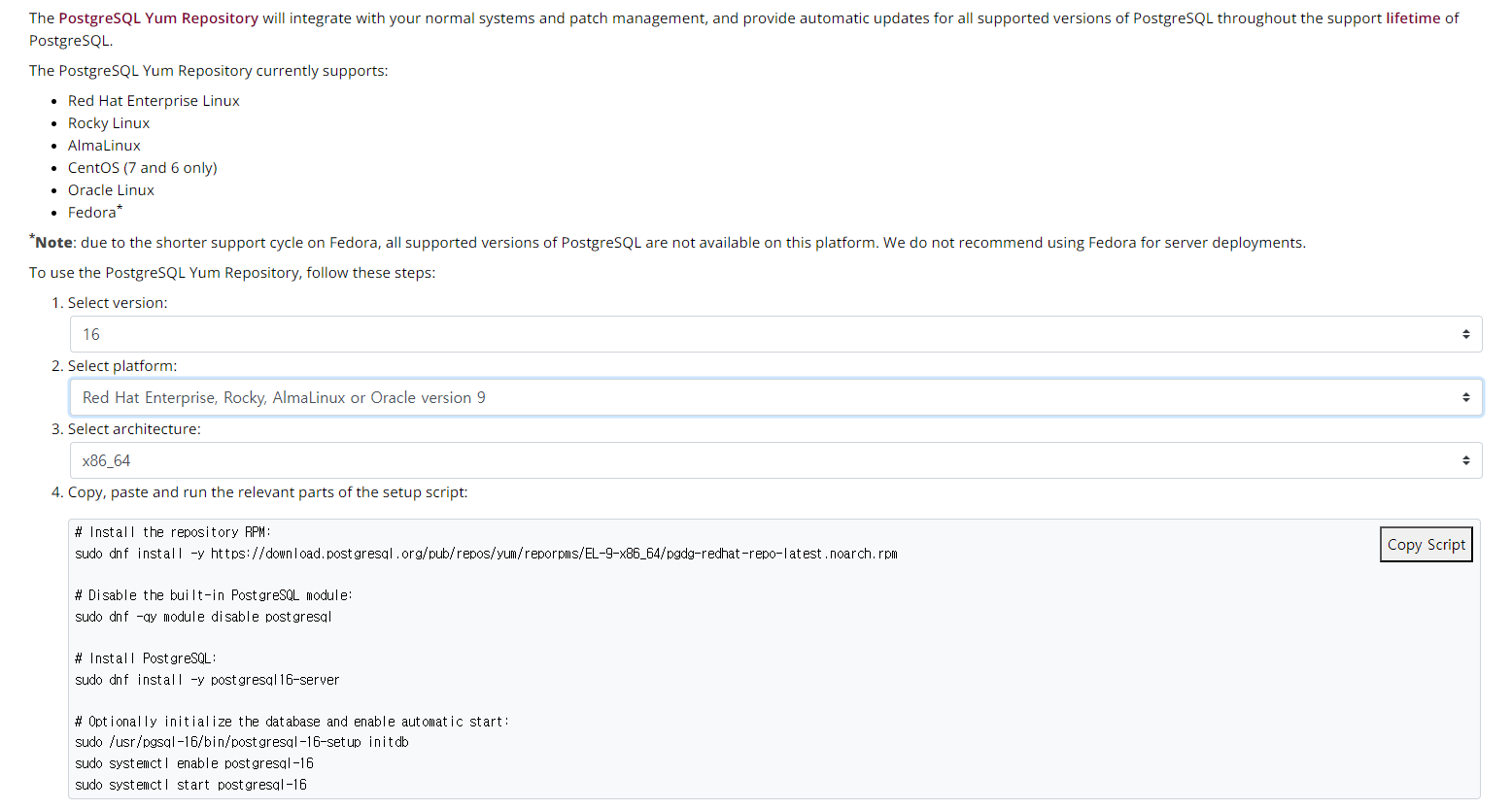
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm
sudo dnf -qy module disable postgresql
sudo dnf install -y postgresql16-server
sudo /usr/pgsql-16/bin/postgresql-16-setup initdb
sudo systemctl enable postgresql-16
sudo systemctl start postgresql-16
sudo -i -u postgres
psqlChapter 3: 개발 도구 설치
1. 필수 패키지 설치
sudo yum install git -y
sudo yum install make gcc -y
sudo yum install postgresql16-devel -y2. 개발 도구 그룹 설치
sudo yum groupinstall "Development Tools" -y3. Clang 설치
Clang을 컴파일러로 사용하려면 다음 명령어로 설치
sudo yum install clang -yChapter 4: pg_cron 설치
1. pg_cron 확장 설치
# pg_cron 설치
sudo yum install -y pg_cron_16
# 소스에서 pg_cron 빌드하기
git clone https://github.com/citusdata/pg_cron.git
cd pg_cron
export PATH=/usr/pgsql-16/bin:$PATH
make && sudo PATH=$PATH make install2. pg_cron 설정
PostgreSQL이 시작할 때 pg_cron 백그라운드 워커를 시작하도록 설정
기본적으로 pg_cron 백그라운드 워커는 "postgres" 데이터베이스에서 메타데이터 테이블을 생성합니다. 이를 변경하려면 postgresql.conf에 다음을 추가합니다.
# Add to postgresql.conf
# required to load pg_cron background worker on start-up
shared_preload_libraries = 'pg_cron'
# optionally, specify the database in which the pg_cron background worker should run (defaults to postgres)
cron.database_name = 'postgres'
# optionally, specify the timezone in which the pg_cron background worker should run (defaults to GMT). E.g:
cron.timezone = 'PRC'
# Schedule jobs via background workers instead of localhost connections
cron.use_background_workers = on
# Increase the number of available background workers from the default of 8
max_worker_processes = 20| 설정 항목 | 설명 |
|---|---|
shared_preload_libraries | PostgreSQL 시작 시 pg_cron 배경 작업자를 로드합니다. |
cron.database_name | pg_cron 작업이 실행될 데이터베이스를 지정합니다 (기본값: postgres). |
cron.timezone | pg_cron 작업이 실행될 시간대를 설정합니다 (기본값: GMT). |
cron.use_background_workers | 작업을 배경 작업자로 실행할지 설정합니다 (on으로 설정). |
max_worker_processes | 최대 작업자 프로세스 수를 지정합니다 (기본값: 8, 이 예제에서는 20). |
3. PostgreSQL을 재시작한 후 pg_cron 함수 및 메타데이터 테이블을 생성
-- 슈퍼유저에서 생성:
CREATE EXTENSION pg_cron;
-- create Role
CREATE ROLE marco WITH LOGIN PASSWORD 'your_password';
-- 사용자 권한 부여
GRANT USAGE ON SCHEMA cron TO marco;
GRANT SELECT ON ALL TABLES IN SCHEMA cron TO marco;
ALTER DEFAULT PRIVILEGES IN SCHEMA cron GRANT SELECT ON TABLES TO marco;
Chapter 5: 인증 방식 변경
- pg_hba.conf 수정
local all all md5- pg_cron 작업 실행 보장
기본적으로 pg_cron은 libpq를 사용하여 로컬 데이터베이스에 새로운 연결을 열며, 이를 허용하기 위해 pg_hba.conf에 trust 인증을 설정합니다.
# Connect via a unix domain socket:
cron.host = '/tmp'
# Can also be an empty string to look for the default directory:
cron.host = ''
Chapter 6: 스케줄링 시작
1. 스케줄링 개요도
┌───────────── min (0 - 59)
│ ┌────────────── hour (0 - 23)
│ │ ┌─────────────── day of month (1 - 31) or last day of the month ($)
│ │ │ ┌──────────────── month (1 - 12)
│ │ │ │ ┌───────────────── day of week (0 - 6) (0 to 6 are Sunday to
│ │ │ │ │ Saturday, or use names; 7 is also Sunday)
│ │ │ │ │
│ │ │ │ │
2. 스케줄링 Query
-- Delete old data on Saturday at 3:30am (GMT)
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
schedule
----------
42
-- Vacuum every day at 10:00am (GMT)
SELECT cron.schedule('nightly-vacuum', '0 10 * * *', 'VACUUM');
schedule
----------
43
-- Change to vacuum at 3:00am (GMT)
SELECT cron.schedule('nightly-vacuum', '0 3 * * *', 'VACUUM');
schedule
----------
43
-- Stop scheduling jobs
SELECT cron.unschedule('nightly-vacuum' );
unschedule
------------
t
SELECT cron.unschedule(42);
unschedule
------------
t
-- Vacuum every Sunday at 4:00am (GMT) in a database other than the one pg_cron is installed in
SELECT cron.schedule_in_database('weekly-vacuum', '0 4 * * 0', 'VACUUM', 'some_other_database');
schedule
----------
44
-- Call a stored procedure every 5 seconds
SELECT cron.schedule('process-updates', '5 seconds', 'CALL process_updates()');
-- Process payroll at 12:00 of the last day of each month
SELECT cron.schedule('process-payroll', '0 12 $ * *', 'CALL process_payroll()');3. 스케줄링 쿼리 확인
-- View active jobs
select * from cron.job;4. Detail 하게 확인
select * from cron.job_run_details order by start_time desc limit 5;
┌───────┬───────┬─────────┬──────────┬──────────┬───────────────────┬───────────┬──────────────────┬───────────────────────────────┬───────────────────────────────┐
│ jobid │ runid │ job_pid │ database │ username │ command │ status │ return_message │ start_time │ end_time │
├───────┼───────┼─────────┼──────────┼──────────┼───────────────────┼───────────┼──────────────────┼───────────────────────────────┼───────────────────────────────┤
│ 10 │ 4328 │ 2610 │ postgres │ marco │ select process() │ succeeded │ SELECT 1 │ 2023-02-07 09:30:00.098164+01 │ 2023-02-07 09:30:00.130729+01 │
│ 10 │ 4327 │ 2609 │ postgres │ marco │ select process() │ succeeded │ SELECT 1 │ 2023-02-07 09:29:00.015168+01 │ 2023-02-07 09:29:00.832308+01 │
│ 10 │ 4321 │ 2603 │ postgres │ marco │ select process() │ succeeded │ SELECT 1 │ 2023-02-07 09:28:00.011965+01 │ 2023-02-07 09:28:01.420901+01 │
│ 10 │ 4320 │ 2602 │ postgres │ marco │ select process() │ failed │ server restarted │ 2023-02-07 09:27:00.011833+01 │ 2023-02-07 09:27:00.72121+01 │
│ 9 │ 4320 │ 2602 │ postgres │ marco │ select do_stuff() │ failed │ job canceled │ 2023-02-07 09:26:00.011833+01 │ 2023-02-07 09:26:00.22121+01 │
└───────┴───────┴─────────┴──────────┴──────────┴───────────────────┴───────────┴──────────────────┴───────────────────────────────┴───────────────────────────────┘
(10 rows)5. 테이블 기록 정리
이 내용은 pg_cron 확장을 사용하여 PostgreSQL 데이터베이스에서 주기적으로 cron.job_run_details 테이블의 오래된 기록을 정리하는 방법에 대한 설명입니다.
1. 정기적으로 기록 정리하기
목적: 주기적으로 실행되는 작업이 많을 경우, cron.job_run_details 테이블의 데이터가 빠르게 쌓일 수 있습니다. 이 데이터를 정리하지 않으면 성능에 영향을 줄 수 있습니다.
SELECT cron.schedule('delete-job-run-details', '0 12 * * *', $$DELETE FROM cron.job_run_details WHERE end_time < now() - interval '7 days'$$);설명: 이 SQL 명령어는 매일 정오(오후 12시)에 cron.job_run_details 테이블에서 end_time이 7일 이전인 기록을 삭제하는 작업을 스케줄합니다
- cron.job_run_details 사용하지 않기
설정: 만약 cron.job_run_details 테이블을 전혀 사용하고 싶지 않다면, 다음 설정을 추가할 수 있습니
#postgresql.conf
cron.log_run = off설명: 이 설정을 postgresql.conf에 추가하면 pg_cron은 작업 실행 로그를 기록하지 않게 됩니다. 이를 통해 불필요한 기록 생성을 방지할 수 있습니다.
Chapter 6: Example Use Cases for pg_cron
| 사용 사례 | 설명 |
|---|---|
| Auto-partitioning using pg_partman | 데이터를 자동으로 파티셔닝하여 성능과 관리 용이성 향상. |
| Computing rollups in an analytical dashboard | 데이터 분석 대시보드에서 정기적으로 롤업(집계) 수행. |
| Deleting old data, vacuum | 오래된 데이터 삭제 및 데이터베이스 성능 유지를 위한 VACUUM 작업 실행. |
| Feeding cats | 특정 함수를 호출하여 고양이에게 정기적으로 먹이를 주는 작업 설정. |
| Routinely invoking a function | 특정 함수를 정기적으로 호출하여 필요한 작업 자동 수행. |
| Postgres as a cron server | PostgreSQL을 cron 서버로 사용하여 다양한 정기 작업 관리. |
회고
pg_cron은 PostgreSQL의 강력한 기능 중 하나로, 데이터베이스 작업을 자동화할 수 있는 뛰어난 방법을 제공합니다. 정기적인 작업을 쉽게 설정하고 관리할 수 있으며, 데이터베이스의 성능을 유지하고 효율적으로 관리하는 데 도움을 줍니다. 다양한 사용 사례를 통해 pg_cron의 유용성을 알 수 있으며, 특히 데이터베이스 관리자가 정기적으로 수행해야 할 작업을 자동화할 수 있는 점이 매우 매력적입니다.
이 포스팅을 통해 pg_cron의 다양한 가능성을 살펴보았고, 이를 통해 데이터베이스 작업의 효율성을 극대화할 수 있는 방법을 배울 수 있었습니다. 앞으로도 이와 같은 도구를 활용하여 데이터베이스 운영을 더욱 효율적으로 관리할 수 있을 것이라 기대합니다.
