대량의 데이터를 다루는 현대의 데이터베이스 환경에서 쿼리 최적화는 성능 개선의 핵심 요소입니다. 이번 포스팅에서는 PostgreSQL의 EXPLAIN 명령어와 PEV(Execution Visualizer)를 활용하여 복잡한 JOIN 쿼리의 성능을 분석하고 최적화하는 방법을 깊이 있게 탐구해보겠습니다.
테이블 생성 및 데이터 삽입
우선, 대량 데이터 환경을 위해 두 개의 테이블을 생성하고, 각각 715 MB 및 287 MB의 데이터를 추가하겠습니다.
1. 테이블 생성
-- customer_data 테이블 생성
CREATE TABLE customer_data (
customer_id SERIAL PRIMARY KEY,
name VARCHAR(100),
age INTEGER,
account_balance NUMERIC(15, 2),
transaction_date DATE
);
-- transaction_log 테이블 생성
CREATE TABLE transaction_log (
transaction_id SERIAL PRIMARY KEY,
customer_id INTEGER REFERENCES customer_data(customer_id),
transaction_amount NUMERIC(10, 2),
transaction_date DATE,
transaction_type VARCHAR(50)
);2. 대량의 더미 데이터 생성
각 테이블에 데이터를 삽입하여 10GB 및 5GB의 크기를 달성할 수 있습니다. 예를 들어, generate_series 함수를 활용하여 1천만 건 이상의 데이터를 삽입할 수 있습니다.
-- customer_data 테이블에 대량 데이터 삽입
INSERT INTO customer_data (name, age, account_balance, transaction_date)
SELECT
'Customer ' || i,
(RANDOM() * 60 + 20)::INTEGER,
(RANDOM() * 100000)::NUMERIC(15, 2),
CURRENT_DATE - (RANDOM() * 365)::INTEGER
FROM generate_series(1, 10000000) AS i;
-- transaction_log 테이블에 대량 데이터 삽입
INSERT INTO transaction_log (customer_id, transaction_amount, transaction_date, transaction_type)
SELECT
(RANDOM() * 10000000)::INTEGER,
(RANDOM() * 1000)::NUMERIC(10, 2),
CURRENT_DATE - (RANDOM() * 365)::INTEGER,
CASE WHEN RANDOM() > 0.5 THEN 'credit' ELSE 'debit' END
FROM generate_series(1, 5000000) AS i;3. 복잡한 JOIN 쿼리 작성
대량 데이터를 효율적으로 분석하기 위해 고객의 평균 잔액이 특정 기준 이상이면서 거래 내역이 많은 고객을 조회하는 복잡한 쿼리를 작성해보겠습니다.
-- 고객의 평균 잔액이 특정 금액 이상이면서 거래 내역이 많은 고객 리스트 조회
EXPLAIN (ANALYZE, BUFFERS)
SELECT
c.customer_id,
c.name,
AVG(c.account_balance) AS avg_balance,
COUNT(t.transaction_id) AS transaction_count,
MAX(t.transaction_date) AS last_transaction_date
FROM
customer_data c
JOIN
transaction_log t ON c.customer_id = t.customer_id
WHERE
c.account_balance > 50000 -- 잔액 기준 설정
AND t.transaction_date >= CURRENT_DATE - INTERVAL '1 year' -- 최근 1년 내 거래만 포함
GROUP BY
c.customer_id, c.name
HAVING
COUNT(t.transaction_id) > 100 -- 거래 횟수가 일정 수 이상인 고객 필터링
ORDER BY
avg_balance DESC, transaction_count DESC
LIMIT 50; -- 상위 50명 고객 조회이 쿼리는 대량 데이터에서 고객의 평균 잔액과 최근 거래 횟수를 계산하여, 이를 기준으로 상위 고객을 추출하는 구조입니다.
쿼리 실행 계획 분석
쿼리의 성능을 개선하기 위해 EXPLAIN 명령어를 사용하여 쿼리 실행 계획을 분석합니다. 이를 통해 쿼리가 어떻게 실행되는지, 각 단계에서 소요되는 시간과 버퍼 사용량을 확인할 수 있습니다.
PEV를 활용한 실행 계획 시각화
PEV(Execution Visualizer)는 실행 계획을 시각적으로 표현하여, 복잡한 쿼리를 쉽게 이해하고 최적화 포인트를 찾아내는 데 도움을 줍니다. 이를 활용하여 실행 계획을 분석하면, 어떤 인덱스가 효과적으로 사용되고 있는지, 쿼리의 병목 현상이 발생하는지 등을 쉽게 파악할 수 있습니다.
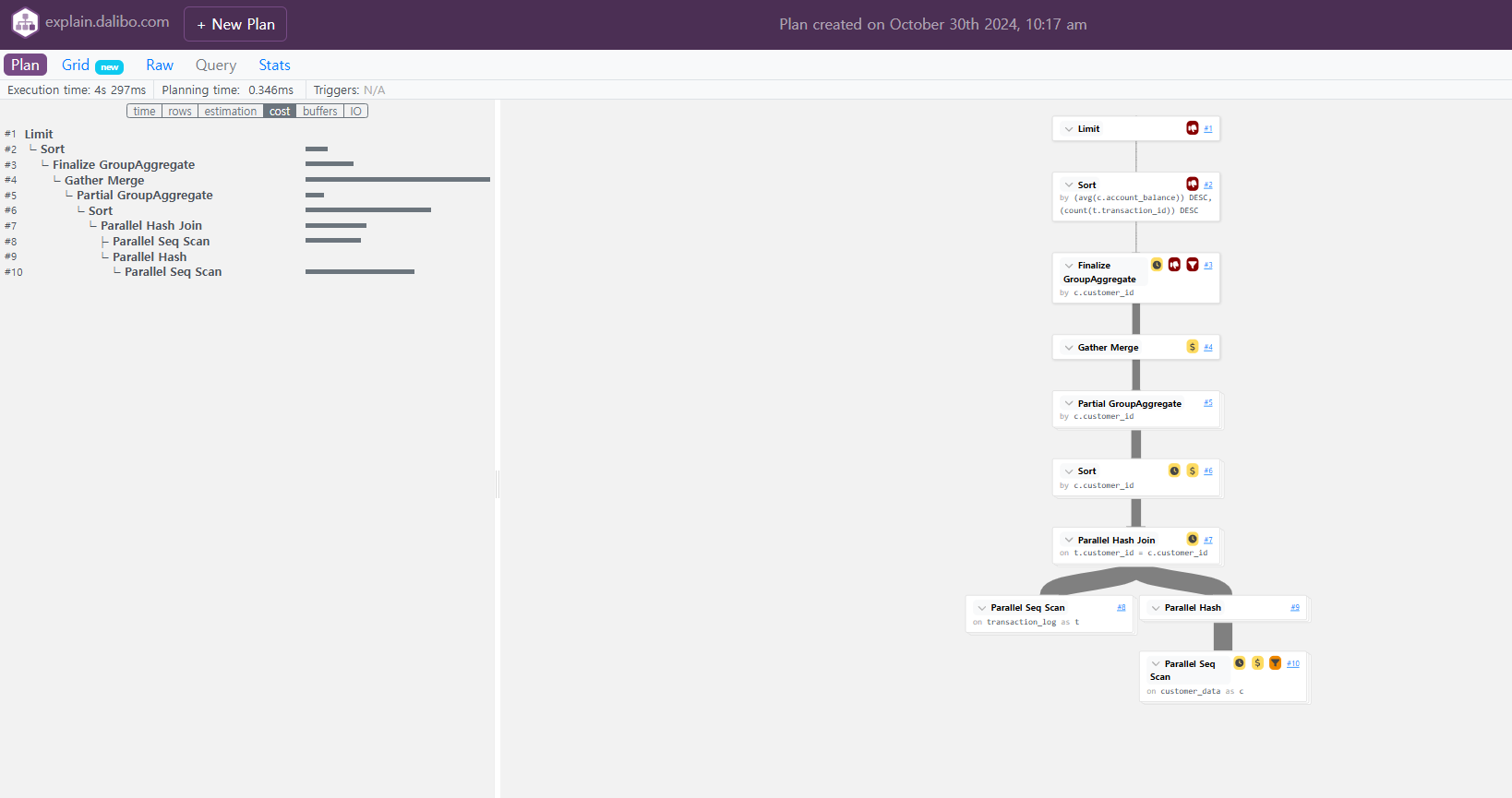
pev(postgresql_explain_visualizer) : https://github.com/dalibo/pev2
이미지 사이트 : https://explain.dalibo.com/
결론
대량 데이터 처리에서 PostgreSQL의 쿼리 최적화는 성능 개선에 중요한 역할을 합니다. EXPLAIN 명령어와 PEV를 활용하여 복잡한 JOIN 쿼리의 실행 계획을 분석하고 최적화하는 방법을 살펴보았습니다.
