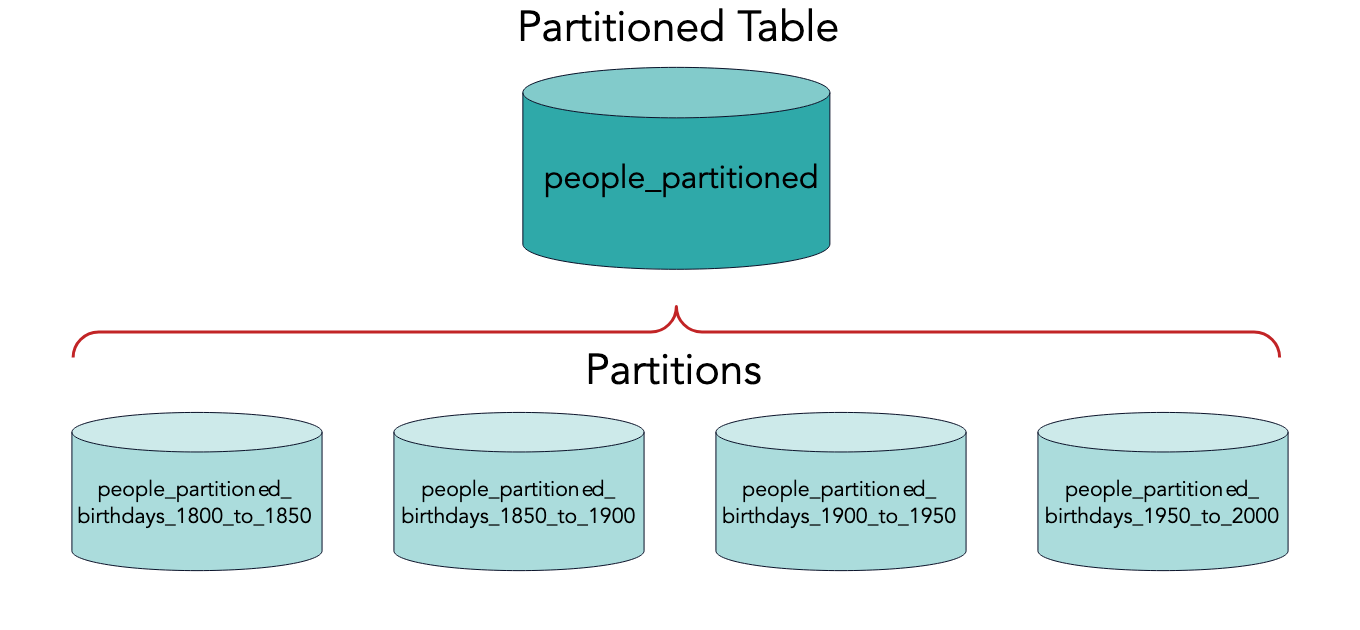
파티셔닝은 큰 데이터베이스 테이블을 더 작은 자식 테이블로 나누어 관리하는 과정입니다. 이 과정은 확장성, 쿼리 성능 개선 등 여러 이유로 수행됩니다.
올바른 파티셔닝 전략을 선택하는 것은 더 나은 성과를 달성하기 위한 중요한 결정입니다. 잘못된 파티셔닝 전략은 오히려 성능을 저하시킬 수 있습니다. 예를 들어, 파티셔닝 후에도 대부분의 데이터가 단일 파티션에 저장되고, 해당 파티션이 읽기 집중적인 경우라면 이러한 파티셔닝 전략은 효과적이지 않습니다.
파티셔닝된 테이블 자체는 가상 테이블로, 자체 저장소가 없으며, 저장소는 파티션에 속해 있습니다. 각 파티션은 일반적인 테이블처럼 동작하며, 파티셔닝된 테이블과 연결됩니다.
PostgreSQL에서 제공하는 파티셔닝 방식은 세 가지입니다
- 리스트 파티셔닝
- 범위 파티셔닝
- 해시 파티셔닝
리스트 파티셔닝 (List Partitioning)
리스트 파티셔닝은 특정 열의 값이 불연속적인 범주형 값일 때 사용합니다. 이를 통해, 특정 값이 속하는 데이터를 별도의 파티션에 저장하여 특정 범주에 속하는 데이터를 효율적으로 조회할 수 있습니다.
특징
- 범주형 데이터에 적합: 특정 값들(예: 국가 코드, 지역 등)에 따라 데이터를 분리할 때 유용합니다.
- 파티션별로 분리된 관리 가능: 예를 들어, 국가별로 데이터를 나누어 지역별 조회 성능을 높이고 관리 편리성을 제공합니다.
- 제한된 값만 포함 가능: 리스트 파티셔닝에서는 주어진 값만 파티션에 포함되며, 그 외 값에 대한 파티션이 필요할 경우 기본 파티션(Default Partition)을 정의할 수 있습니다.
주의사항
리스트 파티셔닝을 잘못 사용하면 파티션 간 데이터 불균형이 발생할 수 있습니다. 예를 들어, 특정 국가에만 사용자가 집중되어 있다면 해당 파티션만 지나치게 커질 수 있습니다.
장점
- 지정된 특정 값에 대한 조회 성능이 뛰어납니다.
- 범주형 데이터를 다룰 때 직관적이고 관리가 용이합니다.
예를 들어, country 열을 기준으로 지역별 데이터를 나눌 수 있습니다.
CREATE TABLE employee (
first_name VARCHAR(30) NOT NULL,
last_name VARCHAR(30) NOT NULL,
country char(2) NOT NULL,
PRIMARY KEY (first_name, country)
) PARTITION BY LIST(country);위의 예시에서 country 값에 따라 직원 테이블을 여러 파티션으로 나누었습니다. 이제 각 나라별로 테이블을 생성할 수 있습니다.
CREATE TABLE emp_in PARTITION OF employee FOR VALUES IN ('IN');
CREATE TABLE emp_us PARTITION OF employee FOR VALUES IN ('US');
INSERT INTO employee VALUES ('foo', 'a', 'US');
INSERT INTO employee VALUES ('bar', 'b', 'IN');이러한 방식으로 특정 지역의 데이터를 검색할 때는 해당 파티션만 조회하면 됩니다.
범위 파티셔닝 (Range Partitioning)
범위 파티셔닝은 연속적인 값, 주로 날짜나 숫자 범위를 기준으로 데이터를 분할합니다. 특정 범위에 해당하는 데이터를 각각의 파티션에 저장함으로써, 조회 시 해당 범위 내의 파티션만을 스캔하게 되어 성능을 크게 향상시킬 수 있습니다.
특징
- 시간 또는 연속 값에 적합: 날짜, 나이, 금액 등 연속된 값의 범위를 기준으로 데이터를 나누기에 유용합니다.
- 자동 확장 가능: 새로운 데이터 범위가 추가될 때마다 새 파티션을 쉽게 만들고 붙일 수 있습니다. 예를 들어, 매년 새로운 데이터를 저장하기 위해 연 단위 파티션을 만들 수 있습니다.
주의사항
범위 파티셔닝은 파티션을 너무 세분화하거나 잘못된 범위를 설정하면 데이터 불균형을 초래할 수 있습니다. 예를 들어, 특정 연도에만 데이터가 집중되는 경우 해당 연도의 파티션만 과도하게 커질 수 있습니다.
장점
- 주기적인 데이터 처리나 로그 데이터 관리에 매우 효과적입니다.
- 쿼리 시 불필요한 파티션을 스캔하지 않아도 되므로, 대량 데이터 처리 시 성능을 크게 향상시킬 수 있습니다.
예를 들어, 직원 테이블을 직원의 입사 연도에 따라 파티셔닝할 수 있습니다.
CREATE TABLE employee (
first_name VARCHAR(30) NOT NULL,
last_name VARCHAR(30) NOT NULL,
country char(2) NOT NULL,
start_time timestamp without time zone NOT NULL
) PARTITION BY RANGE (start_time);이제 특정 연도에 입사한 직원들을 저장할 파티션 테이블을 생성하고 이를 메인 테이블에 연결할 수 있습니다.
CREATE TABLE employee_2024 (LIKE employee INCLUDING ALL);
ALTER TABLE employee ATTACH PARTITION employee_2024
FOR VALUES FROM ('2024-01-01') TO ('2024-12-31');위와 같이 연도별로 파티션을 나누면 데이터가 유기적으로 증가하는 경우 성능을 최적화할 수 있습니다.
해시 파티셔닝 (Hash Partitioning)
해시 파티셔닝은 데이터를 균등하게 분배하기 위해 해시 함수와 모듈러 연산을 사용하여 파티션을 결정합니다. 데이터의 균등 분포가 중요한 경우, 또는 명확한 파티셔닝 기준이 없을 때 해시 파티셔닝이 유용합니다.
특징
- 데이터 균등 분배: 특정 값에 따라 데이터가 치우치지 않고, 모든 파티션에 고르게 분산되도록 보장합니다.
- 동일한 기준에 따라 분할: 해시 함수를 사용하여 일관된 방식으로 데이터를 분할합니다. 예를 들어, 직원 ID를 기준으로 파티션을 분할할 경우, 해당 해시 값에 따라 직원 데이터가 자동으로 균등하게 분배됩니다.
주의사항
해시 파티셔닝은 파티션의 개수가 고정되며, 파티션을 추가하거나 제거하려면 전체 데이터를 다시 해싱해야 하는 번거로움이 있을 수 있습니다. 또한, 자연스러운 데이터 그룹화가 아니라 단순히 해시 값에 따라 분할되므로 특정 범위의 데이터를 조회할 때 성능상 이점이 적을 수 있습니다.
장점
- 명확한 기준이 없거나 균등하게 데이터를 분배해야 할 때 매우 유용합니다.
- 불균형한 데이터 분포를 방지할 수 있습니다.
CREATE TABLE employee (
emp_id bigint,
first_name VARCHAR(30) NOT NULL,
last_name VARCHAR(30) NOT NULL,
country char(2) NOT NULL,
start_time timestamp without time zone NOT NULL
) PARTITION BY HASH (emp_id);이제 해시 값에 따라 파티션을 나누겠습니다.
CREATE TABLE employee_h0 PARTITION OF employee FOR VALUES WITH (modulus 5, remainder 0);
CREATE TABLE employee_h1 PARTITION OF employee FOR VALUES WITH (modulus 5, remainder 1);
CREATE TABLE employee_h2 PARTITION OF employee FOR VALUES WITH (modulus 5, remainder 2);
CREATE TABLE employee_h3 PARTITION OF employee FOR VALUES WITH (modulus 5, remainder 3);
CREATE TABLE employee_h4 PARTITION OF employee FOR VALUES WITH (modulus 5, remainder 4);해시 파티셔닝을 통해 데이터가 고르게 분산되도록 할 수 있습니다.
파티셔닝 프루닝 (Partitioning Pruning)
PostgreSQL에서 파티셔닝된 테이블에 대한 쿼리 성능을 극대화하려면, 파티션 프루닝 기능을 활용해야 합니다. 파티션 프루닝은 쿼리 시 불필요한 파티션을 건너뛰고, 조건에 맞는 파티션만을 읽도록 쿼리 플래너에 지시하는 기능입니다. 이를 통해 쿼리 성능을 극대화할 수 있습니다
SET enable_partition_pruning = on;이 설정을 통해 쿼리 플래너가 필요한 파티션만 스캔하도록 최적화할 수 있습니다.
결론
파티셔닝이 적용된 테이블은 데이터가 여러 파티션으로 나뉘어 저장되기 때문에, 쿼리 실행 시 필요한 파티션만을 읽음으로써 성능을 향상시킬 수 있습니다. 하지만 모든 경우에 파티셔닝이 유리한 것은 아니며, 잘못된 파티셔닝 전략은 성능을 저하시킬 수 있습니다. 예를 들어, 특정 파티션에 데이터가 몰리면 오히려 데이터 접근 속도가 느려질 수 있습니다.
