Hazard의 마지막 Brach Hazard에 대해서 다루고 Pipelining에 대한것은 끝내려고 합니다.
간단하게 복습을 한번 해볼까요
앞에 있던 글들 빠르게 정리해보기
CPU는 원래 순차적으로 일을 처리했다. 즉, 하나의 Task가 끝나고 다음 Task를 실행하는 것으로 개발이 되었음. 하지만, 처리율을 높이기 위해서 하나의 task를 여러개의 stage로 나누어서 실행하는 파이프라이닝을 채택하게 되었음.
파이프라이닝은 하나의 작업을 여러 개의 스테이지로 나누어 연속적으로 실행하기 때문에, 작업간의 의존성이 있을 때 문제점이 생겼음. 우리는 그걸 Hazard 라고 하기로 했음.
Data Dependency Hazard (Data Hazard)
- RAW : 저장되기전에 데이터에 접근하여 읽어오는 것. Stall이나 Data Fowarding을 통해서 해결함. True Dependency로 어쩔 수 없이 생김.
- WAW,WAR (Only,OOO) : OOO(Out of order pipelining)이나 병렬처리에서 생기는 의존성으로 오버라이트 되거나, 미래의 값을 읽는 현상임. 썻던 공간을 재사용하기 때문에 생기는 현상임. Register Renaming으로 해결함.
out of order piplining(OOO)
- 파이프라이닝도 InOrder이었지만, 앞의 작업이 오래걸리면 뒤에 작업을 연달아서 하지 못하는 병목현상이 꾸준히 일어낫고, Performance를 계산하는 식에서
Freq는 한계가 있기 때문에 IPC(사이클 당 처리 명령어 수)를 높여야 할 필요성이 생겼음. - 그래서, SuperScalar가 등장했지만, 하나의 stage내에서도 의존성이 생기고 stall이 그만큼 더 자주생기는 등의 문제점으로 더 발전시키기가 어려웠음. -> 명령어를 순차적으로 실행시킨다는 개념을 뭉개버림. -> OOO가 등장하였고, OOO는 Instruction Window라는 버퍼를 가지고 있고 내부적으로 Register renaming , Reservation Station,ReOrder의 과정을 거치면서 처리가됨.
Branch가 왜 문제가 될까?
프로그래밍은 분기문이 굉장히 많습니다. For문도 분기문이고, 함수도 분기문이고 if도 분기문입니다. 어셈블리어로 해석했을 때 평균적으로 25% 정도가 Branch명령어라고 합니다.
하지만, Branch명령어가 Pipelining구조에서 엄청 취약합니다. OOO든 InOrder든 Fetch는 순차적으로 진행하는데, 중간에 분기문이 Taken(True)가 되면, 아예 다른 Memory에 있는 명령어를 Fetch해야합니다. 파이프라인 전체를 비워야함. 큰 작업 fetch는 순차적으로 진행되어야하기 때문에 Branch가 처리될 때까지 기다려야합니다.
한줄요약
Branch는 Fetch가 연속적으로 일어나지 못함. stall이 생기거나 파이프라이닝을 flush해줘야함.

Branch 넌 누구냐!
사실, Branch의 의미는 중요하진 않습니다. Branch는 프로그램 실행 중에 실행을 제어하기 위해 분기를 만들어내는 기계어일 뿐 입니다. 하지만, Branch의 종류는 앞으로 이야기에서 의미가 있기 때문에 ,Branch를 보고 넘어갑시다.
Branch에도 종류가 있다?!
분기문이라고 한다면, 단순히 If문,함수 정도로 생각할 수 있습니다. 사실 프로그래밍할 때, 쓰는 분기문은 저 2개 뿐이라고해도 무방합니다만, 둘은 어셈블리 레벨에서보면 차이점이 있습니다.
If문은 컴파일 시, Branch가 Taken(True)하면 어디로 갈지 Not Taken(False)하면 어디로 갈지 알 수 있습니다. 하지만, 함수는 어느함수에서 해당 함수를 Call할지 모르기 때문에 Return하는 주소가 애매해집니다. 예를들어, 함수B에서 함수 A를 부른다면, Return값은 함수B일거고, 함수C에서 함수A를 부른다면 Return 값은 함수C 일겁니다.
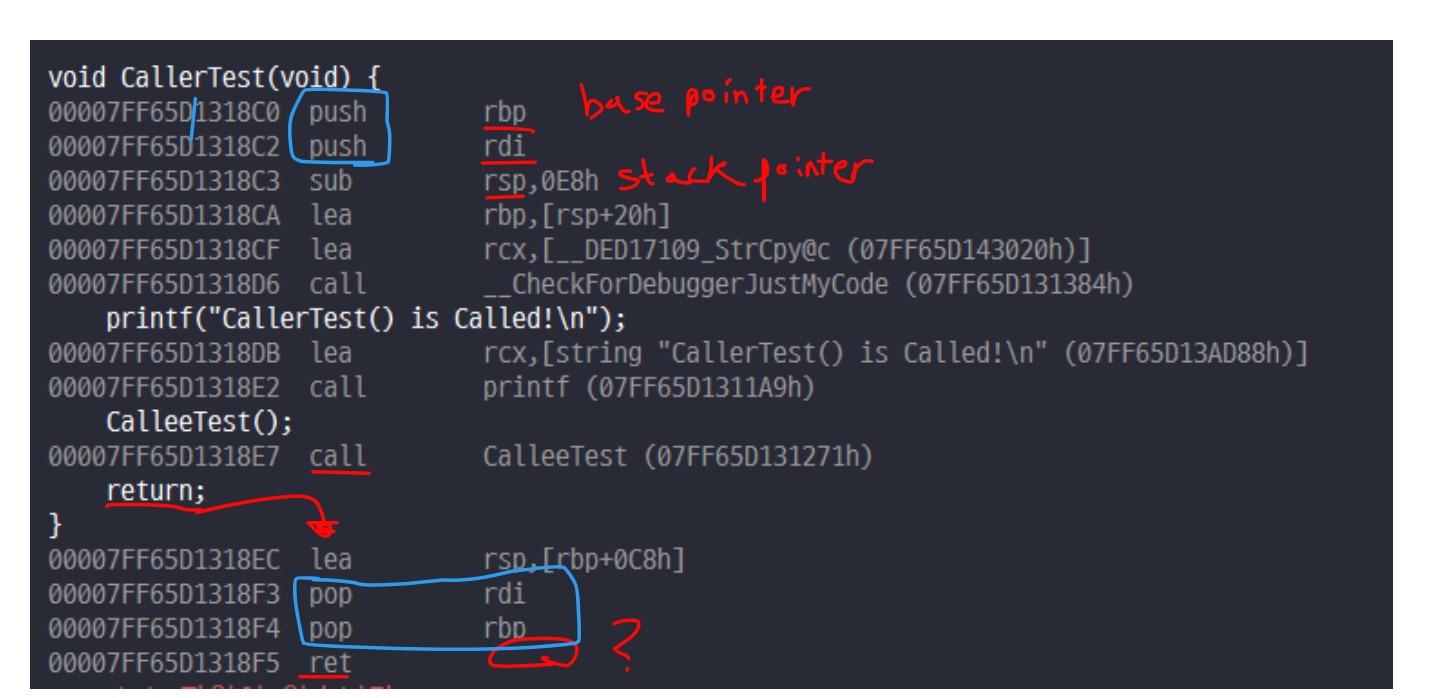
예측은 이렇게 할 수 있지만 진짜 그런지 확인을 해보면 확실하겠죠. Visual Studio로 어셈블리어를 손쉽게 볼 수 있습니다. 디버그 모드로 실행한 뒤 Ctrl + Alt + D
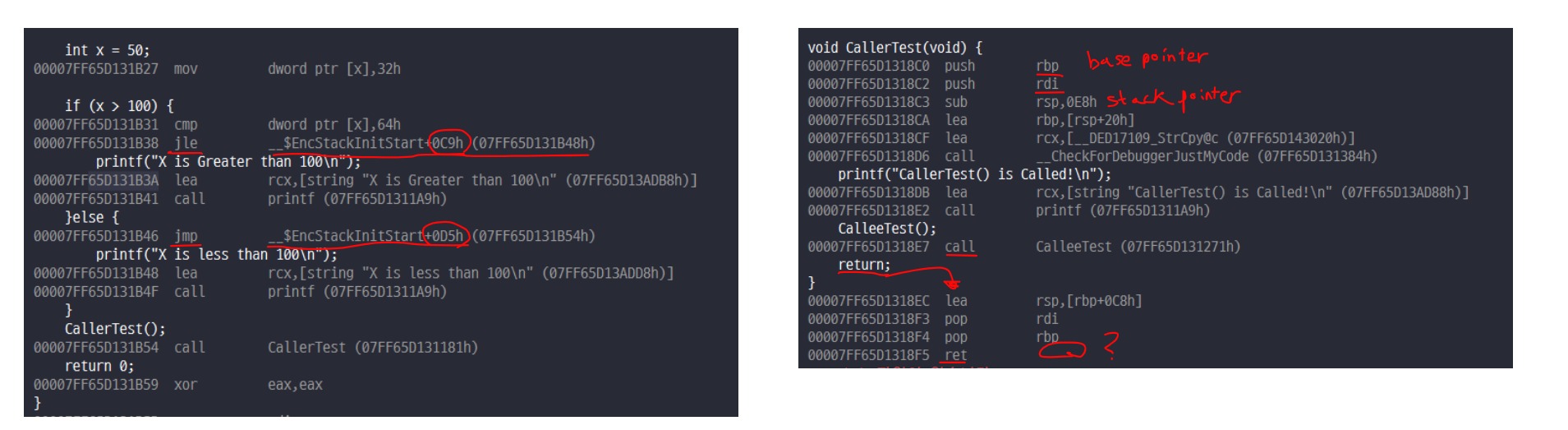
위에서 봤을 때, if문은 돌아갈 주소가 직접적으로 표시되어있는 반면에 함수는 return 뒤에 값이 비워져 있습니다. 즉, Branch마다 사뭇다른 메커니즘을 갖고있다는걸 알 수 있습니다.
Branch의 종류
프로그래밍시 활용하는 Branch는 Direct/Conditional을 조건으로 4가지로 보통 나눕니다. 하지만, 어떤 종류의 Branch냐에 따라서 예측방법이 고정적이진 않습니다. 예를들어, For Loop도 Conditional Predcitor와 BTB를 이용해서 예측을 할 수 있고, 항상 Taken하다고 가정을 한 채로 Prediction을 진행할 수 있습니다.
Branch의 특성에 따라서 Prediction 방법에 큰 영향을 주긴 하지만, 종류에 따라서 방법이 고정적인 것은 아닙니다. 제가 이런 착각을 많이했어서 적어 놓았습니다.
위를 언급하는게 어쩌면 혼란을 가중시킬 순 있지만 그래도 Branch도 다 같진 않고, 여러종류가 있다는 개념은 있어야 다양하게 시도된 Prediction 방법을 이해할 수 있습니다.
Prediction
예측을 하는것은 어렵게 생각하면 한없이 어려워집니다. 머리를 가볍게 하기 위해서 세상에서 어떤 것을 예측을한다는 것은 2가지 방법으로 이루어진다고 생각하고 갑시다.
- 어제 9시에 일어난 shark는 오늘 9시에 일어날 확률이 높다. -> 과거를 보고, 확률을 계산하기
- 넌 내일 9시에 일어날 거야. -> 과감하게 가정하기
static Branch Prediction
static Branch Prediction은 말에서도 알 수 있겠지만, static하게 고정적으로 예측을 한다는 의미니까 위에 말한 케이스중에 과감하게 가정하기 입니다. 응 넌 이럴거야~라고 static하게 가정을하고 시작합니다. 그리고 static Branch Prediction은 컴파일 타임에 알 수 있는 정보를 가지고 예측을 하는 것이기 때문에, Compile Prediction이라고도 합니다.
Always Taken
항상 맞다고 가정을 합니다. if문은 5:5지만, Loop문은 Taken한 경우가 매우 많습니다. 따라서, 정확도가 꽤 높게 나오게 됩니다. 60~70% 정도의 정확도가 나옵니다.
profiling - Add hint bit by compiler
컴파일러가 각 Branch명령마다 이 명렁은 Taken한지, Not Taken한지 등을 컴파일 한 코드를 보고 예측해서 hint bit에 기록을 해놓습니다. 현재에도 일부 쓰이는 방법입니다. 예를들어, Loop같은 경우는 항상 Taken할 것이기 때문에 hint bit에 Taken을 적어놓을 수 있습니다.
여기서 더 발전시켜서 프로그램에서 나타나는 관행들을 미리 칩셋안에 들고있다면, 더 정확하게 예측할 수 있다는 생각을 해볼 수 있습니다.
static이라는 키워드의 문제점
하지만, 코드란 것은 시대에 따라서 달라질 수 있기 때문에 그때마다 컴파일러를 바꾸고, 컴파일링 시간이 점점 길어지는 것은 바람직하지 않을 수 있습니다. 그리고, 무엇보다 컴파일 타임시 알 수 없는 Branch가 있습니다. 대표적으로 함수 Return 혹은 Indirect Jump명령어는 어디로 점프할지 전혀 예측을 할 수 없습니다. 그래서 좀더 유연하게 예측할 수 있는 방법으로 제시된게 아래입니다.

dynamic Branch Prediction
함수리턴 혹은 Indirect Jump명령어는 Jump하는 주소가 런타임시 결정이 됩니다. 컴파일 타임에 알 수 있는 방법이 없습니다. 따라서 , 이럴 때는 다른 방법으로 예측을 해야합니다. 바로, 과거 기록을 보고, 앞에도 그럴 것이라고 예측하는 방법입니다.
BTB
BTB(Branch Target Buffer)라는 하드웨어 장치에 Branch명령어의 주소와 Target주소를 기록한 뒤, PC를 보고 Branch인지 아닌지 예측을 하자는 아이디어 입니다.
특히, Indirect Jump에 유효합니다. 대표적으로 switch -case문같은 경우 case가 5개라면 5개의 주소중 하나로 분기하기 때문에, 5개의 주소가 이미 BTB에 적혀있다면 Fetch시에 바로 다음 점프할 주소를 알 수 있습니다.
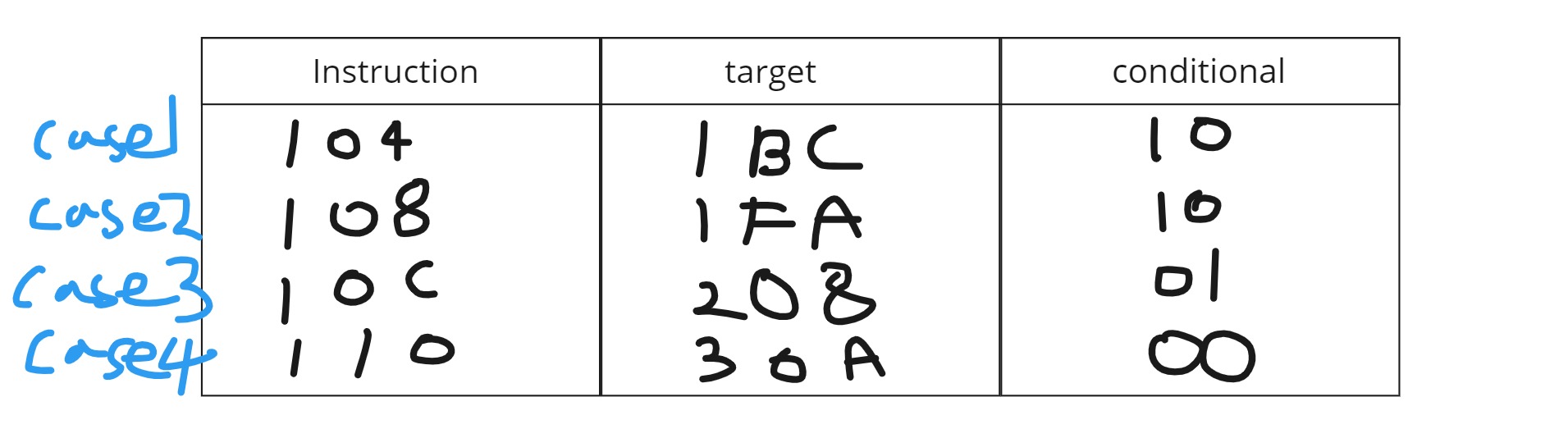
bimodal bits로 더 정교하게
Conditional이라는 필드도 있는데, 여기에 Taken인지 NotTaken인지 기록을 하게됩니다.
- 만약 Taken이라면 +1,Not Taken이라면 -1을 기록해서 BTB에서 Condition도 함께 예측을 합니다.
- 1bit를 이용해서 예측을하면 정확도가 떨어지기 때문에 보통 2비트를 이용해서 2,3(10,11)이면 Taken, 0,1(01,00)이면 Not Taken으로 예측합니다.
현대의 CPU에서는 BTB는 Target Buffer정도로만 쓰이고, Conidtional을 예측하는 것은 더 정교한 장치에서 따로 계산하여 예측합니다.
함수는 특별하니까 RAS
함수는 BTB에 기록을 해도, 예측 실패율이 높습니다.
왜냐하면, Return을 생각해보면 Call이 어디에서 됬냐에 따라서 Return되는 주소가 달라지게 됩니다. 또, 불려지는 위치에 따라서 Instruction도 한정적이지 않아 애매하지만, 함수를 쓰지않는 프로그램은 없습니다. 따라서, 함수는 Return Address Stack이라는 곳에서 따로 관리를 합니다.
원리는 Return하는 주소를 미리 RAS에 순차적으로 저장해두자 입니다. 아까 callerTest()를 부를 때, Push와 POP이라는 명령어를 잠깐 보셨을 겁니다. 이때, Push하는게 돌아갈 주소를 저장하는 과정 입니다. 이렇게하면, Pipelining을 할 때, Fetch에서 PC값을 Pop하는 값으로 지정하면 되기 때문에 파이프라이닝이 끊기지 않습니다.