
지난 글에서는 어떤 처리기에서든 일어나는 RAW Hazard와 해결법에 대해서 적었습니다. 지금 다루는 내용은 Data Dependency로 인해 일어나는 3가지 Hazard들 입니다.
남은건 OutofOrder 혹은 Parallel에서 일어나는 WAW와 WAR에 대해서 입니다. 그렇다면 , 먼저 OutofOrder이 뭔지에 대해서 알아봐야합니다. 저도 이게 정확하냐고 했을 때, 틀린 부분이 있을 수 있습니다.하지만 꽤 재밌는 이야기이고, 틀린 부분이 있다면 꼭 정정해주시면 감사하겠습니다.
Computer(CPU) Performance 측정
파이프라이닝의 목적은 쓰루풋(Throught put)을 늘려 처리효율을 증가하는 것이었습니다. 파이프라이닝으로 인해 처리율을 올라간것은 확실하지만 이제 사람들이 Performance 즉, 진짜 이게 효율적인지 아닌지에 대한 기준을 만들어야 했고, 그럴려면 측정을 해야했습니다.
CPU의 Performance는 Clock당 처리효율이 얼마나 높은지 측정합니다. 하지만, 프로그램(프로세스)이 더 빠르게 처리되는 것은 다양한 요인을 가지게 됩니다. CPU도 빨라야하고, RAM의 크기도 중요할 것이고,해석되는 Instruction의 수도 중요할 겁니다. 또 OS도 중요합니다.

그래서, 이런 모든 것을 고려하여 평가기준을 만드는 것도 필요하지만 좀 더 실용적인 지표를 생각해봅시다. 같은 환경일 때 시간 당 많은 프로그램(프로세스)를 실행하는게 더 빠르다고 생각할 수 있습니다.

Performance = Programs/Time 이라는 아주 간단하면서 명료한 식이 나옵니다. 하지만, 이걸 우리가 알 수 있는 정보로 해석하려면 몇가지 작업이 필요합니다.
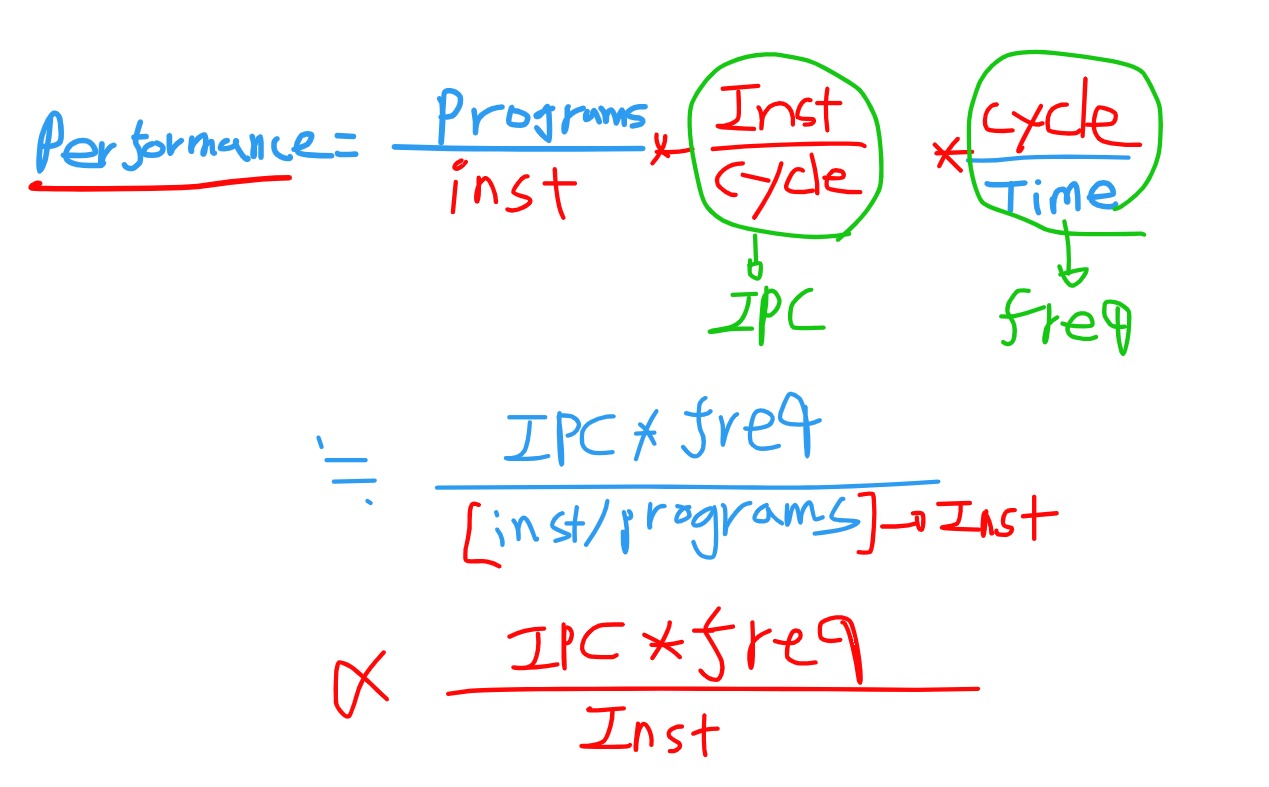
- IPC : Instruction Per Cycle . 한 사이클 당 처리하는 명령어의 갯수
- Frequency : 진동수(CPU의 클락 수)
- Instruction(Inst/program) : 한 프로그램당 명령어 수 (Compiler)
위와 같은 비례식이 세워집니다.복잡해보이지만 비례식은 의미에 집중해서 보면 됩니다. 명령어 수가 적으면 Performance는 올라갑니다. 즉 , 컴파일러로 해석되는 머신코드가 적으면 빨라진다는 이야기입니다. 그리고, 한 사이클 당 처리하는 명령어의 갯수가 많으면 당연히 성능은 올라가고, 진동수(Hz)가 빠를 수록 클락이 빨리 도는거니까 당연히 성능이 올라갑니다.
Frequency
처음에는 Frequency를 늘리는 작업을 했다고 합니다. 실제로 요즘 clock은 GHz단위입니다.
stage수를 늘릴 수록 Frequency는 올라간다.
pipelining과 연관지어서 설명해보면, Pipelining에서 Stage수는 Frequency에 영향을 주게됩니다.
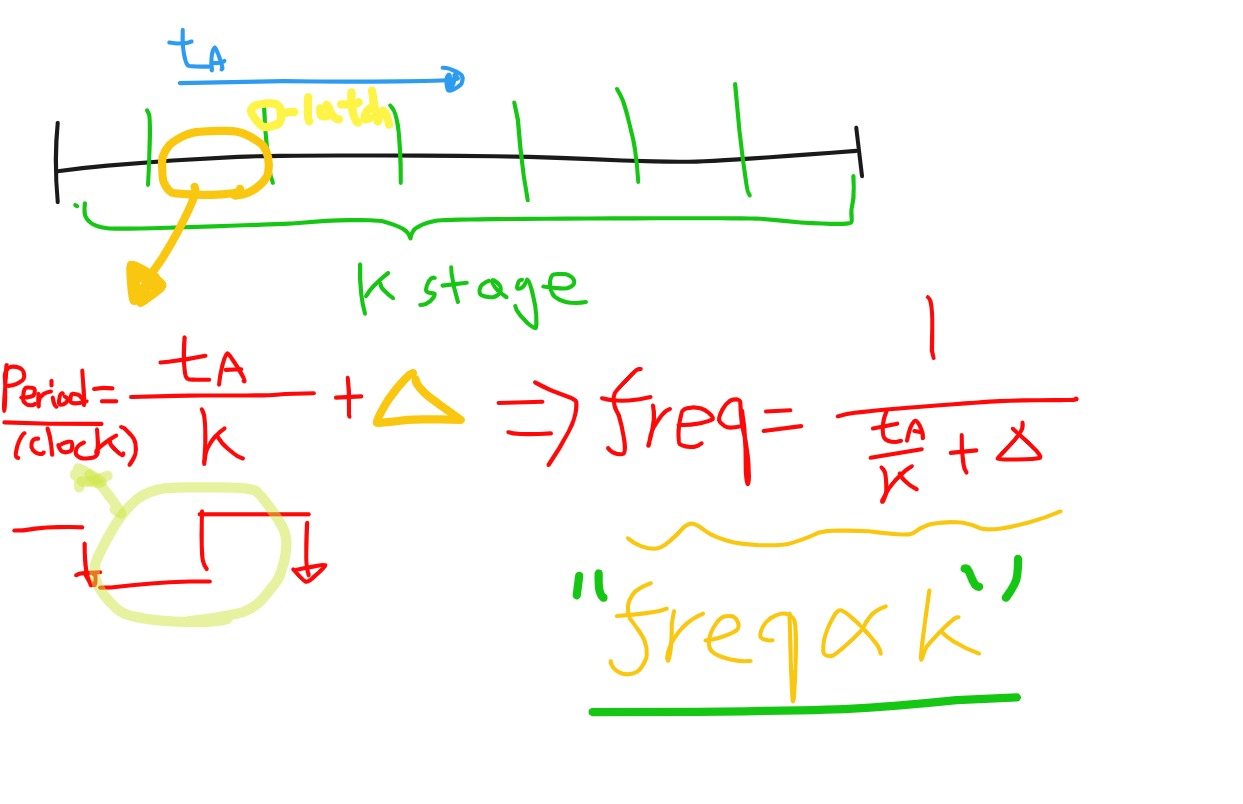
- Ta : 하나의 작업을 완료하는데 걸리는 시간
- K : stage의 수
- 세모(델타) : stage를 나누는 Latch를 통과하는 Overhead
Frequency는 K에 결국 비례하게 됩니다. 하지만, K가 무한정 커지면 델타에 수렴하기 때문에 스테이지를 무한정 늘리는것은 의미가 없습니다. 그리고 진동수(클락 수)의 한계는 명확합니다.
- P(전력) f^3 or f
- P(전력) T(Temperature)
전력소모량과 F의 관계는 CPU의 아키텍처마다 달라진다고 합니다. 그리고 현재 나오는 CPU들은 f^3이 아니라고 합니다. 정확한 지식을 전달해드리고 싶으나 전자공학에 대한 깊은 이해도가 있지 않아 증명을 못해드리나, 자료를 찾은 링크를 달아놓겠습니다.
결론은 Frequency를 늘리면 발열량을 결국 잡아야하고 전력소모량도 상승하기 때문에 Frequency에는 한계가 있다는 겁니다.
SuperScalar의 등장과 드러나는 InOrder의 문제점
그렇다면, 성능(Performance)를 높이기 위해서, 사람들은 어떻게 했을까요? Instruction의 갯수를 줄이는건 Compiler에서 열심히하면 되고, CPU에서는 클락 당 처리되는 명령의 수(IPC)를 늘리는 노력을 하기로 했습니다. 그래서, 하나의 파이프라인에 여러 개의 파이프라인이 처리되는 SuperScala Pipelining이 나왔다고 합니다.
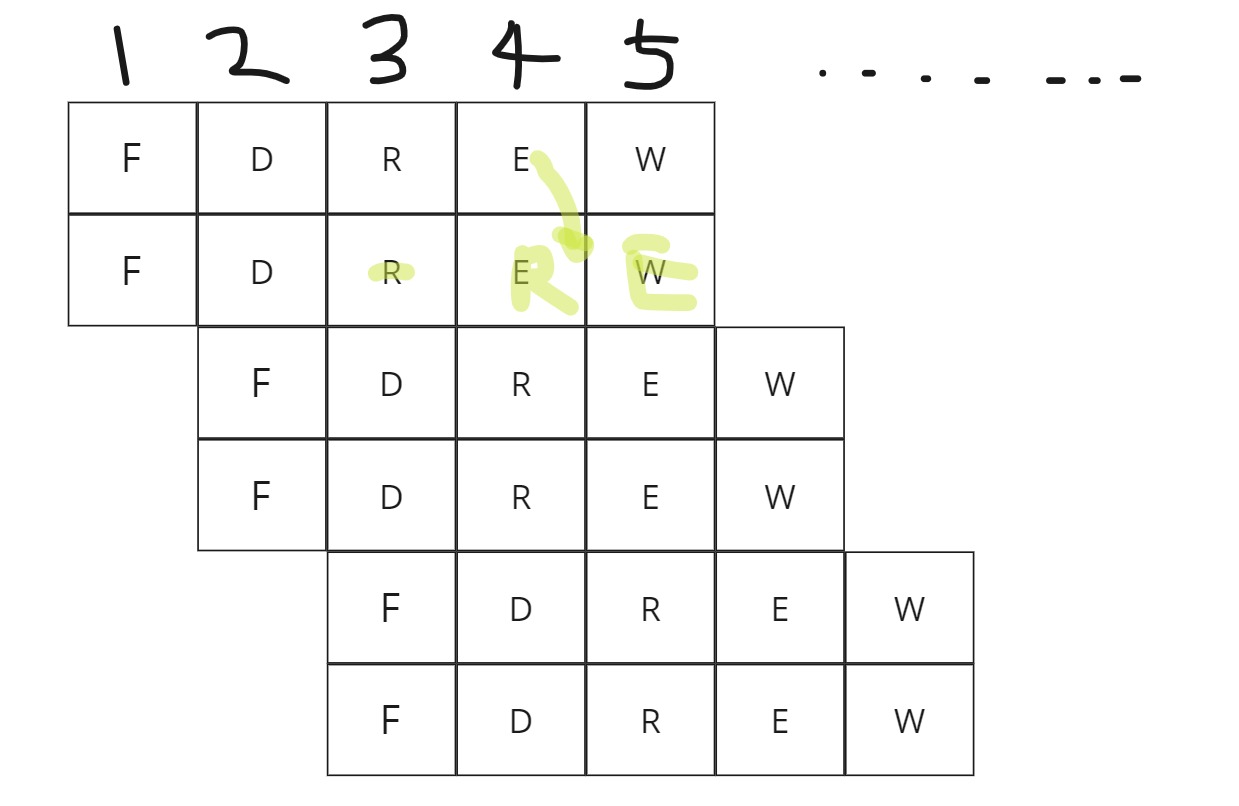
처음에는 팬티엄에서 2개의 파이프라인(u,v)를 이용해서 완벽하지 않지만 ,슈퍼스칼라와 비슷한 구조를 만들었다고 합니다. 하지만, 이때까지만 해도 명령어는 InOrder로 처리하는게 보편적이었습니다. 내부적으로도 순차적으로 명령어가 처리가 되기 때문에 2개의 파이프 라인을 이용해서 처리를 한다고 했을 때, 1클락 내에서도 Data Dependency, Brach Hazard가 발생할 가능성이 높고, 이건 수많은 stall로 인해 성능이 떨어질게 예측이 되었다고 합니다.
OutofOrder(OOO)의 등장
그래서, 기존 패러다임부터 재검토를 하게 됩니다. 과연, 명령어가 꼭 순차적으로 실행이 되어야하는가? 먼저 끝낼 수 있는 명령어가 있다면 , 먼저 끝내는게 더 효율적이지 않을까?로 연구주제가 바뀌어서 거기에 따른 연구가 진행되었다고 합니다.
책의 말을 빌리자면, 비순차적인 실행(OOO)은 명령어 수준에서의 병렬성(ILP)을 찾아서 ,이를 순차적으로가 아니라 병렬적으로 처리할 수 있도록 한 기술입니다.
Instruction Window
Instruction Window는 명령어들이 잠시 대기하는 공간입니다. InOrder에서는 순차적으로 명령어가 들어온대로 CPU를 차지하고 연산을 했다면 이제는 잠시 대기를 시켜서, 뭔가 더 처리를 해주겠다는 아이디어입니다.
한줄요약
CPU내부를 차지하기 위해서 Instruction들이 잠시 대기를 하는 장소라고 생각하면 됩니다.
- 명령어 윈도우는 처리가되는 명령어의 스트림에서 일정 범위내의 명령어를 묶어서, 의존성 검사 , 동적 스케줄링(Reservation station) , ReOrder..과정을 내포합니다.
- 알고리즘에 슬라이딩 윈도우라고 생각하면 되는데, 슬라이딩 윈도우에서 내부적으로 뭔가 처리가 가미된 슬라이딩 윈도우 입니다.
- 결론은 , 아래의 동작들이 사실상 OOO를 만들어내는 기술들이라는 말입니다. Instruction Window는 명령어들이 잠시 대기해서 검사를 받는 곳일 뿐입니다.
OOO에서의 Data Dependency
비순차적으로 실행을 한다고 해도, RAW(Read after Write)는 막을 수 없습니다. 없는 데이터를 읽는건 불가능합니다. 하지만, 아래와 같은 의존성은 제거가 가능합니다. 의존적인것 처럼 보이지만, 의존적이지 않은 경우입니다. WAW Hazard, WAR Hazard라고도 불리는 현상입니다.
WAW Hazard
I1 : ADD R1 R2,R3
I2 : SUB R1 R5,R7- 결과가 Overwrite되는 현상입니다. I1 ->I2 순서대로 처리가 되길 원하지만, OOO 상황에서는 I2가 먼저 실행되어 끝날 수 있습니다. 하지만, 프로그램 자체는 I1->I2 순서대로 실행을 해야합니다.
WAR Hazard
I1 : ADD R1 R2,R3
I2 : SUB R2 R5,R6- I2가 먼저 끝났다고 가정을 했을 때, I1에서도 R2값을 쓰게됩니다. 즉, I1->I2 순서로 진행되어야하는 명령어가 I1이 미래의 값을 읽어버리는것과 같은 현상입니다.
WAR,WAW Hazard는 우리가 어떤 특정 레지스터를 재활용해서 생기는 문제점입니다. 위의 예시에서 아래와 같이 변경하면 아무런 문제가 없고 동작 자체도 문제가 없습니다.
I1 : ADD R1 R2,R3
I2 : SUB R10 R5,R6재활용을 하지 않는 방법이 없을까? -> 이런거 컴퓨터에 흔합니다. 가상화시켜서 논리적인것과 물리적인 것을 분리시키는 방법
Register Renaming
Instruction Winodw에서 의존성(WAW,WAR)을 제거해주는 방법입니다. 우리가 이전까지는 진짜로 1번,2번,3번 레지스터를 썻다고하면 이걸 이제, 이름만 1번,2번,3번으로 정해놓고 실제로 배정되는 레지스터는 다르게 해주자는 개념이다.
논리 레지스터파일(ARF)와 물리레지스터파일(PRF)를 따로 쓰자는 이야기입니다.
위의 예시를 좀 더 확장해서 3가지 명령어가 있다고 생각해봅시다. Register Renaming을 적용하면 오른쪽과 같이 CPU내부에서 프로그래머 모르게 치환해서 연산을하게 됩니다.
I1 : ADD R1 R2 R3 ----> I1 : ADD PR1 PR2 PR3
I2 : ADD R3 R5 R1 ----> I2 : ADD PR13 RP5 PR1
I3 : SUB R3 R7 R5 ----> I3 : ADD PR23 PR7 PR5-
R3의 저장하는 주소가 다 분리된게 보이시나요? 이렇게 하면, 의존성을 제거할 수 있습니다. I1과 I2에서 WAR을 해결하기 위해 R3에 다른 주소를 줍니다. 그리고, I2와 I3에서 WAW를 제거하기 위해 각각 다른 주소를 주게됩니다.
-
내부적으로 Index를 가져서 bit수를 가지고 추상화시키는 장치가 추가적으로 들어가게 되는겁니다. 말 그대로 하드웨어적인 추가장치 입니다.
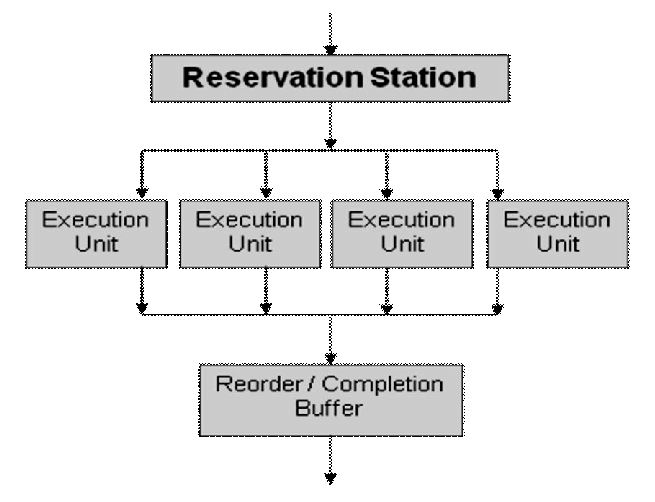
Reservation station
Instruction Window에서 Operand가 준비된 명령어들이 먼저 Functional Unit(ALU,FPU,MMU..)에 가서 계산을 하게됩니다. 그렇다면, Operand(데이터)가 준비되지 않은 명령어들은 데이터가 준비될 동안 잠시 기다릴 공간이 필요합니다. 이 공간들이 바로 Reservation Station이라는 Queue입니다.
Reservation Station은 그림으로 보면 더 확 와닿게 됩니다. 각 Execution Unit마다 station을 따로 가지고 있을 수도 있고, 하나의 큐안에 모아서 관리할 수도 있습니다. Central하냐, Distribute하냐의 차이가 있습니다.
Re-Order Buffer
OOO를 공부하면서 가장 중요한 부분이 바로 이 부분이라고 저는 생각합니다. OOO는 비순차적으로 실행하되, 실행순서는 지키고 싶어합니다. 이건 문법적으로는 뭔가 말이 안될 수 있습니다만, 좀 더 외부에서 보는 시선으로 바라보면 딱 이해가 갑니다.
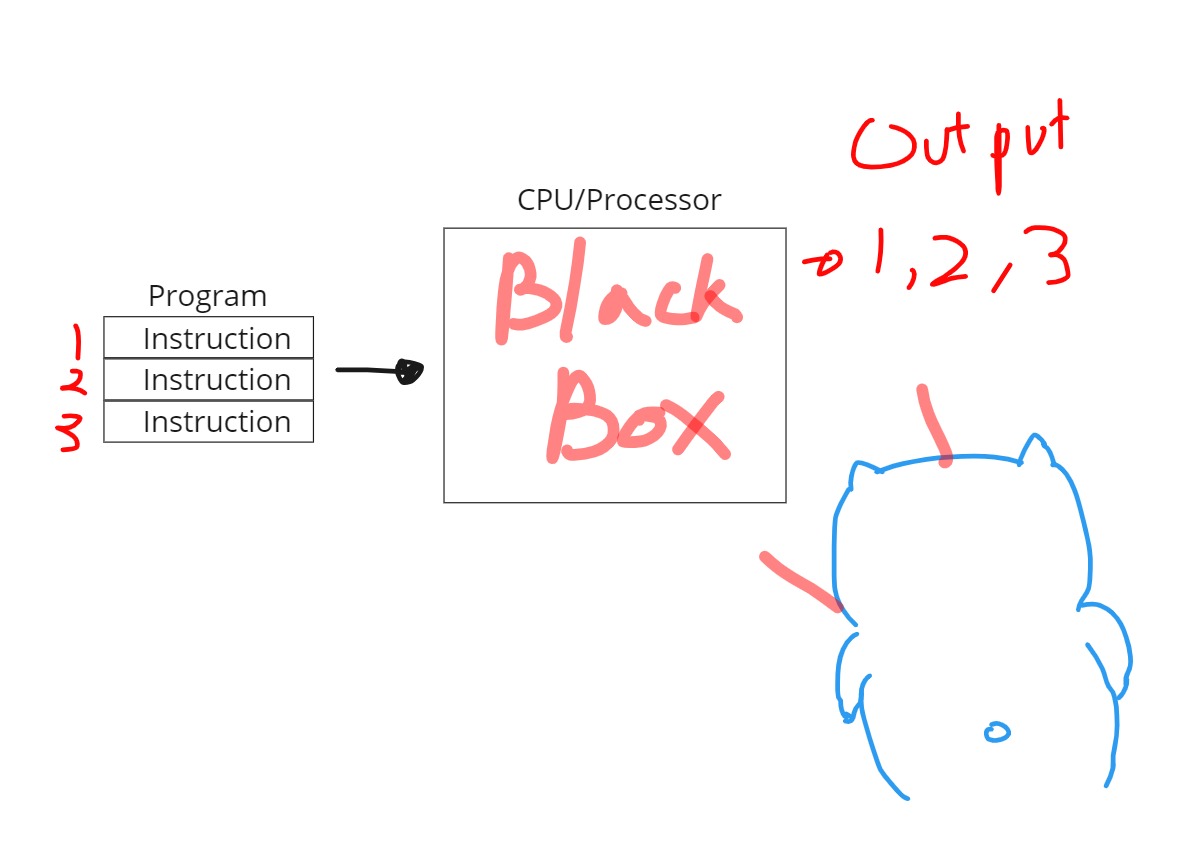
- Program은 A sequence of instruction 입니다. 순차적으로 명령어가 실행되어야 합니다.
- 하지만, Processor는 처리량을 늘리기 위해서 내부적으로 처리는 순차적으로 하지 않습니다.
- 그렇지만, Program은 순차적으로 실행이 되어져서 결과로 조립이 되어야합니다. 따라서, OutPut또한 순차적으로 1,2,3으로 나와야합니다.
- 이렇게 내부동작을 모르는 어떤한 대상을
Black Box라고 보통 합니다. Processor를 BlackBox라고 생각했을 때 1,2,3순서대로 넣었으면 1,2,3순서대로 나오길 사용자는 바라게 됩니다.
정리하자면, 프로그램이 처리순서는 달라질 수 있어도 실행할 때마다 최종결과가 달라지면 안됩니다.
이걸 해결해주는게 ReOrderBuffer ROB입니다.
OutofOrder의 문제점
OutOfOrder의 문제점은 위의 글에서 계속 나왔지만, 정리하는 목차라고 생각하면 될것 같습니다.
- Instruction끼리 처리순서가 달라져서 InOrder에서와 다른 Data Dependency가 생긴다. ->WAW,WAR Hazard -> Register renaming으로 해결.
- 비순차적으로 실행이되나, 최종결과가 달라지면 안된다. 즉, ReOrder를 해주어야한다.
- 아직 Branch Hazard가 해결되지 않았다. 오히려, InOrder에 비해서 더 자주 발생할 수 있다.
- 에러가 났을 때, 복구를 위한 별도의 처리가 필요하다.
Branch Prediction의 필요성
파이프라이닝은 기본적으로 연속적으로 명령어가 들어오는데 Branch의 연산은 비선형적인 주소가 발생한다는 점입니다. Branch연산이 발생하면 파이프라이닝을 비워줘야합니다. 게다가 Branch 연산은 For문과 If문, 함수 등 다양한 구문에서 활용이 되어서 프로그램 전체의 25%정도를 차지합니다. 4개 명령어 중 1개는 분기입니다.
파이프라이닝에서 Branch 명령어는 꼭 해결해야하는 문제이다. -> BTB의 등장 .
그래서, 90년대에 제일 핫한 주제가 Branch Prediction이였다고 합니다. 약 98~99% 정도의 분기예측이 가능한 하드웨어 장치를 개발하는게 목표였고 현대에는 모든 CPU에 다 들어가있다고 합니다. 다음 글에는 기본적인 모델인 BTB에 대해서 살펴보려고 합니다. 2-level-adaptive predictor가 Branch Prediction이 97~98%되는 발전된 모델인데, 자료가 논문밖에 없습니다.
논문을 읽는데는 꽤 큰 시간이 소요되고,이해할 수 있을지도 미지수기 때문에.. 한번 읽어보고 이해가 가능하다면 제가 글을 업로드 해보겠습니다.
참고) Exception Handler
OutOfOrder에서 Exception이 발생하는 경우에도 생각을 해야합니다. 예를들어 zero divide 에러가 코드 중간에 있다고 했을 때,I2까지는 적어도 실행을 하고 I3에서 에러를 내주어야 합니다. 하지만, I3가 먼저 평가되서 에러를 뱉을 수도 있습니다. 그러므로, Error는 별도의 처리유닛(장치)가 필요하게 되는데 이게 Exception Handler입니다.
I1 ADD R1 R3,R5
I2 ADD R5 R2,0
I3 DIV R3 R3,0I2까지 실행...Ik-1까지 실행 -> IK에서 에러 발생 -> IK+1 그 이후 명령어 실행 or 멈추기를 판단해야합니다.
- Stop and Resume을 어떻게 해 줄 것인가
- 에러 핸들을 할 때 누구(OS,Exception Handler와 같은 별도의 Unit,Keyboard,스크린,마우스...)의 도움을 받을 것이냐
Interrupt ,Exception Vector를 CPU내부에 가지고 있는걸로 알고있습니다. 물론 OS도 갖고 있습니다.
디테일을 챙기지 못한것에 대한 회고
이번 글은 자세하게 설명하기 보다는 개념적으로만 짚고 넘어가는 느낌이 강합니다. Reservation Station과 ReorderBuffer, Register renaming 장치가 어떻게 동작하는지 디테일을 살펴보진 않았습니다. 그리고, OOO에서 실제로 명령어를 처리할 때 일어날 다양한 상황들에 대한 디테일을 짚고가진 않았습니다. 하나하나가 큰 주제이기 때문에, 글이 중간으로 빠질까봐 개념만 잡는 형태로 글을 쓰게 되었습니다.
다음 글은 BTB와 Branch Hazard에 대해서 다루고, Cache로 넘어갈 겁니다. 추후에 디테일에 대한 것은 좀 딥하기 때문에 외전격으로 다룰 예정입니다. 혹시 디테일이 너무 궁금하시고, 제 글이 올바른 정보를 전달하지 않을 수 있기 때문에 제가 본 강의 링크를 남겨놓겠습니다.
IIT(인도공과대학) Advanced Computer Architecture
- OOO 1,2,3편 , Fetch Decode stage ~ Commit stage (학습 중)

개념 이해에 정말 많은 도움이 되었습니다 감사합니다 :)