
오늘은 현대 CPU의 처리효율을 굉장히 굉장히 높여주면서, 동시에 해결해야할 문제점(?)을 선물로준 파이프라이닝에 대해서 적어볼까 합니다. 파이프라이닝은 2~3편정도에 걸쳐 길게 적으려고 합니다.
머리안에서 자신만의 CPU구조 생각하기
파이프라이닝에 대해서 설명하기 전에, 파이프라이닝이 적용되기 전 CPU의 동작방식과 문제점에 대해서 알아봅시다. CPU(Central process Unit)의 역할에 대해서 생각을 해봤을 때, 어떤게 가장 먼저 떠오르나요?

위 같은 하드웨어 장치를 떠올리시는 게 당연하고 자연스럽겠지만, 저는 CPU를 떠올릴 때 이렇게 생각합니다. 어엄청 빠른 계산기들이 cache를 내부에 갖고있고 그리고, 이 엄청빠른 계산기가 1클락당 명령어를 하나씩 처리한다고 생각합니다.
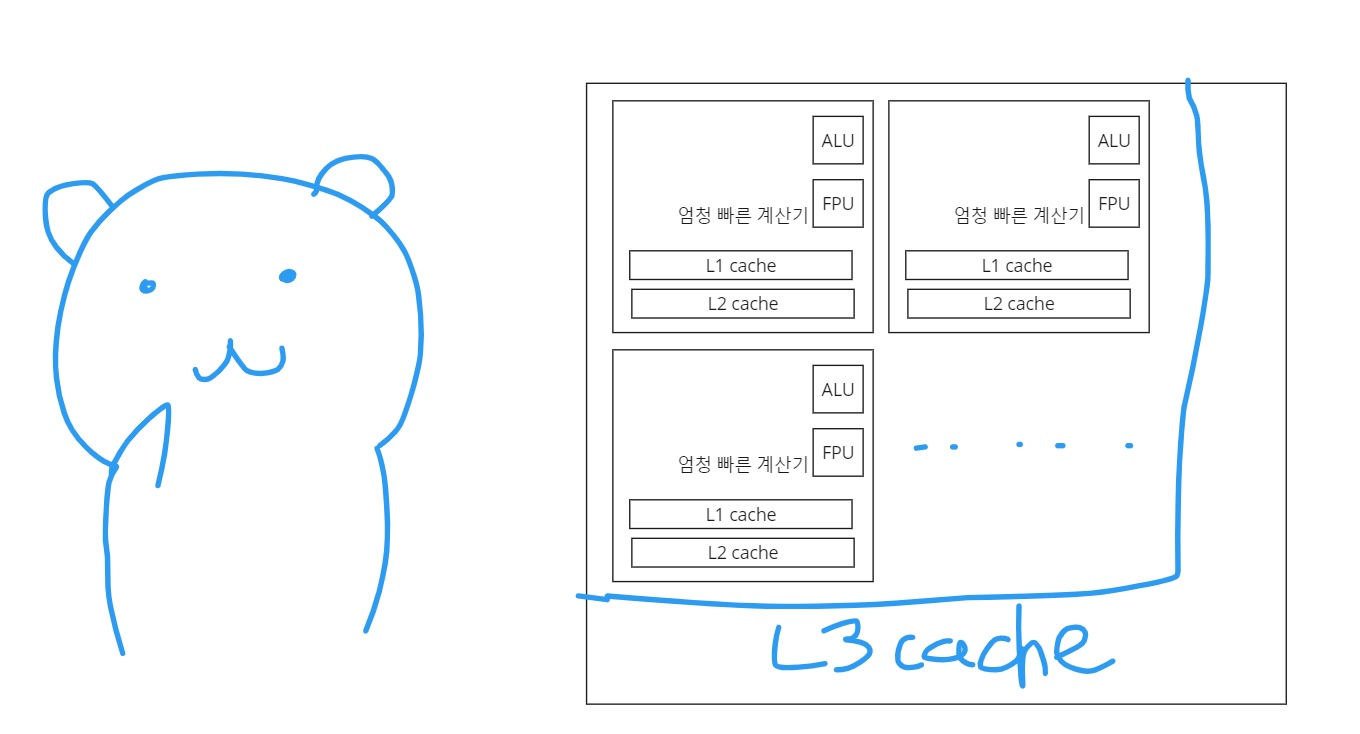
감히 깊게 들어가면 CPU 회사에 따라 다르고, 현대는 또 병렬코어니까 데이터 동일성을 맞추기위한 장치와 최적화를 위한 장치들이 많이 들어가기 때문에 모두 설명하는 것은 제 능력안에서는 불가능합니다. 그래서, 저는 여기까지만 딱 생각합니다. 내부에 cache를 갖고 있고, 엄청 빠른 계산기가 여러개 있다.
그렇다면, 자연스럽게 명령어를 처리하는 순서가 있게 됩니다.. 그 과정을 Fetch - Decode - Read - Execute - WriteBack 5단계로 부르게 됩니다. 이 5개의 영어단어는 의미가 중요하기 때문에, 이것 그대로 이해하는게 좋습니다. 하지만, 저는 25년 토종 한국인이기 때문에 영어를 읽어도 생각은 한국어로 하겠죠? 저의 뇌를 거친 5개의 영어는 이렇게 해석이 됩니다.
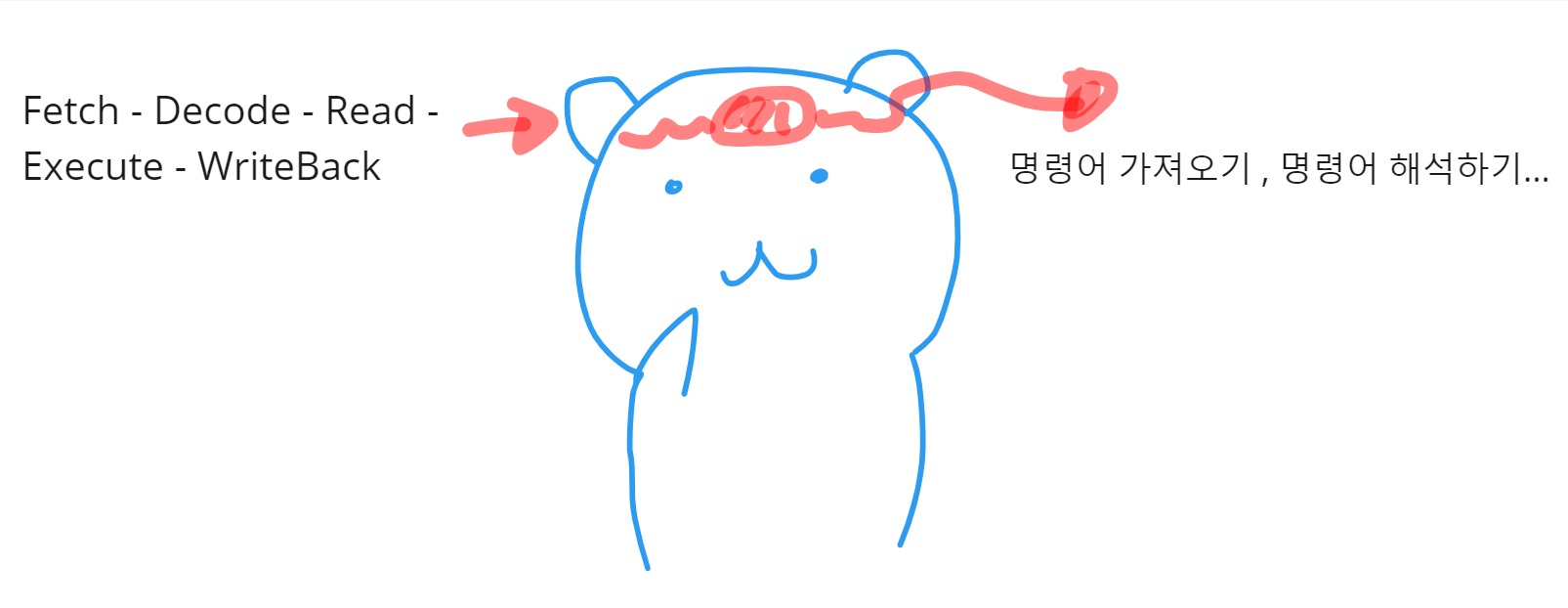
Fetch(명령어 가져오기) -> Decode(명령어 해석하기) -> Read(명령어 읽기) -> Execute(명령어 실행하기) -> Write Back(명령어 실행결과 저장하기)
영어를 잘하시는 분이라면 야 뜻대로 그대로 해석한거 아니냐 라고 할 수 있긴한데, 네 맞습니다. 하지만, 이렇게 생각하는 방식을 치환하면 가끔은 더 쉽게 이해되는 경우가 있어서 잠깐 소개를 해드립니다.
그리고, 사실 당연한 순서입니다. 명령어 실행기가 CPU니까, 가져오고 해석하고, 읽고, 실행하고 , 데이터 저장하고
명령어 해석순서
파이프 라이닝이 없는 CPU는 한번에 1개의 명령어를 처리하게 됩니다. 따라서, 첫번째 작업(I1)이 끝날 때 까지 다음 작업 (I2)는 기다려야하고, Fetch 작업도 못하게 됩니다. 한 stage당 1사이클이라고 했을 때 , 3개의 명령어를 처리하려면 15번의 사이클이 필요하다고 할 수 있습니다.

쓰읍... 뭔가 좀 느린것 같다. 그리고, 뭔가 비효율적이지 않나..?
파이프라이닝
파이프라이닝은 현실세계에도 흔하게 볼 수 있는 개념입니다.쿠팡알바를 생각해보면 됩니다.
만약, 택배물품 하나가 집품 -> 포장 -> 상하차 -> 배송 이 다 끝나야만 다음 택배물품을 진행 한다고 생각해봅시다. 굉장히 비효울적이란걸 알 수 있습니다.
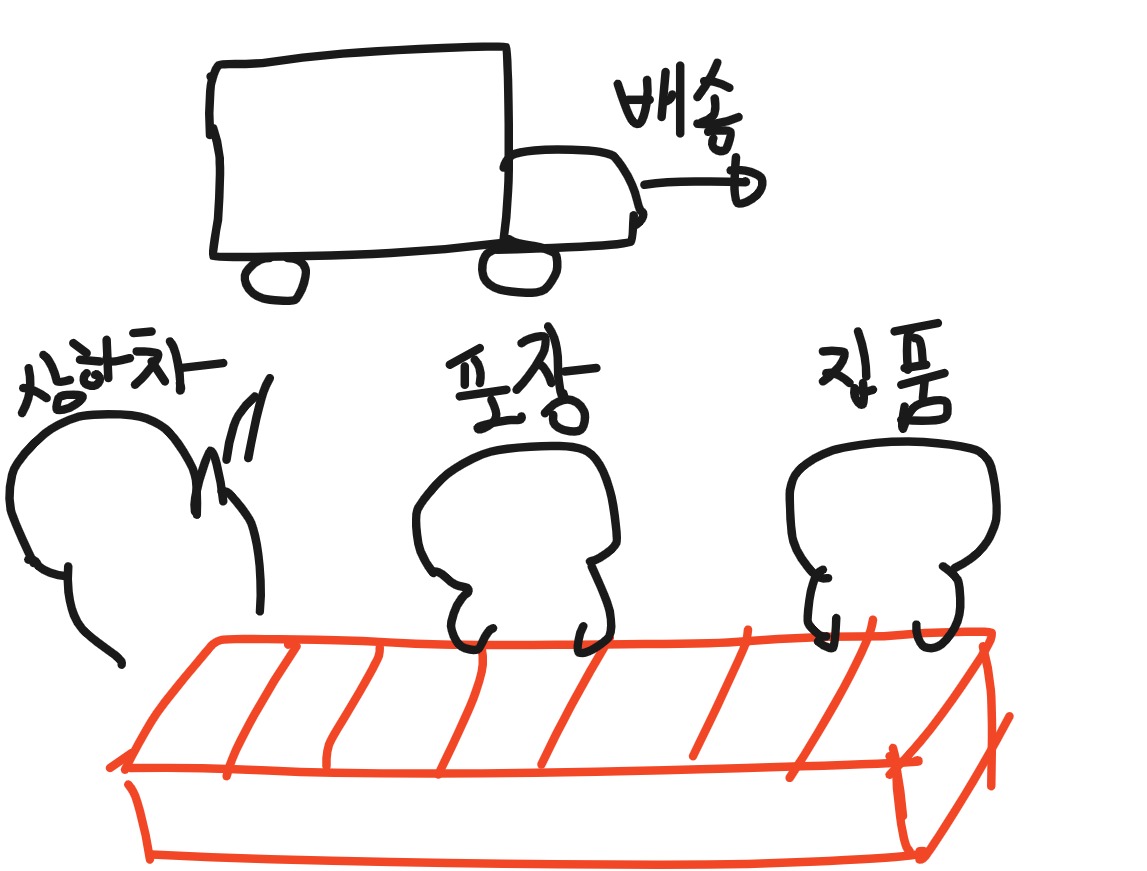
즉, 누군가가 포장을 할 때 앞에서 미리 집품을 해놓고, 누군가가 상하차를 할 때 앞에서 포장을 끝내야하고, 누군가가 배송을 할 때 미리 상하차 준비를 해놔야합니다.
파이프라이닝은 명령어처리를 각 스테이지로 나누어서 미리미리 처리해놓자는 개념입니다. 그림으로 보자면, 아래와 같이 명령어를 연달아서 처리하자는 개념입니다.

파이프라이닝의 장점
처리효율이 말도 안되게 상승합니다.
얼마나 효율적인지 감이 오지 않는다면 이렇게 상상해봅시다. 자동차 1개를 만드는데 2시간이 걸린다고 했을 때, 처음 자동차는 2시간이 걸리겠지만 다음 자동차부터는 마지막 공정시간만 기다리면 나옵니다. 자동차들이 마치 마지막 공정시간이 지날때 마다 1대씩 나오게 되는겁니다. 처리효율이 말도 안되게 올라갑니다.
하지만, 어떤 기술이든 적용을 할 때는 단점이 있게됩니다. 단점이 없는 솔루션은 세상에 거의 없는걸로 알고 있습니다. 파이프라이닝은 단점이 뭘까요?
파이프라이닝의 단점
파이프라이닝의 단점은 명확합니다. 각 스테이지별로 나누는 것도 한계가 있습니다.
예를들어 , 현실이라면 각 공정을 나눌 때마다 각 공정에 맞는 사람을 뽑아야합니다. 인건비가 더 듭니다. 시설도 더 필요하게 됩니다. 전자세계(CPU)에서는 이게 발열과 전력소모량이 됩니다.
그리고 무엇보다 제일 큰 문제점은 명령어는 순차적으로 실행이 되기 때문에, 명령어 사이에 의존성이 존재하게 됩니다. 즉, 파이프라이닝을 하게되면 에러가 발생할 수 있습니다.
예를들어, I2명령어가 I1명령어가 끝나야만 실행할 수 있는 경우가 있을 수 있습니다.
I1 R3 : R1 + R2
I2 R4 : R1 * R3
I1 -> I2 순서대로 실행이 될 텐데, R3 값에 저장이 되고 I2는 실행할 수 있다.아래와 같이 WriteBack전에 명령어를 실행할 수 없다면 지연시킬 수 밖에 없고, 이렇게되면 pipelining을 쓰는 의미가 거의 없습니다. 투자대비 효율이 나와야하는데, 투자대비 효율이 안좋으면 쓸 이유가 없습니다. 아래의 그림을 보면 더 이해가 잘 갑니다.
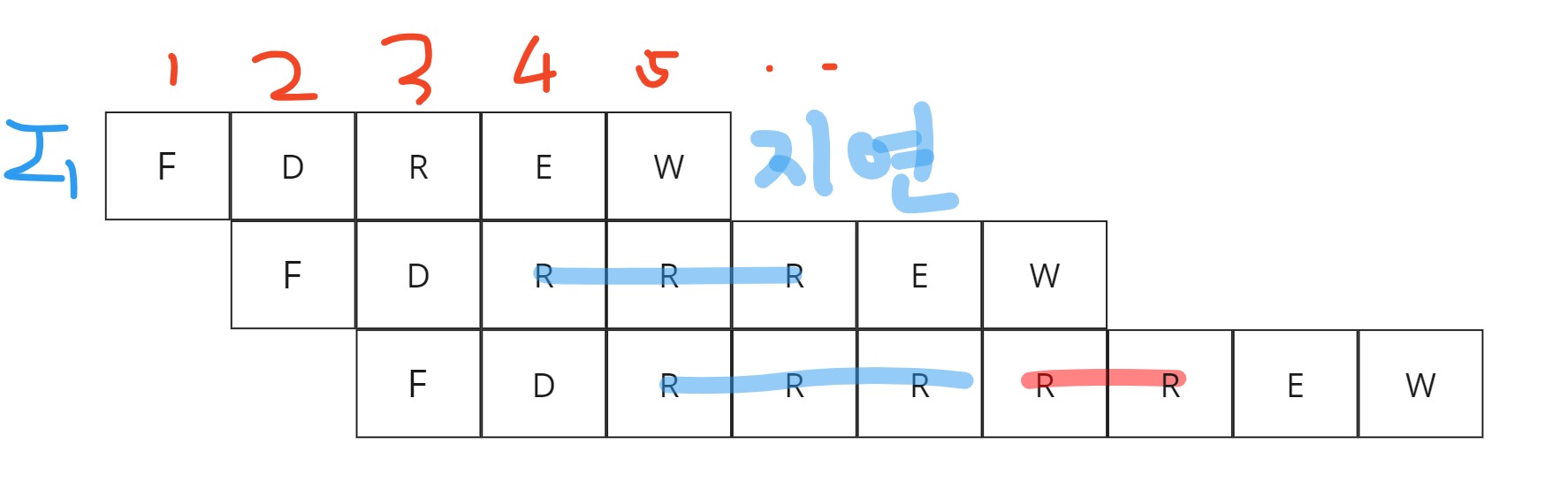
파이프라이닝에서 일어날 문제상황 해석하기
그래서 훌륭하신 우리 컴퓨터공학도 선배(선조)님들이 이 단점을 해결하기 위해서, 파이프라이닝에서 어떤 에러가 일어날 수 있고, 이걸 어떻게 해결할 수 있을지 연구를 하게 됩니다. 왜냐하면, 성공만 한다면 처리효율을 진짜 드라마틱하게 높일 수 있습니다. 그래서, 문제상황들을 추상화(개념화)시키고, 그것을 어떻게 해결할지 이야기가 시작됩니다. 다음글로 가시죠!
