지난 글에는 파이프라이닝에 대한 개념과 문제점이 일어날 수 있는 가능성에 대해서 글을 적었습니다. 오늘은 파이프라이닝의 문제점이 무엇이고 어떻게 해결할 수 있을지에 대해서 적어보겠습니다.
참고) 설명하는 기준은 InOrder 파이프라이닝을 기준으로 먼저 설명합니다. 현대 CPU는 OutOrder 파이프라이닝이 기본이지만, 발전과정의 순서대로 배우는게 이해하기 쉽습니다.
파이프라이닝의 문제점
파이프라이닝의 가장 큰 문제점은 하나의 일(task)를 stage 별로 처리를 하기 때문에, 각 stage간의 의존성이 생긴다는 것입니다. 저번에 예시를 들었던, 쿠팡알바를 생각해보면, 포장이 끝나기 전에 상하차를 진행할 수 없고, 집품이 끝나기 전에 포장할 수 없다는 것을 생각해보면 잘 와닿습니다.
의존성이 생긴다는 것은 알겠는데, 이걸 구체화 시켜야 문제를 해결할 수 있습니다. 구체화 시켜봅시다.
Read After Write Hazard(Dependency)
아래의 간단한 명령어를 가지고 예시를 들어봅시다.CPU에서 일상적으로 일어날 것 같은 A라는 주소에서 R1으로 Load한 다음, R1+R2 를 R3에 저장하는 명령입니다.
I1 : LD R1 <-A
I2 : ADD R3 R1,R2
위에서 어떤 문제점이 생길 수 있을까요 ? 언뜻보면 이게 뭔 문제임? 문제를 위한 문제인가요 ?프로 불편러? 라고 할 수 있지만 자세히보시면, 파이프라이닝시 문제점이 있을 수 있습니다. 그림으로 보면 바로 이해가 갑니다.
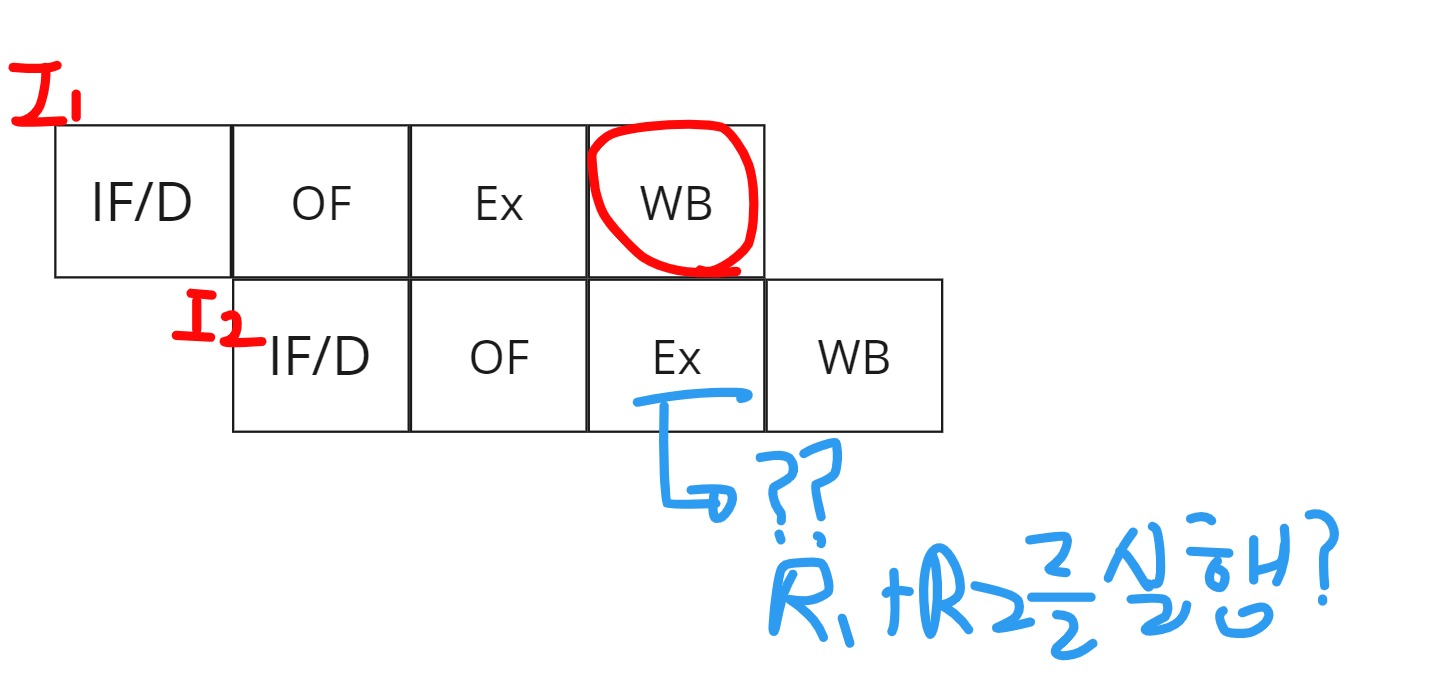
Instruction은 순차적으로 실행된다는 것에는 변함이 없습니다. 그리고, 4stage 파이프라이닝이라고 할 때, 위와 같은 그림으로 우리는 처리되기를 바랍니다. 하지만, I1에서 R1에 데이터가 저장되는 시점을 잘 봐야합니다.
I1에서 연산이 끝나고, R1에 저장되는 시점에 I2는 벌써 Execute 즉 R1+R2를 실행한다.
즉, 저장되지도 않았는데 미리 계산을 하는 이상한 짓을 할 수 있다는 것입니다. 이러한 현상을 Read After Write Hazard(Dependency)라고 합니다. 그리고, 이건 Instruction 자체가 순차적으로 실행되는 현대의 프로그램에서는 어쩔 수 없이 일어나는 Dependency라고 해서 True Dedependcy라고도 합니다.
컴공과들을 위한 꿀팁
제가 컴구 시험을 칠 때 사용했던 방법입니다. 의미를 물어보고 이해를 위한 공부라면 위까지만 해도 충분합니다. 하지만, 시험 문제에서 Instruction들이 쭉 나열되어있을 때, RAW를 찾아라 했을 때 찾다보면 생각보다 중간중간 빠뜨리기 쉽습니다.
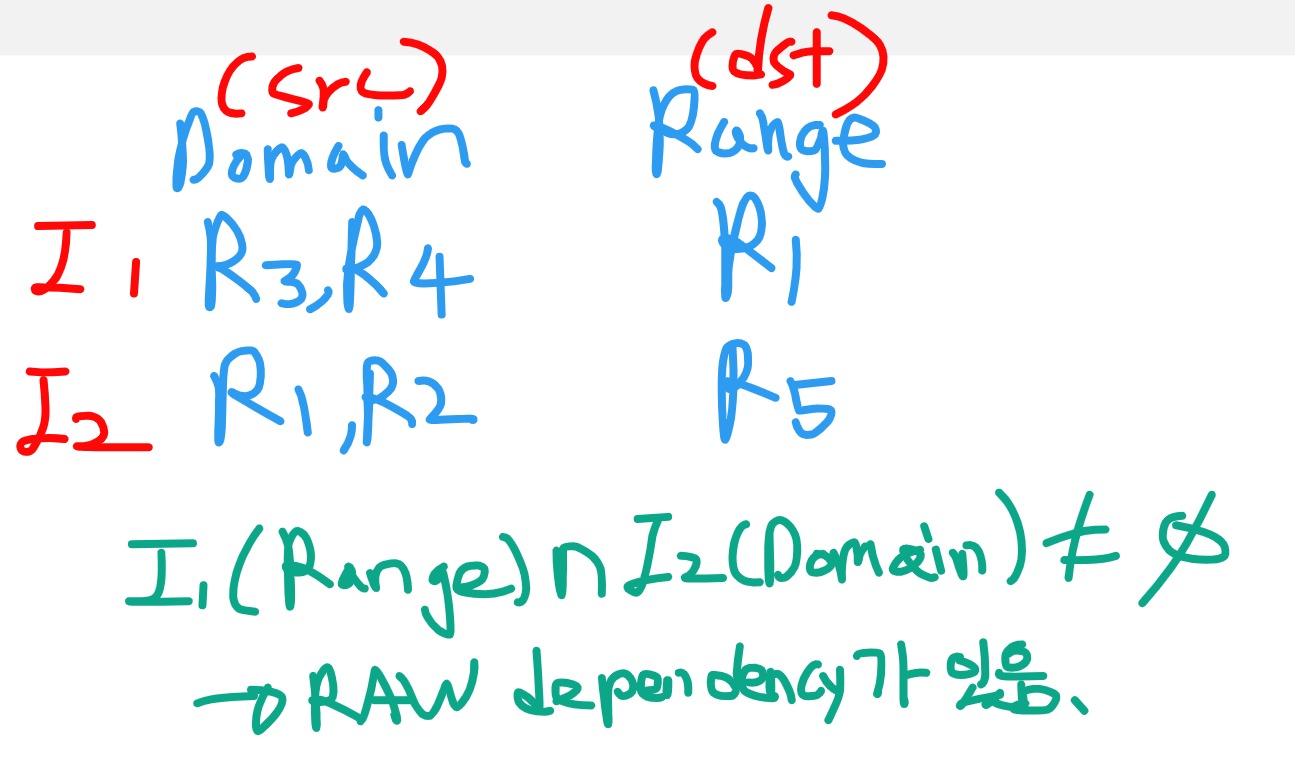
이럴때는 Domain(연산하는 곳)과 Range(저장하는 곳)으로 나누어서 생각한 뒤, 집합개념을 응용하면 쉽게 Dependency가 있는지 없는지 찾아낼 수 있습니다. 아래예시를 봅시다.
I1 : ADD R1 R3,R4
I2 : SUB R5 R1,R2 I1을 분석했을 때 Domain(Src)하는 연산하는 곳을 적어보면 R3,R4이고 Range(dst) 는 R1입니다. 마찬가지로 I2는 R1,R2 , Range는 R5입니다. 이때, I1의 Range 즉, I1이 저장하는 장소가 I2에 연산하는 곳에 또 사용되면 RAW Hazard가 생기는 것이기 때문에 교집합이 공집합이 아니면 RAW hazard가 있다고 할 수 있습니다. 말을 그대로 수학기호로 옮겼을 뿐이지만, 이렇게하면 더 꼼꼼하게 찾을 수 있다는 장점이 있습니다.
한줄요약
I1(Range) n I2(Domain) != 0 일 때, RAw Dependency를 의심해봐라.
RAW 해결하기 - Stall(pipelining interlock)과 Data Fowarding(Data Bypass)
Stall(pipelining Interlock)
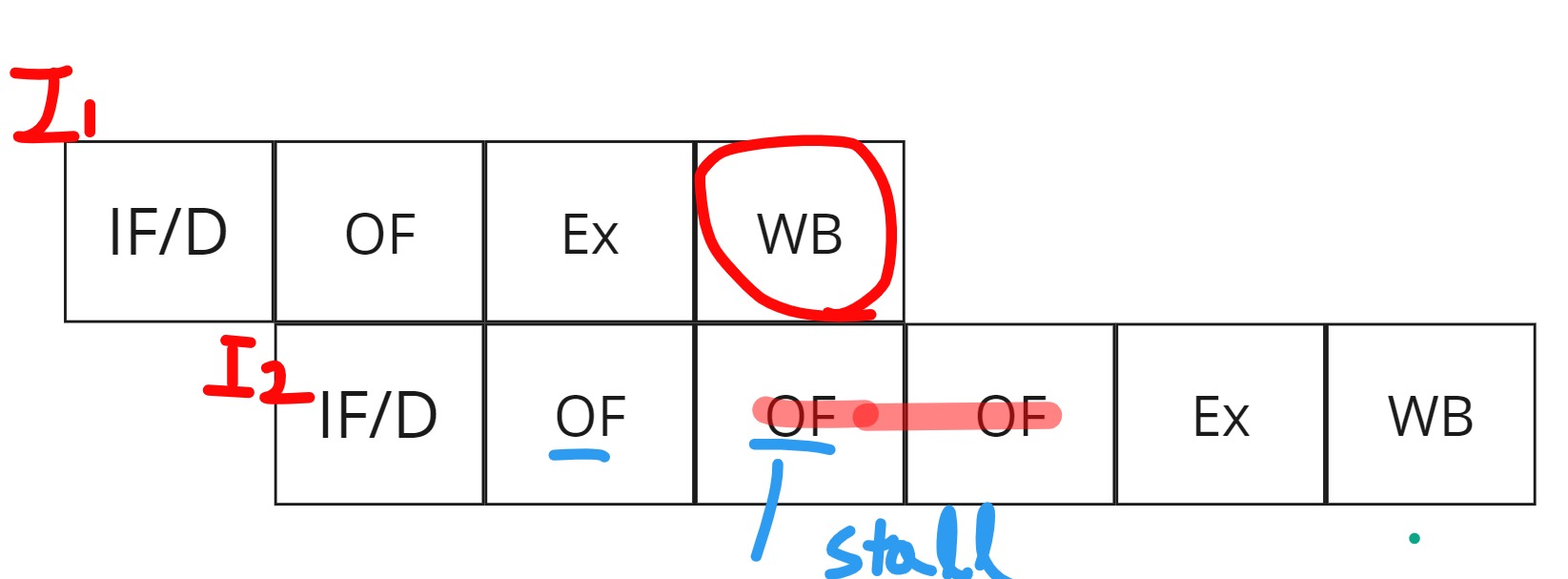
RAW를 어떻게 해결할 수 있을까요? 간단한 해결법은 기다리면 됩니다. I1이 끝날때까지 잠시 연산을 지연시키면 됩니다. 그림으로 보면 이해가 쉽습니다. 지연시킨다는 현상을 가리켜서 stall이라고 부르기도하고, 결국은 pipelining을 잠시 잠구는거니까 interlock이라고 하기도 합니다.
Stall로는 뭔가..애매하다.
I1에서 저장이 끝나고, 다시 저장된게 확인되면 그뒤로 쭉 Execute - WB을 이어나가면 됩니다.
예시로 제시한게 Instruction이 2개여서 stall이 별거 아닌것 처럼 느껴집니다. 하지만, 실제로는 Instruction이 여러개가 되고 의존성이 겹치면 Stall로 인한 Stall이 연쇄적으로 생기고,결과적으로 Pipelining을 쓰나마나한 효과가 나오게 됩니다. 그래서 나오게 된게 Data Fowarding입니다.
Data Fowarding
stall이 생기는건 어쩔 수 없습니다. 하지만, Stall을 최대한 줄일 수 있는 방법이 없을까 생각을 하다가 우리 컴공박사님,교수님들께서 생각해내신 아이디어 입니다.
잠깐, WB다음 OF->OF->Ex->WB이거 좀 불편하지 않아? 연산결과를 바로 I2에 던져주면 안될까?

그림으로 봐도 알겠지만, I2 : SUB R5 R1,R2 에서 R1에 저장되어있는걸 확인하는것도 1클락 걸리고 I2는 결국 OF단계에서 계속 기다리다가 또 OF를 실행해야한다. 이러지말고 ALU의 연산결과를 바로 다음 명령어로 던져주자.라는 아이디어에서 시작되었습니다. 정리하면 필요한 데이터를 Foward(앞서서)주자라는 개념에서 Data ByPass, Data Fowarding이렇게 부릅니다.
한줄요약
Data Forwarding은 파이프라아닝에서 연산의 결과를 다음 Execute Stage로 바로 던져주자는 아이디어이다.
Fowarding을 위한 돈이 더 크지않을까요? NO!
이렇게되면 ALU,FPU와 같은 Functional Unit들간에 ByPass선을 추가로 연결시켜줘야합니다. 하지만, 연산유닛들에게만이라도 ByPass를 뚫어놓고 자주쓰는 레지스터들끼리 ByPass를 뚫어놓음으로써 1클락이라도 줄일 수 있는게 더 이득입니다. 여기서부턴 증명이되었기 때문에, 이렇게 설계가 되었습니다.
그럼 DataForwarding만 쓰면 되는거 아닌가요? NO!
2클락동안 지연되는 연산이 있을 수 있습니다. 그리고, 위의 예시는 2개의 명령어의 예시만 들어서 딱 깔끔하게 떨어지지만, Stall로 인해서 또 stall이 연쇄적으로 일어난 명령어들은 어쩔 수 없이 기다려야하는 상황이 있습니다. 그리고, Load and use Hazard는 Load와 같은 연산은 진짜 Load가 된 후에 해당 레지스터를 사용을 꼭 해야하므로, ALU와 같은 연산장치에서 처럼 바로 Forwarding을 할 수 없습니다. 따라서, stall과 Forwarding을 같이 사용하게 됩니다.
세줄요약
파이프라이닝 시 Data를 저장하기 전에 읽는 RAW Hazard현상이 일어날 수 있다.
RAW를 해결하기 위해서 연산을 지연시켰다.
지연시켰을 때의 리스크를 줄이기 위해 연산결과를 바로 사용하기로 했다.
WAW,WAR Hazard는 OutofOrder Pipelining을 설명한 이후에 해야해서, 글을 한번 끊고 가는게 좋을 것 같다. 다음 글의 주제는 OutofOrder Pipelining이 뭔지, 왜 더 좋은지 , 왜 생겼는지와 거기에 따른 Hazard 2개를 이어서 보면 더 와닿을 것 같다. 그 이후에는 Struct Hazard와 Branch Hazard를 하고, BTB(Brach Target Buffer)에 관한 간단한 설명을 하고 Caching을 업로드할 예정이다.
