POCU와 OS공부를 하면서, 지방러로써 상경을 위한 준비를 하다보니 공부는 하는데 블로그를 쓸 시간이 없었습니다 ㅠㅠ 맘 같아선 진짜 집 통째로 옮기고 싶습니다.

CA는 듣고 싶었던 강의들은 모두 들었고, OS의 세마포어와 데드락에 대해서 공부하고 있습니다. 앞으로 쓸 글들이 많이 남았기 때문에, 캐시 메모리 빠르게 들어가볼까요! 캐시 메모리는 구조도 물론 중요하지만,캐시 전략과 캐시가 가능한 이유, CPU에서의 캐시의 역할에 더 집중하면 좋습니다.
캐시의 필요성
캐시의 필요성에 대해서는 저번 글에 간단하게 언급하고 넘어갔지만, 이번 글에서는 조금 더 전공자스럽게 말을 해봅시다.
Processor(CPU)는 아주 고급자원입니다. 무려, 1초에 수억번의 계산이 가능한 친구입니다. 하지만, CPU에서 RAM으로 접근하기 위해서 BUS를 이용하게 되는데, 이 BUS가 CPU에 비해서 매우 느릴 수 밖에 없습니다.
BUS를 통하지 않으면 안될까요?
- 렘의 모든 구역을 CPU와 연결을 하자는 좋은 접근입니다. 하지만, 16GB렘이라면, 2^34개의 메모리주소가 있을텐데, CPU는 한 개의 Processor가 한 개의 instruction을 처리합니다. 즉 , Processor와 메모리 사이에 2^34개의 핀이 필요합니다. 만들 수도 없고, 발열도 엄청날겁니다.
캐시는 결국 CPU가 메모리에 접근하는 속도는 CPU가 처리하는 속도에 비해, 매우 느리므로 CPU(Processor)안에 미리 가져와서 CPU(Processor)를 계속 바쁘게 돌리기 위한 기술입니다.
CPU를 혹사시킨다고 생각할 수 있지만, 기계일 뿐더러 현실에서도 자주 볼 수 있는 현상입니다. 대통령님,의사선생님들, 각종 회사의 CEO분들의 시간은 매우 값지므로 위와 같은 고급인력들은 한 시라도 idle(여유롭게) 두지 않는게 효율적입니다.
실제로, 현대의 CPU에서 RAM은 갈수록 멀어지고 cache들이 용량이 점점 커졌고, 계층적으로 설계하여 메인메모리에 접근하는 것 조차 거의하지 않습니다.
캐시의 크기
캐시의 구조를 들어가기 전에, 캐시는 메인메모리보다 전체용량이 작고, 속도는 빠른 SRAM구조로 되어있다. 하지만, 캐시 메모리는 기본 단위는 크다. 여기에는 2가지 이유가 있다.
- RAM에 접근하는 것 자체가 느린 작업이라 , 메모리를 한번 접근할 때 많이 들고오기 위함이다.
- 캐시가 가능한 이유가 지역성이 있기 때문인데, 메모리 접근은 하나의 메모리 주소 근방에서 일어나는 경우가 대부분이다. (배열, 반복문 등)

현실에서는 해외여행간다는 예시가 적절한 것 같다. 한번 오기가 쉽지 않으니까, 한번 갈때 잔뜩사서 캐리어에 꾹꾹 담아오기도 한다. 캐시도 똑같다고 생각하면 된다.
(곤약젤리 10봉지)
메모리는 기본 단위로 page를 쓰는데, 캐시 메모리는 그것보다는 큰 Block 혹은 chunk라고 불리는 단위를 쓴다. 보통 page가 4kb라면, chunk는 4page 정도, 혹은 8page정도 되는 큰 값들을 cache에서 하나의 단위로 쓰게 된다.
캐시의 구조
Fully associative cache
메모리의 모든 주소가 캐시의 블락 빈 곳 아무대나 대응이 될 수 있도록 만든 구조이다. 가장 직관적인 방법이다. 캐시의 크기만큼 비교기가 필요해서 , 비싼 방법이지만 속도가 그만큼 빠르다.
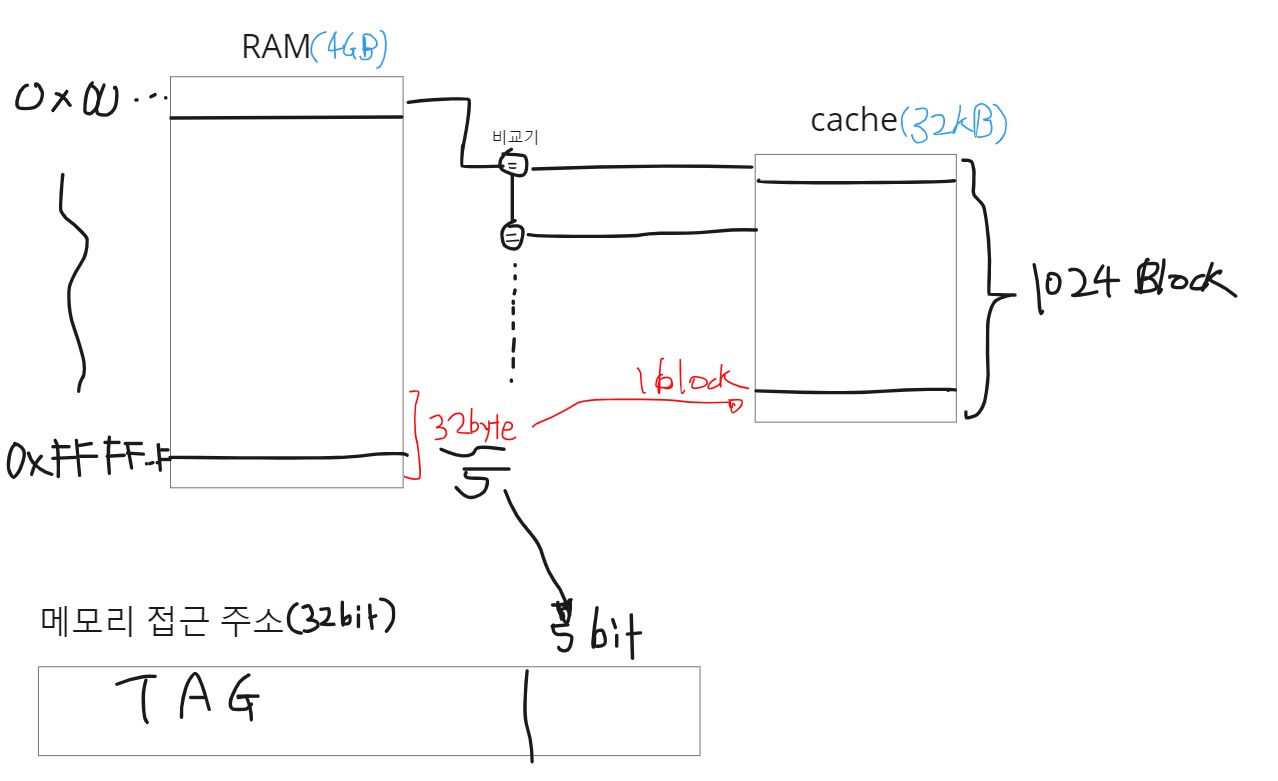
- 속도가 매우 빠르게 요구되거나, 용량이 작아서 비교기 갯수가 감당할만한 사이즈면 위와 같은 구조로 만든다.
- 캐시의 크기만큼 비교기가 필요하다는 말은, 그만큼의 핀도 필요하다는 거라서 매우 비싸다.
direct mapped cache
비교기를 줄이기 위해서, 메모리 구역마다 cache의 block에 대응되는걸 고정시키도록 만든게 direct mapped 캐시이다. 위의 그림의 캐시를 예시로 들자면, 1024개의 block이 있기 때문에, Index bit로 10개를 쓰도록해서, 캐시 1개의 block이 여러 개의 메모리 세그먼트에 대응되도록 만든 방법이다.
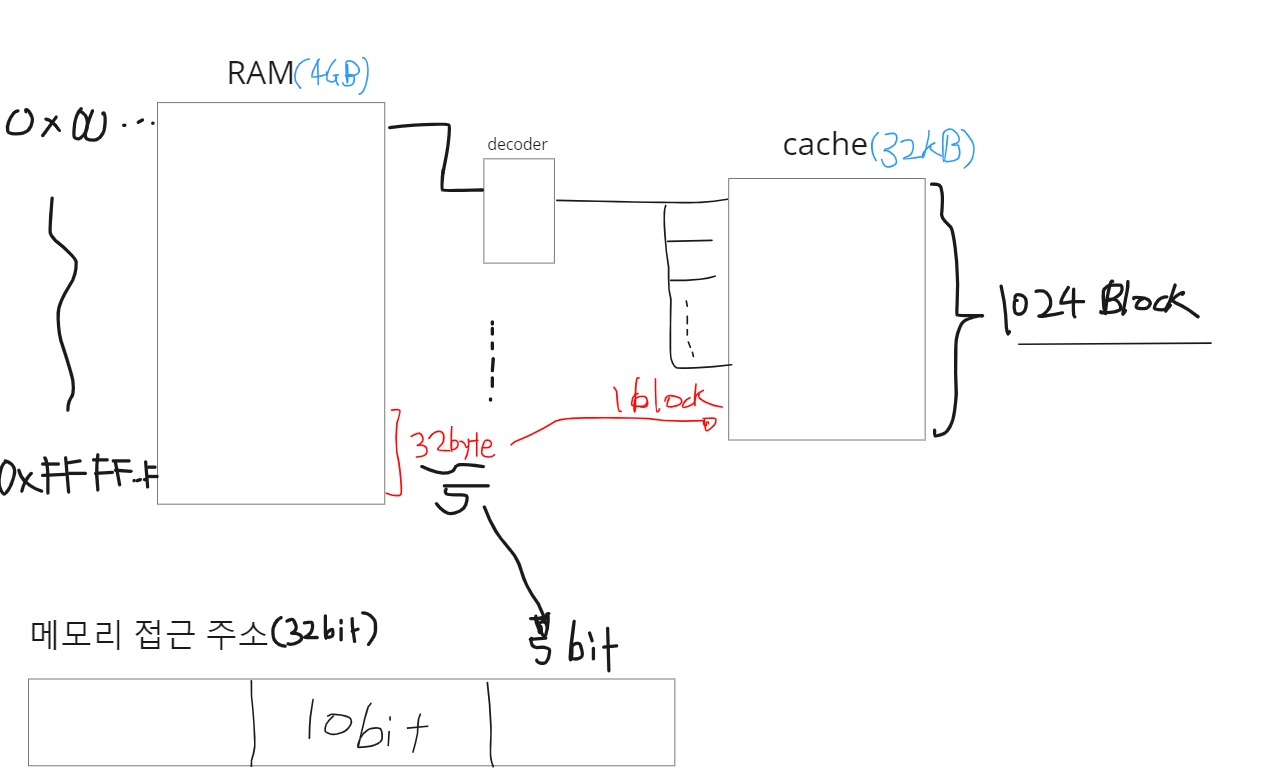
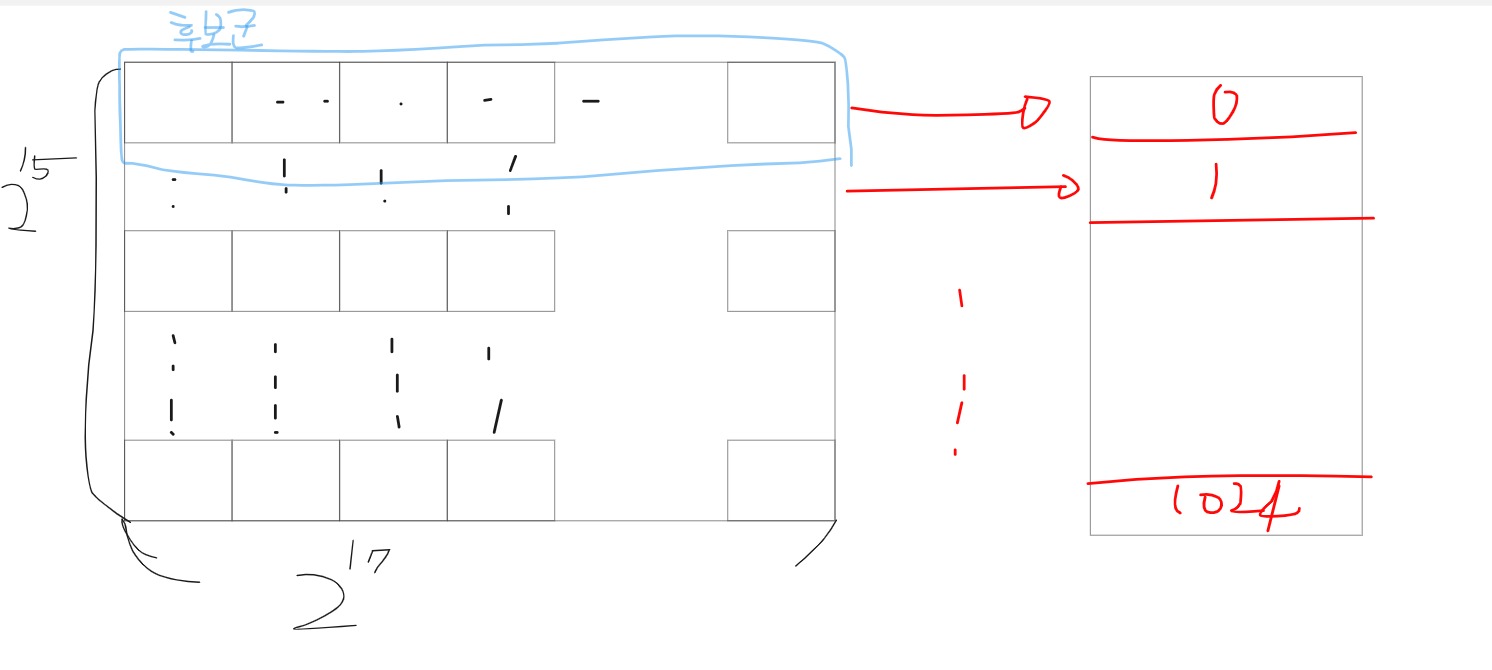
여러 개의 메모리 세그먼트가 1개의 block에 대응되기 때문에, 히트율이 떨어진다. Tag비트로 구별한다해도, 교체가 매우 잦게 된다. 이것도 , 그림으로 나타내면 이해가 쉬운데,4GB(2^32)으로 일렬로 쫙 나열되있는 직선을 32KB(2^15)개의 크기의 방 앞에 줄을 세운다고 생각하면 , 가로길이의 후보군이 얼마인지 대충 각이 나온다.
가로길이만큼이 모두 같은 후보군 취급을 받기 때문에, tag로 구분을 한다고 해도, 교체가 잦게 일어나게 된다.
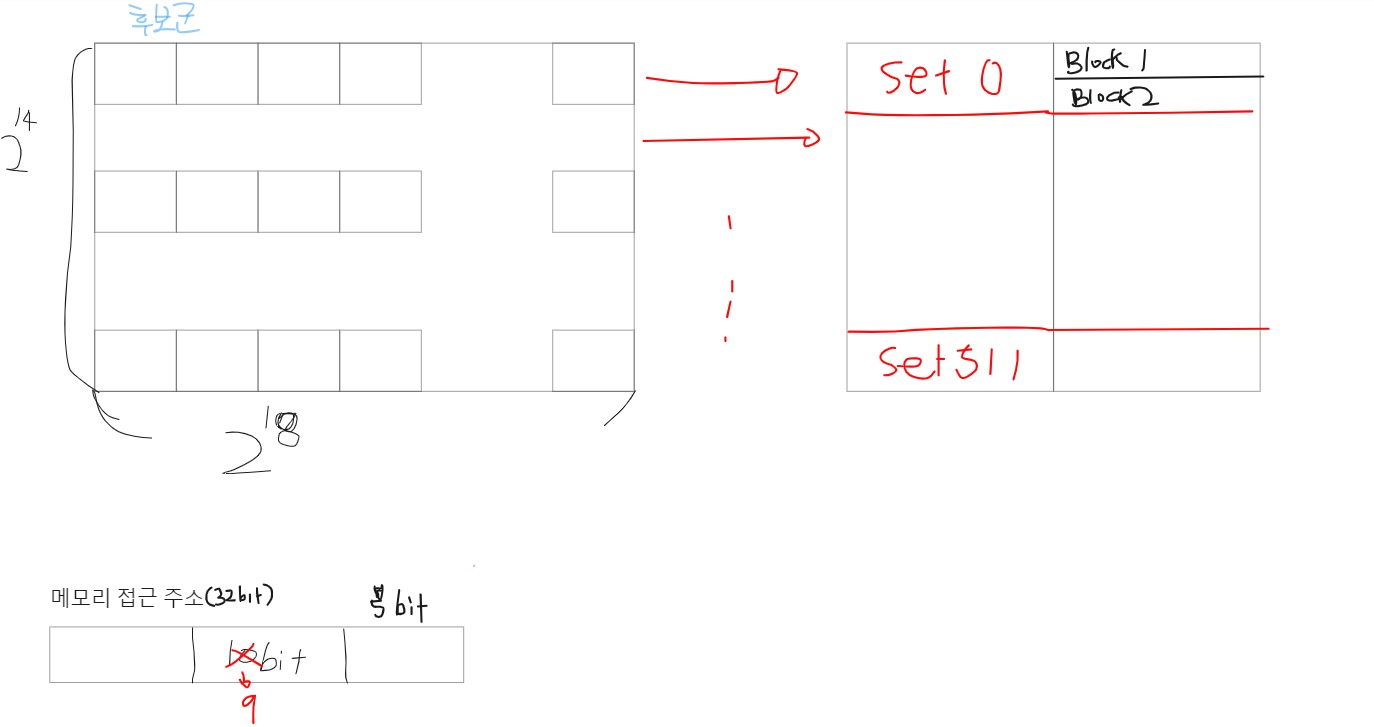
set(n-way)-associative cache
너무 잦은 교체가 문제인 점을 고친 캐시 구조이다. 잦은 교체의 이유는 1개의 block에 메모리 세그멘트 1개가 대응됬기 때문이다. 즉, 후보군이 많은데 , 1개의 후보군 밖에 집어넣지 못해서 그렇다. 메모리 맵을 바꾸지 않는 선에서 후보군을 많이 넣는 방법은 , 2개를 1개처럼 생각하면 된다. 즉, 1:1 대응에서 2:1 대응이나, 3:1 대응처럼 바꿔주면된다.
이게 set ,집합의 개념과 똑같기 때문에 1개의 세트안에 2개의 공간을 넣어주면 2-way-set, 3개의 공간을 넣어주면 3-way-set으로 생각하면 된다. 이렇게되면, 1개의 set에 대응되는 메모리범위는 커질수 있어도 안에 남아있는 메모리가 있기 때문에 잦은 교체 문제는 줄어들게 된다.
현대 CPU에 적용되는 캐시구조의 기반이 되는 구조이다. 기반이 되는 구조라고 말하는 이유는 여기서 더 발전시켜서, 적용시킨 부분이 있기 때문이다. 그걸 이해하려면 필요한 전문적인 지식들이 많고, 제가 이해하는 것도 정확한지 반증을 할 수 없어 링크정도만 남기고 넘어가겠습니다.
스택오버플로 - which cache mapping technique is used in intel core i7 processor?
cache는 현재까지도 발전되고 있고, 현대 CPU들은 사실상 cache가 cpu의 성능을 좌우한다고 합니다.
캐시 미스(Miss)
어쩌면 캐시 미스가 나는 것 자체는 당연합니다. 왜 미스를 따로 챕터를 나눴냐고 할 수 있습니다. 하지만, 캐시미스에서 우리가 얻어가야하는 것은 미스가 아니라, 미스가 되었을 때, 어떻게 교체시간을 줄일 수 있고, 계층적인 캐시 구조가 왜 장점을 가지게 되는지가 여기서 증명되기 때문입니다.
캐시 미스와 계층적인 캐시 구조의 장점
AMAT(Average Memory Access Time) = Hit Time + Miss_Rate * MissPenalty
프로세서에서 메모리를 접근하는 시간은 위와 같은 식을 통해서 측정하게 됩니다. 한국어로 풀어서 보면 더 확 와닿습니다.
- 한 번 Hit했을 때의 시간 + 미스할 확률 * 미스했을 때, 걸리는 시간
여기서, 캐시가 계층적으로 이루어져 있으면 미스했을 때 걸리는 시간(Miss Penalty)에서 신기한 현상이 일어나게 됩니다.
L1,L2 캐시가 있다고 합시다.
- L1 캐시는 hit시간 1초, 히트율이 95%, 미스시 걸리는 시간이 10초라고 합시다.
- L2 캐시는 hit시간 1초, 히트율 99%, 미스시 걸리는 시간 5초라고 합시다.
L1만 있을 때, AMAT는 1 + 0.05 * 10 = **1.5초**
L1,L2가 있을 때 AMAT는 1 + 0.05 * (1 + 0.01*5) = 1 + (0.05 * 1.05) = 1 + 0.0525 = **1.0525초**
계층적으로 구성만 했을 뿐인데, 1.5가 1.0525초로 확 줄어들었다. 이게 얼마나 대단한건지 감이 오지 않을 수 있다.이럴 땐, 비율을 구해보면 된다. 1.5에 약 0.7을 곱해줘야 1.05가 된다. 즉, 단순히 계층적으로만 구성했을 뿐인데 70%나 성능이 향상된거다.
꿀팁) 비율이 헷갈리면, 비례식을 세워보자.
가끔, 1.5초에 비해 , 1.0525초가 얼마나 빨라졌는지 구해봐라고하면, 헷갈릴 때가 많다. 1.5/1.0525인지, 1.0525 /1.5인지 헷갈린다. 이럴 땐, 비율의 의미를 생각하면 된다. 비율은 어떤 것을 1로 두고 생각하겠다는 거다. 여기서는 1.5초를 1로 뒀을 때 1.0525의 비율을 구하는 거니까, 옆과 같이 비례식을 세우면 된다. 1.5 : 1.0525 = 1 : x => 1.0525 /1.5 이다.
캐시 전략
캐시전략은 캐시내부를 관리하는 방법이다. 캐시를 읽고, 쓰고, 교체하는데 어떤 전략을 사용하는지 보면, 나중에 Redis와 같은 DB가 왜 caching이라고 하는지 이해가 간다.
읽기(Read Policy)
Read Allocation을 무조건 한다. 메모리 공간을 읽게되면, 읽은 정보는 cache에 무조건 가져다 놓는다.
쓰기(Write Policy)
캐시의 쓰기 전략은 2가지가 있다. 캐시에 있는 데이터가 변경되었을 때, 어떻게 할것이냐는 질문에 대한 답이다.
Write through
- 우선, 캐시에다가 기록을 하고, 그 뒤에 있는 메모리(L2,L3,RAM)에도 업데이트를 해주는 전략이다.
- cache의 일관성을 지키기 위한 방법이지만, cache에 어떤 정보를 쓸 때마다 트래픽이 발생하므로, 캐시를 쓰는 의미가 많이 퇴색되어서 잘 쓰지 않는다.
Write back
- 현재 이용 중인 캐시에만 기록을 하는 전략이다.
- 나중에, 캐시가 hit되지 않아 교체가 될 때, 바로 뒤에 있는 메모리(L1이라면 L2, L2라면 L3 , L3라면 RAM)까지만 업데이트 해주는 방식이다.
- Cache coherence를 유지하기 힘들다. 따라서, cache coherence Engine이라는 별도의 장치를 둬서, 그기서 이런 일관성을 조절해주는 역할을 하게 된다.(Snooping Engine이라고한다.)
90년도 때(내가 태어나기도 전), BTB와 더불어 2개의 메인연구주제 중 하나였다고 한다.
교체(Replace Policy)
캐시가 가득 찼을 때, 어떻게 교체해줄 것이냐는 질문에 대한 답이다. 기본적으로 가장 안쓴걸 버리는 방식으로 교체를 한다. 그 외에는 랜덤으로 쫓아내는 방법도 있다.
LRU
- 미래에 무엇을 쓸 것인가를 예측하는 것은 불가능하다.
- TimeStamp를 찍거나, Global Search를 하는 것은 하드웨어에서 비용이 꽤 비싸다. 따라서, 보통 타이머를 정해놓고 주기적으로 초기화 시키는 방식으로 구현한다.
예를들어, 10초마다 특정 비트를 0으로 만들어놓은 뒤,그 비트가 10초내에 변경이 없다면 이건 지워도 무방할거라고 생각하고 지워버린다.
Random으로 쫓아내기
- 진짜 아무거나 쫓아낸다.
- 근데 ,사이즈가 굉장히 커지면 LRU나 Random이나 성능이 비슷하게 나오게 된다.
컴퓨터 시스템에 존재하는 다양한 캐시
캐시 시스템은 정말 다양하다. Control Hazard를 하면서 배웠던 BTB도 어떻게 보면 Branch를 예측하기 위해서 미리 기록을 해놓는 일종의 캐시이다. 그리고, VM(Virtual Memory) 이야기에 가게 되면 TLB도 보게 되는데 TLB도 캐시의 일종이다. 이 외에도 현대 CPU에는 계층적인 L1(i-cache , d-cache), L2 ,L3가 있다.
아마, 첫글에서 CPU 전체맵을 보여줄 때 L1,L2,L3가 나눠져있는 그림을 소개한적이 있다.
