Select,Update,Join,INSERT와 같이 Query문을 다루는건 Query 다루기에서 업로드할 생각입니다. 여기서는 MySQL의 내부동작과 DBMS가 어떤식으로 움직이는지에 대한 이해를 위한 공부를 한 기록입니다. 출처는 RealMySQL -1,2입니다.
DBMS
DBMS는 Database를 다루게 해주는 소프트웨어 입니다. 그리고, 애초에 DB라는 개념도 DBMS와 떨어져서 구현된 건 아니기 때문에, 흔히 DB라고 부르는 것들은 다 DBMS입니다. Oracle,MSSQL(SQL sever),MySQL,PostgreQL ...등
여기서 중요한건 소프트웨어라는 겁니다. 실질적으로 OS를 쓰지 않으면 컴퓨터를 사용하기 매우 힘들지만 , OS도 컴퓨터 자원을 효율적으로 다루기 위한 소프트웨어 일종이듯, DBMS도 DB를 다루기위한 특화된 Software라고 생각하면 됩니다.
MySQL
제가 필요하고 공부해야하는 부분은 RDB(관계형) 데이터베이스 입니다.
MSSQL,Oracle,PostgreQL,MySQL 등이 있지만 앞에 두 녀석들은 유료니까 제외하고, 코끼리 친구는 요즘 많이 쓰지만 자료가 많이 없고 MySQL(Community Edition)는 학습자료도 많고, 안정성도 검증되어서 많은 기업에서 쓰고 있기 때문에 선택했습니다.
MySQL구조
MySQL은 여러 언어들과 소통할 수 있는 프로그래밍 API 밑에, 내부적으로 아래와 같은 구조를 가진다.
MySQL Engine
- Query문을 해석하고, 최적화하여 실행하는 곳을 MySQL Engine이라고 한다. 각각의 역할에 따라
SQL Parser(해석),SQL Optimizer(최적화),SQL 실행기(실행)로 이루어져있다. - 하지만, DB 또한 컴퓨터 내부에 데이터의 형태로 저장이 되어야한다. 실제로 DB는 .db와 같은 확장자로 컴퓨터 내에 저장이 되어진다.
- 컴퓨터 내부 즉, 저장공간에 직접 데이터를 읽어오고, 쓰고, 수정하는 등의 역할을 하는 친구가 필요하다.
Storage Engine(Handler)
- 컴퓨터 내부 저장공간에 실행된 쿼리문에 맞게 데이터를 읽고,쓰고, 수정하는 등의 역할을 한다.
- MySQL에는 InnoDB,MyISAM 등의 Storage Engine과 함께 다양한 추가기능을 겸비한 Plugin이 있어 꽤 자유롭게 Storage Engine을 선택할 수 있다. (이게 MySQL의 가장 큰 장점이라고 한다. 다른 DB에 비해서 꽤나 독특한 구조라고 한다.)
- MySQL Engine과 Storage Engine을 굳이 나누지 않고 합쳐서 MySQL 서버, MySQL이라고 표현하기도 한다.
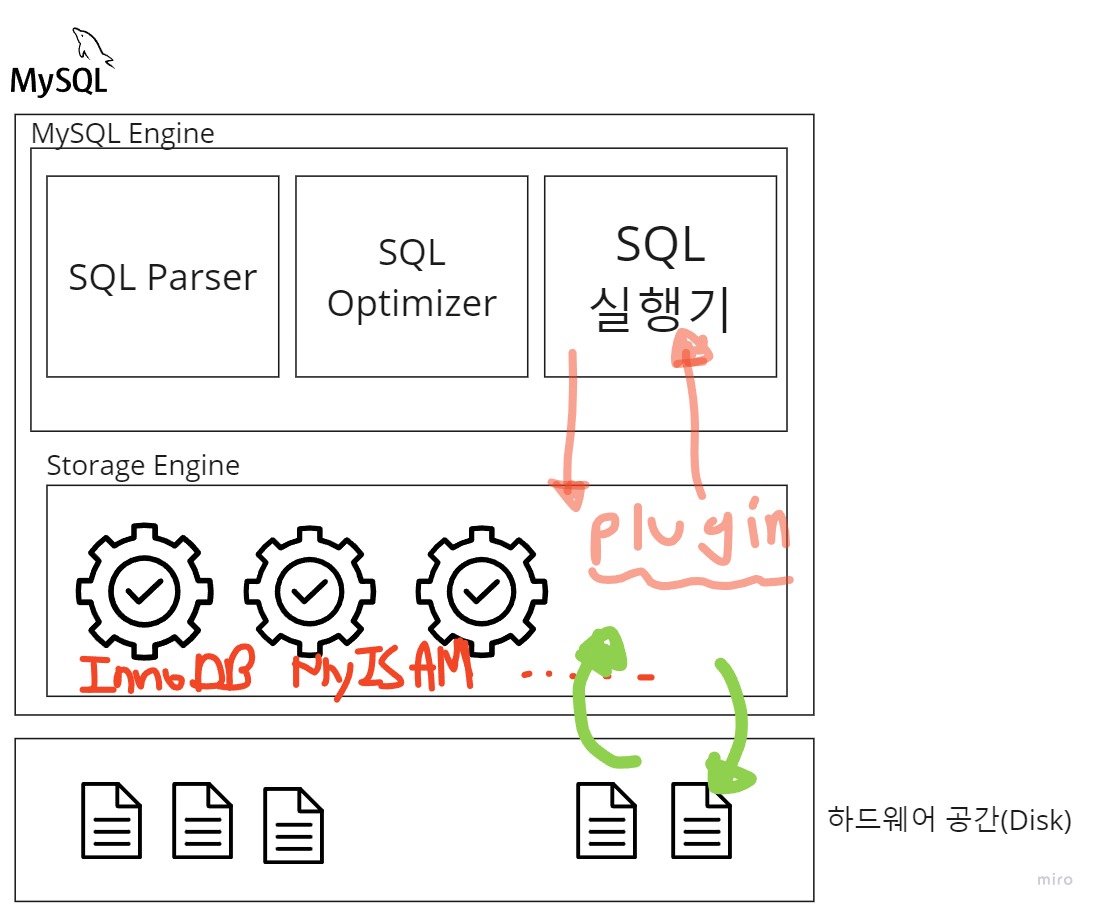
MySQL 엔진에서 해석된 쿼리문이 직접적으로 반영되는 과정은 InnoDB와 같은 Storage Engine이 담당하고 있으므로 , Storage Engine이 컴퓨터를 조작하는게 자동차를 직접 조종하는 Handle과 같은 역할을 한다고 해서 Handler(핸들러) 라고 부르기도 한다.
MySQL는 스레드 기반이다.
MySQL서버(Storage + Engine), 쉽게 이야기하면 MySQL이라는 소프트웨어는 스레드 기반 프로그램이다.. Query문을 요청하면, 그 처리를 하나의 스레드 단위로 만들어서 처리한다는 이야기이다.
Query문을 던졌을 때, MySQL에서 일어나는 시나리오
사용자(혹은, 프로그램)가 요청할 때, 기본적으로 1:1로 Foreground(fg)가 생성되며, fg 실행-> 캐시/버퍼 탐색 -> 없으면 , bg로 던지고(다른 작업과 동시에 수행) -> fg 캐시에 등록.(꽉찼다면, 종료) 그림으로 표현하자면, 아래와 같다.
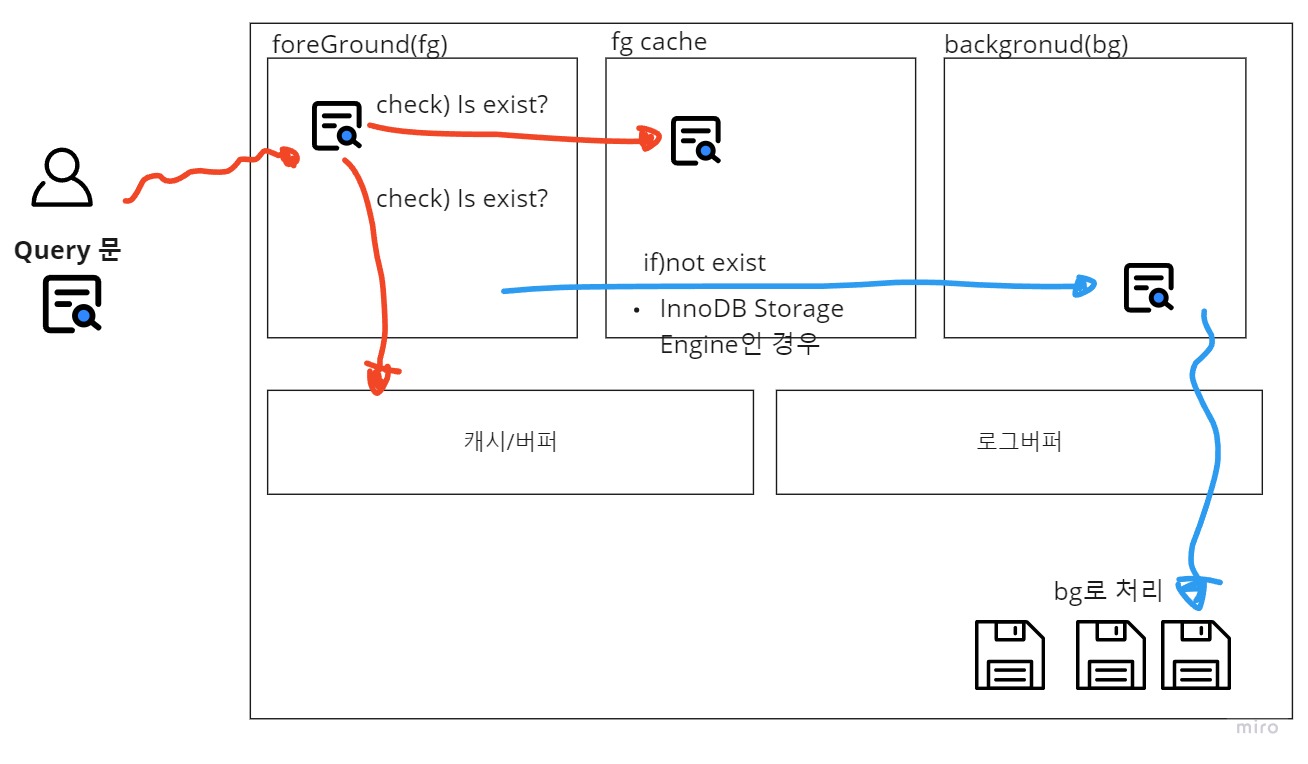
Foreground(fg) vs BackGround(bg)
포어 그라운드와 백 그라운드는 OS를 공부하신 분이라면 친숙한 개념일 것이다. 컴퓨터 사용성을 높이기 위해 만들어진 개념으로, Linux,Window와 같은 운영체제에서 단일 프로세서환경에서 다중 프로세스를 실행하기 위해 만들어진 개념이다. 쉽게 이야기하면, Shell에서 다중 프로세스를 구현하기 위해서 프로세스를 나눈 것이다.
더 설명하자면 ?
컴퓨터가 GUI가 없던시절 Console(shell)에서는 CLI로 한 가지의 커맨드를 입력하게 되는데, 출력값이 나올 때 까지 기다려야 했다.(foreground기준) 이때, Background로 프로세스를 실행하면, 출력값이 언제 나올지는 모르지만 실행하도록 시켜놓고 다른 명령어를 추가적으로 실행할 수 있다.(스케줄링함)
즉, InnoDB는 캐시/버퍼가 없다면 Background로 등록을 해놓고 또 다시 유저의 요청을 처리하여 반응성이 빠르고 동시성을 확보할 수 있다는 이야기랑 똑같다. 버퍼를 중간에 둬서 지연 쓰기를 하는것과 Background로 등록하는게 맞물려서 INSERT,UPDATE,DELETE와 같이 디스크에 필수적으로 접근해야하는 연산도 빠르게 수행할 수 있다고 한다. Read는 지연되면 안되기 때문에 바로바로 반응을 해주어야한다.
MySQL의 메모리공간
MySQL이 하나의 소프트웨어라면, 당연히 메모리공간을 OS로 부터 할당받게 될 것이다. 하지만, 이 할당받는 크기는 OS마다 다르고, 요청한만큼 다 메모리를 할당해줄 수도 있고 하지 않을 수 도 있다.(OS가 메모리를 관리 하기 때문에, OS가 판단하여 그때 그때 알아서 주기 때문)
하지만, 쉽게 생각해서 MySQL의 시스템 변수로 설정해둔 만큼 운영체제로 부터 메모리를 할당받는다고 러프하게 생각해도 무방하다고 한다.
각 Thread간에 공유하는 글로벌 메모리 영역, 각 thread가 갖는 메모리(세션,커넥션)영역이 있다.
성능은 결국 Storage Engine(Handler)와 Optimizer
MySQL 즉, DB를 잘 접근하게 만들고 데이터에 접근하는 시간을 줄이려면 구조상 결국 2가지를 신경써야하는 것 같다.
- Optimizer
- Storage Engine
Optimizer는 Query문을 최적화하는 과정이니까 당연히 잘 유도를 해서 성능을 최적화 시켜야할 것 같고, Storage Engine은 외부장치(I/O)로 접근하는거니까 당연히 리소스가 많이 들 수 밖에 없으니까 여기서 성능이 결정될 것 같다.
책에서도 하나의 쿼리작업은 여러 하위 작업으로 나뉘게 되는데, 각 하위 작업이 MySQL 엔진 영역에서 처리되는지 or 스토리지 엔진 영역에서 처리되는지 구분할줄 알아야한다라고 소개하고 있다.
데이터 읽기/쓰기는 Storage Engine이 , SQL문 처리 및 최적화는 MySQL Engine이 처리한다고 러프하게 일단 알고가면 될 것 같다.
Query 중간에 Cache를 두지않는 이유 ?
Redis가 Caching DB처럼 쓸 수 있는것처럼 똑같은 Query문이면 , 굳이 I/O장치를 찔렀다가 가야하냐?라는 의문이 생길 수 있다. 물론 , 이 기능은 웹같은 환경에서는 꽤 유용했기 때문에 MySQL 5.3까지는 쓰였다고 한다. 하지만, Insert/Update/Delete와 같이 data를 조작하는 연산이 일어난다면 Cache에 저장되어있는 데이터와 실제로 물리적인 Disk에 존재하는 Data 사이에 정합성이 깨질 수 있으므로, MySQL은 위의 연산이 일어나면 cache를 지우도록 해놓았다.
Read만 일어나는 웹 서비스라면 채용할만 하겠지만 Read만 일어나는 웹 서비스는 잘 없을 뿐더러, 중간에 Insert/Update/Delete 연산이 한번이라도 일어난다면, cache를 lock하기 때문에 배보다 배꼽이 더 큰 경우가 많았다고 한다. 그래서, MySQL 8.0부터는 아예 삭제한 기능이다.
공식문서에서 또한 아래와 같이 안내하고 있다.
"The query cache can be useful in an environment where you have tables that do not change very often and for which the server receives many identical queries."
Thread Pool
Community버전에는 지원을 하지않는 기능이지만, Percona Server의 스레드 풀 플러그인을 설치하면 쓸 수 있다고 한다. 하지만, Thread Pool의 개념은 CPU 갯수 만큼 보통 Pool을 지정해놓고, 그 이상의 Thread들이 생성되면 기다리게 하고 CPU가 쓰레드를 생성한 만큼 잘 처리할 수 있도록 사람이 유도해주는 방법이다. 하지만, 스케줄링 과정에서 CPU시간을 제대로 확보하지 못하거나,스레드 수가 많아져서 Contextswitching 비용이 더 들어가는 등의 부작용이 발생할 수 있기 때문에 사용시 주의를 해야하는 부분이다.
스레드 풀의 타이머 스레드가 주기적으로 스레드 그룹의 상태를 체크하여, Thread_pool_stall_limit 시스템 변수에 정의된 밀리초 만큼 작업 스레드가 처리 중인 작업을 끝내지 못하면, 새로운 스레드를 생성해서 스레드 그룹에 추가하도록 한다. 반응성이 민감한 프로그램이라면, thread_pool_stall_limit 동안 새로운 요청을 기다려야 하므로 , 적절하게 낮추는걸 추천한다고 한다.
(자세한건 뒷장에서 다룬다고 하니까, 그때가서 구체적으로 하자)
