요즘은 전공자가 아니더라도, 다들 한번 쯤 들어보셨을 단어 'DB'에 대해서 차근차근 정리를 해보려고 합니다!
제가 생각하기에 CS는 컴퓨터 네트워크 , OS , DB , 알고리즘 및 자료구조 4개가 정수의 영역인 것 같습니다. 다른분야는 응용에 가깝고, 저 네 명의 친구는 순수학문의 느낌입니다.(개인적인 생각입니다)

DB에 대해서 깊게 들어가면 매우매우 어려운 영역입니다. 그러므로, DB를 학문적으로나, 연구하듯이 적을 능력도,시간도 없기 때문에 개발자의 영역에서 DB를 잘 이해하고, 잘 다루는것을 목표로 두려고 합니다.
제가 지금 생각하고 있는 것들은 DB 설계(정규화,1:N,N:M 관계) ,SQL(DML,DDL,DCL,JOIN) ,MySQL 3개 입니다. 여기에 추가로, Indexing과 MySQL DB의 내부동작을 살짝살짝 뿌리는 형식으로 해보려고 합니다. 물론, 공부해나가면서 필요한 내용이 있다면 무적권 추가할 예정입니다.
Data
데이터의 사전적 적의는 아래와 같다고 합니다.
- 어떤 분야에서 기초가 되는 사실,혹은 바탕이 되는 것
- 컴퓨터가 처리할 수 있는 문자, 숫자
역시 사전적 정의는 항상 추상적일 수 밖에 없어서 예시와 함께 기억을 해야합니다. 예를들어, 은행에 가서 업무를 보는데 Shark 본임임을 증명하는 상황입니다. 보통, 신분증을 보여달라고 합니다. 하지만, 신분증이 어떻게 shark를 증명하게 될까요 ?

성별,출생연월,거주지,주민등록번호 ...등과 같은 사실들이 sharkkk를 증명하게 됩니다. 위와 같은 성별 ,출생일 , 거주지 ,주민등록번호가 Data가 되는겁니다.
컴퓨터에서는 간단하게, 컴퓨터가 처리하는 문자, 숫자, 각종 자료들을 모두 데이터라고 생각하면 됩니다.
Data로 할 수 있는 작업
Data는 기본적으로 쓰기(Write/Create) , 읽기(Read) , 수정(Update), 삭제(Delete) 4가지 행동으로 정의가 됩니다. 물론 현실에서는 수정도 못하고, 삭제도 못하는 데이터가 존재하긴 합니다만, 그런 데이터는 제외합시당!
예를들어,주문정보(배송지, 배송번호, 도착예정일..)라는 데이터가 있다고 합시다.
- 쓰기는
주문정보를 처음 만들어낼 때의 작업이쓰기입니다. - 읽기는 배달기사님이 배달을 위해서
주문정보를 보는 것을읽기(Read)라고 할 수 있습니다. 그래서, Read를 "조회한다"고도 많이 씁니다. - 수정은 배송지를 잘못입력했을 때,
배송정보를 고치는 것이 수정입니다. 즉, 정보의 내부가 일부 바뀌는걸 의미합니다. - 삭제는
주문을 취소하는 걸 삭제라고 볼 수 있습니다.
file -> DataBase(DBMS)
컴퓨터에서는 Data를 저장하기 위해서 File System이란 것을 씁니다. 파일은 친숙합니다. 당장 바탕화면에 가서 우클릭 한뒤, 메모장을 생성하면 파일 한 개를 생성한 겁니다. 파일은 매우 뛰어난 장점들을 많이 갖고있지만, 데이터를 가공하고,다루는 입장에서는 불편한 점이 생기게 됩니다.
예를들어, 대한민국 전국민 데이터가 파일로 이루어져 있다면, 어떻게 될까요? 사는 곳마다 폴더를 나누어서, 각각 txt 파일로 존재하게 되겠죠. 그럴 때, 이철수라는 사람의 이름이 이은수라는 이름으로 바뀌었다고 합시다. 이 정보가 파일로 존재하면 다 하나하나 뒤져가면서 '이철수'라는 이름을 '이은수'라고 바꾸어 주면됩니다. 일하는 분은 하루종일 문서실 안에서 자료만 찾을 겁니다.

그래서, Spread Sheet라는 개념이 등장하게 됩니다. Spread Sheet는 '표'로 데이터들을 쫙 나열해놓고, 안의 내부 데이터를 관리해보자! 라는 생각입니다. 엑셀이 Spread Sheet입니다. 그런데, Spread Sheet도 여러가지 문제점이 있습니다.
- 사용자가 1명 입니다.
- Spread Sheet는 누가 수정했는지 확인이 힘듭니다.
- Spread Sheet도 엄청 커지면 찾기 힘든건 똑같습니다.
- 중간에 중복된 데이터가 있거나, 사용자가 실수를 하면 '에러'가 아니라 그냥 그 값이 그대로 입력됩니다. 왜냐하면, 그게 옳은 정보인지 아닌지 모르니까요.
등 데이터의 복잡성과 관리에 여러가지 문제점을 느끼고, 해결한 것이 DataBase 입니다.
DBMS
DB는 파일로써 존재합니다. DBMS는 DB를 관리해주는 소프트웨어를 이야기합니다.(MySQL,Oracle,PostgreQL ...) 물론, 혼용해서 써도 아무런 문제 없습니다. DB는 일반적으로 DBMS를 이야기합니다.
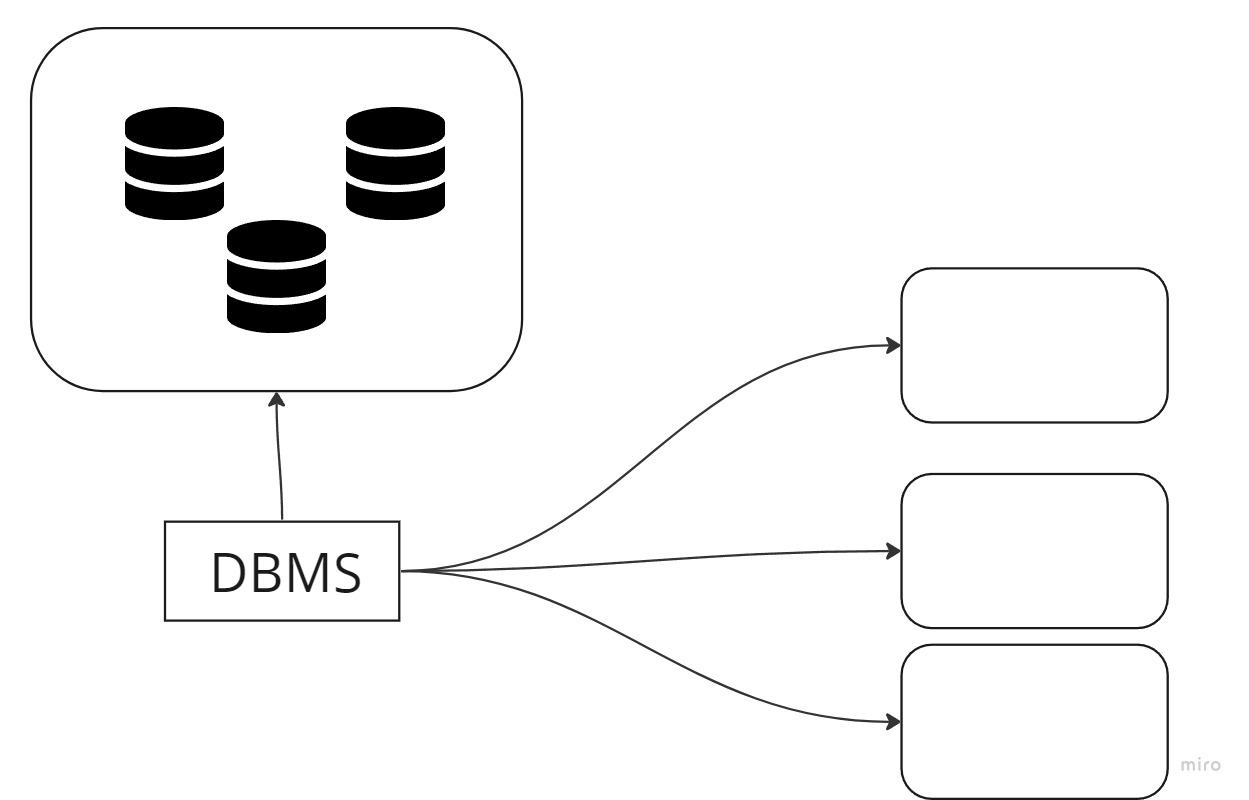
그렇다면, DB에서는 데이터를 어떻게 정의하고 있나요?
관계형 데이터베이스 , NoSQL, 그래프 데이터베이스 등 으로 나뉘게 됩니다.하지만 ,제일 많이 쓰고 흔히 DB라고만 하면 관계형(RDB)를 기본으로 이야기 합니다.
RDBMS는 2차원 테이블로 데이터를 저장하여 관리하게 됩니다. Spread Sheet의 발전버전이라고 볼 수 있죠! 테이블의 구조는 아래와 같습니다.
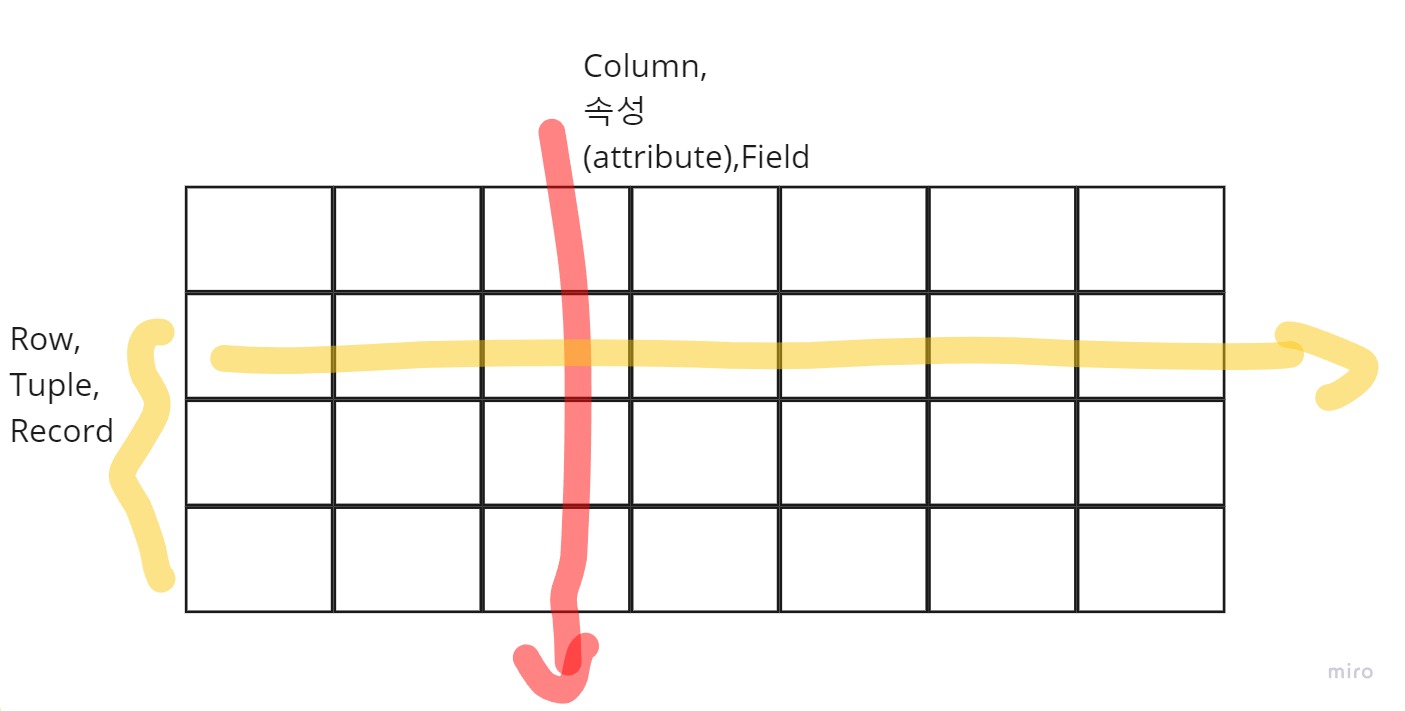
-
Column,attribute,Field : 열에 해당하는 값입니다. 주로, 자료의
속성들이 옵니다. 예를들어, 학생에 대한 데이터라면,학번,전화번호,이름등 이 있을 수 있습니다. 속성에 들어갈 수 있는건 원자성을 가진 친구만 들어갈 수 있습니다.(의미적으로 더 쪼개지지 않는 것) -
Row,Tuple,Record : 줄에 해당하는 값입니다. 자료 1개를 나타냅니다. 즉, 여러 개의 column이 하나의 row를 나타내기 때문에, Row 1개는 1개의 데이터 입니다.
위의 구조로 .db라는 파일로 컴퓨터에 저장하고 있습니다.(DBMS도 소프트웨어이기 때문에, OS위에서 돌아야함) 그리고, 이런 테이블이 하나가 아니겠죠. 이제 이 테이블들 끼리 연관시키기도 하고, 어떻게 자료를 잘 보관할 수 있는지 등에 대해서 다루어 볼겁니다!
끗

