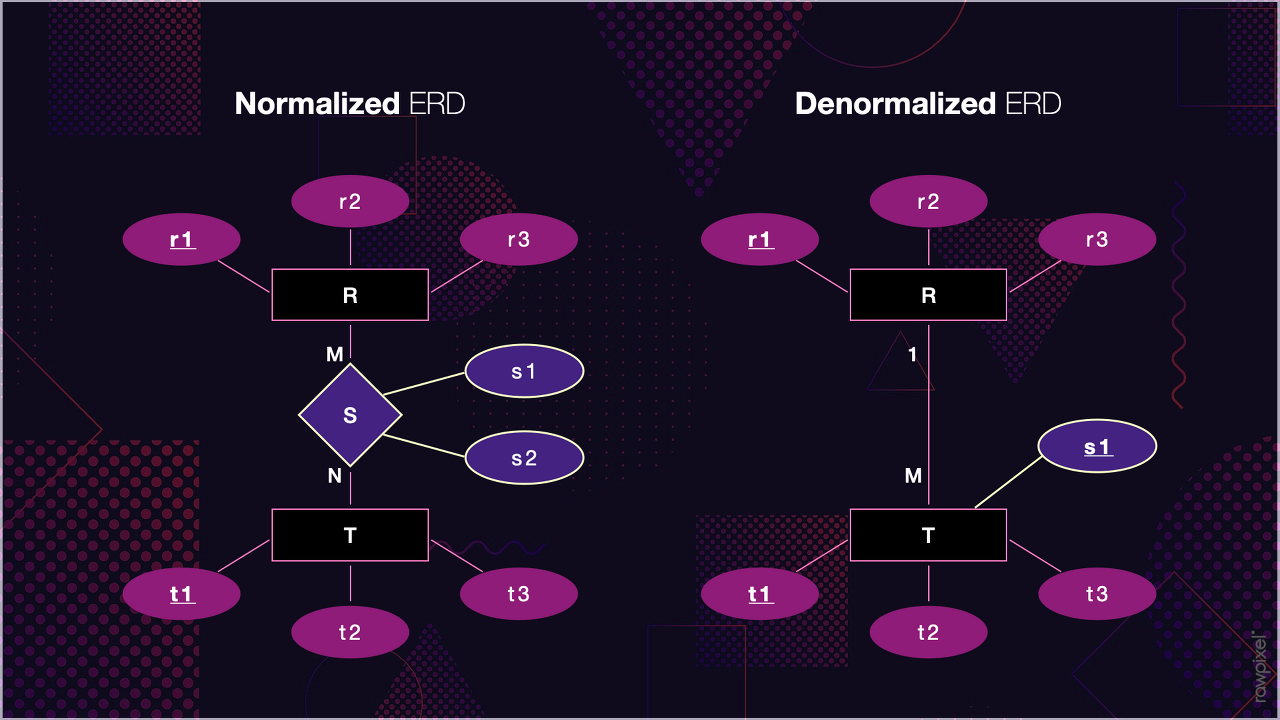
🎯 정규화
정규화 데이터베이스는 중복을 최소화하기 위해 데이터를 구조화하는 작업이다. 좀 더 구체적으로는 하나의 종속성이 하나의 릴레이션에 표현될 수 있도록 분해해가는 과정이라 할 수 있다.
정규화의 원칙
-
하나의 스키마를 다른 스키마로 변환할 때 정보의 손실이 있어서는 안 된다. (정보의 무손실 표현)
-
하나의 독립된 관계성은 하나의 독립된 릴레이션으로 분리시켜 표현해야 한다. (분리의 원칙)
-
데이터의 중복성이 감소되어야 한다.
장점
-
데이터베이스 변경 시 이상 현상 제거
-
저장 공간의 최소화 가능
-
효과적인 검색 알고리즘 생성 가능
-
데이터 삽입 시 릴레이션 재구성의 필요성 감소
-
데이터 구조의 안전성 및 무결성 유지
단점
-
릴레이션 간의 JOIN 연산 증가
-> 이로 인한 질의에 대한 응답 시간 저하
🎯 비정규화
비정규화 데이터베이스는 하나 이상의 테이블에 데이터를 중복해 배치하는 최적화 기법이다.
비정규화를 사용하는 대상
-
자주 사용되는 테이블에 액세스하는 프로세스의 수가 가장 많고, 항상 일정한 범위만을 조회하는 경우
-
테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우
-
테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
주의점
-
반정규화를 과도하게 적용하다 보면 데이터의 무결성이 깨질 수 있다.
-
입력 수정 삭제의 질의문에 대한 응답 시간이 늦어질 수 있다.
이상현상
-
삽입 이상
- 원하지 않는 자료가 삽입되거나, 삽입하는데 자료가 부족해 삽입이 되지 않아 발생하는 문제
-
삭제 이상
- 하나의 자료만 삭제하고 싶지만, 그 자료가 포함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제
-
갱신 이상
- 정확하지 않거나 일부의 튜플만 갱신되어 정보가 모호해지거나 일관성이 없어져 정확한 정보 파악이 되지 않는 문제

Junior-Backend-Developer