컴퓨터공학
1.[컴퓨터공학] 컴퓨터 시스템 및 구성 요소 + 논리회로
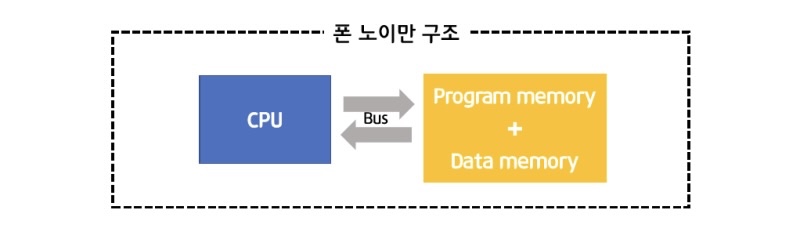
컴퓨터 시스템은 운영체체 혹은 응용 프로그램인 소프트웨어와 CPU, Memory, Storage, Network등의 하드웨어의 융합이다.현재 대부분의 컴퓨터의 구조이다. Memory에 프로그램과 데이터가 저장되고, 하나씩 꺼내어 CPU로 연산하는 구조이다.기존 컴퓨터들
2.[컴퓨터구조] 디지털컴퓨터와 프로그래밍 이해
Instruction SetSoftware는 code와 데이터로 이루어져 있다.Software Engineer : code를 작성하느 사람Machine language : CPU는 Instruction code를 만들어 놓고 제공한다.컴파일 : 프로그래밍 언어로 작성된
3.[운영체제] 운영체제의 역할과 구조

OS -> Operating System일반적으로 커널에 여러가지를 추가한 상태를 OS라고 통칭한다.But! OS는 더 정확하게 이야기하면 kernel이라고 할 수 있다.그러면 안드로이드는 OS일까?? X→ 안드로이드는 Linux 운영체제의 kernel을 사용하기 때
4.[운영체제] 프로세스와 스케쥴러

바이너리 형태의 실행가능 목적파일(실행 파일)로 메모리에 적재되어 실행 중인 프로그램을 프로세스라고 한다. 응용 프로그램은 하나 이상의 프로세스로 이루어져있다. \->하나의 응용 프로그램이 여러 프로세스들과 상호작용하면서 실행될 수도 있기 때문이다.프로세스와 프로그램의
5.[운영체제] 커널의 구성
하드웨어와 응용 프로그램 사이에서 인터페이스를 제공하여 응용 프로그램이 하드웨어에서부터 오는 자원을 관리하고 사용 할 수 있게 해주는 운영체제의 핵심 요소이다.커널의 핵심 기능은 컴퓨터에 속한 자원들에 대한 접근을 중재하는 기능이다.커널이 핵심 기능을 수행하는 일은 크
6.[컴퓨터구조] 컴퓨터의 구조
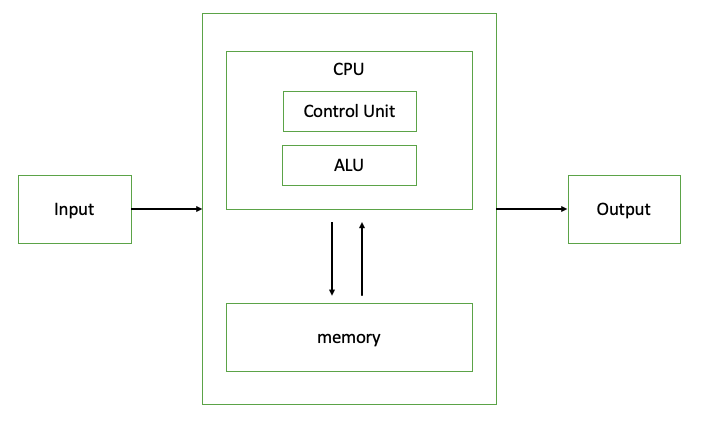
존 폰노이만이 제시한 컴퓨터 구조로 프로그램 내장 방식이라고도 불린다. 현대 컴퓨터 구조의 기반이 된 컴퓨터 구조로, CPU,메모리,프로그램 구조를 확립시켰다.산술 논리 장치와 프로세서 레지스터를 포함하는 처리 장치명령 레지스터와 프로그램 카운터를 포함하는 컨트롤 유닛
7.[컴퓨터구조] 레지스터의 역할과 종류
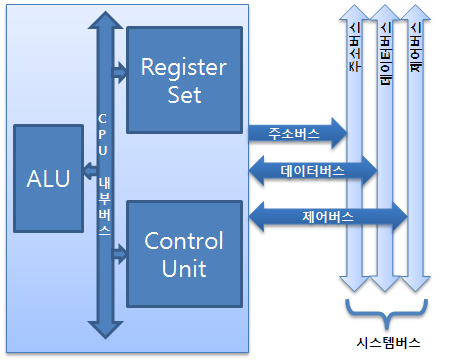
레지스터는 CPU가 요청을 처리하는데 필요한 데이터를 일시적으로 저장하는 다목적 공간이다.CPU 내부에 존재하며 연산제어 및 디버깅 목적으로 사용된다. 일시적 메모리 역할을 한다. CPU가 메모리에 데이터를 가져오게 되면 시간이 오래 소요 되지만, CPU 내부에 있는
8.[운영체제] 컴퓨터 성능 향상 기술
컴퓨터 성능의 저하를 유발하는 이유는 CPU와 메모리에서의 작업 속도일 것이다.CPU는 매우 빠른 속도로 작업을 수행하지만, Memory에서 데이터를 가져오게 되면 시간이 너무 많이 걸리기 때문에 성능이 저하된다.이런 문제들을 해결하기 위해 나온 기술들을 컴퓨터 성능
9.[운영체제] 프로세스와 스레드
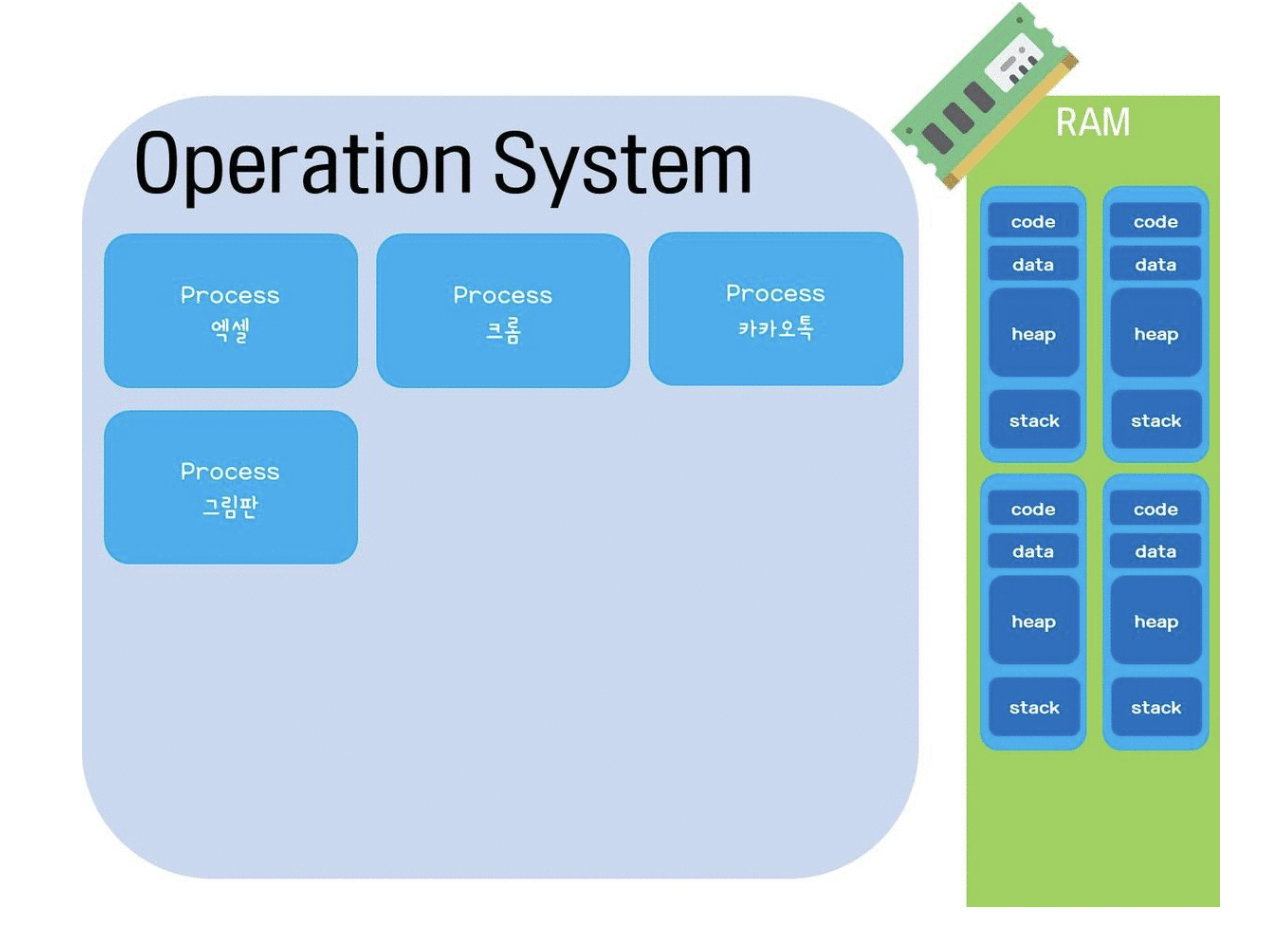
프로세스는 메모리에 적재되고 CPU 자원을 할당받아 프로그램이 실행되고 있는 상태를 의미한다.프로세스는 code, data heap, stack 영역으로 구분되어 있다.code : 프로그래머가 작성한 프로그램이 코드 영역에 작성된다.data : 코드가 실행되면서 사용한
10.[운영체제] PCB와 Context Switching
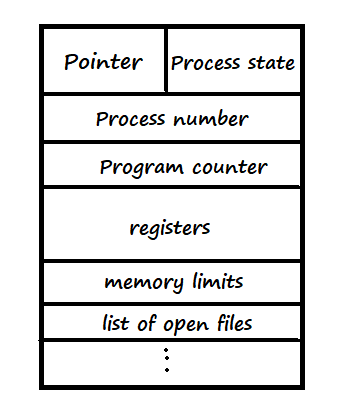
운영체제가 프로세스를 제어하기 위해 정보를 저장해 놓는 곳으로, 프로세스의 상태 정보를 저장하는 구조체이다.프로세스 상태 관리와 ContextSwitching(문맥교환)을 위해 필요하다.PCB는 프로세스 생성 시 만들어지며 주기억장치에 유지된다.프로세스 생성 단계 예시
11.[운영체제] 프로세스의 구조
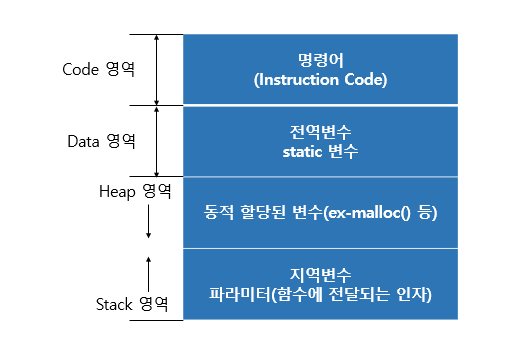
프로세스는 생성과 동시에 해당 4가지 메모리 영역을 가진다.code : 프로그램을 실행시키는 실행 파일 내의 명령어들이 위치하는 공간data : 전역변수나 static변수들이 들어가는 공간heap : 코드에서 동적으로 만들어지는 객체 또는 동적메모리의 공간stack :
12.[운영체제] 스케줄링
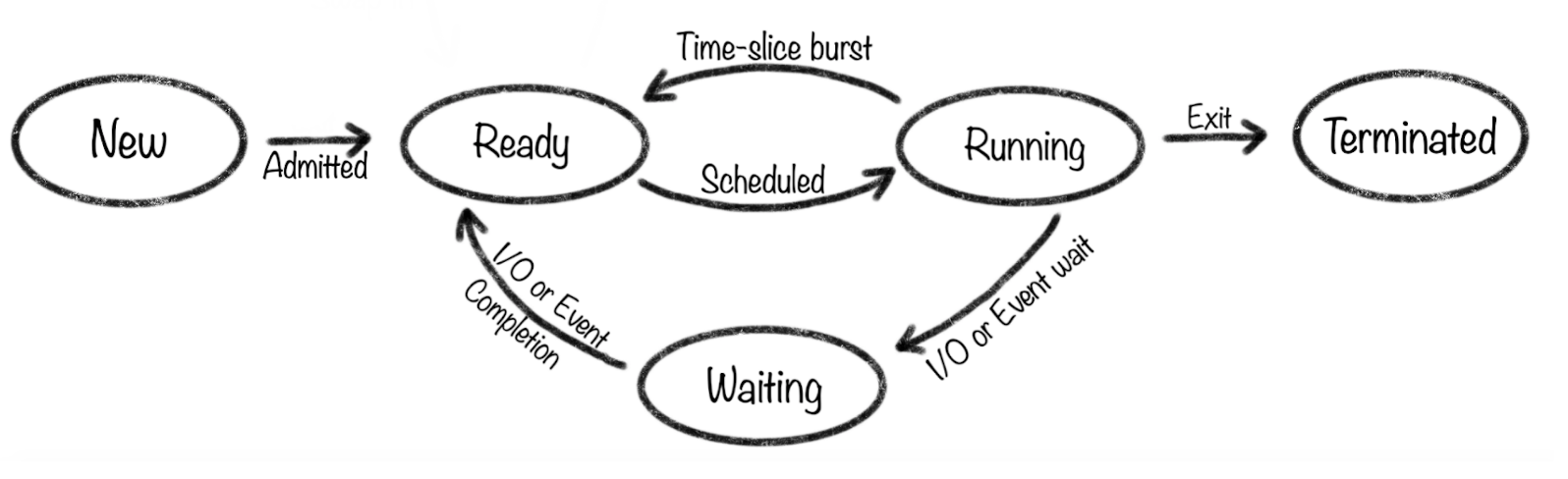
스케줄링은 다중 프로그래밍을 가능하게 하는 운영체제의 동작 기법이다.운영체제는 프로세스들에게 CPU등의 자원 배정을 적절히 함으로써 시스템의 성능을 개선할 수 있다.공정성 : 모든 프로세스에 공정하게 할당합니다.처리율(량)증가 : 단위 시간당 프로세스를 처리하는 비율(
13.[운영체제] 프로세스 간 통신
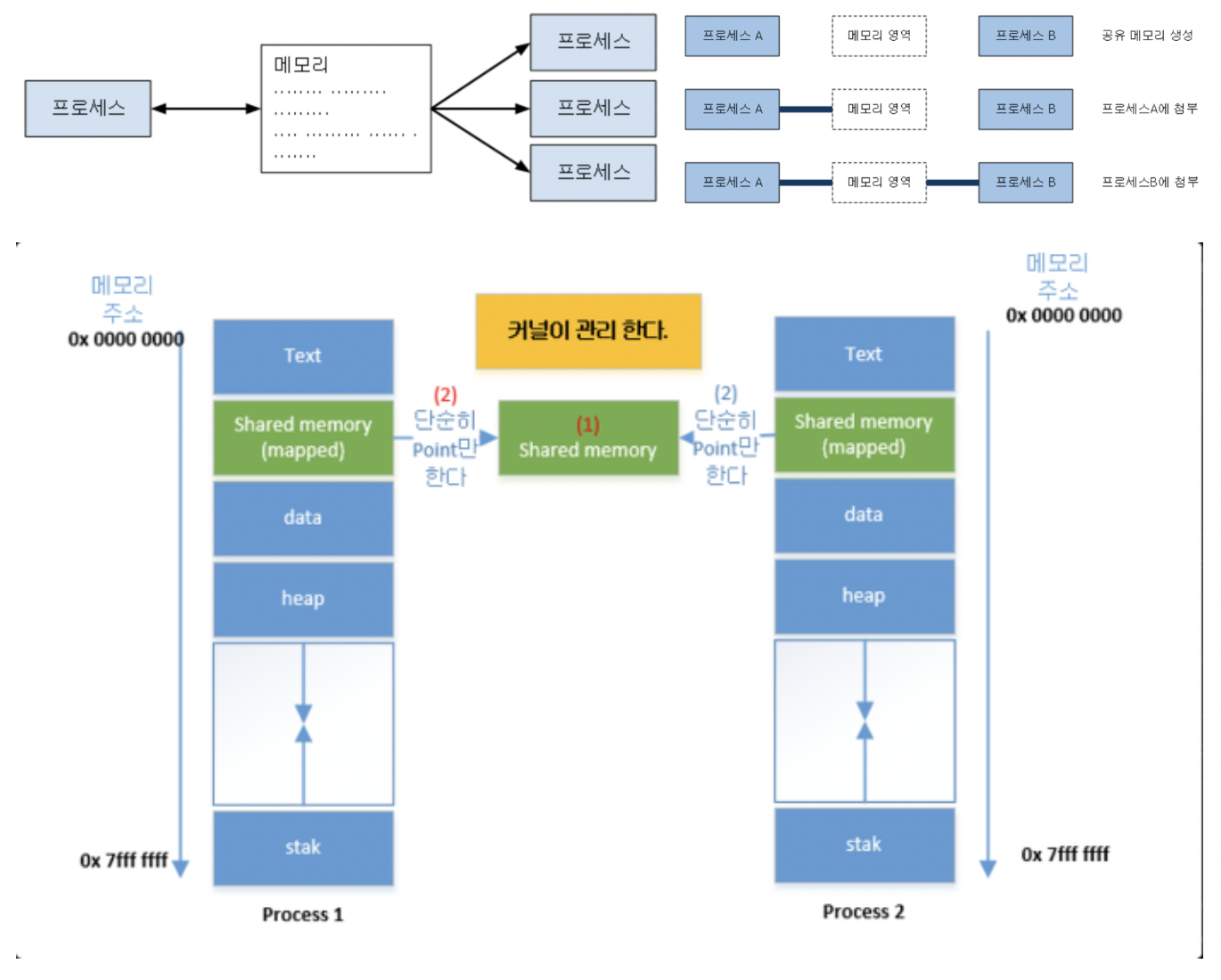
프로세스들 간의 의사소통하는 것을 IPC라고 한다.일반적인 방법으로는 프로세스들 간의 공유가 불가능하지만, 동시에 접근 가능한 메모리 즉 프로세스들이 공유하는 메모리가 필요하다. 공유 메모리는 프로세스간 메모리 영역을 공유해서 사용할 수 있도록 허용한다.프로세스가 공
14.[운영체제]메모리 할당
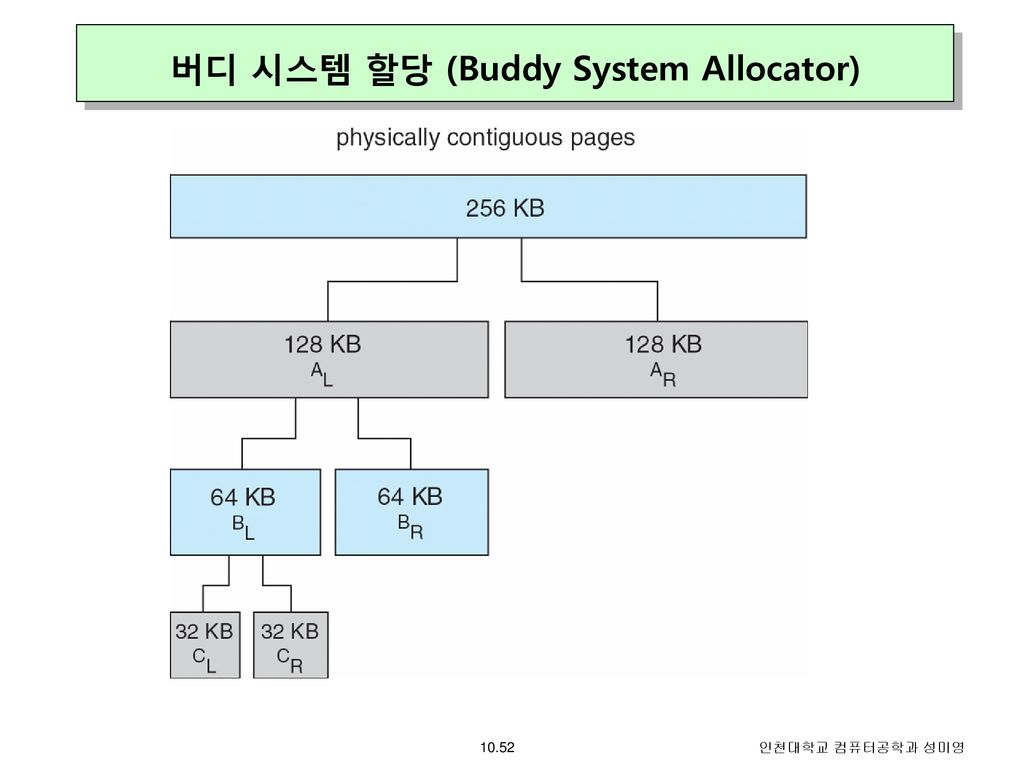
프로그램이나 데이터를 주기억장치에 할당하는 기법을 말한다.메모리할당은 연속 로딩 기법(단일, 다중 분할 할당)과 분산 로딩 기법(페이징, 세그먼테이션)으로 나눌 수 있다. 한 순간에 하나만 주기억장치의 USER영역을 사용하는 기법초기 운영체제에서 사용하던 기법으로 가장
15.[운영체제] 가상메모리
가상 메모리는 메모리가 실제 메모리보다 많아 보이게 하는 기술로, 어떤 프로세스가 실행될 때 메모리에 해당 프로세스 전체가 올라가지 않더라도 실행이 가능하다는 점에 착안하여 고안되었다.어플리케이션이 실행될 때, 실행에 필요한 일부분만 메모리에 올라가며 어플리케이션의 나
16.[운영체제] 가상메모리 관리
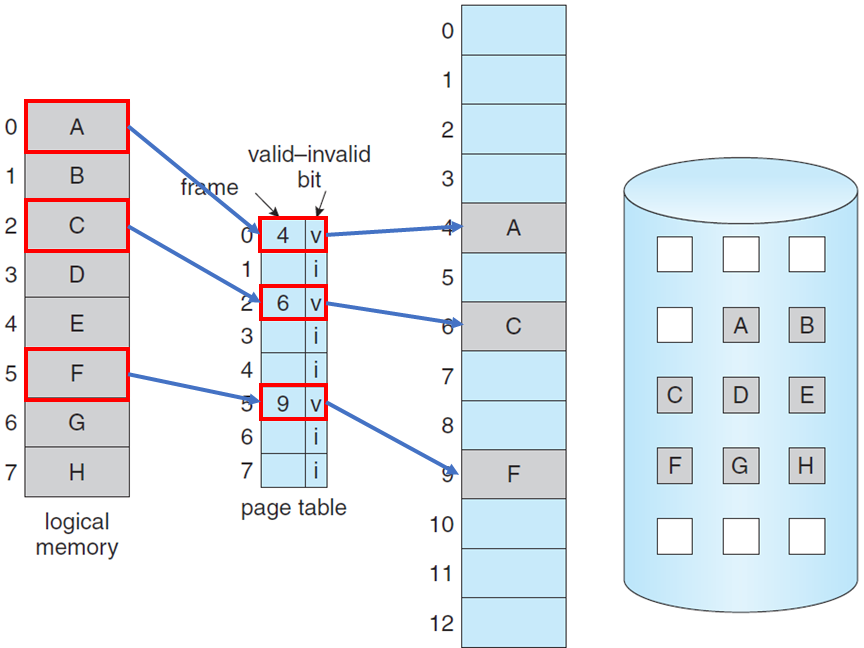
가상메모리란 메모리 내에 완전히 존재하지 않는 프로세스를 실행하는 기술을 의미한다.즉 프로그램이 CPU에 의해 실제로 사용되는 부분만 메모리로 로드하고, 사용되지 않는 부분은 디스크로 옮겨서 실제 메모리를 대체하도록 하는 것이다.장점물리 메모리의 크기에 제한 받지 않는
17.[운영체제]저장장치와 파일시스템
저장장치는 속도는 낮지만 용량은 큰 휘발성 메모리이다.종류는 HDD와 SDD로 HDD는 대용량이 가능한 대신 디스크 방식이라 SDD 보다는 느리다는 단점이 있고, SDD는 HDD보다는 적은 용량이지만 플래쉬를 통해 빠른 속도를 준다는 장점이 있다.SDD의 용량의 한도가
18.[네트워크] Web & HTTP
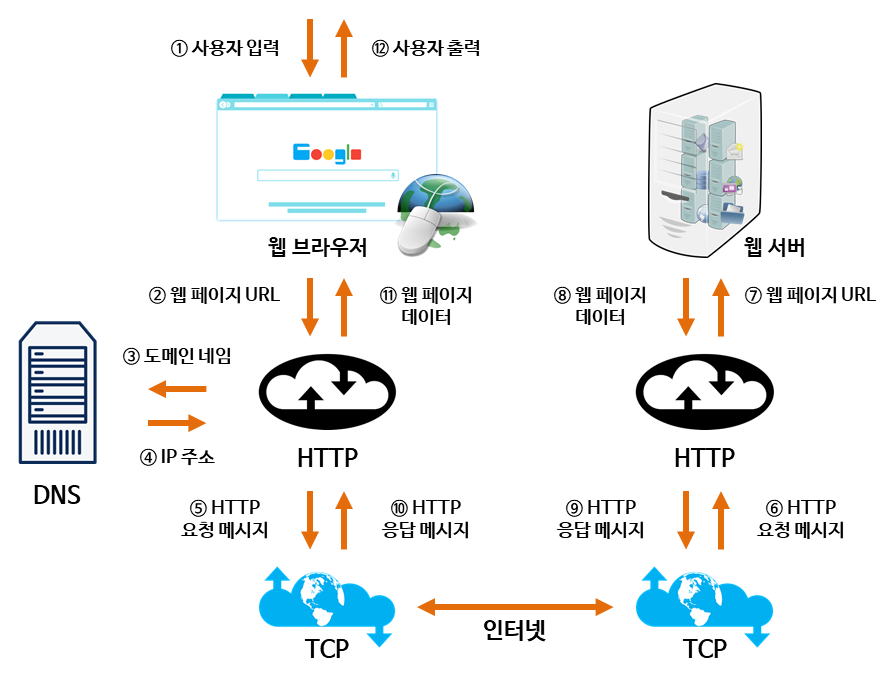
World Wide Web으로 WWW나 Web으로 불리며, 인터넷에 연결된 사용자들이 서로의 정보를 공유할 수 있는 공간을 의미한다.특징으로 웹에서는 html이라는 hypertext언어를 사용하여 문서를 작성하고, http라는 프로토콜을 사용하여 검색하고 접근이 가능하
19.[네트워크] 프로토콜 & OSI 7계층
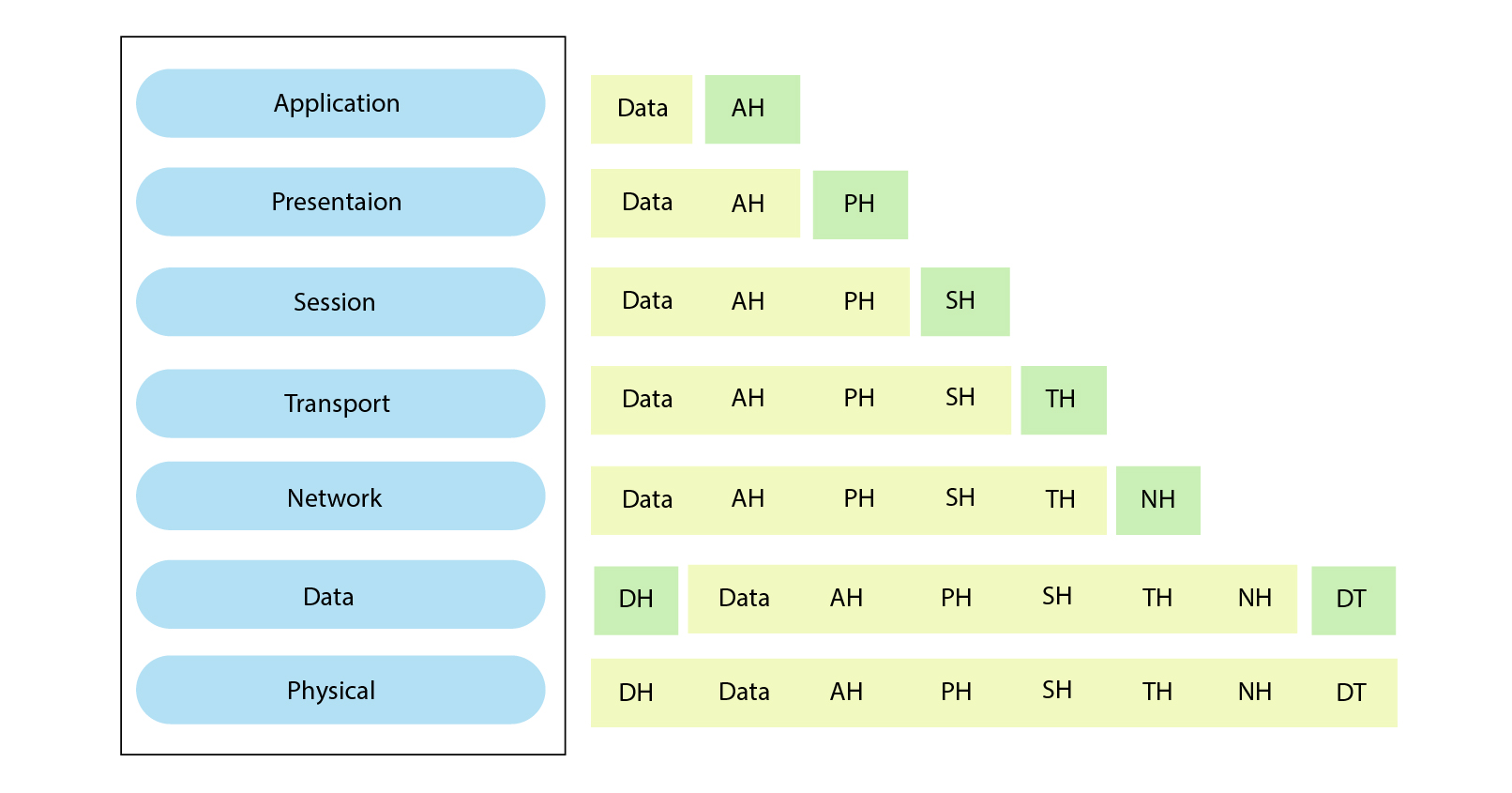
통신 프로토콜 또는 통신 규약은 컴퓨터나 원거리 통신 장비 사이에서 메시지를 주고 받는 양식과 규칙의 체계이다.즉 컴퓨터와 컴퓨터가 서로 이해 할 수 있는 언어이자 통신규약 및 약속이다.구문 : 전송하고자 하는 데이터의 형식, 부호화, 신호 레벨 등을 규정한다.의미 :
20.[네트워크] 네트워크 연결
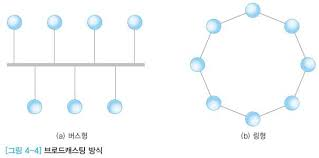
LAN은 단일 건물이나 학교 같은 소규모 지역에 위치하는 호스트로 구성된 네트워크이다.호스트의 간격이 가깝기 때문에 브로드캐스팅 방식으로 전송한다.버스형과 링형 2가지 연결 방식을 가진다. \* 무선 로컬 영역 네트워크로 와이파이 라고도 한다.IEEE 802.11
21.[네트워크] 네트워크 통신
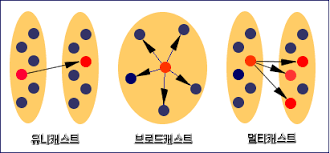
네트워크 상에서 서로를 구분하기 위하여 Device마다 할당된 물리적인 주소를 뜻하며, 정확한 정의로 컴퓨터에 장착되 랜카드를 구별하기 위해 만들어진 식별 번호이다.통신에는 유니캐스트, 브로드캐스트, 멀티캐스트, 애니캐스트가 있다.출발지와 목적지가 정확해야 하는 일대
22.[네트워크] 스위치(Layer2:데이터링크)

로컬 홈 네트워크와 같은 네트워크 내의 장치 간 통신을 허용하는 네트워크 하드웨어 장치이다.허브의 확장된 개념으로 디바이스에서 전송된 패킷이 허브에 연결된 모든 기기로 브로드캐스팅 시키는 반면, 스위치는 패킷의 목적지 주소로 지정된 디바이스로 이어지는 포트로만 패킷이
23.[네트워크] 라우터
라우터는 네트워크와 네트워크 간의 경로를 설정하고 가장 빠른 길로 트래픽을 이끌어주는 역할과 함께 NAT, 방화벽, VPN, QoS등 다양한 부가 기능을 함께 제공하기도 한다.경로지정 : 경로 정보를 모아 라우팅 테이블을 만들고 패킷을 라우터에 들어오면 패킷의 도차지
24.[백준] 10026(적록색약)
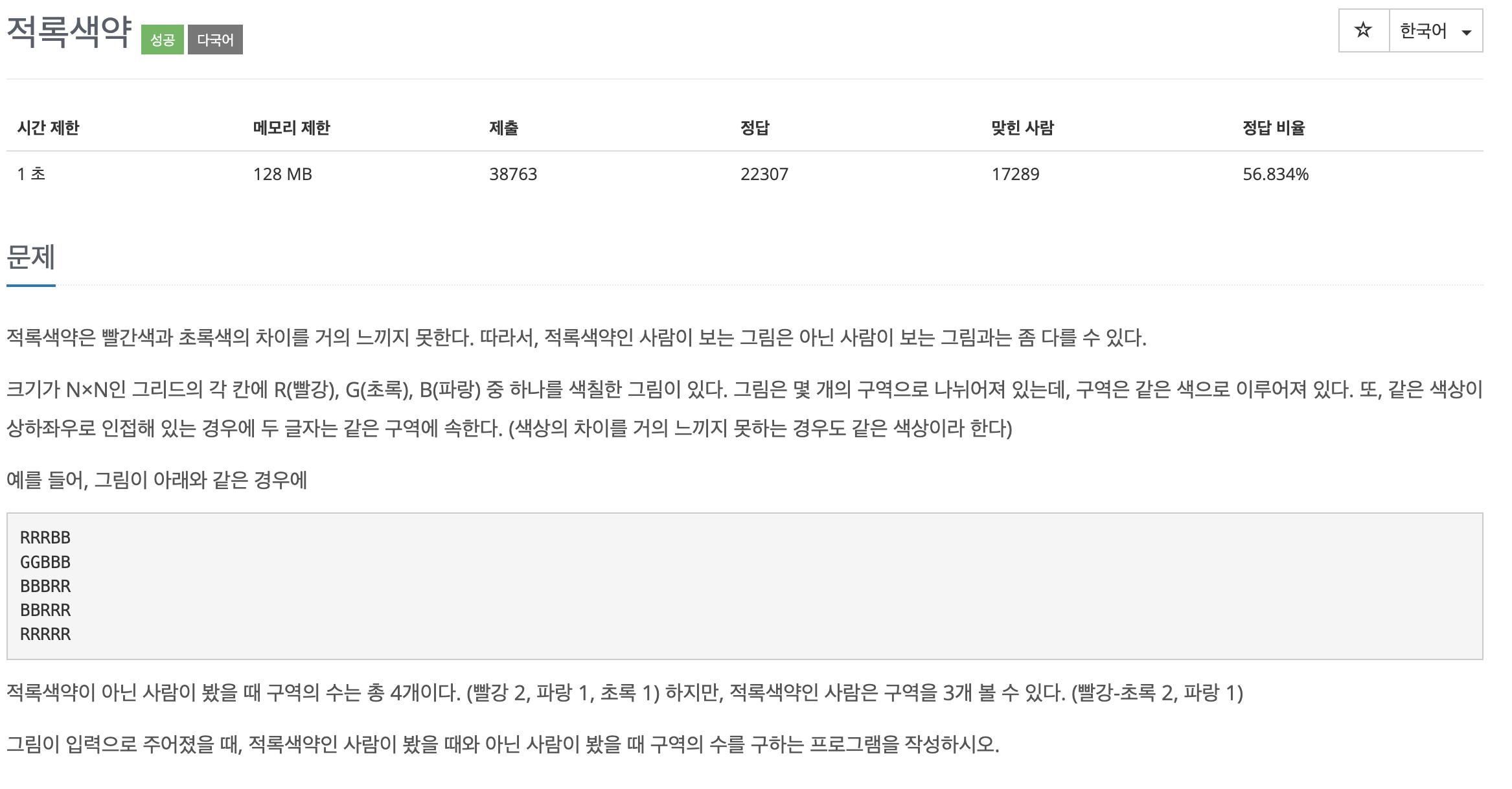
처음에는 int배열이 아닌 char배열을 사용하고, map과 visited배열을 정상인과 적록색인을 따로 따로 만들어 BFS를 통해 풀었지만, 메모리 초과를 받았다. 그래서 하나의 배열로 통일하고 DFS로 바꾸어 풀었다.색깔이 모여있는 그룹의 개수를 찾는 문제로 완전탐
25.[네트워크] 로드밸런서 (Layer4)
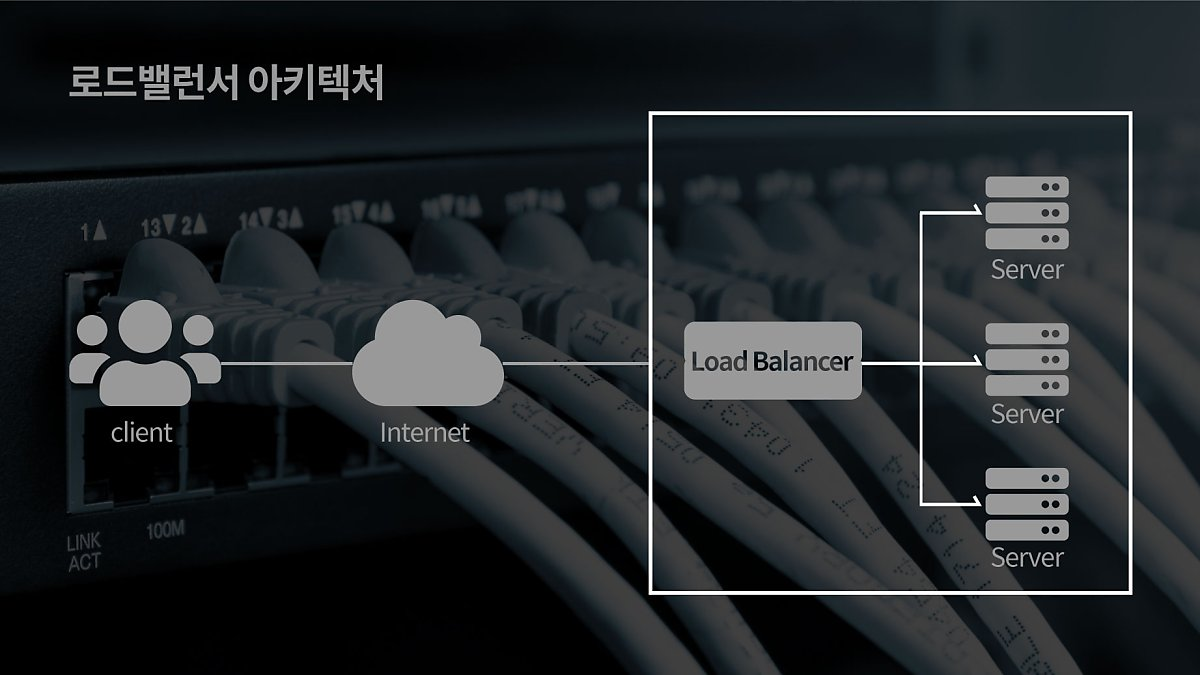
로드밸런서는 서버에 가해지는 부하(로드)를 분산(밸런싱)해주는 장치 또는 기술을 칭한다.클라이언트와 서버풀 사이에 위치하며, 한 대의 서버로 부하가 집중되지 않도록 트래픽을 관리해 각각의 서버가 최적의 퍼포먼스를 보일 수 있도록 제공해 준다.layer 4에서 패킷을 확
26.[네트워크] 네트워크 기술
NAT(Network Address Translation)은 IP패킷이 라우팅 장비를 거치면서 이동할 때 헤더에 있는 IP정보를 변환하는작업을 말하며, 공인IP 주소에 여러 개의 사설 IP주소를 할당하여 사용할 수 있게하는 장치이다.Static NATIP 주소들을 1대
27.[DB] 키
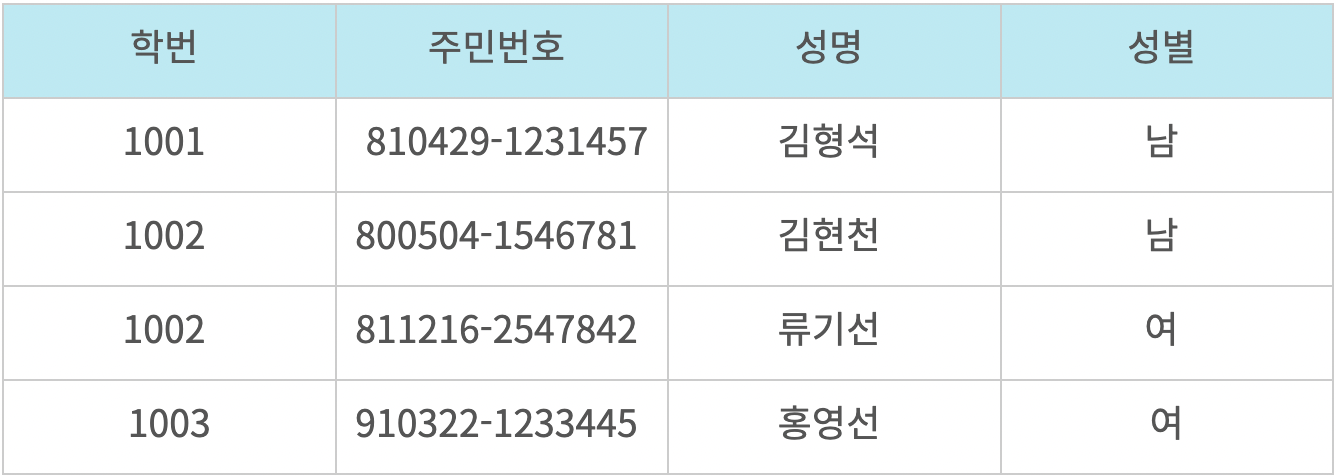
키는 DB에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 다른 튜플들과 구별할 수 있는 유일한 기준이되는 속성이다.튜플 : 릴레이션을 구성하는 각각의 행, 속성의 모임으로 구성된다. 데이터베이스에서 학번, 주민번호는 키(Key), 1001,810429-12314
28.[DB] Join
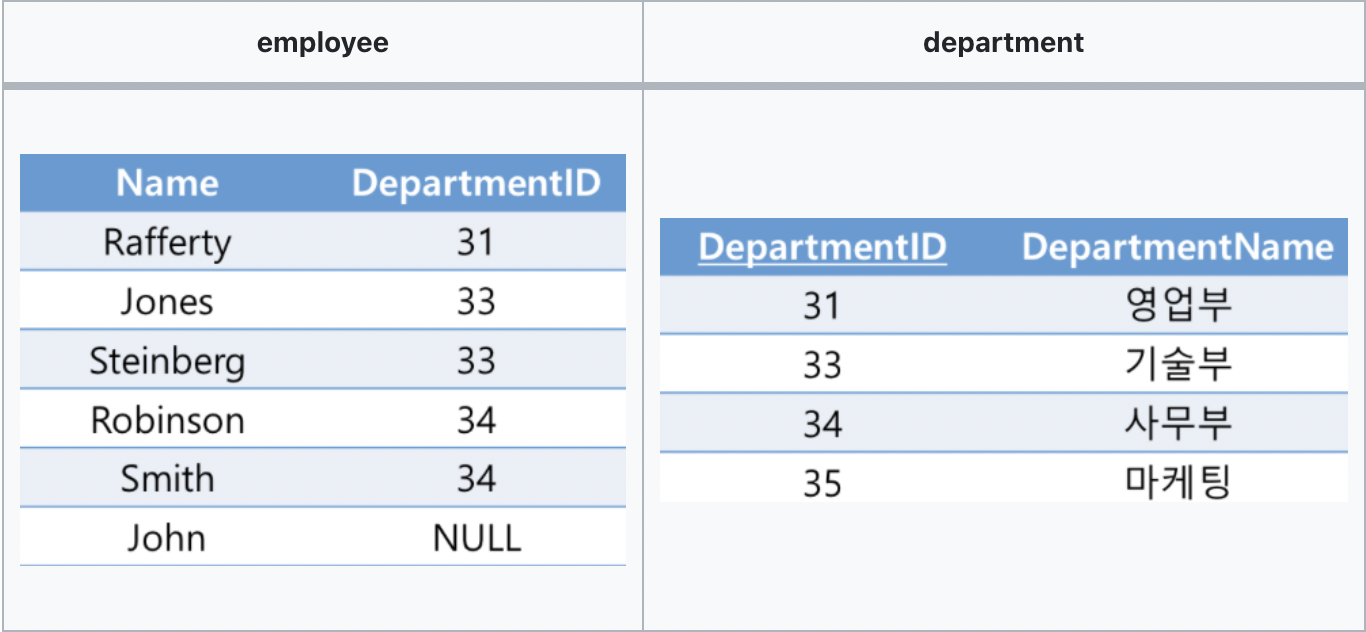
한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한 것을 의미한다.관계형 데이터베이스의 구조적 특징으로 정규화를 수행하면 의미 있는 데이터의 집합으로 테이블이 구성되고 각 테이블끼리는 관계를 가진다.이와 같은 특징으로 관계형 데이터베이스는 저장 공
29.[DB] SQL Injection
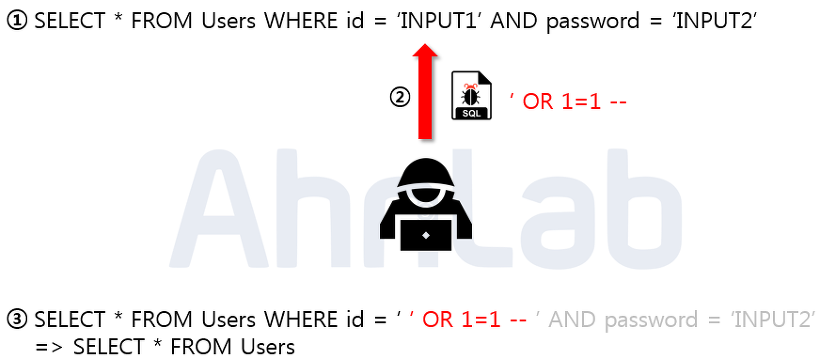
SQL Injection이란 악의적인 사용자가 보안상의 취약점을 이용하여 임의의 SQL문을 주입하고 실행되게 하여 데이터베이스가 비정상적인 동작을 하도록 조작하는 행위이다.위의 사진에서 보이는 쿼리문에서 where 절에 OR 1=1 이라는 구문을 이용해 where문을
30.[DB] SQL vs NOSQL
SQL은 RDBMS에서 데이터를 저장,수정,삭제 및 검색을 할 수 있고, 관계형 데이터베이스이다.관계형 데이터베이스의 특징데이터는 정해진 데이터 스키마에 따라 테이블에 저장된다.데이터는 관계를 통해 여러 테이블에 분산된다.관계형 데이터베이스는 테이블마다 명확하게 정의된
31.[DB] Index & B tree
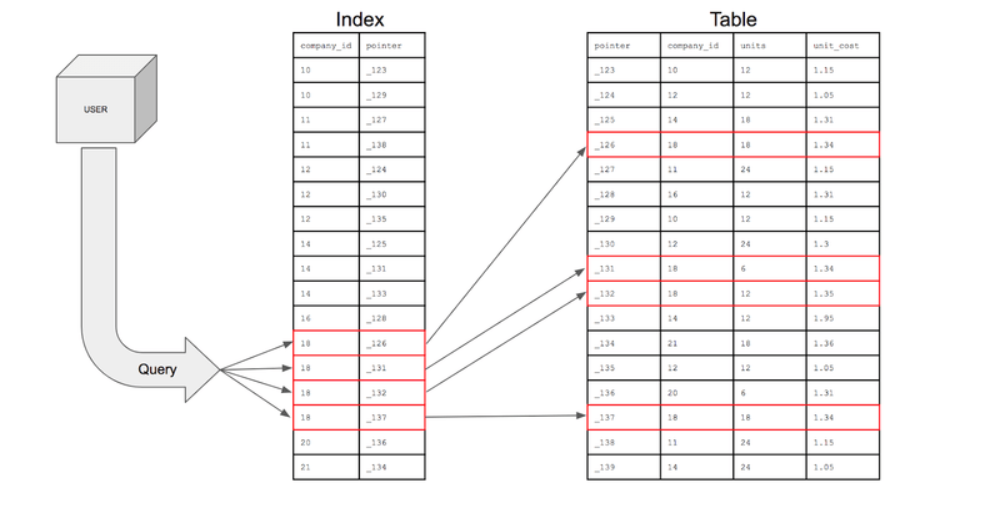
Index는 데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조이다. Index는 책에서 목차라고 생각하면 편하며 테이블에서 컬럼의 값과 물리적 주소를 한 쌍으로 저장한다. 주로 큐모가 큰 테이블이나, CUD작업이 자주 발생하지 않고, where,orderb
32.[DB] 정규화 vs 비정규화
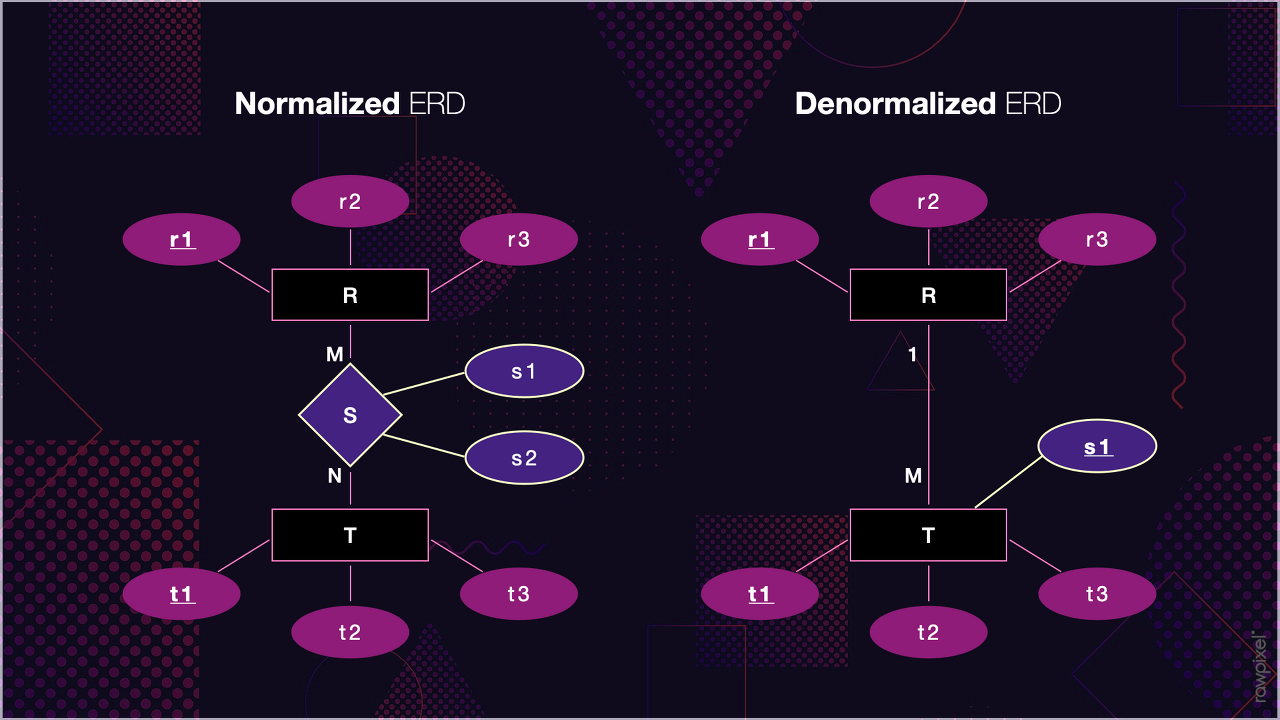
정규화 데이터베이스는 중복을 최소화하기 위해 데이터를 구조화하는 작업이다. 좀 더 구체적으로는 하나의 종속성이 하나의 릴레이션에 표현될 수 있도록 분해해가는 과정이라 할 수 있다.하나의 스키마를 다른 스키마로 변환할 때 정보의 손실이 있어서는 안 된다. (정보의 무손실
33.[DB] Transaction
Transaction은 상태를 변화시키기 위해 수행하는 작업 단위를 의미한다. 상태 변화 == CRUD 작업 단위 == 많은 SQL 명령문들을 사람이 정하는 기준에 따라 정하는 것원자성(Atomicity)트랜잭션이 DB에 모두 반영되거나, 혹은 전혀 반영되지 않아야 한
34.[DB] Redis

비관계형 데이터베이스(NoSql)로 메모리 기반의 key-value 구조 데이터 관리 시스템이다. 읽고 쓰는 속도가 SQL에 비해서 매우 빠르기 때문에 사용된다.자바 자료구조와 유사한 영속적인 자료구조 제공(키는 자바에서 참조와 동일하게 객체를 식별하는 역할을 한다.)