
구글에서 집필한 일본어와 한국어 음성 검색 논문입니다. BERT에서도 쓰이는 WordPiece Tokenizer가 처음으로 고안되었습니다.
음성 모델을 제외하고 NLP 관련 부분만 살펴보겠습니다.
✔ Introduction
한국어와 일본어 음성 검색의 한계
-
많은 알파벳 수
- 일어의 경우 기본 문자가 50자 정도 됨
-
여러 문자들의 혼합
- 일어 -> 히라가나 + 가타카나 + 한자 + ASCII
- 한국어 -> 한글 + 한자 + ASCII
-
많은 동음이의어
- 다양한 방법으로 문자를 표현할 수 있음 -> normalization을 요구하기도 함
-
공백 문자(space)
- 공백 문자는 언어에 따라(일어는 공백 문자를 거의 안씀) 또, 실제 적용에 따라서 달라진다.
-> Segmenter들은 기본 단어 단위를 고려하는데 사용되어야함.
-> 공백 문자는 디코딩 후 더해지거나 지워지는 방향으로 이루어져야함.
언어별 제약을 받지 않기 위해서 data-driven의 Segmenter 사용
✔ Acoustic Data Collection
기존 공공데이터는 음성 검색 작업과 다른 도메인들이 많음 => 데이터를 직접 만들어서 사용
Blackberry 음성 데이터 사용, 구글 검색 도메인의 익명화된 상위 N개의 쿼리로 도메인 매칭
장단점
- 장점: 일일히 전사(transcribe)할 필요가 없음
- 단점: LM 모델링, 인식 과정에서의 정교함이 필요
✔ Segmetation and Word Inventory
대부분의 아시안 언어는 공백이 없음
-> 어떻게 구분할 것인가?
유니코드로 구분하는 방법이 있지만, 문자 하나당 많은 발음을 가지고 있는 경우가 많아 어려움.
또한, 문맥적 의미나 언어에 대부분 의존하기 때문에 대규모 OOV 발생.
때문에 WordPieceModel을 사용, 많은 양의 텍스트를 자동으로 학습할 수 있다. WordPieceModel은 그리디 알고리즘으로 로그가능도를 가장 높일 수 있는 방향으로 학습한다.
Algorithm
-
단어 유닛 인벤토리를 기본 유니코드 문자와 ASCII로 초기화한다.
(일본어 - 히라가나, 가타카나, 한자: 22000자 / 한국어 - 한글: 11000자) -
1번의 인벤토리를 사용한 훈련 데이터로 언어모델을 학습한다.
-
단어 인벤토리 증가를 위해 두 단어 유닛을 결합하여 새로운 단어 유닛을 만든다. 이때 모델에 추가될 경우, 훈련 데이터의 우도(likelihood)를 가장 많이 증가시키는 후보지를 고른다.
-
사전에 정한 단어 유닛의 한도에 도달하거나 우도가 특정 한계점 이하로 증가하기 전까지 2, 3의 과정을 반복한다.
-
학습에 시간 복잡도 O(K2) 소요
* K는 현재 단어 유닛의 수 -
알고리즘이 빨라지기 위해서는...
- 학습 데이터에 실제로 있는 단어 쌍들만 확인한다.
- 우선 순위가 높은 단어 쌍들만 확인한다.
- 여러 클러스터링 과정들을 하나의 iteration으로 만든다.(단어쌍 군집들이 서로에게 영향을 주지 않을 때만)
- 영향을 받는 항목에 대한 언어 모델 수만 조정한다.
=> 이를 기반으로 200k word piece inventory를 제작함
segmentation algorithm은 기본 문자에서 시작하는 역 바이너리 트리 구조를 가짐
=> 문장의 길이에 대해 선형 시간의 segmentation을 제공할 수 있음
200k만 되도 거의 모든 단어에 대해 커버가 가능
- OOV 문제 해결 다소 해결
- 여러 발음이 할당된 단어가 많지 않아 모델 성능에 도움이 됨
* 대략 4%의 단어들이 여러 발음을 가지고 있었음
공백 처리 방법
처음에는 단어 조각들을 다시 결합하지 않는 시스템을 생각했으나 길고 드문 쿼리에 대해서는 나와서는 안되는 공백들이 등장함.
=> 어디에 공백 문자를 넣어야 하고 디코딩 전략의 일부로 만들기 위해 다음과 같은 방법을 사용
-
기존 언어 모델 데이터는 공백 문자가 있는 데이터와 없는 데이터가 섞여 있음
-
LM 데이터를 WordPieceModel로 분할할 때, 공백 문자 앞뒤로 space marker를 부착함.(논문에서는 '_'나 '~' 사용) 그러면 각가의 단어는 양쪽에 '_' 가 있는 경우(데이터의 가장 양옆은 공백이 있음), 왼쪽에 있는 경우, 오른쪽에 있는 경우, 없는 경우로 나뉜다. 이로써 단어 인벤토리의 크기는 4배가 됨
-
새로운 인벤토리를 기반으로 LM과 단어 사전을 만든다.
-
모델이 공백을 어디에 붙이고 붙이지 않아야 하는지 학습하는 동안 부착한 space marker들은 명확한 전시를 위해 필터링된다. 보통 디코더가 출력 문자열의 유닛 사이 자동으로 공백을 넣는 것을 고려하면 예상 시나리오는 다음과 같다.
(a) 모든 공백을 제거한다.(" " -> "")
(b) spacemarker 두개를 공백 문자로 바꾼다.("__" -> "_")
(C) 남은 단일 space marker를 제거한다.("_" -> "")
예시
(1) "京都 清水寺の写真" (원 텍스트)
(2) "京都 清水寺 の写真"(segmentation 후)
(3) "_京都_ _清水寺 の写真_"(LM 훈련, 단어 사전 등에 사용되는 underscore 추가)
(4) "_京都_ _清水寺 の写真_"(디코더 결과)
(5) "京都 清水寺の写真"(전시된 결과)
✔ Language Modeling
논문에서 사용한 LM은 Katz back-off가 적용된 entropy-pruned 3-5 gram이다.
영어 외래어(일어 사전의 25%, 한국어 사전의 40%는 ASCII 단어이고, 대부분이 영어다.)의 경우 기존 단어와 구분이 없게 설정하였으며, 기존 음소 집합으로 발음하겠끔 하였다.
데이터의 경우 시기 별로 자주 쓰이는 단어를 고려하여 1년 치 데이터를 사용하였다.
표 1에서는 기본 단어 인벤토리의 크기(50k, 100k, 200k)에 따른 일어 LM의 perplexity를 나타내고 있는데, 테스트 집합을 랜덤으로 뽑은 rand250k 집합과 상위 10k개를 뽑은 top10k 집합으로 나뉘어져 있다.
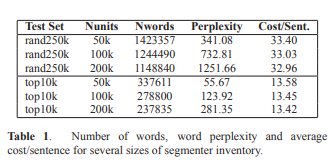
단어 정의가 인벤토리 크기에 따라 달라지기에 perplexity 자체를 비교하는 것은 의미가 없으나, 문장 별 평균 비용(디코딩 과정에서의 로그 가능도를 통해 계산이 가능하다.)을 통해 비교할 수 있다.
✔ Dictionary
일어와 한국어 발음 사전이 구축되기 어려운 이유
-
일어의 경우
- 한자의 음독, 훈독이 있어 모호한 발음을 가지고 있음
- 여러 문자들이 혼재되어 사용되기에 자동 툴로는 발음이 어려움(ex- AKB48, シャ乱Q 등)
- 지명, 이름의 경우 현지 일본인도 발음이 어려운 단어들이 있음
-
한국어의 경우
- 두 언어가 섞인 약어, TV 쇼 이름, 라디오 방송사 등의 단어들은 자동을 통한 발음이 어려움
=> 많은 단어의 사전을 만들 때에는 인간의 개입이 가능한 반자동 프로세스를 거칠 필요가 있다.
semi-automatic process
-
내부 IME(Input Method Editor) 데이터, ASCII 단어를 위한 내부 transliterator 등을 검토하여 중요한 발음 그룹의 음성 인식을 평가헀다.
-
LM 데이터에서 발생한 상위 10k 단어
-
단일 문자 단어(한자)
-
단일 음소 발음을 가진 단어
-
1~3 글자의 ASCII 단어(상당수는 약어)
-
-
발음만 맞으면 사전 내 유닛으로 어떤 일어/한국어 단어도 표현할 수 있기에 해당 작업은 한번만 해도 된다.
또한, 무작정 많은 발음 데이터를 학습시키는 건 accuracy의 감소로 이어짐
낮은 빈도의 발음이나 높은 빈도수의 짧은 단어(단일 한자나 단일 ASCII 단어) 발음을 추가한다면, 성능 감소가 이뤄질 수 있다.
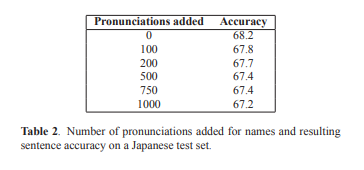
표 2는 일어 이름 발음을 추가했을 때의 accuracy를 보여주는데, 추가하는 발음이 많을수록 감소하는 경향을 보인다.
=> 기존의 발음과는 다르되, 빈도수는 어느 정도 있는 발음만 추가하는 것이 좋다.
