
위 논문은 NMT(neural machine translation)에서 subword segmentation을 통해 의도적으로 노이즈를 주는 방법을 제시합니다. 그 과정에서 Unigram이라 하는 새로운 subword segmentation 알고리즘을 제시합니다.
✔ Introduction
이전까지 NMT 분야에서 중요한 것은 vocabulary, 단어 집합의 크기였습니다. 하지만, 대부분 고정된 단어 집합을 사용하였고 그로 인해 OOV 문제가 대두되었습니다.
이런 문제를 해결하기 위해 드물게 등장하는 단어들을 subword 유닛들로 쪼개어 사전을 구성하였습니다. BPE(Byte-Pair_Encoding)가 그 예시입니다.
BPE
BPE을 기반으로 한 segmentation은 단어 집합 크기와 디코딩 효율성 모두 챙길 수 있었습니다. 하지만, 같은 단어 집합이더라도 문장이 여러 subword sequence로 표현될 수 있었습니다.
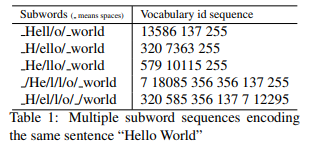
표 1은, "Hello World"라는 문장을 여러 subword sequence로 분할하고 인코딩한 결과입니다.
이런 일종의 '모호성'은 NMT 훈련 시 모델이 합성성의 원리를 배우게 하여 성능 향상에 도움을 줄 수 있습니다.
때문에 본 연구에서는 NMT를 위한 새로운 regularization 방법인 subword regularition을 고안했습니다. 이 방법은 다음 두 가지로 이루어집니다.
- 여러 segmentation들을 통합할 수 있는 NMT 훈련 알고리즘
- 즉각적인 데이터 샘플링
- LM에 기반한 새로운 subword segmentation 알고리즘
- 여러 segmentations을 확률로 제공
여러 크기와 언어의 corpora로 실험한 결과, subword regularization 기법이 단일 subword segmentation 기법을 사용했을 때보다 훨씬 좋은 성능을 보입니다. 게다가 도메인 밖인 corpora의 경우에도 성능 향상이 있었습니다.
✔ NMT with multiple subword segmentaion
NMT trainig with on-the-fly subword sampling
소스 문장 X와 타겟 문장 Y가 있다면
, 를 각각의 subword segmenter와 대응되도록 분할합니다.
이므로 NMT 모델이 타겟 문장의 확률을 계산하는 식은 다음과 같습니다.
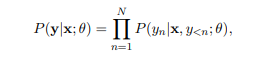
모델은 타겟 히스토리인 와 모델 파라미터 θ를 기반으로 타겟 subword 를 예측합니다.
보통, subword 를 예측하기 위해서는 RNN 아키텍쳐를 사용합니다. 하지만, RNN에 국한된 것이 아닌 다른 아키텍처를 통해서도 subword regularization을 구현할 수 있습니다.
NMT 모델은 로그 가능도 L(θ)를 최대화하는 걸 목적으로 하고 있습니다.
병렬 말뭉치 일때, 로그가능도는 다음과 같습니다.
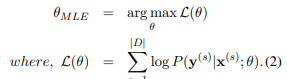
소스 문장과 타겟 문장 X와 Y는 segmentation 확률 와 를 각각 가진 여러 subword sequences로 나뉠 수 있습니다. 로그 가능도를 marginalize likelihood로 최적화하면 아래와 같은 식이 나옵니다.
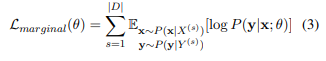
일 때 x의 기댓값인 과 일 때 y의 기댓값인 를 활용하여 특정 , 가 아닌 변수들의 분포에 따른 값을 기준으로 합니다.
실상, 위의 식의 정확한 최적화는 실현할 수가 없습니다. 가능한 segmentation의 수가 문장 길이에 따라 지수적으로 증가하기 때문입니다. 때문에 와 각각 k개의 sequence만 샘플링하여 근사치를 구합니다. 근사치를 구하는 식은 다음과 같습니다.
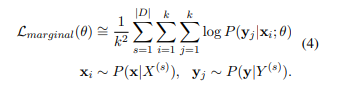
k개의 샘플을 추출한 후 로그 가능도를 계산하고, 평균을 내는 과정입니다.
단순성을 위해 k의 값을 1로 사용하고, 파라미터 θ가 코퍼스 D의 하위 집합(mini-batch)에 대하여 반복적으로 최적화되게 학습하였습니다. 이후 충분히 학습이 진행되면 subword sampling이 진행됩니다. 이 방식은 k의 값이 1이더라도 (3)의 근사치를 구할 수 있지만, subword sequence가 매 파라미터 업데이트마다 동적으로 샘플링됩니다.
Decoding
직관적으로 디코딩을 보자면 P(x|X)를 가장 높이는 segmentation x*를 번역하는 것입니다.
즉,
추가적으로 논문에서는 여러 segmentation 기법들을 합치기 위해 의 n-best segmentation을 사용합니다. n-best segmentation 중 다음 스코어를 최대화하는 을 선택합니다.
의 경우, 의 subword의 수이고, 은 짧은 문장들에 패널티를 부여하는 파라미터입니다.
✔ Subword segmentations with language model
Byte-Pair-Encoding(BPE)
BPE는 기존의 NMT에서 많이 쓰이던 segmentation 알고리즘입니다. 알고리즘 과정은 다음과 같습니다.
- 전체 문장을 개별적인 문자(character)로 나눈다.
- 가장 빈도가 높은 인접한 두 쌍의 문자를 병합한다.
- 2의 과정을 원하는 단어 사전 크기에 도달할 때까지 반복한다.
BPE segmentation의 경우에는 문자의 빈도수를 기준으로 병합을 진행하기 때문에 흔하지 않은 문자로 이뤄진 단어는 작은 유닛으로 흩어질 것입니다. 때문에 작은 vocab의 경우에선 문장 인코딩에 필요한 symbol의 수가 많지 않아집니다.
하지만, BPE의 경우에는 그리디하고 결정론적 알고리즘에 기반을 하고 있기 때문에 확률에 따른 여러 segmentation을 제공해주지는 못합니다.
그러므로 segmentation 확률 을 사용하는 subword regularization에 BPE를 적용하는 것은 효과적이지 않을 수 있습니다.
Unigram langauge model
논문에서는 multiple subword segmentation 확률에 기반할 수 있도록 새로운 subword segmentation 알고리즘을 제안하였습니다.
unigram langauge model의 경우 각각의 subword가 독립적으로 발생하고,
subword sequence 가 subword 발생 확률인 의 곱으로 이루어집니다. (target sequence인 도 마찬가지로 적용됩니다.)
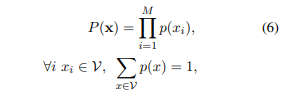
는 미리 결정된 단어사전입니다. 입력 문장 X에 대해 가장 확률이 높은 segmentation 은 다음과 같이 표현됩니다.
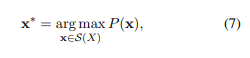
는 입력 문장 X에게서 얻어진 segmentation 후보군 집합을 말합니다. 은 Viterbi 알고리즘에 의해 구할 수 있습니다.
단어사전 B가 주어졌을 때 subword 발생 확률 는 다음의 marginal likelihood을 최대화하는 EM 알고리즘을 통해 산출할 수 있습니다. 이때, 는 hidden variable로 간주됩니다.
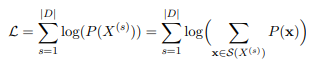
하지만 실제 환경에서는 단어집합 V는 알기 힘듭니다. 단어 집합의 joint optimization이나 발생 확률을 다루기 힘들기 때문입니다. 그렇기에 다음과 같은 알고리즘을 사용합니다.
-
학습 코퍼스로부터 충분히 큰 seed vocabulary를 만든다.
-
다음 과정을 가 원하는 단어 사전 크기에 도달할 때까지 반복한다.
a) 단어 사전을 조정하기 위해서 EM 알고리즘에 따라 를 최적화한다.
b) 각 subword 별 를 계산한다. 는 subword 가 현재 단어 사전에서 제거되었을 때 가능도 이 얼마나 감소되는지를 표현한 것이다.
c) 를 기준으로 symbol들을 정렬한 후 상위 %의 subword만 남긴다. OOV 문제를 방지하기 위해 subword가 단일 문자로 이루어지게 해야한다.
seed vocabulary를 준비하는 방법은 여러 가지가 있습니다. 일반적으로는 모든 문자의 조합과 코퍼스 내 가장 빈도가 높던 substring들로 구성합니다. (BPE를 돌리는 것으로도 만들 수 있습니다.)
빈도수가 높은 substring들은 Enhanced Suffix Array algorithm에 의해 O(T)의 시간과 O(20T) 공간으로 나열될 수 있습니다. 이때, T는 코퍼스의 크기입니다.
최종 단어 사전 는 코퍼스 내 모든 개별 문자를 포함하기에, 문자 기반 segmentation 역시 segmentation 후보군 에 포함합니다. 즉, unigram langauge model 기반 subword segmentation은 문자, subword, 그리고 word segmentation의 확률 조합이라 볼 수 있습니다.
Subword sampling
subword regularization은 각 파라미터 업데이트에서 분포 로부터 하나의 subword segmentation을 샘플링합니다.
직관적으로 l-best 샘플링을 사용할 수 있습니다. 확률 에 따른 l-best segmentaton을 구합니다.(Forward-DP Backward-A 알고리즘으로 선형시간에 l-best를 찾는 과정이 진행됩니다.)
segmenation 는 다음 다항분포에 의해 샘플링됩니다.
는 하이퍼파라미터로 분포 굴곡의 완만함을 조절합니다. 가 작을 수록 균등 분포에서 샘플링하는 것과 비슷해지고, 가 커질 수록 Viterbi segmentaton에서 고를 경향이 높아집니다.
이라 가정하는 건 가능한 모든 segmentation을 고려하는 것과도 같습니다. 하지만 segmentation 후보 수가 지수적으로 증가하기에 이는 불가능에 가깝습니다.
가능한 segmentation들을 정확히 샘플링하기 위해, FFBS(Forward-Filtering and Backward-Sampling) 기법을 사용합니다.
FFBS에서 모든 segmentation 후보군들은 격자 구조로 표현됩니다. 각각의 노드는 하나의 subword에 대응됩니다.
첫 번째 단계에서 FFBS는 격자 내 모든 subword의 forward probability(전방 확률)를 계산합니다. 이 확률은 특정 subword w에 도달할 확률을 나타냅니다.
두 번째 단계에서는 문장의 끝에서 시작하여 격자의 노드들을 역방향으로 순회합니다. 이 과정에서 subword들은 forward probability를 기반으로 재귀적 샘플링을 진행합니다.
BPE vs Unigram language model
BPE와 Unigram 모두 텍스트를 데이터 압축 기법으로 적은 비트에 인코딩한다는 개념에서 비롯되었습니다. 하지만 다음과 같은 점에서 차이를 보입니다.
-
BPE
- dictionary encoder의 일종
-> symbol의 집합을 찾아서 전체 symbol 수를 최소화하는 방향
- dictionary encoder의 일종
-
Unigram
-
entropy encoder 기반
-> 텍스트의 전체 code(인코딩된 표현) 길이를 최소화하는 방향cf) Shannon의 코딩 정리를 기반으로 symbol s에 대한 최적의 code 길이는 이다. 는 의 발생 확률을 뜻한다.
-
확률 언어 모델을 기반은로 하기 때문에 유연하고 여러 segmentation을 확률에 따라 산출할 수 있다.
-> subword regularization 작업에 더 적확함
-
✔ Experiment
Setting
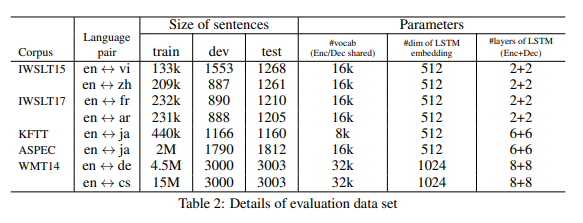
코퍼스 및 언어
: 다양한 크기와 언어의 코퍼스를 사용하여 실험을 진행하였습니다.
-
소형 코퍼스: IWSLT15/17, KFTT(언어 독립성 평가 가능)
-
중형 코퍼스: ASPEC, WMT14(en<->de)
-
대형 코퍼스: WMT14(en<->cs, 1000만개 이상의 문장 쌍 포함)
NMT 시스템
- GNMT(Wu et al., 2016) 기반
- 코퍼스 사이즈에 따라 몇몇 세팅은 바꿈
- 공통 설정
- dropout: 0.2
- Adam + SGD
- length normalization, converge penalty: 0.2
- decoding beam size: 4
데이터 전처리
- 평가 지표: BLEU
- Moses 토크나이저 사용
-> but, 중국어와 일본어는 문장을 단어로 바꿔주지 못함
-> KyTea를 사용해 문자 단위로 세분화 후 BLEU 계산
비교 시스템 및 샘플링 전략
- Baseline system
: BPE segmentation 사용
-
Test system
: Unigram language model segmentation 사용- subword regularization 없이 ()
- subword regularization 적용 ()
- infinite sampling ()
- : IWSLT
- : 나머지
-
one-best 디코딩과 n-best 디코딩을 비교
- BPE segmentation의 경우 multiple segmentation을 적용할 수 없으므로 one-best decoding만 평가
-> 로 BPE와 Unigram의 순수한 성능 비교
- BPE segmentation의 경우 multiple segmentation을 적용할 수 없으므로 one-best decoding만 평가
Main results
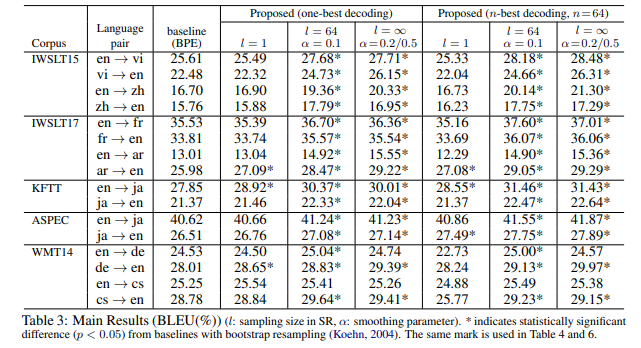
표 3을 통해 알 수 있는 점은 다음과 같습니다.
-
subword regularization을 적용하지 않았을 때( 일때), BPE 방식과 Unigram 방식은 BLEU 점수에서 큰 차이를 보이지 않았습니다. 이는 둘 모두 데이터 압축 알고리즘을 기반으로 하기 때문입니다.
-
WMT14(en->cs)를 제외한 모든 언어쌍에서 subword regularization이 BLEU 점수를 확연히 높였습니다. (+1~2 정도)
- 특히 IWSLT와 KFTT에서 큰 차이를 보였는데, 이는 크기가 작은 데이터셋에서 subword regularization으로 인한 데이터 증강이 긍정적인 영향을 주는 것이 아닐까 사료됩니다.
-
샘플링 알고리즘 부분에서는 IWSLT 코퍼스에서 ()가 ()보다 살짝 앞섰지만, 크기가 큰 데이터셋에서는 큰 차이를 보이지 못했습니다.
-
n-best 디코딩은 많은 언어쌍에서 더 높은 결과를 보였습니다. 하지만, n-best 디코딩은 subword regularization이 필수적이라는 점을 알아야 합니다. subword regularization을 적용하지 않은 경우(l=1)에서는 몇몇 언어쌍들의 BLEU 점수가 감소하였습니다.
Results with out-of-domain corpus
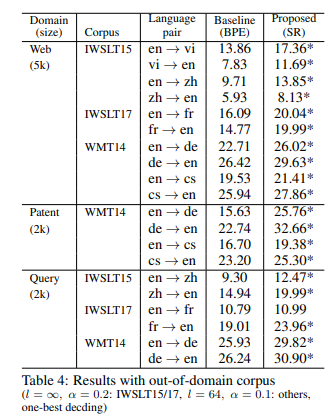
subword regularization이 open-domain일 때의 효과를 보기 위하여, 여러 장르(web, patent, query)로 이루어진 out-of-domain 플랜트 데이터로 평가했습니다. KFTT와 ASPEC 코퍼스의 경우, 도메인이 너무 특정적이라 BLEU 점수가 극히 낮아졌기(5 미만으로)에 시행하지 않았습니다.
표 3의 증가폭과 비교했을 때, out-of-domain에서의 subword regularization 사용이 2 포인트 정도 더 증가폭이 컸습니다. 또한 조금의 증가가 있었던 데이터셋(WMT14)에서조차 큰 폭의 증가를 보였습니다. 이는 subword regularization이 open-domain에서 강점을 보인다는 점을 뒷받침합니다.
Comparison with other segmentation algorithms

표 5는 단어, 문자, 단어/문자 혼합, BPE와 subword regularization을 적용한 Unigram을 비교한 표입니다. 평가에 사용한 독일어는 형태가 풍부한 언어이기에 큰 단어 집합이 필요합니다. 때문에 subword 기반의 알고리즘이 기존의 단어 모델보다 BLEU 점수가 1포인트 더 높습니다.
Impact of sampling hyperparameters
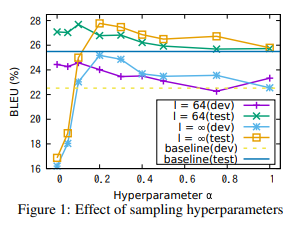
subword regularization은 두 개의 하이퍼파라미터가 있습니다.
- : 샘플링하는 후보의 개수를 정합니다.
- : 분포의 완만함을 정하는 상수입니다.
그림 1은 IWSLT15(en -> vi) 데이터를 사용하여 하이퍼파리미터에 따른 BLEU 점수를 도식화한 그림입니다.
첫번째로, 샘플링 크기인 에 따라서 BLEU 점수가 최대가 되는 가 달라집니다. 이는 의 수가 커질수록 샘플 시퀀스들을 Viterbi sequence x*에 가깝게 하기 위해 가 커져야 하기 때문입니다.
또한, 일때 유독 성능이 떨어지는 경향을 보였습니다. 이는 segmentation 확률인 가 에서는 무시되고, 하나의 segmentation만 샘플링 되기 때문입니다. 이는 편향된 샘플링이 실제 노이즈를 반영하여 번역에 도움이 된다는 점을 시사합니다.
일반적으로 의 값이 커지면 적은 데이터셋에 효과적인 적극적인 regularization이 됩니다. 반대로 의 추정치는 민감해지고, 가 극단적으로 작으면 baseline 모델보다 안 좋은 성능을 낼 수 있습니다. 이러한 점을 고려했을 때, 많은 크기의 코퍼스에는 를 사용하는 것이 합리적입니다.
Results with single side regularization
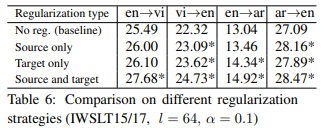
표 6은 subword regularization을 소스 문장과 타겟 문장 각각 적용시켰을 때의 BLEU 점수를 나타낸 것으로, 인코더 혹은 디코더 중 어느 쪽이 더 영향을 받았는지 나타냅니다.
예상대로, 한쪽에만 적용한 결과는 양쪽 모두에 적용한 결과보다 낮았습니다. 하지만 한쪽만 정규화를 진행했을 때에도 기존 baseline 모델보다는 높은 성능을 보였습니다. 이는 subword regularization이 인코더-디코더 구조뿐만 아니라 다른 NLP task에서도 강점을 보일 수 있음을 시사합니다.
