
Inductive bias
모델은 특정 데이터를 기반으로 학습하기에 일반화의 오류를 가진다. 모델이 주어진 데이터에만 일반화 성능이 좋은 것인지, 아님 전반적인 일반화 성능을 가진 것인지 모르기 때문이다. 따라서 주어지지 않은 입력에 대해 출력을 이럴 것이다 하고 예측하는 가정을 세운다. 그것이 inductive bias이다.
대표적인 예시는 다음과 같다.
Linear regression: 데이터가 라는 선형 관계를 가질 것이라 가정. a와 b를 조정하여 최적의 모델을 찾음
CNN: 이미지는 가까운 픽셀끼리 정보가 강하게 연관되어 있음.(locality)
RNN: 입력이 sequential하다고 가정. 입력의 순서와 출력의 순서는 동일함.(temporal invariance)
Transformer: self-attention으로 입력 데이터와 encoder 내 모든 요소를 반영, positional encoding으로 위치 관계 주입. 하지만 상대적으로 CNN보다 inductive bias가 약함.
Inductive bias가 강할수록 작은 데이터셋에 학습 성능이 좋아진다. 하지만, 다양한 task에서 준수한 성적을 내기는 힘들기에 최근의 딥러닝에서는 inductive bias를 낮추는 경향을 보인다. 다만 이 경우 많은 양의 데이터셋이 필요하다.
Bias-Variance trade-off
Variance: 예측값이 얼마나 분포되어있는가?
Bias: 타겟과 예측값이 얼마나 떨어져 있는가
Bias가 높은 경우 Underfitting이 발생하고, Variance가 높은 경우 Overfitting이 발생한다. MSE를 예시로 설명하도록 하겠다.
실제값이 이라 할 때(은 노이즈), MSE에서는 기댓값은 이다.
보통 은 평균이 0으로 설정되므로
정리하면
는 의 분산을 나타낸 것이다.
노이즈의 분산이 고정되어 있다는 전제 하에서, 오차의 기댓값을 줄이려면 bias와 variance를 줄여야 한다. 하지만 모델의 복잡도 축에서 bias와 variance는 trade off되는 경향이 있다.
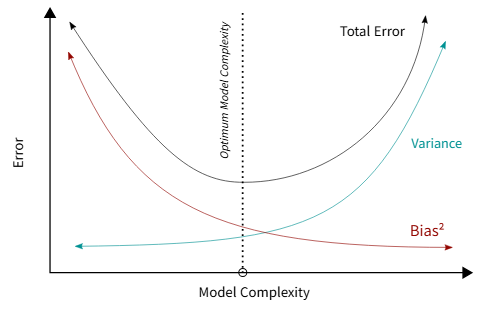
모델의 정의에 따라 함수 공간 가 설정되는데, 모델의 복잡도가 증가하면(파라미터 수가 늘리거나 제약이 적어진다면) 는 넓어진다.
모델 의 risk를 로 정의한다. 이는 데이터 분포 로부터 무작위로 뽑은 표본 에 대해 평균적인 오차를 나타냅니다. 학습이 끝났을 때, 이 작아지도록 하는 것이 목표지만, 를 모르고, 모든 데이터를 샘플링하지 않기에 경험적 오차인 를 측정한다.
는 근사 오차로 함수 공간 안에서 일반화 오차가 작은 함수를 골랐을 때의 오차를 말한다.
를 키우게 되면 최소인 후보가 많아지므로 근사 오차는 줄어들고, 이는 곧 bias 감소로 이어진다. 또한 함수 공간을 넓힐수록 모델의 복잡도 역시 증가한다. 이 고정일 경우 복잡도가 커지면 추정오차인 가 커지게 된다. 이때 표본이 달라져 가 크게 변화하므로 Variance 역시 커진다. 다만 이 경우에는 n이 충분히 크면 어느 정도 상쇄가 가능하다.
inductive bias는 모델을 어떤 형태의 함수로 가정할 것인지 정하므로 함수 공간 의 구조를 정한다고 볼 수 있다. 가령, linear regression의 경우 의 형태로 inductive bias를 잡기 때문에 함수 공간은 의 형태를 가진다.
따라서 bias variance trade off에 입각하여 성능을 고려할 때는 validation data로 여러 복잡도의 모델을 고려하는 것뿐만 아니라, inductive bias로 인해 제한되는 가설 공간 역시 고려할 필요가 있다.
Reference
[1] https://untitledtblog.tistory.com/143
[2] https://moon-walker.medium.com/transformer%EB%8A%94-inductive-bias%EC%9D%B4-%EB%B6%80%EC%A1%B1%ED%95%98%EB%8B%A4%EB%9D%BC%EB%8A%94-%EC%9D%98%EB%AF%B8%EB%8A%94-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C-4f6005d32558
[3] https://re-code-cord.tistory.com/entry/Inductive-Bias%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
[4] https://dacon.io/en/forum/405840
