
Seq2Seq는 기존의 DNN 중심의 모델에서 RNN을 활용한 End-to-End 방식을 제시하였습니다. Encoder와 Decoder로 구성된 모델 구조는 이후 등장할 수많은 논문들에 영향을 주었습니다.
✔ Introduction
DNN은 음성 인식이나 오브젝트 인식 같은 복잡한 문제들에서 높은 성능을 보였습니다. 라벨링된 데이터가 충분히 있다면, 역전파를 통해서 학습이 가능합니다.
이런 성능에도 불구하고 DNN은 입력과 타겟 데이터가 고정 차원의 벡터로 인코딩된 문제들만 적용이 가능합니다. 하지만, 대부분의 문제들은 사전에 길이를 알 수 없는 시퀀스로 표현되곤 합니다. 일례로, 음성 인식이나 기계 번역과 같은 문제들은 본질적으로 순차적인 성질을 띠고 있습니다.
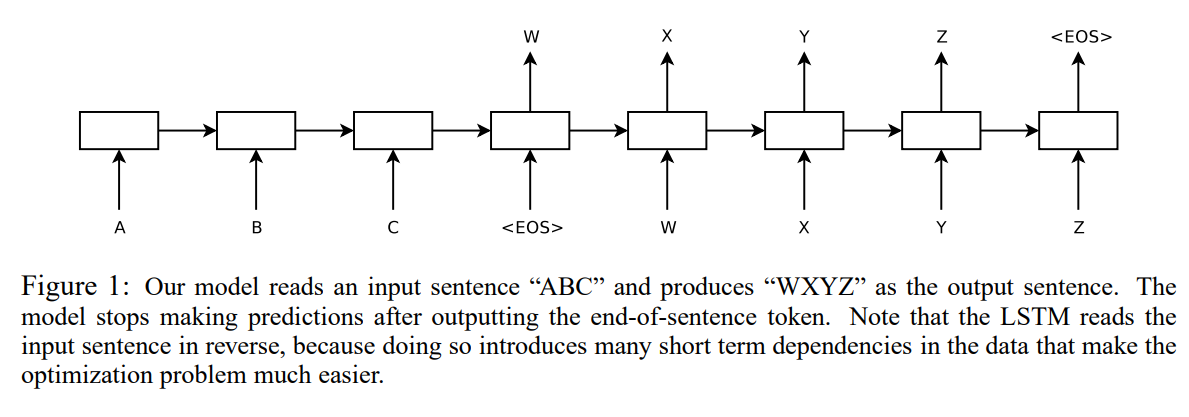
이를 해결하기 위해 논문에서는 LSTM(Long Short-Term Memory) 구조를 적용하였습니다. 입력 시퀀스를 읽기 위해 LSTM을 사용해 한 번에 하나의 time step씩 읽어 고정 차원의 벡터 표현(vector representation)을 생성하고, 다른 LSTM을 연결해서 해당 벡터 표현으로부터 출력 시퀀스를 얻는 방식으로 이루어집니다. 두 번째 LSTM은 본질적으로 RNN 언어 모델이긴 한데, 입력 문장의 조건만 달라진 거라고 보시면 됩니다.
모델 성능은 WMT'14 English to French task에서 5개의 deep LSTM을 앙상블한 모델로 BLEU score 34.81을 달성하면서 대규모 신경망 네트워크를 사용한 직접 번역한 것들 중에는 가장 높은 성과를 냈습니다. SMT와 비교했을 때, 최적화가 되지 않은 작은 vocab을 가졌음에도 성능이 더 높게 나왔습니다.
LSTM이 매우 긴 문장에서 성능 저하를 보이기 때문에, 논문에서는 입력 문장만 역순으로 배치하는 방법을 사용하였습니다. 그 결과 매우 긴 문장에서도 성능 저하를 보이지 않는 LSTM을 학습할 수 있었습니다.
또한 번역이라는 학습 목표는 LSTM으로 하여금 의미가 비슷한 문장끼리는 가까운 벡터로, 다른 문장끼리는 먼 벡터로 표현하게 하면서, 단어 순서나 능동태 같은 의미적인 부분에서도 강하다는 것을 확인할 수 있었습니다.
✔ Model
RNN(Recurrent Neural Network)는 FNN을 시퀀스에 확장한 버전입니다. 기본적인 RNN은 입력 시퀀스 와 출력 시퀀스 가 있을 때 다음 수식을 반복합니다.
RNN은 입력과 출력 시퀀스 사이 alignment가 주어진 경우, 쉽게 매핑이 가능하나 둘 사이 길이가 다르거나 관계가 복잡할 경우에는 어떻게 적용해야 할 지 명확하지 않습니다.
이 경우, RNN을 사용하여 입력 시퀀스를 고정된 크기의 벡터로 매핑한 후 다른 RNN을 사용하여 타겟 시퀀스와 매핑하는 것이 일반적입니다. RNN이 모든 관련된 정보를 받기에 가능하지만 long-term dependecies로 인해 학습이 어렵습니다. 때문에 이를 보완한 LSTM을 많이 사용합니다.
LSTM의 목표는 입력 시퀀스 와 출력 시퀀스 가 주어졌을 때, 조건부 확률 을 구하는 것입니다. (이때, 과 는 다름)
LSTM은 입력 시퀀스를 넣은 LSTM의 마지막 hidden state에서 주어진 고정 차원 표현 를 기반으로 조건확률을 계산합니다.(입력 시퀀스 전체 요약) 그 후에는 해당 벡터를 LSTM-LM의 hidden state으로 넣어 을 얻습니다.
각각의 분포는 vocab 전체에 대한 softmax 분포로 표현됩니다. 이를 통해 각 단어의 등장 확률을 계산할 수 있습니다. 또한 각 문장 끝마다 <EOS>라는 special token을 붙이게 되는데, 이는 가변적인 시퀀스 길이에도 정상적인 확률 분포 정의가 가능하게 해줍니다.
실제 모델에서는 세 가지 점에서 차이가 발생했습니다.
-
인코더와 디코더를 각각 다른 LSTM으로 분리
-> 유연한 학습 도모 -
4개의 층으로 된 deep LSTM 사용
-> 성능을 향상 -
입력 문장의 단어 순서를 뒤집어 매핑
ex) -> 을
-> 로 매핑-> SGD가 효과적으로 학습, 성능 향상
✔ Experiment
WMT'14 English to French MT task를 두 가지 방식으로 적용하였습니다.
-
직접 번역
: reference SMT baseline을 쓰지 않고 직접 번역 -
rescore n-best list
: SMT baseline이 만든 n-best 단어 리스트를 재평가
✅ Dataset details
- 정제된 12M 문장들
- 348M 프랑스어 단어, 304M 영어 단어으로 구성
- 고정된 단어사전 사용
- 입력 언어: 빈도순으로 160,000개- 출력 언어: 빈도순으로 80,000개
- OOV는 "UNK"로 처리
✅ Decoding and Rescoring
입력 문장 에 대해 정답 번역 가 주어졌을 때 로그 확률이 최대화되도록 학습을 진행하였습니다. 아래는 목적 함수입니다.
는 훈련 집합입니다. 훈련이 끝나면 가장 가능성이 높은 번역을 선택합니다.
논문에서는 가장 확률이 높은 번역을 찾기 위해 좌 -> 우 방향의 beam search decoder를 사용하였습니다. 매 시점마다 작은 수 개(beam size)의 부분 가설(a prefix of some translation)만 유지하고 나머지는 고려하지 않습니다. 이는 단어 사전 내 모든 단어로 확장할 경우 연산량이 기하급수적으로 증가하기 때문에 상위 개의 단어만 남기는 것입니다.
<EOS>가 어떤 가설 뒤에 붙는 순간 해당 가설은 빔에서 제거되고 완전한 가설(complete hypotheses)에 추가됩니다. beam size가 1에서도 좋은 성능을 보이며, 2가 되어도 빔 서치의 대부분의 효과를 얻을 수 있습니다.
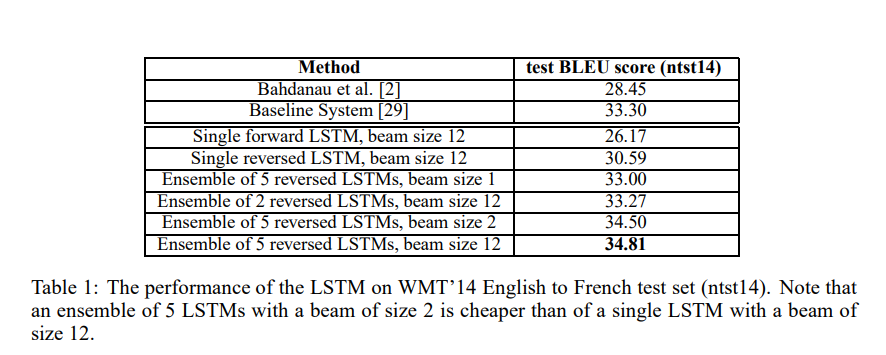 table 1을 보면, beam size가 2인 경우와 12인 경우와 큰 차이가 없는 것을 확인할 수 있습니다.
table 1을 보면, beam size가 2인 경우와 12인 경우와 큰 차이가 없는 것을 확인할 수 있습니다.
또한, 논문에서는 baseline 시스템이 만든 1000-best 리스트를 재평가(rescore)하였습니다. n-best 리스트를 재평가하기 위해 모든 가설을 LSTM으로 로그 확률을 계산해보고, 그 점수와 기존 시스템의 점수를 평균내어 최종 점수로 사용했습니다.
✅ Reversing the Source Sentences
LSTM의 고질적인 문제인 long term dependencies를 해결하기 위해 입력 문장을 역순으로 입력하는 방법을 차용했습니다. 논문에선 해당 현상에 완벽한 설명을 할 수는 없지만, 데이터셋에 많은 short term dependencies이 발생했기 때문이라고 추측합니다. 보통 소스 문장과 타겟 문장을 이으면, 소스 문장의 각 단어는 대응하는 타겟 문장과 멀어지기 마련입니다. 이는 곧 큰 최소 시간 지연(minimal time lag)으로 이어집니다.
반면, 단어 순서를 뒤집는 경우에는 전체 평균 거리는 변하지는 않지만, 소스 문장의 앞쪽 단어와 타겟 문장의 앞쪽 단어가 가까워지기 때문에 최소 시간 지연이 크게 줄어집니다. 이로 인해 역전파 학습 시 소스 문장과 타겟 문장의 연결을 더 잘 학습할 수 있게 됩니다.
✅ Training details
-
4개 레이어로 구성된 deep LSTM 사용
- 레이어 당 1000개의 셀
- 1000 차원의 단어 임베딩
- 160,000개의 입력 단어 사전, 80,000개의 출력 단어 사전
-> 8000개의 실수로 문장 표현(1000 x 4 x 2)
-
80,000개의 단어에 대해서 naive softmax 진행
-
384M의 파라미터
-
-0.08과 0.08 사이 균등 분포로 파라미터 초기화
-
SGD 사용
- 고정 learning rate는 0.7
- 5 에폭 후 반 에폭마다 반으로 줄임
-
7.5 에폭 학습
-
128개씩 미니 배치를 나눠 학습하였고, 각 샘플이 만든 gradient를 배치 크기로 나눠서 반영함
-
gradient의 norm이 임계점을 넘으면 조정하는 제약을 걸음
- 매 학습 배치마다 (는 128로 나눈 gradient) 계산.
- 이면
-
각 문장끼리 길이가 다르다보니(짧은 문장들이 많음) 여러 미니 배치가 버려졌음. 때문에 비슷한 길이의 문장끼리 묶어서 학습.
✅ Parallelization
- C++ 구현 + 단일 GPU => 1초에 1700 단어
- 너무 느림
- 8-GPU로 각 레이어 당 하나씩 4개 배치, 나머지 4개는 softmax 병렬 연산
=> 1초에 6300 단어 달성.
✅ Experimental Results

논문에서는 평가 지표로 cased BLEU score를 사용하였습니다. 기존 논문과 동일하게 multi-bleu.pl을 사용하여 토큰화된 결과와 정답 간의 BLEU 점수를 계산하였습니다. 하지만 WMT'14의 최고 결과를 위와 같은 방식으로 평가하면 37.0으로, 기존에 보고된 35.8점보다 높습니다. 이는 같은 BLEU 점수여도 계산 방식에 따라 결과에 차이가 발생할 수 있음을 뜻합니다.
표 1과 표 2에서 나와있듯, 가장 좋은 결과는 LSTM 앙상블 모델이었는데 이는 모델 초기화와 미니 배치 구성이 다르게 학습되었기 때문인 것으로 사료됩니다. 결과 자체는 WMT'14의 최고 점수보다 낮지만, 신경망 기반 NMT가 구문 기반 SMT를 뛰어넘은 최초의 경우입니다. 또한 LSTM이 1000-best list를 재평가했을 때의 BLEU score는 best WMT'14와 0.5점 밖에 차이나지 않았습니다.
✅ Performance on long sentences
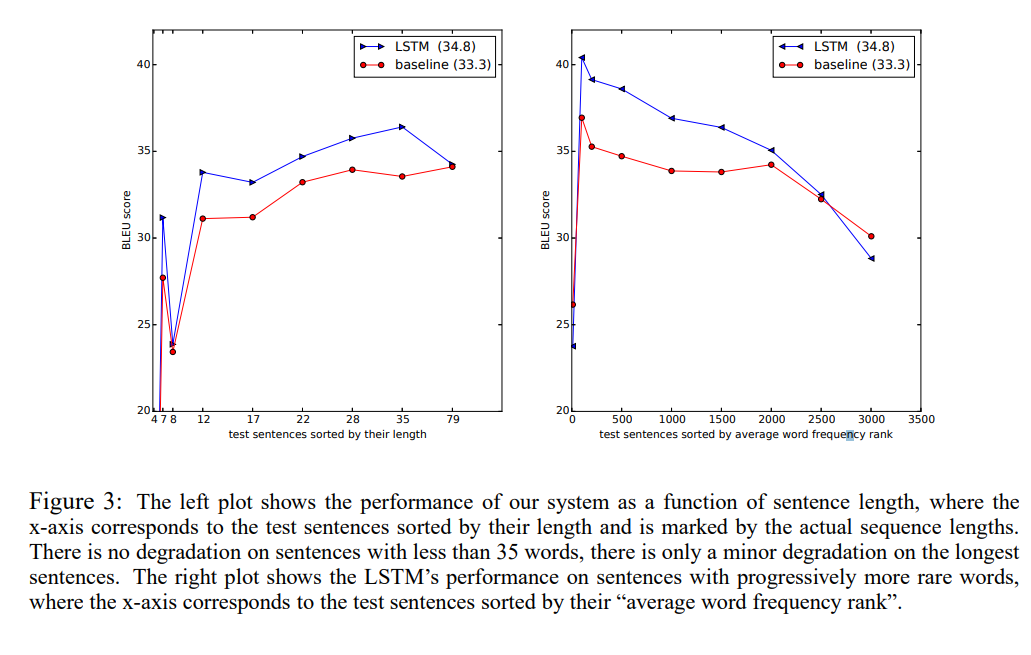

그림 3에 나온 것처럼 LSTM은 긴 문장의 경우에도 성능이 좋습니다. 표 3에서 예시를 확인할 수 있습니다.
✅ Model Analysis
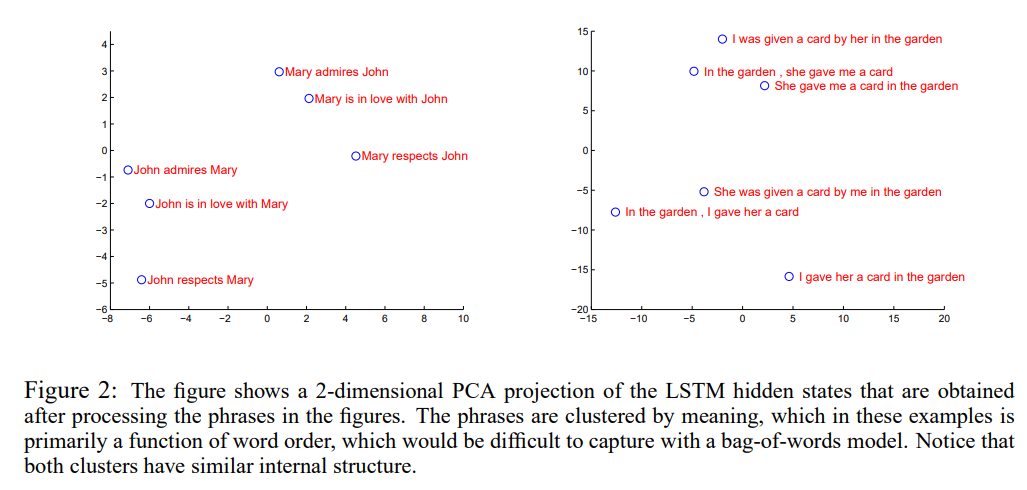
모델의 주요한 특징 중 하나로는 단어 시퀀스를 고정 차원 내에 벡터화할 수 있다는 것입니다. 그림 2에서는 학습한 representation 일부를 PCA로 시각화하고 있습니다. 살펴보면, representation이 단어 순서에는 민감하지만 능동태/수동태에는 그렇게 민감하지 않다는 것을 확인할 수 있습니다.
