
✔️ Introduction
현대의 NLP task들은 PLMs(pre-trained language models)이 대부분입니다. 특히, tokenize 기법으로 사용되는 BPE 알고리즘은 OOV(Out of Vocabulary) 문제를 어느 정도 해결할 수 있다는 점에서 주로 사용되었습니다. 하지만, 한국어는 많은 알파벳, 하위 문자들의 결합 등으로 vocabulary의 개수가 증가하고, 교착어의 성질로 인해 BPE tokenizer의 이점이 발휘되지 못하였습니다.
따라서 논문에서는 하위 문자(sub-character)와 형태소 분석기 기반 BPE를 통해 해당 한계를 극복하려 합니다. factorization 기반 형태론적 접근을 통해 새로운 한국어 언어 모델 KRongBERT를 제시합니다.
✔️ Preliminaries
💡 Korean writing system
한글은 초, 중, 종성으로 구성되어 있고, 11,172개의 음절 블록이 유니코드에 등재되어 있습니다. 이는 기본 방식으로 했을 때 높은 cost와 complexity를 발생시킵니다.
💡 Morphological characteristics of Korean
한국어 형태소는 어근과 접사를 포함한 의미의 최소 단위이며, 형태론적 변환(morphological transformation)을 통해 단어를 형성합니다. 한국어는 교착어이기 때문에 의미나 문법 형태를 표현하기 위하여 여러 접사가 어근에 부착되며, 이는 유럽 계통 언어와는 차이점을 보입니다.

가령 표 1의 '아름다운'의 경우 '아름답'이라는 어근에 '은'이 결합되어 형태론적 변환을 거친 결과입니다. 반면, '학교에서'와 '학교의'는 같은 어근인 '학교'이지만 사용되는 접사가 다릅니다. 이처럼 한국어는 접사에 따라 단어의 형태나 의미가 크게 차이납니다.
또한, 문장부호나 격조사로 인해 단어 순서가 비교적 자유롭습니다. 기본 형태는 subject- object - verb(SOV)이지만, object - subject - verb(OSV)와 같은 형태도 문법적으로 인정되고 강조를 위해 사용되기도 합니다.
✔️ Methodology
모델 전체 구조는 다음과 같습니다.
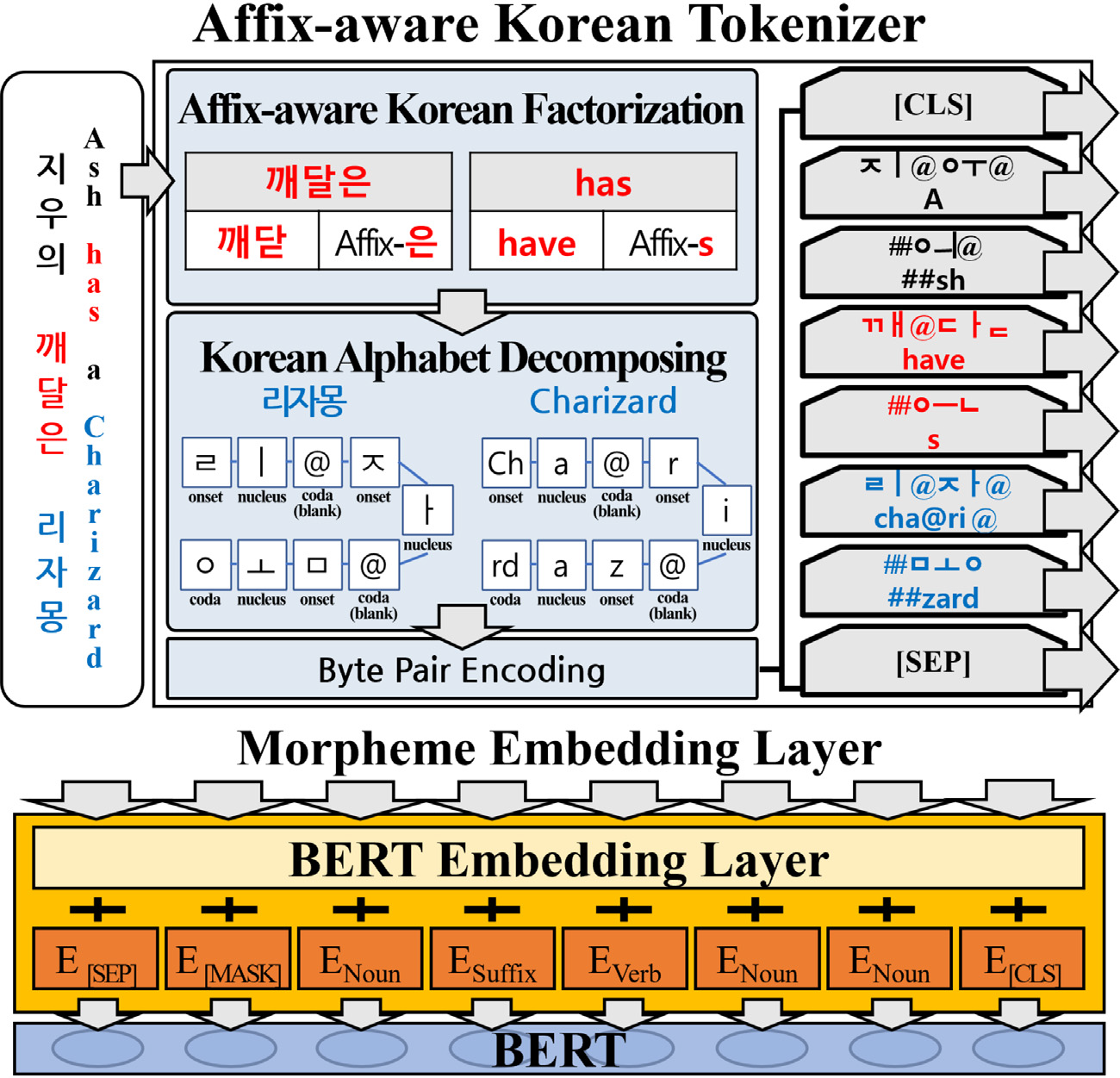
💡Affix-aware Korean tokenizer
KoRongBERT의 tokenizer는 접사 구조를 효율적으로 분해하기 위해 접사 중심으로 학습합니다. 형태 변화는 일반적으로 하위 문자 수준에서 발생하고 어근에 비해 형태가 단순합니다. 때문에 한국어를 하위 문자 단위로 분해하고 핵심 접사를 추가하는 방식으로 한국어 BPE tokenizer를 구성하였습니다.

이를 위해서 먼저 코퍼스 내 모든 단어를 형태소 분석기를 통해 분해합니다. 분석기는 하위 문자 단위로 형태소 분석이 가능한 Kiwi를 사용하였습니다.
이 과정에서 접사들의 출현 빈도를 바탕으로 형태소-품사 사전이 갱신됩니다. 즉, 조사, 어미, 접사 등의 형태소가 코퍼스 전체에서 몇 번 등장했는지를 pos_dict에 누적합니다.
또, 각 단어들을 형태소로 분해하고 morphs에 저장합니다. 각 형태소에 대해 pos_dict는 출현 빈도를 담고, vocab에서는 형태소의 목록을 저장합니다. 결과적으로 형태소 빈도 사전(pos_dict)과 형태소 목록(vocab)을 반환합니다.

그 후 분해된 한국어 문자들을 자모로 분리합니다. 종성이 없는 경우, blank 문자인 @로 표기하여 일관성 있게 처리합니다. 이런 토큰들은 decomposed_vocab에 저장되며 한국어 음절 구조에 맞는 토크나이징을 가능하게 합니다.

BPE vocab은 형태소-품사 사전과 자모 수준으로 분해된 단어 집합으로 학습됩니다. 때문에 초기 vocab은 한국어 하위 문자들과 자주 발생하는 접사 토큰들로 이뤄져 있습니다. 하지만 최종 vocab은 자주 나타나는 문자들을 결합하면서 학습됩니다. 다만, 효율적인 vocab 구성을 위해 코퍼스에서 자주 등장하는 형태소와 접사를 찾고, 일정 threshold 이상의 것들만 vocab에 추가합니다.
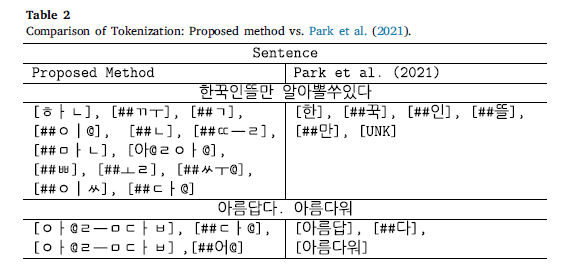
기존의 토큰화 방법들은 형태소 수준에서 공백 문자를 정의하지만, 이는 한국어 형태론 내 다양한 변형을 다루는데 한계가 있습니다. 또한, 한국어 형태소는 어근과 접사가 결합하는 과정에서 형태가 변하기에 바이트 수준의 형태소 BPE로도 한계가 있습니다.
표 2는 baseline 모델과 KRongBERT를 비교한 것입니다. 첫 예문에는 "한꾹인뜰만 알아뽈쑤있다"같은 장난식으로 적은 표현이 있는데, KRongBERT는 OOV 없이 처리하는 것을 확인할 수 있습니다. 또한, "아름답다"에서 변형된 "아름다워"를 어근과 접사를 나누어 파악해 기존 모델보다 의미를 더 잘 보존할 수 있습니다. 그리고 토큰 수 역시 불필요하게 증가하지 않는 점도 볼 수 있습니다.
💡 Morpheme embedding layer
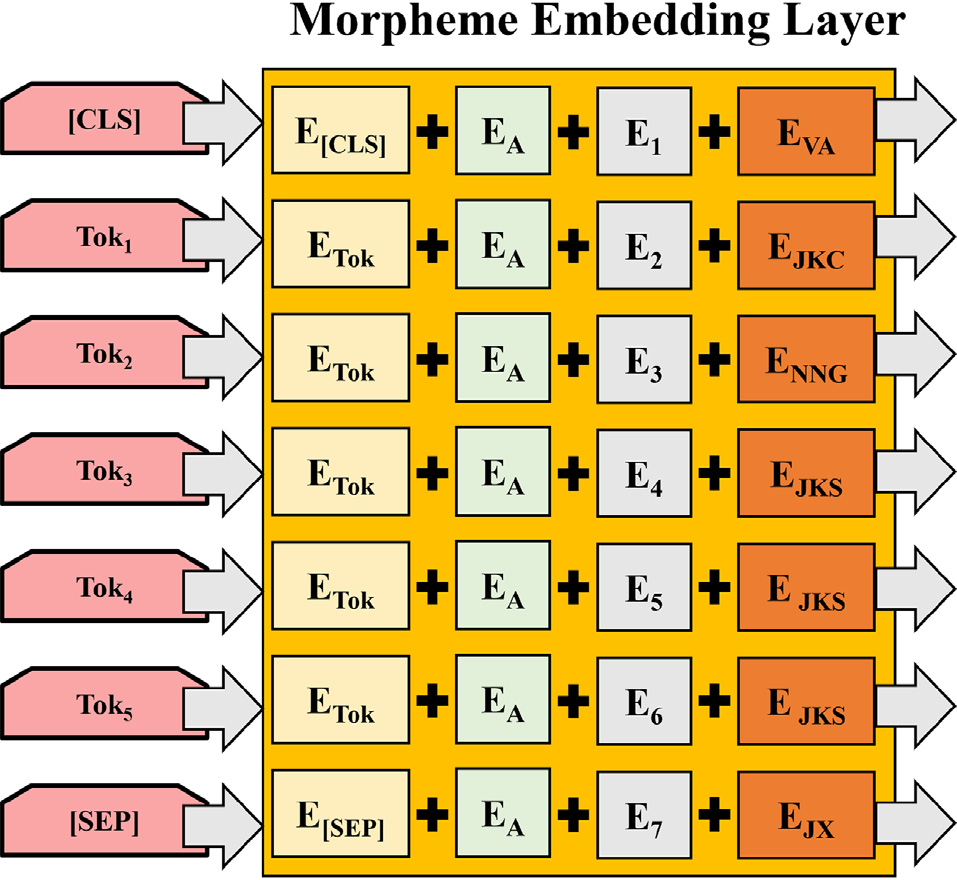
KRongBERT에서는 기존 BERT 모델에서 사용한 token embedding, segment embedding, positional embedding에 morphological embedding을 추가합니다. 영어나 중국어같은 고립어에서는 positional embedding만으로 의미 정보를 줄 수 있었지만, 한국어와 같이 형태소가 의미에 큰 영향을 주는 언어의 경우 별도로 morphological embedding이 필요합니다.
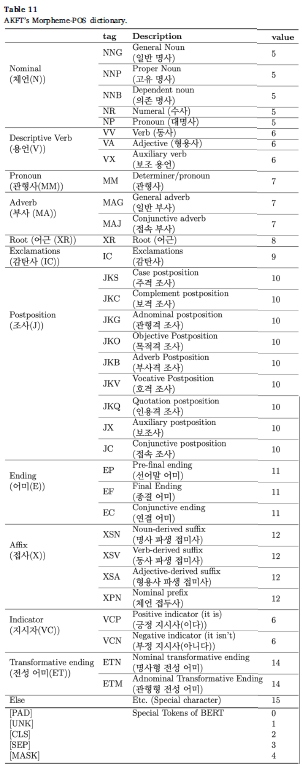
morphological embedding은 품사 토큰으로 이뤄져 있고, 형태소-품사 사전을 이용해 미리 정의된 16개의 품사 토큰을 참조합니다.
다음은 품사 토큰 리스트입니다.
💡 Training objectives
KRongBERT는 Masked Language Modeling(MLM)과 Sentence Order Prediction(SOP)을 objective로 훈련됩니다.
MLM은 입력 문장에서 랜덤으로 15%의 토큰을 뽑고, 그 중에서 80%는 [MASK] 토큰으로, 10%는 랜덤 토큰으로, 나머지 10%는 바꾸지 않고 모델로 하여금 예측하게 합니다.
SOP의 경우 [CLS] 임베딩을 사용하여 두 개의 문장이 순차적으로 연결되었는지 예측과 실제 문장을 비교합니다.
최종적으로, loss는 다음과 같이 계산됩니다.
해당 loss를 사용하므로써, 모델은 각 토큰의 문맥적 의미와 문장의 올바른 순서를 포착할 수 있게 됩니다.
✔️ Experiments
💡 Comparision models
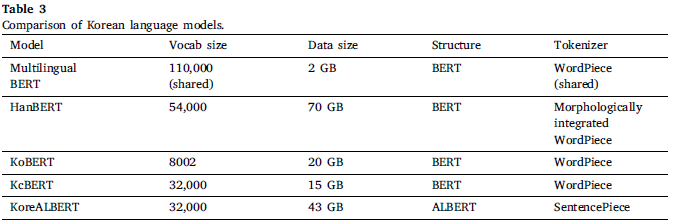
💡 Evaluation benchmarks
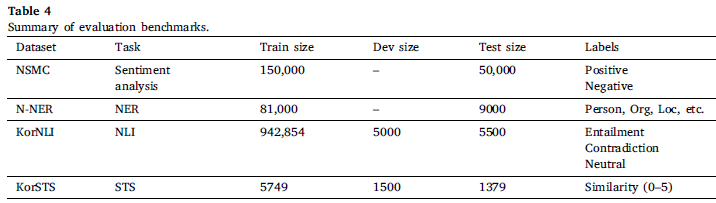
💡 Experimental setup
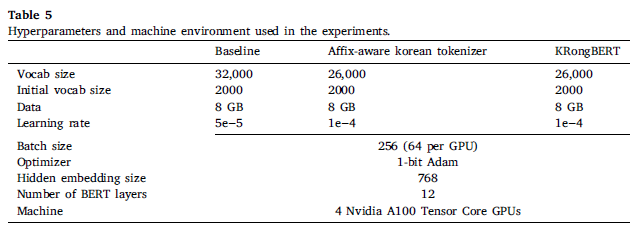
💡 Results and discussion
실험은 총 두 가지를 진행하였습니다.
-
KRongBERT의 tokenizer가 다른 SOTA tokenizer보다 OOV를 더 잘 다루는가?
-
downstream task에서 성능이 잘 나오는가?
1. Performance comparision for handling out-of-vocabulary issues
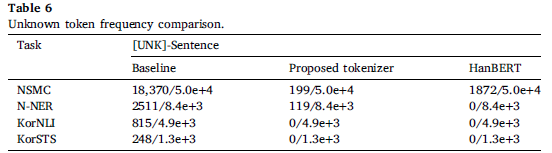
표에서 알 수 있듯, KRongBERT의 tokenizer가 baseline, HanBERT보다 OOV가 훨씬 적습니다. 또한, KRongBERT의 vocab은 26,000개 정도로 54,000개 vocab을 가진 HanBERT보다도 작지만, OOV 문제에서 더 좋은 성능을 보입니다.
2. Evaluation of the morpheme embedding
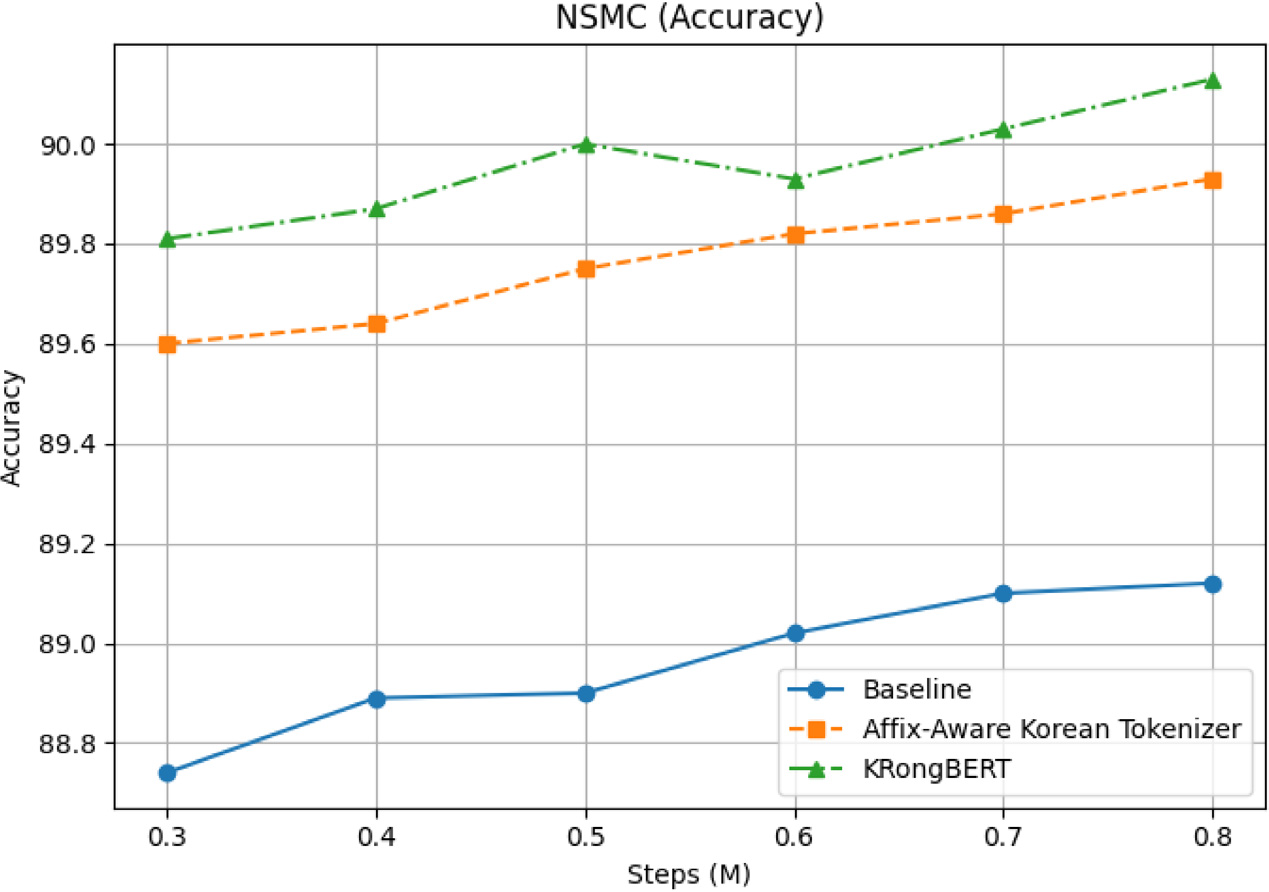
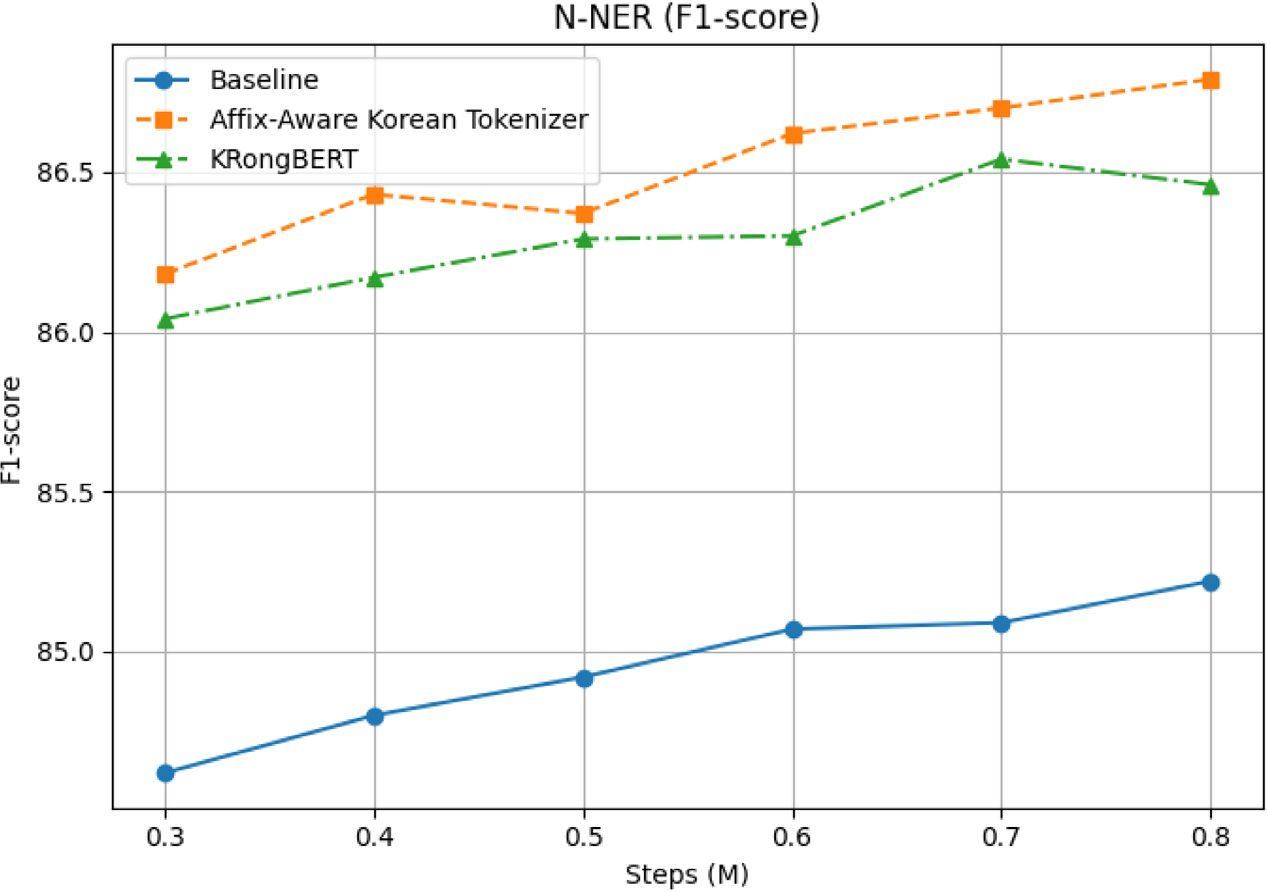
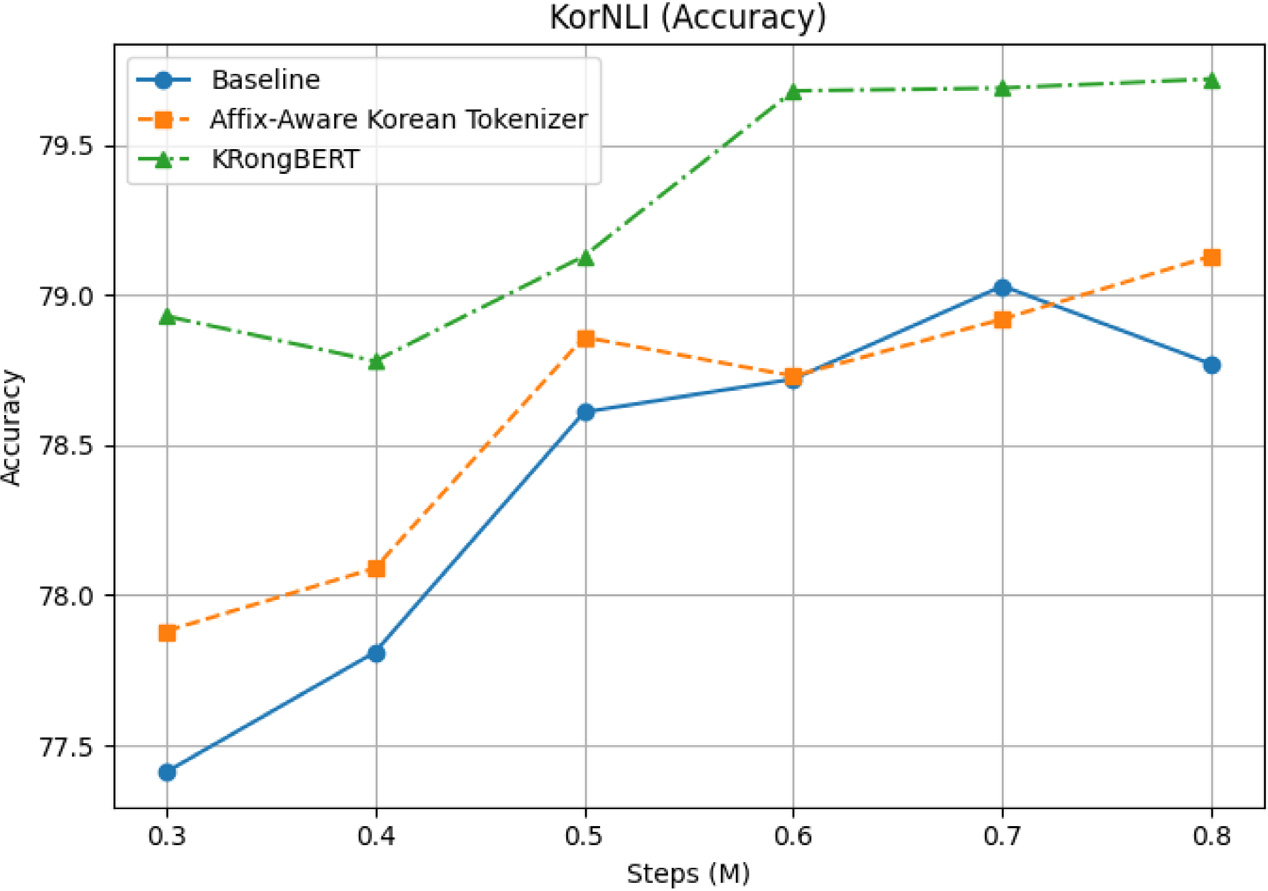

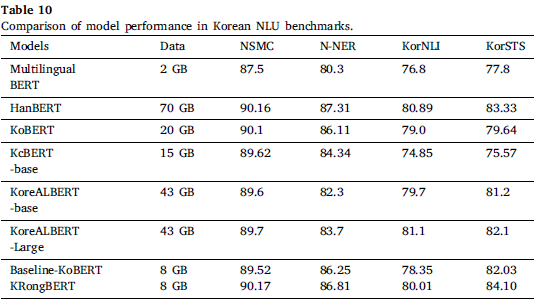
적은 데이터임에도 불구하고 전반적으로 뛰어나거나 우수한 성능을 보이는 것을 확인할 수 있습니다.
