
✔️ Introduction
현대 Generative Language Models(GLMs)은 우리 생활에서 여러 task를 수행합니다. 대부분의 경우, 모델 크기를 늘려서 목표를 달성하는데 이 경우 높은 추론 비용이 발생하기 마련입니다. 이러한 추론 시간을 최적화하기 위해서 tokenizer의 중요성은 높아지고 있습니다. tokenizer는 텍스트를 시퀀스 단위로 잘라 모델의 처리를 돕기 때문에, 모델이 자연어를 이해하고 처리하는데 핵심적인 역할을 합니다. 또한, GLMs은 보통 추론 단계 하나당 토큰을 하나씩 생성하기 때문에, 같은 문장이더라도 적은 토큰을 소모하는 것이 추론 시간을 줄일 수 있습니다.
즉, 단어 당 토큰의 수인 fertility를 줄이는 것이 성능 향상의 핵심입니다.
하지만 기존 연구는 성능 향상에만 치중되어 있어 높은 추론 비용을 소모했습니다. 따라서 연구에서는 token fragmentation을 최소화하는 한국어 토크나이저 개발을 목적으로 두었습니다. 의미 단위들을 쪼개는 걸 줄이기 위해 한국어 문법을 고려한 rule을 기반으로 한 pre-tokenization 과정을 도입했습니다. 또한 branching entropy 기반 방법론을 사용하여 낮은 fertility와 높은 모델 성능을 보였습니다.
✔️ Methods
💡 Pre-tokenization for Korean
pre-tokenization은 입력 문장을 문자, 공백 등의 기준으로 작은 단위로 쪼개는 것을 말합니다. 가령 "Just drank 2 cups of coffee!"라는 문장은 "Just+drank+2+cups+of+coffee+!"로 pre-tokenized될 수 있습니다. 이런 분할은 모델로 하여금 의미 단위 간의 관계를 더 잘 학습할 수 있게 합니다. 하지만 과하게 분할하게 되면 토큰 수가 증가하므로 전체 모델 성능에 악영향을 줄 수 있습니다.
fertility를 줄이기 위해 pre-tokenization은 text를 큰 의미 단위로 쪼개는 과정이 되야 합니다. 가령 숫자 + 단어인 2 cups을 한번에 처리한다면, 성능 향상에 도움이 될 것입니다. 하지만, 관련 없는 단어를 무작위로 합치는 경우를 고려해야합니다. 그럴 경우 모델 성능에 악영향을 미치기 때문입니다.
따라서 논문에서는 한국어의 문법적 성격을 고려하여 두 단계의 pre-tokenization 패턴을 제시했습니다.
1. Whitespace-connected Korean words are treated as a single chunk
한국어에서 공백문자는 쓰이지만 없어도 의미 이해에 영향을 주지 않습니다. 가령 점심 시간은 점심시간으로 쓰여도 같은 뜻으로 이해됩니다. 따라서 토큰 수 감소를 위해 이런 단어들은 하나로 취급합니다.
2. Sentence-final punctuation, such as '.', '?', and '!', is merged with the preceding word
한국어는 교착어이고 종결어미가 구두점과 밀착하게 연관이 있습니다. (가령, '-니다'는 '.'과 '-니까'는 '?'과 연결됩니다.) 따라서 문장의 끝부호는 단일 단위로 처리하지 않고 앞의 단위와 합쳐서 고려합니다.
논문에선 이러한 두 가지 패턴을 정규 표현식으로 구현하였습니다.
(?: ?\p{L}+)+(?:[.?!])?
💡 Language-aware Seed Vocabulary
pre-tokenization 단계에서 긴 단위로 텍스트를 나누는 건 추론 효율에 도움이 되지만, 잘못 디자인된 경우 의미 없는 토큰을 생성할 수 있습니다. 따라서 논문에서는 특정 형태론적 기준을 만족하는 경우만 vocab의 토큰으로 포함하게 하였습니다.
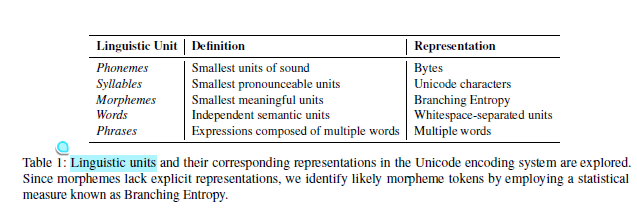
다음과 같은 언어학적 유닛들과 유사한 토큰만 추가하게 하여 형태론 기반의 vocab을 구축하였습니다. 각 언어학적 유닛들은 유니코드 인코딩 시스템과 매칭됩니다.
음소의 경우 음절이 유니코드 문자로 치환되기에 직접적으로 매칭되진 않습니다. 논문에서는 한국어 음절이 초성, 중성, 종성으로 이뤄져있다는 점에서 착안하여 음소를 바이트로 설정하였습니다. 그리하여 바이트가 모여 음절인 유니코드 문자로 이뤄지게 대응하였습니다.
논문에선 표현력을 높이기 위해 각 언어학적 유닛들의 substring들을 포함하는데, 이때 substring은 바로 아래 단계의 단위들로 나눠져야만 추가가 가능합니다.
가령, "안녕하세요"라는 단어를 생각해보면, 바로 아래 단계인 음절(유니코드 문자)만으로 이뤄진 substring만 허용됩니다. 따라서 "안녕"은 허용이 가능하고, "안녕+ㅎ"은 허용되지 않습니다.
seed vocab은 각 문장을 하나의 문자열로 간주하는 것에서 시작됩니다. 그 후, 가능한 바이트 단위 sub token 문자열을 추출하고 불필요한 토큰들을 제거합니다. 이때 공백 문자의 처리 방법은 SentencePiece의 방법을 따라 공백을 토큰 앞에 붙이고, 그럼에도 남은 공백문자는 단어로 처리했습니다. 또한, 형태론적 조건들을 만족하게 하여 final vocab에는 제시한 기준을 만족한 토큰들만 존재하게 하였습니다.
vocab을 구성할 때 형태소 분석을 별도로 진행하지 않는데, 이는 한국어의 공백문자가 모든 형태소를 분리할 수 없기 때문입니다. 대신에 token scoring 단계에서 형태소 정보를 합쳐 형태론적으로 의미 있는 토큰인지 평가합니다.
💡 Branching Entropy
이전 한국어와 같은 교착어 연구에선 형태소 분석기를 통해 형태소와 유사한 토큰을 생성하는 방법이 제시되었습니다. 하지만, 한국어의 특성 상 단음절 형태소 분석이 많고, 이는 토큰 수 증가로 이어지기에 branching entropy를 도입하여 토큰이 확률적인 특징을 드러내도록 하였습니다.
🤔 Branching Entropy?
단어의 내부에서는 uncertainty, 즉 entropy가 줄어들고 단어 사이 경계에서는 증가합니다. 가령 "대한민"이라는 문자열이 제시되었을 때는 뒤에 "국"이 올 것을 쉽게 예측할 수 있지만, "대한민국" 뒤에는 어떤 것이 올 지 쉽게 예측하기 어렵습니다. 식은 다음과 같이 정의됩니다.
branching entropy는 타겟 토큰과 인접한 char들의 다양성을 계산합니다. 하지만, 한국어에서는 같은 char(같은 음절)여도 문맥에 따라 의미가 달라지는 경우가 많습니다. 가령, 그 말이 달린다와 그 말은 틀렸어를 살펴보면 둘 모두 그 말이 쓰이지만 의미하는 바는 전혀 다릅니다. 때문에 논문에서는 branching entropy를 토큰 가 등장하는 전체 문장에 대한 다양성으로 설정합니다.
는 주어진 토큰이고, 는 문장들의 집합입니다. 의 경우 Unigram Tokenizer에서 제시한 EM 알고리즘을 사용하여 계산합니다.
각 문장 는 여러 segmentation으로 나눠집니다. 가 문장 의 가능한 segmentation이라 하고, 를 segmentation의 가중치라 하면, 해당 가중치는 모든 토큰들의 확률곱으로 이뤄집니다.
이 값들을 정규화하면, segmentation 확률 를 구할 수 있게 됩니다.
는 를 포함한 모든 segmentation 의 합이므로, 베이즈 정리에 의해 를 구할 수 있습니다.
또한, vocab 크기를 줄이기 위해 흔히 생기는 단어는 단일 토큰으로 처리해야할 필요가 있습니다. 따라서 를 score에 반영해서 vocab을 구성하도록 하였습니다.
해당 과정을 알고리즘으로 정리하면 다음과 같습니다.
💡 Tokenization Method
논문에서는 Unigram Tokenizer처럼 토큰 확률을 계산했고, 비슷한 segmentation 전략을 사용했습니다. 입력 문장이 있을 때 토큰들의 로그 확률의 합을 최대화하는 tokenization을 선택하게 하였습니다.
✔️ Experiments
💡 Experimental Setup
논문은 BPE, Unigram, BPE + Mecab-Ko와 Thunder-Tok을 비교하였습니다. 위의 표 2는 해당 토크나이저들의 토크나이징 방식을 비교한 것입니다.
pre-tokenization 단계에서 GPT-2의 방식을 차용하여, 규칙 기반 regular expression을 수행했습니다. "-'s"나 "-'re", 숫자, 구두점, 공백문자들을 처리하였습니다. 또한 Unigram의 경우 최대 토큰 길이를 32 바이트로 하였고, 나머지 설정은 기존 설정과 동일하게 했습니다.
언어 모델은 LLaMA3를 사용하여 360M일 때와 1.5B 파라미터일 때 토크나이저 성능을 비교헀습니다. 해당 모델들은 HPLT v2.0 데이터셋을 학습하였습니다. 반면, 토크나이저들은 해당 코퍼스의 1M개의 샘플 문서들로 개발되었습니다.
평가의 경우, KoBEST HeelaSwag, KoBEST COPA, Korean ARC-easy, Korean LAMBADA를 벤치마크 데이터셋으로 사용하였습니다.
💡 Tokenizer Fertility
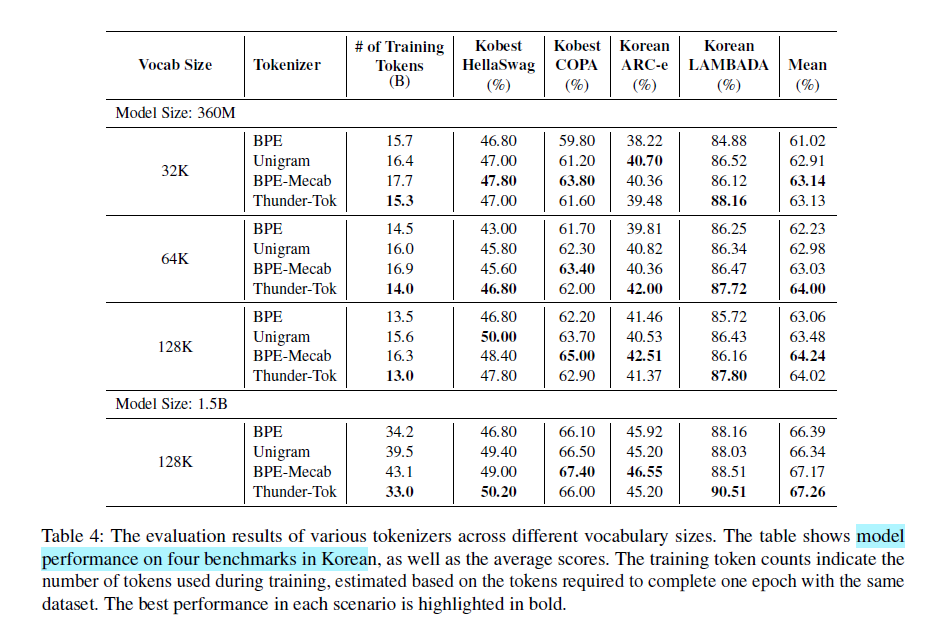
다음은 128K로 vocab 크기를 고정하고 fertility를 측정한 결과입니다. fertility는 단어 당 평균 토큰 수로 정의하였습니다. 일반화 성능을 위하여 학습 데이터셋뿐만이 아니라 다양한 벤치마크 데이터셋에 대해 fertility를 측정했습니다.
Thunder-Tok는 여러 데이터셋에서 가장 낮은 fertility를 보였으며, 평균적으로 10%의 향상을 보였습니다. 이는 10% 이상의 추론 비용 감소가 가능하다는 뜻이기도 합니다.
💡 Downstream Performance
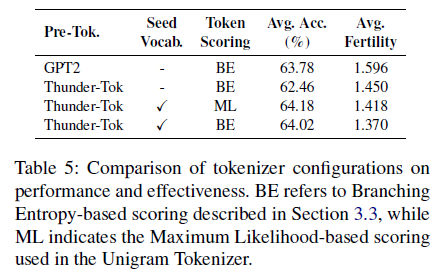
360M 모델의 경우 vocab 크기는 32K, 64K, 128K로 설정하고, 1.5B의 경우 128K로 실험하였습니다. 모델 성능은 zero-shot 설정에서 진행하였고, test set 크기에 따른 가중 평균을 적용하였습니다.
표 4에서 볼 수 있듯, Thunder-Tok가 모든 설정에서 가장 높거나 비교할만한 성능을 보입니다.
💡 Ablation Study
논문에서는 어떤 요소가 tokenizer 성능에 영향을 주는지 확인하기 위해 ablation study를 진행했습니다. 비교한 부분은 다음과 같습니다.
-
Thunder-Tok's pre-tokenization 방법 vs GPT-2에서의 pre-tokenization
-
language-aware vocab vs N-gram 기반 vocab
-
token score: Branching Entropy vs maximum likelihood
모든 실험은 128K 고정 vocab과 360M 파라미터의 언어 모델로 진행했습니다.
결과는 Thunder-Tok에서 수행한 pre-tokenization을 사용하는 것이 fertility를 9% 가까이 줄였지만, 모델 성능 역시 평균 1.5% 정도 감소했습니다. GPT-2와 달리, Thunder-Tok은 텍스트를 multi-word expression으로 분리할 수 있어서, 의미 없는 표현들이 많이 생길 수 있기 때문입니다. 이러한 문제를 해결하기 위해 언어학적 유닛과 유사한 토큰들만 추가하는 기법을 적용하였고, 그 결과 fertility는 감소하고 모델 성능은 약 1.5% 향상하였습니다.
branching entropy를 token score에 적용하는 것은 성능이 소폭 감소하였으나 fertility를 대폭 감소하였습니다.
✔️ Conclusion & Limitations
논문에서 제시한 방법론은 한국어에 맞춤 제작되었기에 다른 언어에는 조정이 필요합니다. 규칙 기반 pre-tokenization과 seed vocab의 구축은 한국어의 형태론적 특징을 참조해서 만들었기 때문입니다. 또한, 1.5B 모델밖에 적용을 못했기에 더 큰 파라미터의 모델에선 어떤 결과가 나올지 미지수입니다.
