
이전 리뷰에서 이어집니다.
[NLP Paper Review] Transformer -1
✔️ Training
💡 Traning Data and Batching
논문에서는 두 가지 기계번역 task를 실험했습니다.
- 영어 - 독일어 번역
- 영어 - 프랑스어 번역
사용한 데이터셋과 인코딩 방식은 각각 다음과 같습니다.
- standard WMT 2014 English-German dataset (4.5 milion sentence pairs)
- BPE(Byte Pair Encoding)으로 인코딩된 37000개의 source-target 단어사전을 사용합니다.
- WMT 2014 English-French dataset (36M sentences)
- 32000개의 wordpiece 기반 단어사전을 사용합니다.
문장 쌍은 비슷한 길이로 배치되며, 대략적으로 25000개의 소스 토큰과 25000개의 타겟 토큰으로 배치가 구성됩니다.
💡 Hardware and Schedule
NVIDIA P100 GPU 8개로 실험을 진행했습니다. transformer base model은 training step에 0.4초가 걸리고, 총 100,000 step을 12시간에 걸쳐 학습했습니다. big model은 1 step에 1초가 걸리고 총 300,000 step을 3.5일에 걸쳐 학습하였습니다.
💡 Optimizer
논문에서는 Adam optimizer를 사용하였습니다. 사용한 hyperparameter는 다음과 같습니다.
Adam 식
Adam Hyperparameter
learning rate 조정은 다음과 같습니다.
warmup step 구간일 때는 step에 비례하여 learning rate가 선형으로 증가했다가 step이 커질수록 감소합니다. 의 설정값은 4000입니다.
또한, 모델 차원이 커져도 가중치 스케일이 커지기에 learning rate에 을 곱해줍니다.
💡 Regularization
논문에서는 학습 중 세 가지 형태의 정규화를 적용합니다.
- Residual Dropout
: sub layer의 입력이 더해지고 정규화되기 전, sub layer의 출력에 dropout을 적용합니다.
또한, embedding과 positional encoding을 더한 값에도 dropout을 적용합니다. 이는 입력 단계에서 발생할 수 있는 과적합이나 편향을 방지하기 위해서입니다.
dropout을 적용할 비율 은 입니다
- Label Smoothing
: 정답 label의 값을 1로 설정하지 않고 으로 설정하여 confident를 줄입니다. 이는 perplexity를 악화시키지만, accuracy와 BLEU score를 올려줍니다.
설정된 는 입니다.
✔️ Results
💡 Machine Translation
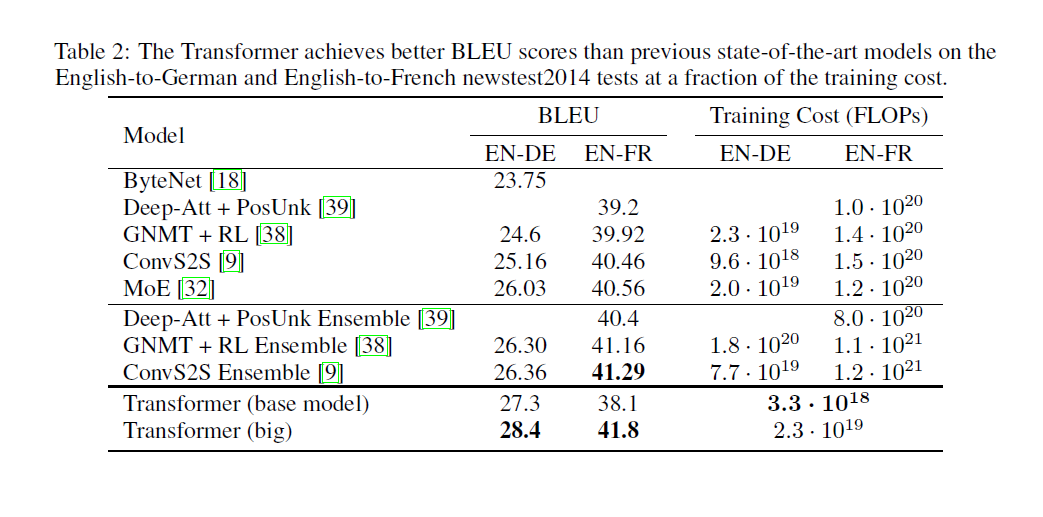
영어-독일어 번역 task에선 big transformer 모델이 기존 BLEU score보다 2.0이나 높은 결과를 보여주며 SOTA를 달성했습니다. base 모델 역시 학습 비용을 제외하고 모든 측면에서 기존 모델을 뛰어넘는 결과를 달성했습니다.
영어-프랑스어 번역에서도 기존 앙상블 모델보다 1/4 수준의 학습 비용으로 BLEU score 41.8을 달성했습니다.
base 모델의 경우 마지막 5개의 checkpoint 평균을, big 모델의 경우 마지막 20개 checkpoint 평균으로 만들었습니다.
또한 beam size가 4인 beam search를 사용했고, length penalty 을 사용하여 조정했습니다. 해당 값들은 development set에서 실험적으로 선택되었습니다.
최대 추론 길이는 입력 길이의 50을 더한 값으로 하되, 가능하면 일찍 끝내게 하였습니다.
💡 Model Variations
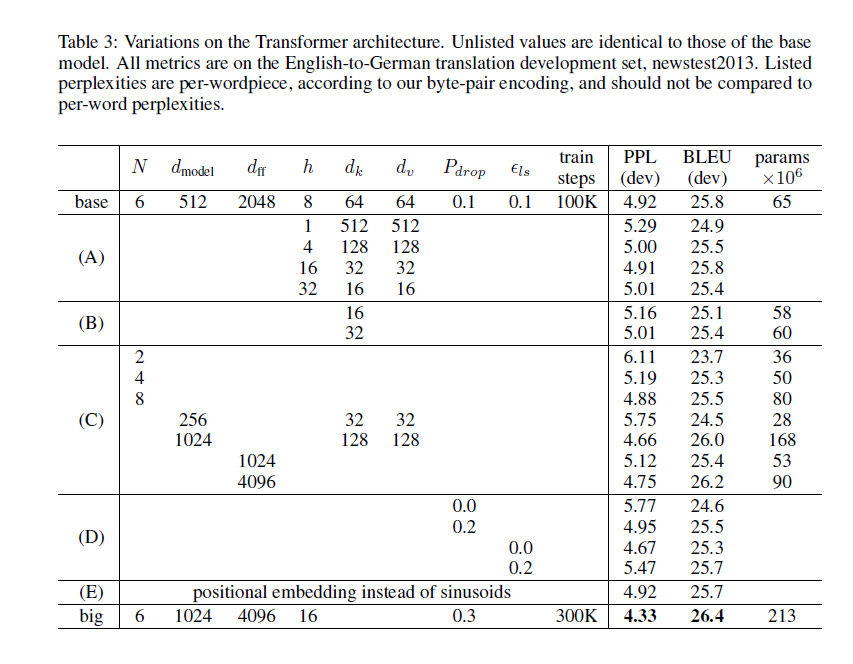
논문에서는 hyperparameter 설정에 따른 영어-독일어 번역의 성능을 비교하였습니다. development set에는 newstest2013을 사용했습니다. 전과 달리 checkpoint 평균은 쓰지 않았습니다.
💡 English Constituency Parsing
transformer 모델의 성능을 측정하기 위해서 영어 구문 분석 task를 실험했습니다. 해당 task는 출력이 문법적 제약을 갖고 있고, 입력보다 긴 길이를 갖는다는 것이 특징입니다. 또한, 데이터 수가 적어 RNN 계열 seq2seq 모델들은 좋은 결과를 갖기 어려웠습니다.
인 4-layer transformer를 Wall Street Journal(WSJ) 40K 문장을 학습했으며, BerkleyParser로 자동 생성한 17M 문장들도 semi-supervised로 학습했습니다. WSJ만 사용하는 경우 vocab 크기를 16K로, semi-supervised의 경우에는 32K로 설정했습니다.
기존 영어-독일어 번역 모델에서 설정이 변하지는 않았으며, 추론에서 최대 출력 길이를 입력 문장 길이 + 300으로, beam size를 21로, 를 0.3으로 설정하였습니다. (WSJ only와 semi-supervised 모두)
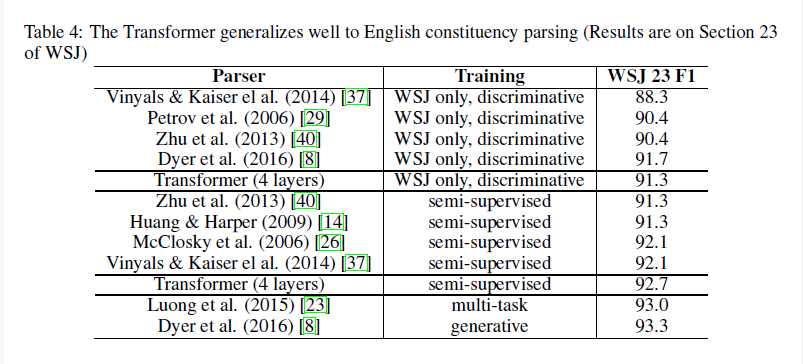
결과는 RNN Grammar를 제외한 모델보다는 높은 성능을 보이는 것을 확인할 수 있습니다.
