
저번 시간에 정수 인코딩을 통해서 텍스트 벡터화에 대해 배웠습니다. 이번 시간에는 정수 인코딩과 같이 대표적인 텍스트 벡터화 기법 중 하나인 원-핫 인코딩에 대해 알아보겠습니다.
🤔 원-핫 인코딩이란?
원-핫 인코딩은 단어 집합의 크기만큼 벡터 차원을 가지고, 해당되는 단어가 있으면 1, 그렇지 않으면 0으로 표현하는 방식입니다. 쉽게 설명하자면 단어 하나를 표현할 때, 단어 집합 전체의 크기의 배열로 표현한다는 것이죠.
예를 들어, 만약 cat, dog, mouse, bird, rabbit 순으로 구성된 단어 집합이 있다면 원-핫 인코딩으로 다음과 같이 표현할 수 있습니다.
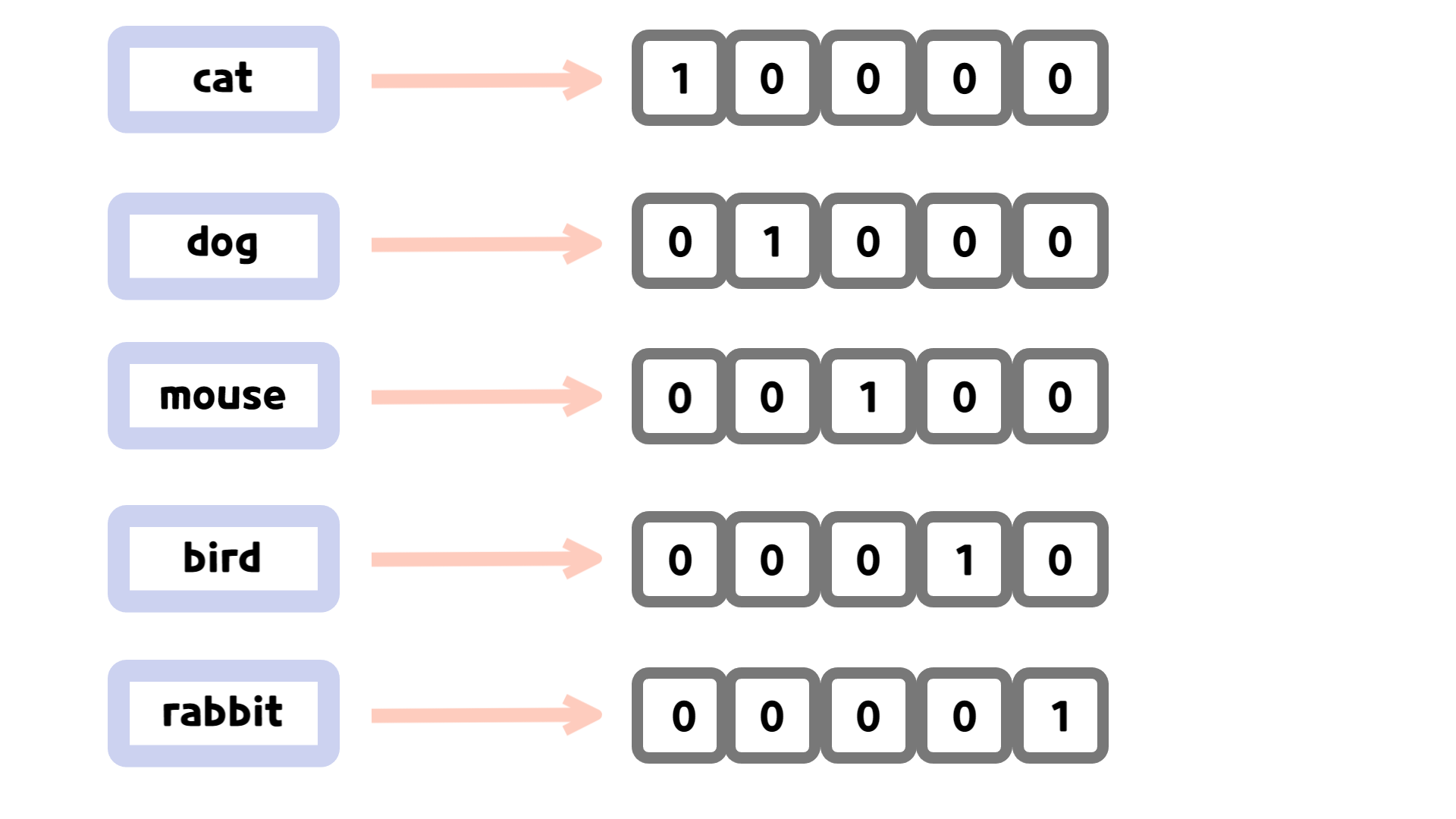
이렇게 원-핫 인코딩을 통해서 컴퓨터는 단어를 빠르게 처리할 수 있지만, 원-핫 인코딩을 사용함으로써 단점도 존재합니다.
우선, 단어 하나 당 단어 집합의 크기를 가지기 때문에 큰 단어 집합을 가지고 있는 경우 공간적으로 비효율적입니다. 또한 원-핫 인코딩의 결과로 단어 간의 유사도를 표현할 수는 없다는 단점을 가지고 있습니다.
💻 원-핫 인코딩의 구현
원-핫 인코딩을 위해서는 먼저 단어들에 대해 정수 인코딩을 진행할 필요가 있습니다.
from nltk.tokenize import word_tokenize
text = "I went to the school"
text = text.lower()
tokens = word_tokenize(text) # 토큰화를 진행합니다.
word_index = {word: i + 1 for i, word in enumerate(tokens)}
# enumerate(): 인자로 넘어온 것을 인덱스와 원소를 튜플로 짝지어 반환
print(word_index)
# 결과
# {'i': 1, 'went': 2, 'to': 3, 'the': 4, 'school': 5}정수 인코딩을 기반으로 해당되는 단어의 인덱스에는 1, 그렇지 않으면 0을 부여하여 원-핫 인코딩을 구현합니다.
result = []
for word, num in word_index.items():
lst = [0]*len(word_index)
lst[num - 1] = 1
result.append(lst)
print(result)
# 결과
# [[1, 0, 0, 0, 0], [0, 1, 0, 0, 0], [0, 0, 1, 0, 0], [0, 0, 0, 1, 0], [0, 0, 0, 0, 1]]함수로 정리하면 다음과 같습니다.
from nltk.tokenize import word_tokenize
def word_to_index(tokens: list[str]) -> dict[str, int]:
return {word: i + 1 for i, word in enumerate(tokens)}
def one_hot_encoding(word_index: dict[str, int]) -> list[list[int]]:
result = []
for word, num in word_index.items():
lst = [0]*len(word_index)
lst[num - 1] = 1
result.append(lst)
return result🔥 tensorflow를 활용한 원-핫 인코딩
tensorflow는 파이썬 라이브러리 중 하나로, 머신러닝 및 딥러닝 관련 기능을 제공합니다. 해당 라이브러리에서는 정수 인코딩과 원-핫 인코딩 관련 함수를 제공하기 때문에 이를 활용하여 원-핫 인코딩을 진행할 수 있습니다.
우선 텐서플로우 라이브러리가 설치되지 않았다면 설치할 필요가 있습니다.
%pip install tensorflow텐서플로우 내 Tokenizer() 클래스, to_categorical() 함수를 사용하여 원-핫 인코딩을 진행합니다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical먼저 Tokenizer() 클래스에 텍스트를 학습시킵니다.
text = "I like studying python."
text = text.lower()
tokenizer = Tokenizer()
tokenizer.fit_on_texts([text]) # 문자열로 넘겨주면 한 글자씩 쪼개기 때문에 리스트의 형태로 넘겨줘야합니다.Tokenizer() 클래스 내 메소드인 texts_to_sequences()를 통해 정수 인코딩을 진행합니다.
print(tokenizer.word_index) # 빈도수에 따라 정수 인코딩된 결과입니다.
int_encoded = tokenizer.texts_to_sequences([text])[0] # 반환값이 이중 리스트이기에 [0]으로 하나만 꺼내옵니다.
# 결과
# {'i': 1, 'like': 2, 'studying': 3, 'python': 4}정수 인코딩된 결과를 to_categorical() 함수의 인자로 넘겨 원-핫 인코딩을 진행합니다.
result = to_categorical(int_encoded)
print(result)
# 결과
# [[0. 1. 0. 0. 0.]
# [0. 0. 1. 0. 0.]
# [0. 0. 0. 1. 0.]
# [0. 0. 0. 0. 1.]]tensorflow로 진행한 원-핫 인코딩은 정수 인코딩의 결과를 그대로 인덱스에 적용하여 기존의 정수 인코딩된 결과의 길이보다 하나 더 긴 것을 확인할 수 있습니다.
