Introduction

무시무시한 '말록'이다..
지난번 링크드 리스트의 기초를 다루는 포스트에서 짤막하게 다뤘었던 '동적 메모리 할당'을 가능하게 만들어주는 할당기(allocator)를 만들어보려한다.
기본적으로 동적으로 메모리를 'Heap'에 할당하기위해 실제로 system call로서 malloc 이 어떻게 작동하는 지를 이해하는데 방점이 찍혀있는 과정이다. 그러므로 직접 unix 단계의 함수를 만드는 것은 아니고
일종의 '시뮬레이션'을 하는 것으로 볼 수 있다.
malloc 함수를 포함하여 realloc, free 등 allocator가 하는 역할을 모두 구현하면 할당기를 구현했다 라고 말할 수 잇을 것이다.
Remind
지난번 포스트에서 정리했었던 '동적 메모리 할당'을 살짝 떠올려보자. 프로그램이 실행되는 런타임동안 (유)동적으로 메모리를 할당해주는 것이 동적 메모리 할당 이었다.
이때, 메모리가 할당되는 영역이 'Heap'영역이었다. 힙은 스택 영역과 다르게 따로 free 를 해주기 전까지는 할당되었던 메모리가 프로그램이 진행되는 동안 반환 되지 않는다. (explicit programming)
이런 힙 영역을 가상메모리 상에서 구현하고 메모리를 필요한 만큼 할당하고, 부족할시 커널에 요청하여 추가적으로 힙영역을 늘리는 것 까지 구현하는 것이다.
mm_init
int mm_init(void)
{
// Create the initial empty heap
if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1)
return -1;
PUT(heap_listp, 0); // Alignment padding
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); // Prologue header
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); // prologue footer
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); // Epilogue header
heap_listp += (2*WSIZE);
// Extend the empty heap with a free block of CHUCKSIZE bytes
if (extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}init 함수는 malloc 함수를 부르기 전에 힙에 sbrk 함수를 통해 가상 힙(?)을 만들어주는 함수이다.
이렇게 만들어진 가상 힙에다가 할당기는 요청하는 메모리를 할당하게 된다.
extend_heap
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
// Allocate an even number of words to maintain alignment
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL;
// Initialize free block header/footer and the epilogue header
PUT(HDRP(bp), PACK(size, 0)); // free block header
PUT(FTRP(bp), PACK(size, 0)); // free block footer
PUT(HDRP(NEXT_BLKP(bp)), PACK(0,1)); // new epilogue header
// Coalesce if the previous block was free
return coalesce(bp);
}extend heap 함수는 말그대로 할당할 공간이 없을경우 (ex: external fragmentation) 힙 자체를 늘리고 늘어난 만큼을 free block 으로 추가해주는 역할을 한다.
mm_malloc
void *mm_malloc(size_t size)
{
size_t asize; // Adjusted block size
size_t extendsize; // amount to extend heap if no fit
char *bp;
// Ignore spurious requests
if (size == 0)
return NULL;
// adjust block size to include overhead and alignment reqs.
if (size <= DSIZE)
asize = 2*DSIZE;
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE);
// search the free list for a fit
// ** We have to make find_fit function & place
if ((bp = find_fit(asize)) != NULL) {
place(bp, asize);
return bp;
}
// no fit found. Get more memory and place the block
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}대망의 말록함수는 생각보다 그리 복잡하지 않다. 그냥 적절한 크기의 free block을 찾고 이를 적절한 방법으로 할당해주면 끝이다. 핵심은 '적절한'을 어떻게 찾을 것이냐 이다.
find_fit with implicit free list
find_fit 함수를 구현하는 방식에서부터 다양한 방법이 존재한다. 우선 free block의 리스트를 구성하는 방법에 따라 implicit free list 와 explicit free list 로 나뉘고 그 안에서 또다시 다양하게 나뉘는데 우선 implicit 을 보자.
implicit 은 블럭의 헤더에 있는 사이즈를 통해 각 블럭을 이동하며 이때 할당여부와 관계없이 모든 블럭을 탐색하는 방식을 말한다.
first fit
static void *find_fit(size_t asize)
{
char *bp;
// what is the actual function of find_fit?
// Finding proper free blocks that can be contain the asize(input value)
// How to find?
// get header of blocks, and calculate to extract some information about that blocks
// the informations are about 'allocation' 'size' 'number of padding blocks'
// and finally return 'block ptr : bp' is HDRP of fittable free blocks
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
{
return bp;
}
}
return NULL; // this means not fit to put.
}
first fit 은 free block을 header의 크기로 계산하면서 할당여부와 상관없이 모든 블럭을 다 탐색하다가 나오는 첫번째 free block에 할당하는 방식이다.
next fit
static void *next_fit(size_t asize)
{
void *bp;
for (bp = last_fit_bp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
{
return bp;
}
}
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0 && last_fit_bp > bp; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
{
return bp;
}
}
return NULL; // this means not fit to put.
}next fit 은 implicit free list 즉, 모든 블럭을 이동하며 탐색하는 것은 동일한데 마지막으로 할당했던 블록을 가리키는 포인터를 기억해놓았다가 다음에는 그 블럭부터 탐색하는 방법으로 전체 탐색속도에 해당하는 'Throughput'을 상당부분 줄여줄 수 있다. (처리 속도가 빨라진다는 말이다.)
find_fit with explicit free list
implicit free list가 마치 포인터를 사용한 array의 선언과 탐색같은 느낌이라면
explicit free list 는 free block 들 만을 모아놓은 linked list 를 구현한 느낌이다.
이때 free block 만을 모아놓기 때문에 상당한 처리속도를 보여준다. 아래 그림은 explicit free list 에서 find fit 을 수행하는 모습이다.
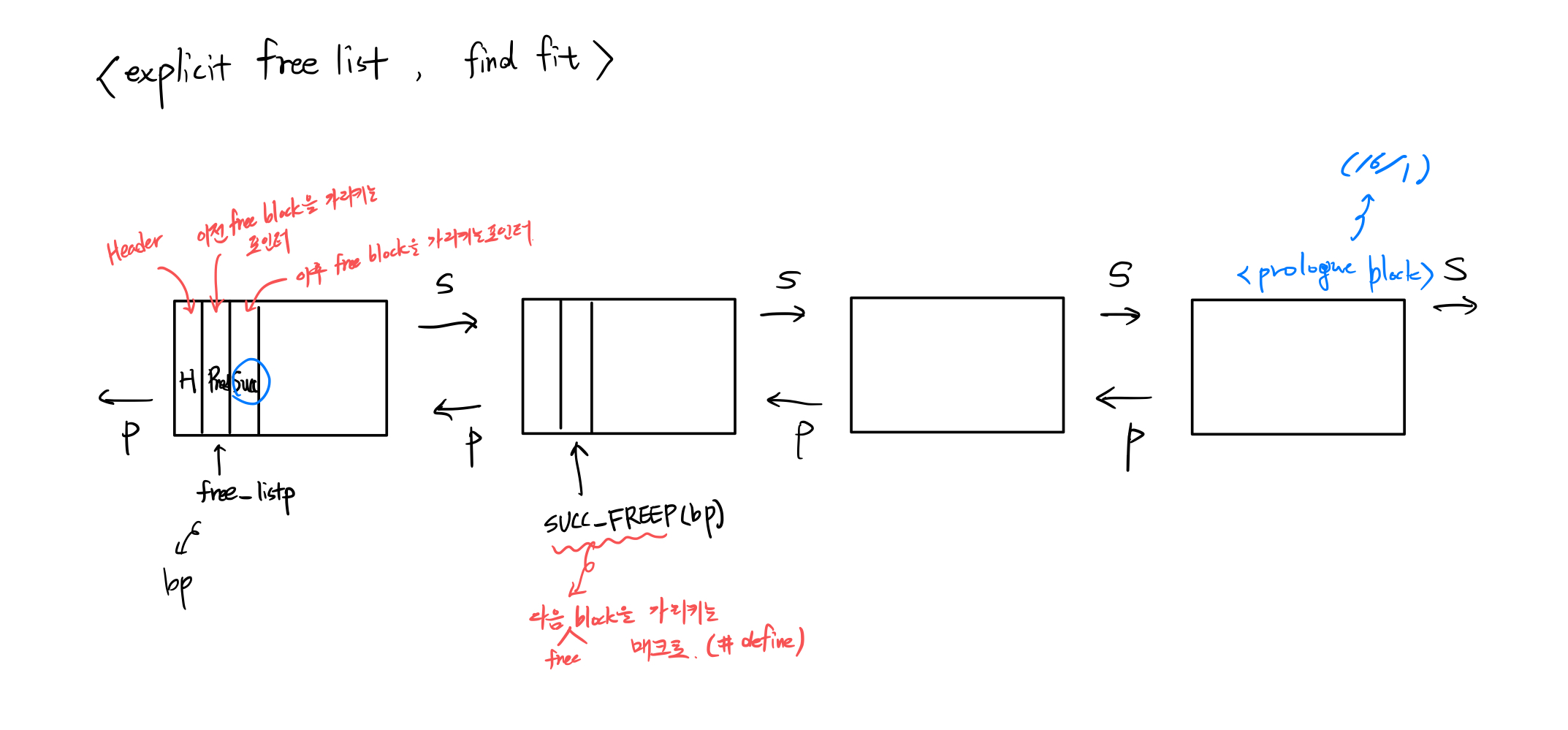
basic explicit free list
static void *find_fit(size_t asize)
{
// first fit
void * bp;
bp = free_listp;
for (bp; GET_ALLOC(HDRP(bp)) != 1; bp = SUCC_FREEP(bp)){
if (GET_SIZE(HDRP(bp)) >= asize){
return bp;
}
}
return NULL;
}
void putFreeBlock(void *bp)
{
SUCC_FREEP(bp) = free_listp;
PREC_FREEP(bp) = NULL;
PREC_FREEP(free_listp) = bp;
free_listp = bp;
}
void removeBlock(void *bp)
{
// 첫번째 블럭을 없앨 때
if (bp == free_listp){
PREC_FREEP(SUCC_FREEP(bp)) = NULL;
free_listp = SUCC_FREEP(bp);
// 앞 뒤 모두 있을 때
}else{
SUCC_FREEP(PREC_FREEP(bp)) = SUCC_FREEP(bp);
PREC_FREEP(SUCC_FREEP(bp)) = PREC_FREEP(bp);
}
}explicit free list 를 구현하기 위해 많은 작업이 필요하지만 그중에 가장 핵심이 되는 함수들만 우선 모아보았다.
사실 함수가 작동하는 방식은 linked list 의 그것과 매우 유사하다. 이 점에 유의해보면 쉽게 이해가 될것이다.
Next Topic... to be continued
segregated free list
Buddy system
