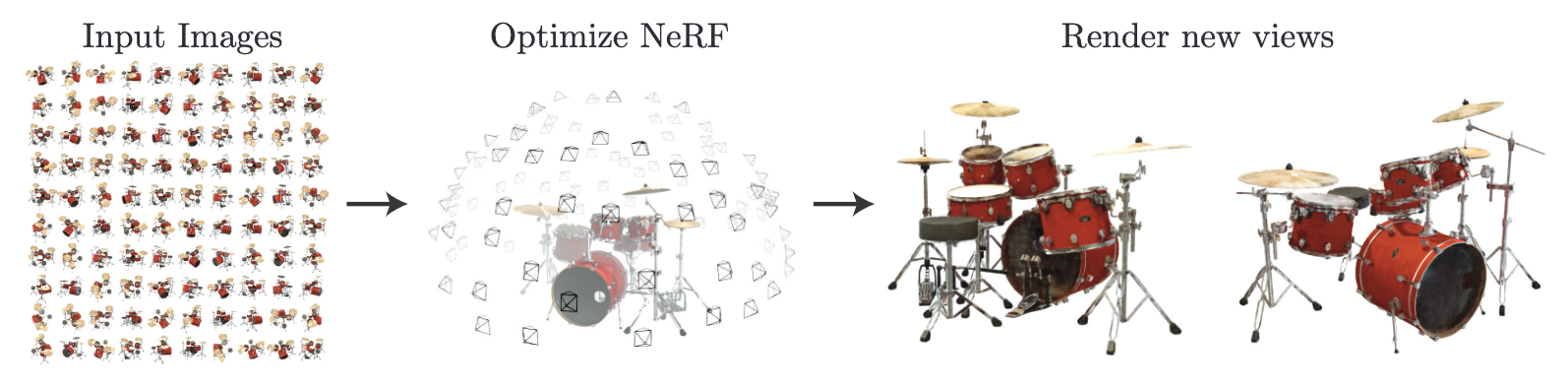
최근 컴퓨터 그래픽스에 대한 관심이 생겨 친구의 권유로 인해 논문 하나를 추천받았다.
그 첫번째 주제인 NeRF 에 대해 리뷰를 해보려 한다.
1. 연구의 목적과 기존의 방법
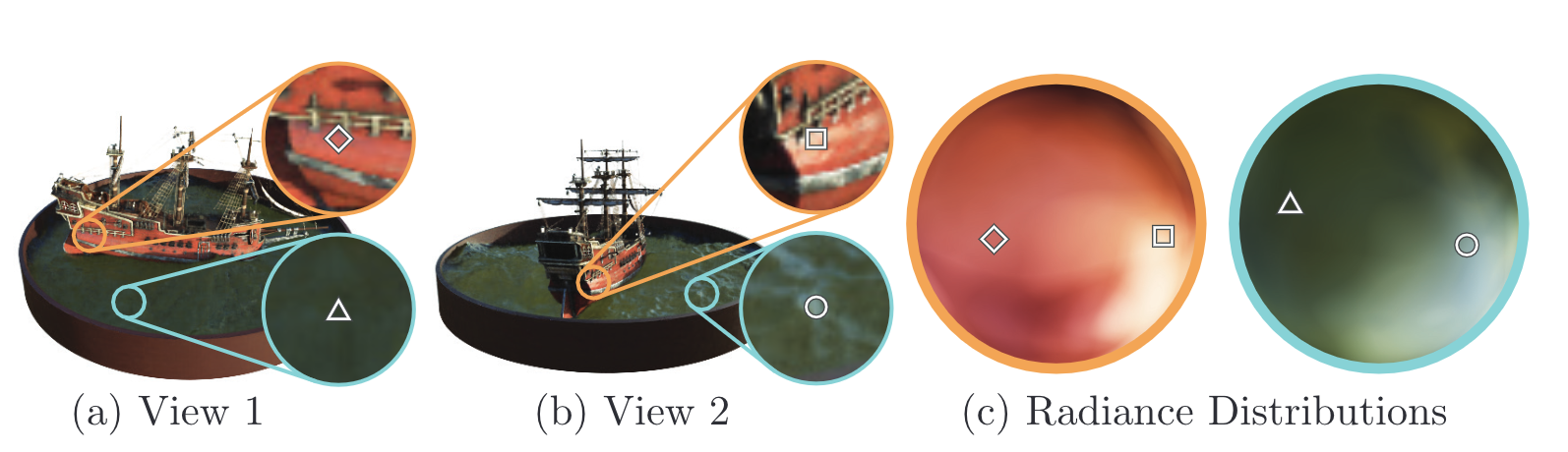
사람이 물체를 인식하는 방법은 2D의 정보를 많이 축적하여 3D 를 머릿속으로 그려 그 물체의 볼륨감과 공간감을 파악한다.
이 과정에서 필요한 방법이 바로 View synthesis task 이다.
하지만 기존까지는 성능이 좋지 않아 저자는 새로운 방식을 제안하게 된다.
New method
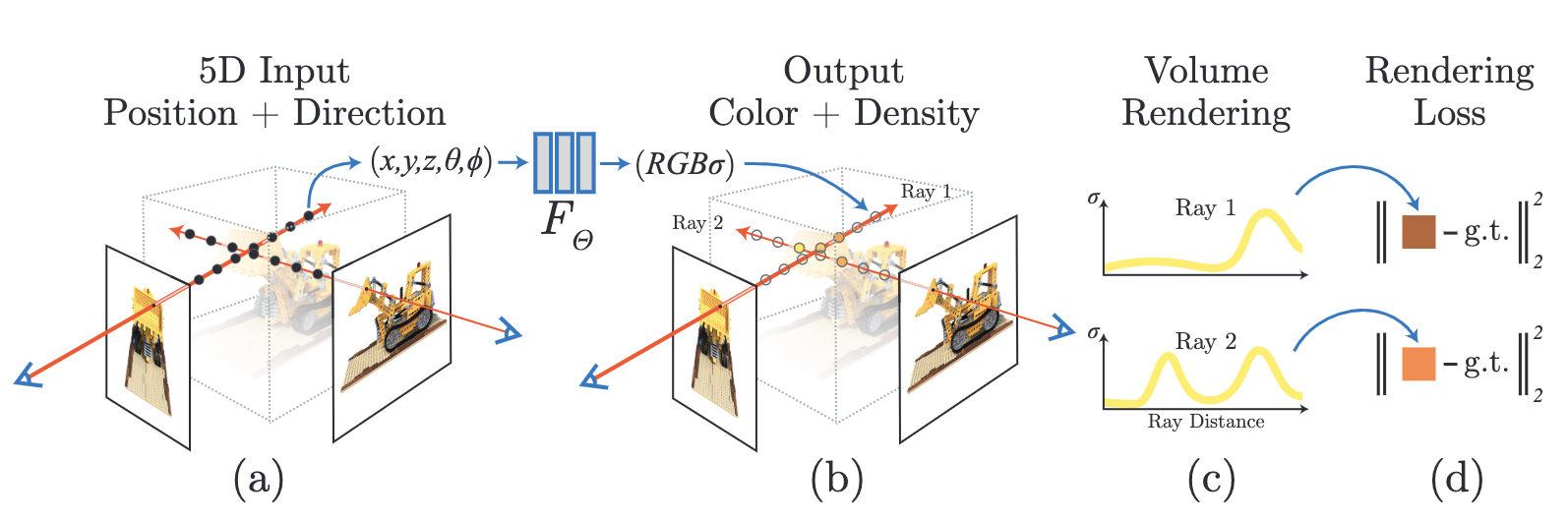
저자는 5차원 데이터,를 입력받아 각 시점을 통해 바라본 객체에서 추출되는 radiance 와 density를 추출해내는 하나의 함수를 고안했다.
,
이때 radiance는 (x,y,z)에서 , 방향으로 방출되는 광원
density는 (x,y,z)를 지나는 레이저에 축적되는 광원을 제어하는 differential opacity 같이 작동하는 밀도
그 과정은 이러하다.
- , 을 입력받아 single volume density와 view-dependent RGB를 출력하는 MLP 설계한다.
- Classical volume rendering techniques를 이용해 MLP로 얻는 RGB와 density 데이터들을 2D 이미지에 축적한다.
- 새로운 관점에서 객체를 바라보았을 때 Scene를 얻을 수 있다.
이를 실질적으로 적용하기 위해서는 다음의 요소를 적용한다.
- 3D point의 sampled set 생성하기(바라볼 관점들을 지정)
- 생성한 sampled set과 sampled set에 해당하는 2D viewing direction을 MLP에 넣어 해당 위치에서 바라본 객체의 color와 density 얻기
- classical volume rendering techniques으로 휙득한 color와 density를 2D 이미지에 축적하기
-> 이 두 말은 근본적으로 같다.
위 그림은 말로 설명한 부분을 그림으로 설명한 모식도 이다.
더 나아가 논문의 저자는 NeRF를 수행하는 과정에서 미분(differential)이 가능하다고 했다.
해당 지점에서 실제로 관측된 이미지와 MLP로 만들어진 '추측된' 이미지 사이의 에러를 계산해 경사하강법으로 MLP를 최적화 시킬 수 있다는 것이다. 이렇게 여러 관점에서 관측된 이미지의 에러를 줄일 수 있으면 새로운 관점에서 관측될 이미지를 더 정확히 관측할 수 있다.
"what is the MLP?"
MLP : Multi- Layer Perceptron
다층 퍼셉트론은 퍼셉트론으로 이루어진 측 여러 개를 순차적으로 붙여놓은 형태를 의미한다.
MLP는 정방향 인공신경망(FFDNN) 이라고 부르기도 한다.
- 은닉층이 1개 이상 추가된 신경망을 다층 퍼셉트론이라고 한다.
무엇이 문제일까?
저자는 복잡한 scene을 표현하기 위한 NeRF를 최적화하는 basic implementation이 좋지 못한 성능을 보이며 더 많은 sampled set이 필요하다는 사실을 알아내었다.
그래서 positional encoding을 이용하여 , 의 3D 데이터를 변환하고 NeRF에 쓰이는 MLP가 더 높은 주파수를 표현할 수 있게 만들었다.
더 높은 주파수를 쓰는 이유는?
이미지의 저주파 대역은 배경을 표현하고, 고주파 대역은 테두리와 RGB 데이터의 변동이 심해지는 지역을 나타낸다. 따라서 높은 주파수를 표현할 수 있게되면 경계선을 표현하는 능력이 더욱 증가한다는 것을 의미한다.
또한 hierarchical sampling procedure을 도입하여 쿼리의 숫자를 감소시켰고, 고주파의 scene을 표현할 때 필요한 sampled set을 적절한 갯수만큼 선별할 수 있도록 만들었다.
그래서 장점이 뭔데?
NeRF는 우리눈에 사영된 이미지를 이용하여 gradient-based optimization을 수행할 수 있다.
그 이유는 volumetric representation이 장점을 가지고 있기 때문입니다.
또한 복잡한 객체를 모델링 할 때에는 [disvretized voxel grids]로 모델링 할 때 (https://www.researchgate.net/figure/Discretization-of-space-by-means-of-a-three-dimensional-grid-of-voxels-Red-voxels_fig1_259268933)
필요한 cost보다 훨씬 적다는 장점을 가지고 있다.
즉, 작은 용량만 있어도 3D 모델의 scene을 생성할 수 있기때문에 용량 최적화적인 부분에서 큰 이점을 차지한다고 볼 수 있다.
요약
-
MLP 네트워크로 continuous scenes with complex geometry and materials을 표현하는 방식을 제안했다.
-
classical volume rendering techniques 기반의 미분 가능한 렌더링 방식(MLP의 순방향 연산)을 제안. MLP는 렌더링 과정에서 얻은 값과 실제 데이터 사이의 오차를 미분해(미분 가능하므로) parameter 학습을 수행하여 최적화가 가능하게 했다.
-
5차원 입력 데이터를 더 고차원 데이터로 mapping하는 positional encoding을 제안. positional encoding 덕분에 NeRF가 고주파의 scene을 성공적으로 표현할 수 있게 만들었습니다.
이로인해 더욱 화상도가 좋은 사진을 표현할 수 있게 됨.
다음 주제는 Scene representation에 대해서 학습하도록 하겠습니다.

출처 : https://velog.io/@minkyu4506/NeRF-Representing-Scenes-asNeural-Radiance-Fields-for-View-Synthesis-리뷰
Neural Radiance Field Scene Representation
NeRF란 density 와 color(r,g,b)를 출력하는 함수를 만들어 MLP를 구현했다.
이때 측정 위치에서 객체를 바라보는 방향을 직교 좌표계로 구성된 unit vector d 로 표현한다면 다음과 같이 5차원 데이터로 scene를 나타내는 방식을 mapping을 통해 구현할 수 있다.
(X,d) -> (c,) 로 매핑하는 MLP 의 parameter 를 학습시켜 더욱 현실에 가까운 scene을 만들도록 했다.
편향된 학습을 막아주는 하나의 방법
딥러닝에서 학습을 저하시키는 가장 큰 원인은 편향된 학습법에 기인되어 특정 결과값에 원하지 않는 결과가 나오는 경우를 살펴볼 수 있다. NeRF가 수행하는 view sysnthesis에서는 '특정 시각에서 관측되는 scene만 잘 예측하는 경우' 라고 볼 수 있다.
때문에 논문의 저자는 다음의 방법으로 문제를 해결할 수 있다고 보았습니다.
- X를 이용해 volume density 를 예측하기
- X와 d를 모두 사용하여 c를 예측하기
다음의 두 경우는 ReLU를 활성화 함수로 사용하여 진행합니다.
일단 1번의 경우에는 8개의 fully-connected layer로 구성된 MLP가 X를 입력받고 와 256차원의 feature vector를 출력하는 방식입니다.
2번의 경우에는 MLP로 예측한 256차원의 feature vector를 와 concatenate 하고 128개의 뉴런을 가진 fully-connected layer에 넣어 view-independent RGB를 획득하는 방식으로 진행합니다. 다음의 그림을 살펴봅시다.

3. Volume Rendering with Radiance Fields
우리는 현재까지 MLP로 해당 위치에서 바라본 객체의 volume density와 RGB를 획득하는 부분까지의 논의를 진행하였습니다.
앞서 설명한 부분에서 'classical volume rendering techniques'을 이용하여 랜더링을 수행하는 방법에 대해서 이제부터 설명하도록 하겠습니다.
find color to be randering
volume density : X에 존재하는 아주 작은 입자에서 사라지는 레이저가 미분이 가능할 확률
-> 우리가 바라보는 위치에서 나아갈 가상의 레이저가 미분이 될 확률을 volume density로 알 수 있다.
이를 이용하여 객체 일부분을 랜더링 할 떄 사용할 색상을 다음의 식으로 결정할 수 있다.
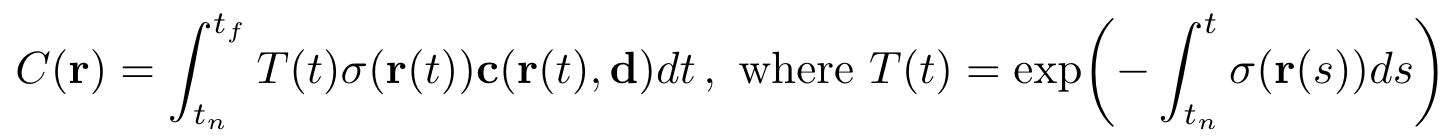
T(t)는 광선이 t_n부터 t 까지 객체를 통과하며 축적된 투과율을 의미한다.
= 'camara ray 가 t_n부터 t구간에 있을 때 객체와 접촉하지 않을 확률'
"NeRF를 이용하여 Scene를 생성하려면 desired virtual camera 가 발사하는 가상의 관성이 접촉하는 픽셀들을 가지고 C(r)을 측정한 값이 필요하다. "
Stratified sampling approach
이제 C(r)을 실제로 계산하기위해서는 어떻게 해야할까?
-Deterministic quadrature : 적분할 구간을 사각형으로 근사한 이후 다시 합치는 기법
이를 개선한 방법이 바로
-strarified sampling approach : C(r)의 적분구간인 [t_n,t_f] 를 일정한 N개의 구간으로 나누고 각 구간에서 임의로 하나씩 뽑아 discrete한 적분의 구간으로 사용하는 방법
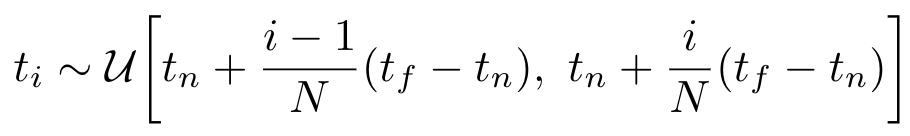
이렇게 적분에 쓸 값을 선별하게 되면 continious position을 처리하는 MLP에서 얻은 값에서 선별하기 때문에 유요한 값들 속에서 sampling을 수행할 수 있습니다.
그렇게 sampling한 t_i를 가지고 적분을 수행하면 더욱 좋은 성능을 발휘할 수 있다.
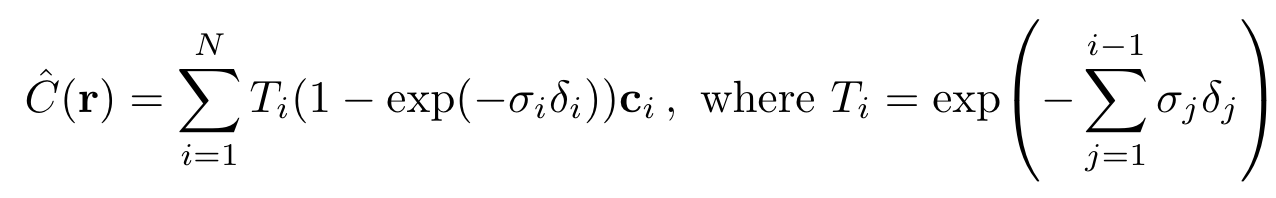
이때 C(r)은 trivially differentiable 하며 a_i = 1- exp(- x _i ) 와 합치기 때문에 값이 감소하는 것을 확인할 수 있다.
Optimizing a Neural Radiance Field
이번에는 Positional Endoding 과 hierarchical smapling procedure에 대해 설명하도록 하겠습니다. 이 둘은 고주파의 복잡한 scene을 표현할 수 있게 도와준 요소들이며 이 둘의 역할을 다음과 같다.
1. Positional endoding : MLP가 고주파 데이터를 처리할 수 있게 도와주며 입력데이터에 적용한다.
2. Hierarchical sampling procedure : NeRF가 고주파 scene을 효율적으로 sample할 수 있게 만들어준다.
이 둘을 하나씩 살펴보도록 하겠습니다.
Positional encoding
현재 발생하는 문제점은 네트워크가 저주파를 처리하는 함수로 학습되기 때문에 고주파 영역의 렌더링 성능이 크게 떨어진다.
이를 위한 해결책은 고주파 함수로 입력 데이터를 더 고차원 데이터로 맵핑하고 네트워크 입력값으로 넣으면 해결될 수 있지 않을까? 라는 생각에서 시작되었습니다.
다시말해 F = F' * 로 재구성 하였을 때 성능이 매우 크게 향상된다는 점을 발견했습니다.
여기서 F' 는 simply a regular MLP이며 는 R차원에서 R^(2L) 차원으로 맵핑하는 함수를 의미합니다.
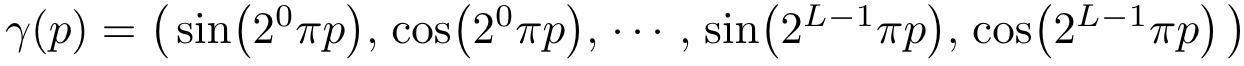
다음의 값은 입력데이터 X=(x,y,z)의 각 원소와 X를 통과하는 camera ray의 unit vector d의 원소 x,y,z 모두 적용하여 해당 값들을 [-1,1] 범위에서 normalize 하게 합니다.
정리하면 NeRF의 positional encoding은 연속적인 입력 데이터의 좌표들을 좀 더 고차원 데이터로 맵핑하여 MLP가 고차원 성분으로 바뀌게 되고, Scene에 있는 테두리들을 좀 더 쉽게 근사할 수 있게 하기위해 사용됩니다.
Hierarchical volume sampling
