

프로젝트 링크입니다.
https://github.com/boostcampwm-2024/refactor-web21-TICLE
문제
현재는 개발 편의를 위하여 typeorm을 이용한 복잡한 쿼리가 작성되어 있습니다.
이 때문에 복잡한 쿼리의 실행 시간이 길어지는 성능 문제가 발생하고 있습니다.
이 쿼리 실행시간을 단축시키고자 합니다.
쿼리 플랜
먼저 쿼리 플랜을 이용하여 이 복잡한 쿼리의 어느 부분에서 성능 병목이 발생하는지 파악하고자 했습니다.
쿼리 플랜 (Query Plan) 이란?
쿼리 실행 계획(Query Plan)은 데이터베이스 관리 시스템(DBMS)이 SQL 쿼리를 처리하기 위해 사용하는 실행 계획입니다.
쿼리 실행에 필요한 단계를 보여주며, 각 단계에서 DBMS가 사용하는 액세스 경로를 보여주고, 쿼리 실행에 필요한 리소스 및 비용 정보를 제공합니다.
이를 통해 DBMS에서 쿼리를 처리할 때 데이터베이스에서 데이터를 검색하고 가져오는 방법을 결정하는데 사용됩니다.
즉, SQL을 실행하는데 있어 사용되는 cost와 어떠한 방식이 가장 적절한지 판단하고, 올바른 플랜 중 평가하여 어떠한 순서와 방식으로 처리할 것인지 계획을 세우고 필요에 따라 변경하여 성능을 개선하는데 사용됩니다.
특징
- 쿼리 실행에 필요한 단계를 보여줍니다.
- 각 단계에서 DBMS가 사용하는 액세스 경로를 보여줍니다.
- 쿼리 실행에 필요한 리소스 및 비용 정보를 제공합니다.
장점
- 성능 문제를 식별하는 데 도움이 됩니다.
- 실행 계획을 변경하여 쿼리 성능을 개선할 수 있습니다.
- 쿼리 최적화를 위한 정보를 제공합니다.
쿼리 플랜 사용하기
먼저 typeorm을 이용하였기에 실제로 어떤 쿼리가 실행되는지 파악해야 합니다.
이를 위해서 typeorm에서 제공하는 logging 기능을 사용하여 실제로 어떤 쿼리가 발생하는지 log를 통해 파악하였습니다.

이렇게 발생한 query를 explain analyze SELECT ... 구문을 통해 mysql에 직접 실행함으로써 쿼리를 분석하였습니다.
약 10만개의 게시글(ticle)중에서 590~600번까지의 게시글을 조회하는 쿼리입니다.
실제 쿼리 분석 표| Operation | Details | Cost/Rows | Actual Time (ms) | Actual Rows |
|---|---|---|---|---|
| Limit/Offset | Limit 10, Offset 590 row(s) | N/A | 793 | 10 |
| Sort | Sorting by ticle.created_at DESC, limit input to 600 rows per chunk | N/A | 793 | 600 |
| Stream Results | Stream results | Cost = 82,582, Rows = 48,111 | 0.791–747 | 100,000 |
| Group Aggregate | GROUP_CONCAT(DISTINCT tags.name, ','), COUNT(DISTINCT applicant.id) | Cost = 82,582, Rows = 48,111 | 0.713–534 | 100,000 |
| Nested Loop Left Join | Join with applicant | Cost = 77,771, Rows = 48,111 | 0.656–463 | 100,005 |
| Nested Loop Left Join | Join with tags | Cost = 60,992, Rows = 48,111 | 0.585–364 | 100,005 |
| Nested Loop Left Join | Join with ticle_tags | Cost = 44,213, Rows = 47,870 | 0.466–259 | 100,000 |
| Nested Loop Left Join | Join with ticle | Cost = 27,459, Rows = 47,870 | 0.456–240 | 100,000 |
| Filter | Filter ticle.ticle_status IN ('open', 'inProgress') | Cost = 10,704, Rows = 47,870 | 0.329–153 | 100,000 |
Index Scan on ticle | Scanning ticle using the PRIMARY index | Cost = 10,704, Rows = 95,741 | 0.324–105 | 100,000 |
Covering Index Lookup on ticle_tags | Lookup on ticle_tags using the PRIMARY index (ticle_id = ticle.id) | Cost = 0.25, Rows = 1 | 0.000741 | 0.001 |
Single-row Index Lookup on tags | Lookup on tags using the PRIMARY index (id = ticle_tags.tag_id) | Cost = 0.25, Rows = 1 | 0.0000749 | 0.001 |
Covering Index Lookup on applicant | Lookup on applicant using the idx_unique_application index (ticle_id = ticle.id) | Cost = 0.25, Rows = 1.01 | 0.000931–0.000935 | 0.01 |
Single-row Index Lookup on speaker | Lookup on speaker using the PRIMARY index (id = ticle.speaker_id) | Cost = 0.249, Rows = 1 | 0.000804–0.000835 | 1 |
실제 쿼리 분석
위 실제 쿼리 분석에서 볼 수 있듯이 약 0.8sec의 쿼리 실행 시간이 측정됩니다.
0.8초는 크게 문제가 없어 보일 수 있지만, 다수의 사용자가 동시에 쿼리를 실행할 경우 서버 부하가 급격히 증가합니다. 또한 데이터의 양이 증가한다면 더 느려질 가능성이 있습니다. 따라서 쿼리 실행 시간 개선이 필요합니다.
+) 데이터를 약 80만개로 증가시킨 경우 60만 번째 데이터를 조회하는 쿼리를 실행시키자 약 7.8초의 쿼리 실행시간을 나타내었습니다.
위의 쿼리 분석표에서 가장 개선이 필요한 부분은 3가지 입니다.
1. offset으로 인해 불필요한 데이터를 조회한 뒤 사용하지 않음
2. 불필요한 80만개의 join
개선
1. 인덱스 적용
created_at은 현재 서비스에서 오름차순, 내림차순으로 정렬하는데 사용하고 있습니다. 이 칼럼에 인덱스가 적용되어 있지 않기 때문에 전체 테이블을 full-scan하고 있습니다. 따라서 O(n)의 시간복잡도가 발생합니다.
created_at에 인덱스를 적용하면 MySQL의 탐색 방법이 변경됩니다. index는 B-Tree 구조로 저장되어 검색 성능을 향상시킵니다. O(log n) 시간으로 탐색시간을 감소시켜 쿼리 실행 시간을 감소시킬 수 있습니다.
또한, index를 적용하면 데이터 삽입 시 인덱스를 업데이트해야 하므로, 삽입 성능이 떨어질 수 있습니다. 하지만 현재 서비스에서 생성보다 조회쿼리가 더 많이 사용되기 때문에 이러한 단점을 상쇄시킨다고 판단하였습니다.
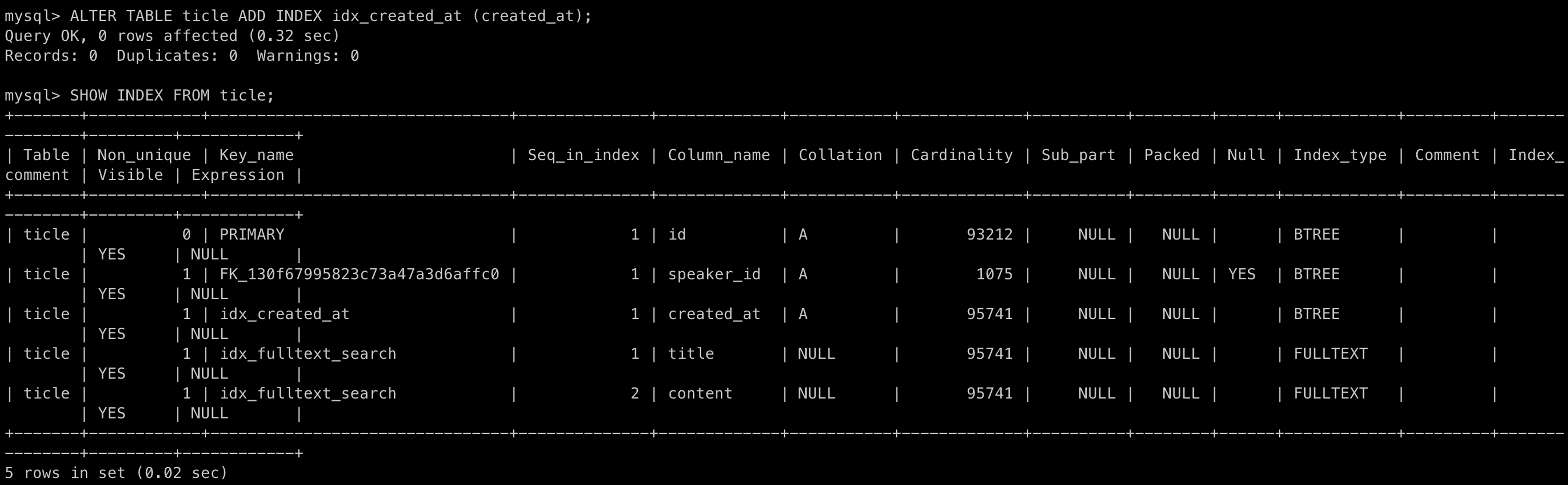
위 그림처럼 created_at 칼럼에 idx_created_at이라는 인덱스를 추가하였습니다.
실제로 Index가 created_at을 이용한 정렬에 영향을 주는지 알아보기 위해 여러 join연산을 제외하고 실행해 보았습니다.
explain analyze SELECT *
FROM ticle
WHERE ticle_status IN ('open', 'inProgress')
ORDER BY created_at DESC
LIMIT 10 OFFSET 599990;10번의 반복 실행 결과는 다음과 같습니다.
- index 적용 전: 평균 5.28초
- Index 적용 후: 평균 3.42초
대략 O(n)의 시간복잡도에서 O(logn)으로 줄어든 것을 눈으로 확인할 수 있었습니다.
하지만, 아직 실제 사용되기에는 부족합니다.
2. 커서 기반 페이지네이션
Offset 기반 페이지네이션의 문제
현재는 페이지네이션이 offset을 이용하여 구현되어 있기에 성능문제가 발생하고 있습니다.
- 불필요한 데이터 조회
80만개의 데이터중 60만번재 데이터를 조회하기 위해서는 60만번까지 조회하고, 필요한 10개의 데이터를 찾은 뒤, 나머지 데이터는 버리게 됩니다. 이 과정은 데이터베이스의 I/O 작업을 증가시켜 쿼리 실행시간을 증가시키고, CPU 및 메모리 자원도 낭비하게 만듭니다. - 중복된 데이터
예시를 들어 설명해 보겠습니다.
게시글 서비스이고, 정렬은 생성순으로 정렬되어 있다고 가정합니다.
- 사용자 A가 1페이지에서 5개의 데이터를 조회했습니다. (게시글 id: 10, 9, 8, 7, 6)
- 다른 사용자들이 새로운 데이터를 생성하여 3개의 데이터가 추가되었습니다. (게시글 id: 11,12,13)
- 사용자 A가 다음 페이지를 보기 위해 2페이지의 데이터 5개를 조회하였습니다.
이때 조회되는 게시글은 아이디가 8,7,6,5,4 입니다.
위 3번과정에서는 사용자 A가 1페이지에서 조회한 8,7,6 번 게시물이 포함되어 있는 (중복된 게시글이 보이는 현상)이 발생합니다.
단순히 페이지를 이동하는 게시글이라면 문제가 없을 수 있지만, 무한 스크롤에서 이용한다면 이러한 중복된 데이터로 인한 문제가 발생합니다.
커서 기반 페이지네이션이란?
커서 기반 페이지네이션은 해당 Cursor를 기준으로 다음 N개의 데이터를 응답하는 방식입니다.
offset 기반 페이지네이션은 원하는 데이터가 '몇 번째'있는가에 집중한다면, 커서 기반 페이지네이션은 원하는 데이터가 '어떤 데이터 다음'에 있는데 집중합니다.
예를들어 100개의 데이터중 55번 데이터 다음의 10개를 달라고 요청하는 것입니다.
주의점
커서 기반 페이지네이션의 기준이 되는 데이터는 unique해야 정확한 결과를 반환합니다.
커서 기반 페이지네이션은 과연 옳은가?
페이지네이션의 UI/UX에 맞추어 페이지네이션을 구현하는게 좋은 사례라고 들었습니다.
저희 팀은 무한 스크롤만 지원하기에 복합 인덱스를 이용한 커서 기반 페이지네이션이 적절하다고 생각했지만, 실제 페이지 번호를 탐색하는 경우에는 커서 기반 페이지네이션이 효과적이지 않을 수 있습니다.
페이지를 바로 건너뛰는 기능(20페이지로 바로 이동)이나 정렬 조건이 다양할 경우 offset 방식이 더 적합할 수 있습니다. 따라서 목적에 맞게 선택해야 합니다.
테스트
먼저 커서 기반 페이지네이션이 제대로 동작하는지 확인해 보았습니다.
80만개의 데이터 중에서 60만개를 created_at < '2025-01-14 17:19:29.551000' 조건으로 skip하여 성능이 개선되었는지 살펴보았습니다.
SELECT *
FROM ticle
WHERE ticle_status IN ('open', 'inProgress')
ORDER BY created_at DESC
LIMIT 10 OFFSET 599990;첫 쿼리에서는 커서가 적용되지 않았기에 7.13초가 소요되었습니다.
이는 created_at이라는 기준값이 없기에 당연한 결과입니다.
SELECT *
FROM ticle
WHERE ticle_status IN ('open', 'inProgress')
AND created_at < '2025-01-14 17:19:29.551000'
ORDER BY created_at DESC
LIMIT 10;위의 created_at의 조건으로 포함된 값은 첫 쿼리에서의 마지막 결과값의 created_at입니다.
위 쿼리문으로 실행하니 0.01초가 소요되었습니다.
이처럼 60만개의 데이터를 조회한 뒤 버리는 과정 없이 한번에 60만번째 데이터부터 조회하기 때문에 엄청난 성능의 차이를 보여주었습니다.
적용
인덱스와 커서 기반 페이지네이션을 적용하고 실제 typeorm으로 작성했던 쿼리를 실행시켜 보았습니다. 쿼리는 아래와 같습니다.
SELECT
`ticle`.`id` AS `ticle_id`,
`ticle`.`speaker_name` AS `ticle_speaker_name`,
`ticle`.`title` AS `ticle_title`,
`ticle`.`start_time` AS `ticle_start_time`,
`ticle`.`end_time` AS `ticle_end_time`,
`ticle`.`created_at` AS `ticle_created_at`,
`ticle`.`profile_image_url` AS `ticle_profile_image_url`,
GROUP_CONCAT(DISTINCT `tags`.`name`) AS `tagNames`,
COUNT(DISTINCT `applicant`.`id`) AS `applicantCount`,
`speaker`.`profile_image_url`
FROM
`ticle` `ticle`
LEFT JOIN `ticle_tag` `ticle_tags` ON `ticle_tags`.`ticle_id` = `ticle`.`id`
LEFT JOIN `tag` `tags` ON `tags`.`id` = `ticle_tags`.`tag_id`
LEFT JOIN `applicant` `applicant` ON `applicant`.`ticle_id` = `ticle`.`id`
LEFT JOIN `user` `speaker` ON `speaker`.`id` = `ticle`.`speaker_id`
WHERE
`ticle`.`ticle_status` IN ('open', 'inProgress')
AND `ticle`.`created_at` < '2025-01-14 17:40:25.124000'
GROUP BY
`ticle`.`id`
ORDER BY
`ticle`.`created_at` DESC
LIMIT 10커서 기반 페이지네이션이 제대로 적용되었고, Timestamp를 이용한 쿼리도 제대로 적용된 것을 explain analyze를 통해 알 수 있었습니다.
-> Index range scan on ticle using idx_created_at over (created_at < '2025-01-14 17:40:25.124000'),
with index condition: (ticle.created_at < TIMESTAMP'2025-01-14 17:40:25.124')
(cost=111657 rows=403892) (actual time=0.419..1209 rows=864763 loops=1)이 두가지를 적용한 결과 약 7초에서 4.46초로 개선되었지만, 아직 부족합니다.
쿼리를 분석한 결과 불 필요한 join이 아직도 많이 발생하고 있습니다.
3. 서브쿼리
앞서 2가지 개선을 진행하였지만 여전히 중첩된 join으로 인해 성능이 저하되고 있습니다.
이 중첩된 join을 제거하기 위해서는 join의 순서를 변경해야 한다고 생각했습니다.
join이 진행된 후 where 절을 이용하여 10개의 게시글을 찾는 것이 아니라, 10개의 게시글을 찾고 join이 필요한 부분만 join하면 해결할 수 있다고 생각하였습니다.
이를 위해서 서브 쿼리를 이용해야 합니다.

서브 쿼리란?
서브 쿼리는 다른 쿼리 내부에 포함되어 있는 SELECT 문을 의미합니다.
서브 쿼리를 포함하고 있는 쿼리를 외부 쿼리라고 하며, 서브 쿼리는 내부 쿼리라고도 합니다.
실행 순서는 서브 쿼리 -> 외부 쿼리 순입니다.
더 자세한 내용은 추후 업데이트 하겠습니다.
장점
서브 쿼리는 아래와 같은 장점들이 있습니다.
- 쿼리의 각 부분을 명확히 구분 가능
- 데이터의 중간 결과를 생성하고, 이를 바탕으로 추가 작업 수행가능 (임시 테이블 x)
- 동적 필터링
서브 쿼리 적용
현재 쿼리에서 서브 쿼리를 적용하여 불필요한 join연산을 줄이고자 하였습니다.
서브쿼리를 이용하여 10개의 게시글을 추출하고, 10개의 게시글에만 필요한 Join을 진행하므로 불필요한 join이 발생하지 않습니다.
성능또한, 위의 4.46초에서 0.02초로 개선되었습니다.
SELECT
limited_ticles.id AS ticle_id,
limited_ticles.speaker_name AS ticle_speaker_name,
limited_ticles.title AS ticle_title,
limited_ticles.start_time AS ticle_start_time,
limited_ticles.end_time AS ticle_end_time,
limited_ticles.created_at AS ticle_created_at,
limited_ticles.profile_image_url AS ticle_profile_image_url,
GROUP_CONCAT(DISTINCT tags.name) AS tagNames,
COUNT(DISTINCT applicant.id) AS applicantCount,
speaker.profile_image_url
FROM (
SELECT *
FROM ticle
WHERE ticle.ticle_status IN ('open', 'inProgress')
AND ticle.created_at < '2025-01-14 17:40:25.124000'
ORDER BY ticle.created_at DESC
LIMIT 10
) AS limited_ticles
LEFT JOIN ticle_tag ticle_tags ON ticle_tags.ticle_id = limited_ticles.id
LEFT JOIN tag tags ON tags.id = ticle_tags.tag_id
LEFT JOIN applicant applicant ON applicant.ticle_id = limited_ticles.id
LEFT JOIN user speaker ON speaker.id = limited_ticles.speaker_id
GROUP BY limited_ticles.id
ORDER BY limited_ticles.created_at DESC;결과
이처럼 복잡한 쿼리를 최적화해 보았습니다.
쿼리 플랜으로 쿼리를 분석하며 성능 병목 현상을 확인할 수 있었습니다. 또한, 분석 결과를 바탕으로 인덱스, 커서 기반 페이지네이션, 서브 쿼리 등의 3가지 방법을 적절히 조합하여 더 효율적인 쿼리를 설계할 수 있었습니다.
이 최적화를 진행하면서 orm은 만능이 아니며, 성능 문제가 발생하는 쿼리를 분석하고 최적화하는 단계가 필요하다고 느꼈습니다.
추후 개선사항
-
trending 정렬 개선
현재까지의 수정사항은 최신순, 오랜된 순에서만 커서 기반 페이지네이션이 가능합니다.
applicant라는 참가자 수 테이블에 의해 trending 기준을 설정하고 있기 때문입니다. 따라서 이 기능을 이용하기 위해서는 DB구조 변경과 업데이트 로직 변경이 필요합니다.
추후 개선할 예정입니다. -
커서 기반 페이지네이션은 과연 옳은가?
페이지네이션의 UI/UX에 맞추어 페이지네이션을 구현하는게 좋은 사례라고 들었습니다.
저희 팀은 무한 스크롤만 지원하기에 복합 인덱스를 이용한 커서 기반 페이지네이션이 적절하지만, 실제 페이지 번호를 탐색하는 경우에는 커서 기반 페이지네이션이 효과적이지 않을 수 있습니다.
페이지를 바로 건너뛰는 기능(20페이지로 바로 이동)이나 정렬 조건이 다양할 경우 offset 방식이 더 적합할 수 있습니다. 따라서 목적에 맞게 선택해야 합니다.
참고
