
0. 이 글을 쓰는 이유 + 이 기능을 구현한 이유
커서 기반 페이지네이션이라는게 있는지도 몰랐다. 그런데 예전에 다른 두 회사 면접을
연속으로 본적이 있는데 공교롭게도 Cursor-based Pagination 관련 질문을 받았다.
당연히 제대로 대답을 못했고 이후에 여러 글들을 보며 이런게 있구나 개념적으로만 학습했다.
그리고 몇달 후 동아리에 참여해 프로젝트를 시작했고,
마침 앱에서 무한스크롤 기능을 구현할 일이 생겼다.
그래서 이번 기회에 Cursor-based Pagination 방식으로 구현해보면서
기능 요구사항도 만족하고, 제대로 공부해보기 위해 기능을 구현하며 글을 쓰기 시작했다.
1. 페이지네이션(Pagination) 이란?
-
전체 데이터에서 지정된 갯수만 데이터를 전달하는 방법
-
필요한 데이터만 주고 받으므로 네트워크의 오버헤드를 줄일 수 있다.
-
구현 방법에는 크게 두 가지가 있다.
-
오프셋 기반 페이지네이션 (Offset-based Pagination)
-
커서 기반 페이지네이션 (Cursor-based Pagination)
-
2. 오프셋 기반 (Offset-based Pagination)
select *
from post
order by create_at desc
limit 10, 20;-
offset, limit 을 사용한 쿼리 이용 (MySQL 기준)
-
페이지 단위로 구분
-
직관적이고 구현도 간단하지만, 치명적인 문제점이 있다.
2-1. 데이터 중복 문제
- 게시판이라고 생각하고, 예시를 보자. 이 게시판에는 10개의 게시글이 있다.
-
A 사용자가 첫 메인페이지에 진입한다.
-
최신 게시글을 보여주기 위해 id가 10~6인 게시글을 가져와서 보여준다.
select * from post order by id desc limit 5 # 가져올 개수 offset (0*5) # (몇 번째 페이지인지 * 가져올 개수) -
A 사용자가 구경하는 사이 다른 사용자들이 새로운 게시글 3개를 생성했다.
-
A 사용자가 게시글을 다 구경하고, 다음 페이지 버튼을 눌러 요청했다.
select * from post order by id desc limit 5 # 가져올 개수 offset (1*5) # (몇 번째 페이지인지 * 가져올 개수) == 5개 데이터를 건너뛰어라-
현재 총 게시글 개수는 13개이다. (위에서 게시글 3개 추가 생성)
-
그러면 id가
8번 부터 ~ 4번게시글을 가져오게 된다. -
이렇게 되면 id가 8,7,6인 게시글을 또 다시 가져오게 된다. → 데이터 중복 발생
-
-
- 반대로 게시글이 삭제되는 경우에는, 특정 게시글이 조회되지 않는 현상도 발생한다.
평소에 게시판류 서비스를 이용하면서 다음 페이지로 넘어갔는데 이전 페이지에 있던 게시글이 보인다면, 해당 서비스는 오프셋 기반 페이지네이션으로 구현됐다고 보면 된다.
2-2. 성능 저하 문제
select *
from post
order by create_at desc
limit 10
offset 100000000;-
offset 값이 클 때 문제가 생긴다. 이유는 앞에 있는 모든 데이터를 읽어야 하기 때문이다.
-
그래서 위 쿼리는 앞에 1억개의 데이터를 읽고, 그 다음 10개 데이터를 읽어서 응답한다.
- 즉 뒤로 갈수록 읽어야 하는 데이터가 많아져 점점 느려진다.
-
그런데 일반 사용자가 게시판에서 1억번째에 있는 게시글을 조회할 일이 있을까? 라는 생각이 들었지만 예외가 있다고 한다.
-
검색 엔진이 색인을 생성하기 위해 1억번째에 있는 데이터를 조회할 수 있고,
offset 값을 쿼리 파라미터로 넘긴다면 사용자가 임의로 큰 값을 넣어 요청할수도 있다.
성능 저하 문제는 둘째 치더라도, 데이터 중복문제는 해결할 수 없다.
Cursor-based Pagination을 사용하면 위 문제점들을 모두 해결할 수 있다.
3. 커서 기반(Cursor-based Pagination)
-
Cursor 개념을 사용한다.
Cursor란 사용자에게 응답해준 마지막의 데이터의 식별자 값이 Cursor가 된다. -
해당 Cursor를 기준으로 다음 n개의 데이터를 응답해주는 방식이다.
쉽게 말로 비교하면
-
오프셋 기반 방식
- 1억번~1억+10번 데이터 주세요. 라고 한다면 → 1억+10번개의 데이터를 읽음
-
커서 기반 방식
- 마지막으로 읽은 데이터(1억번)의 다음 데이터(1억+1번) 부터 10개의 데이터 주세요
→ 10개의 데이터만 읽음
- 마지막으로 읽은 데이터(1억번)의 다음 데이터(1억+1번) 부터 10개의 데이터 주세요
그러므로 어떤 페이지를 조회하든 항상 원하는 데이터 개수만큼만 읽기 때문에
성능상 이점이 존재한다는 것이다.
# 첫 페이지 진입시 발생 쿼리
select *
from post
order by id desc
limit 10;
# 이후 페이지 요청시 발생 쿼리
select *
from post
where id < 10 # ex) cursor값이 10인 경우
limit 10;-
첫 페이지에 진입했을 때의 쿼리는 그냥 limit으로 10개 짤라서 주면 된다.
-
이후 페이지에 대한 요청은, 사용자에게 응답한 데이터 중 마지막 게시글이 Cursor가 된다.
- 마지막 게시글의 ID가 Cursor가 되겠다.
-
데이터 중복이 발생하지도 않고 딱 필요한 데이터만 가져올 수 있다.
4. Cursor 기반 페이지네이션 구현하기
4-1. Querydsl로 구현
@Override
public Page<Club> findClubsByCondition(Long cursorId, ClubFindCondition condition, Account loginAccount,
Pageable pageable) {
List<AccountClub> findAccountClubs = queryFactory.selectFrom(accountClub)
...
.where(
cursorId(cursorId)
...
)
.limit(pageable.getPageSize())
.fetch();
...
}
private BooleanExpression cursorId(Long cursorId){
return cursorId == null ? null : club.id.gt(cursorId);
}-
처음에는 id기준 오름차순으로 데이터를 가져오도록 구현했다.
-
필요없는 부분은 모두 생략했고, where절만 자세히 보면 된다.
-
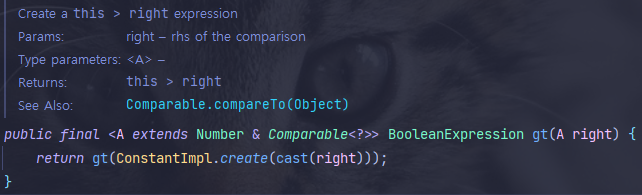
참고로
gt()는 querydsl이 제공해주는 메서드로, 아래와 같은 부등호 비교를 수행한다.
4-1-1. 사용자가 첫 페이지에 접근한 경우
- 첫 페이지에 접근한 경우, 클라이언트에서는 cursorId값을 보내지 않는다.
즉 null값이므로 cursorId()는 null값을 반환하며, where절은 실행되지 않는다.
select *
from 모임
... # join절 생략
limit 10;4-1-2. n번째 페이지에 접근한 경우
- 클라이언트가 curosrId값을 10을 전달했다고 가정하면,
club의 id > cursorId(10)이 where절에 추가된다.
select *
from 모임
... # join절 생략
where id > 10
limit 10;
4-2. 마지막 페이지에서 스크롤을 한다면?
95개의 데이터가 있고, 한 페이지에서 10개씩 데이터를 보여주고 있다고 했을 때
마지막 페이지에서 5개의 데이터를 보여주고, 여기서 사용자가 아래로 스크롤을 내려서 다음
데이터를 요청하면 어떻게 될까?
id > 95 를 만족하는 데이터는 존재하지 않기 때문에 아무 데이터도 응답하지 않는다.
비어있는 데이터를 응답받으면, 클라이언트에선 기존 데이터를 유지해주세요~ 라고
할 수 도 있지만, 간단하게 다음 데이터가 존재하지 않는다는 의미를 포함한 필드를 추가했다.
public ClubFindResponse findClubsByCondition(Long cursorId, ClubFindCondition condition, Account account,
Pageable pageable){
Page<ClubInfo> findClubInfos = clubRepository.findClubsByCondition(cursorId, condition, account, pageable)
.map(clubMapper::toInfo);
ClubFindResponse response = ClubFindResponse.of(findClubInfos, false);
if(findClubInfos.getTotalElements() == 0){
response.setHasNotClub(true);
}
return response;
}처음에는 추가 쿼리를 날려서 확인하려 했는데, 그럴 필요 없이 if문에서
조회한 데이터가 비어있다면 마지막 페이지라는걸 의미하고, 더 이상 데이터가 없다는 의미의
boolean 데이터인 hasNotClub 필드에 true값을 전달하였다.
이래저래 설명은 했지만 구현은 정말 간단하다.
지금부터의 내용은 예외적인 상황에 대한 내용이다.
5. Cursor 데이터가 유니크하지 않다면?
5-1. 문제점 - 데이터 누락
-
현재는 id(pk)값을 cursor로 사용하고 있다. 그리고 정렬도 하고 있지 않다.
-
그런데 기획을 다시보니
모임 종료 시간를 기준으로 정렬해야 한다. -
cursor 값을
모임 종료 시간으로 변경하게되면, 시간은 중복될 수 있는 값이므로
문제점이 생길 수 있다.- 참고로 앱에서는
모임 종료 시간이 최소 단위가 초가 아니라 분이므로 충분히 중복될 수 있다.
- 참고로 앱에서는
-
아래와 같은 데이터가 있다고 해보자.
id 모임 모임 종료 시간 1 모임1 2022-04-01 00:00:00 2 모임2 2022-05-01 00:00:00 3 모임3 2022-06-01 00:00:00 4 모임4 2022-07-01 00:00:00 5 모임5 2022-07-01 00:00:00 6 모임6 2022-07-01 00:00:00 7 모임7 2022-08-01 00;00:00
5-1-1. n번째 쿼리
select *
from 모임
where 종료시간 > '2022-03-30 00:00:00'
limit 4;| id | 모임 | 모임 종료 시간 |
|---|---|---|
| 1 | 모임1 | 2022-04-01 00:00:00 |
| 2 | 모임2 | 2022-05-01 00:00:00 |
| 3 | 모임3 | 2022-06-01 00:00:00 |
| 4 | 모임4 | 2022-07-01 00:00:00 |
-
결과는 모임1,2,3,4가 나올것이다.
-
그러면 마지막으로 조회된 모임4의 종료 시간(2022-07-01 00:00:00)이 다음 cursor가 된다.
5-1-2. n+1번째 쿼리
select *
from 모임
where 종료시간 > '2022-07-01 00:00:00'
limit 4;| id | 모임 | 모임 종료 시간 |
|---|---|---|
| 7 | 모임7 | 2022-08-01 00;00:00 |
-
결과는 모임7 하나만 나오게 된다.
-
모임4의 종료시간과 중복된 모임 5,6는 건너뛰게 된다.
6. Cursor 데이터가 유니크하지 않은 경우 - 해결
-
위와 같은 문제로 인해
Cursor 기반 페이지네이션을 구현할 때 Cursor 중 하나는 반드시 유니크한 값을 가져야 한다. -
모임 종료 날짜와, 유니크한 id(pk)값을 함께 사용하도록 구현해보자.
-
데이터는 똑같이 아래와 같다.
| id | 모임 | 모임 종료 시간 |
|---|---|---|
| 1 | 모임1 | 2022-04-01 00:00:00 |
| 2 | 모임2 | 2022-05-01 00:00:00 |
| 3 | 모임3 | 2022-06-01 00:00:00 |
| 4 | 모임4 | 2022-07-01 00:00:00 |
| 5 | 모임5 | 2022-07-01 00:00:00 |
| 6 | 모임6 | 2022-07-01 00:00:00 |
| 7 | 모임7 | 2022-08-01 00;00:00 |
6-1. SQL 작성
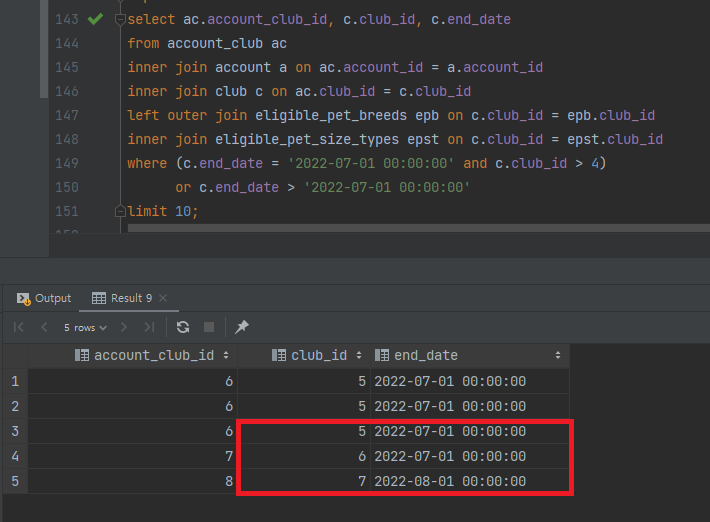
select *
from 모임
where (종료시간 = '2022-07-01 00:00:00' and id > 4) // 이전에는 누락된 모임 5,6 조회
or 종료시간 > '2022-07-01 00:00:00' // 모임 7 조회
...and조건을 보면, 이전에는 누락됐던 모임 5,6이 조회되고
or이후 조건으로 그 다음 모임들이 조회될 수 있다.
중복된 club_id가 조회되는건 애플리케이션에서 별도로 처리하므로, 무시하자.
6-2. Querydsl 구현
@Override
public Page<Club> findClubsByCondition(Long cursorId, ZonedDateTime cursorEndDate,
ClubFindCondition condition, Account loginAccount, Pageable pageable) {
List<AccountClub> findAccountClubs = queryFactory.selectFrom(accountClub)
...
.where(
cursorEndDateAndCursorId(cursorEndDate, cursorId),
...
)
.limit(pageable.getPageSize())
.fetch();
...
}
private BooleanExpression cursorEndDateAndCursorId(ZonedDateTime cursorEndDate, Long cursorId){
if (cursorEndDate == null || cursorId == null) {
return null;
}
return club.endDate.eq(cursorEndDate)
.and(club.id.gt(cursorId))
.or(club.endDate.gt(cursorEndDate));
}-
첫 페이지 조회하는 경우를 대비해 null 처리
-
and,or연산자는 직관적으로 봐도 SQL이랑 비슷해서 쉽게 이해할 수 있다.
7. OR 연산자 문제점
문제점은 아래와 같다.
-
or연산자 사용 시 인덱스를 제대로 타지 않는다. -
Cursor 데이터들(여기서는 모임 id, 모임 종료 시간)을 클라이언트에서 알고 있어야 한다.
-
이 부분은 사실 모임과 관련된 데이터들이라 당연히 클라이언트에서 들고 있고,
두개라 매번 보낸다고 해도 부담되는 개수는 아니다. -
그리고 커스텀 커서를 만들때 cursor 데이터를 통해 만들기 때문에
클라이언트가 전달해야하는 건 똑같으므로, 문제점이라고 볼 수 없다.
-
결국 문제점은 인덱스를 제대로 타지 않는 다는 것이다.
실행계획을 확인해보자.
7-1. 실행계획을 확인하기 전에..
실행계획에서 인덱스 여부를 보려면 type부분을 보면 된다. 아래는 type 컬럼에 대한 설명이다.
| 구분 | 설명 |
|---|---|
| system | 테이블에 단 한개의 데이터만 있는 경우 |
| const | SELECT에서 PK 혹은 UK를 상수로 조회하는 경우로, 많아야 한건의 데이터만 존재 |
| eq_ref | 조인할 때 PK 혹은 UK로 매칭하는 경우 |
| ref | 조인할 때 PK 혹은 UK가 아닌 Key로 매칭하는 경우 |
| ref_or_null | ref와 같지만 NULL이 추가되어 검색되는 경우 |
| index_merge | 두 개의 인덱스가 병합되어 검색이 이루어지는 경우 |
| unique_subquery | IN절 안에 서브쿼리 결과가 PK인 경우 |
| index_subquery | unique_subquery와 같고, 서브쿼리 결과가 PK가 아닌 일반 인덱스인 경우 |
| range | Index Range Scan 하는 경우 |
| index | Index Full Scan 하는 경우 |
| all | Table Full Scan 하는 경우 |
7-2. 실행계획 확인 - 인덱스가 없을 때
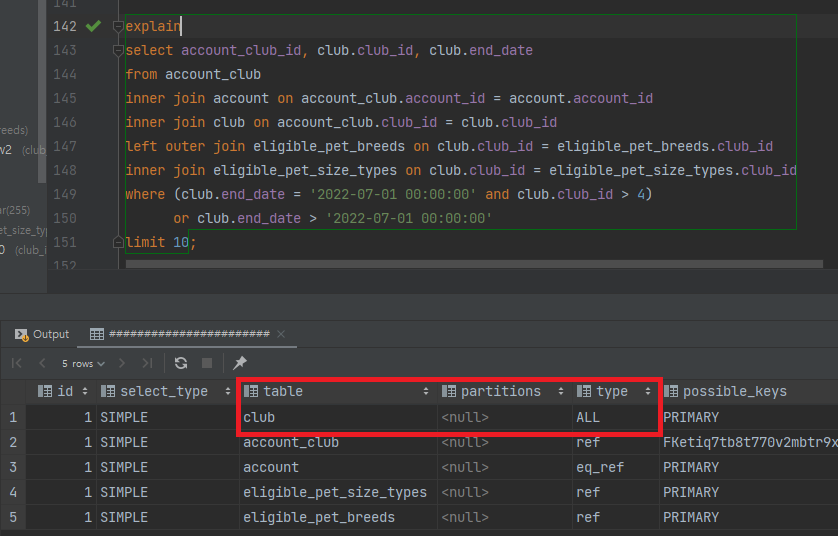
- club 테이블쪽을 보면 type이
ALL인걸 알 수 있다. 즉 Table Full Scan(TFS)이 발생한다.
물론 TFS가 무조건 안좋은건 아니다.
보통 인덱스를 통해 레코드를 읽는 것은 직접 읽는 것의 4~5배 비용으로 계산한다.
즉 조회할 레코드의 건수가 전체 레코드 수의 20~25%를 넘기면 인덱스를 사용 안하는게 더 효율적이다.
하지만 지금 상황에는 해당하지 않으니 참고만 하자.
7-3. 실행계획 확인 - 인덱스를 추가했을 때
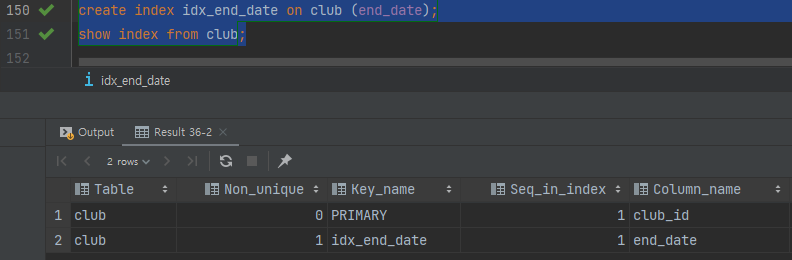
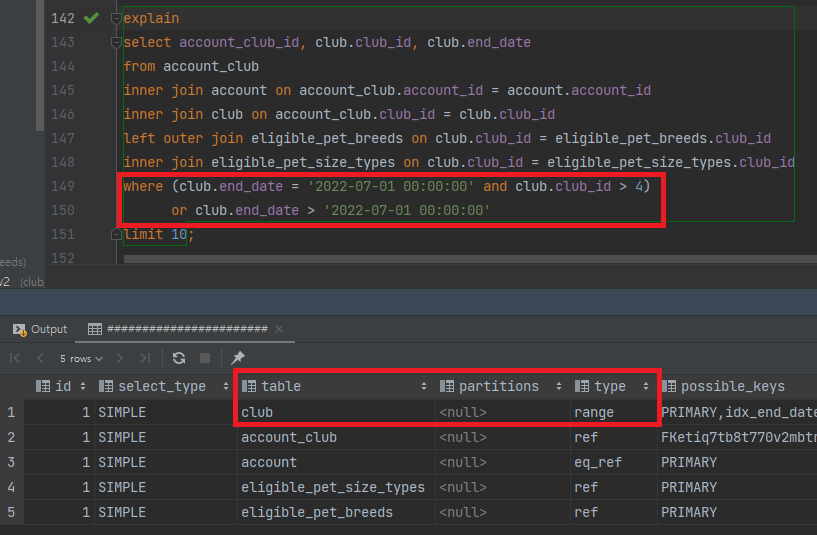
-
오잉..? 인덱스를 안탈줄 알았는데, type이
range다. 즉 인덱스를 탄다는 이야기다. -
and와or연산자를 섞어서 사용해서 그런걸까?and연산자를 제거해보자.
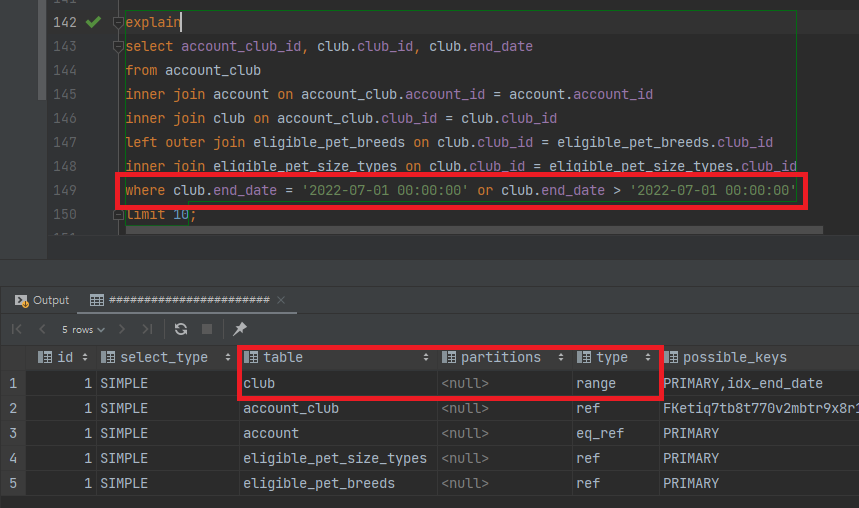
- 여전히 인덱스를 잘 탄다. 음 쿼리를 단순화 해보자.
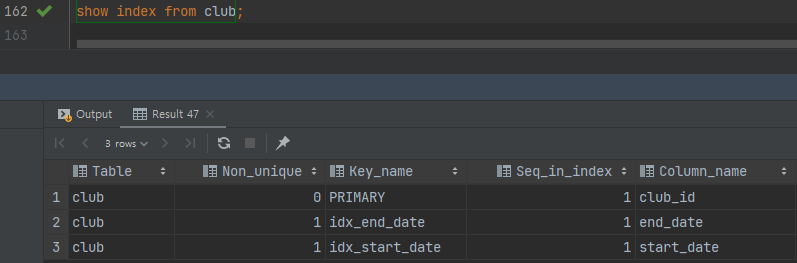
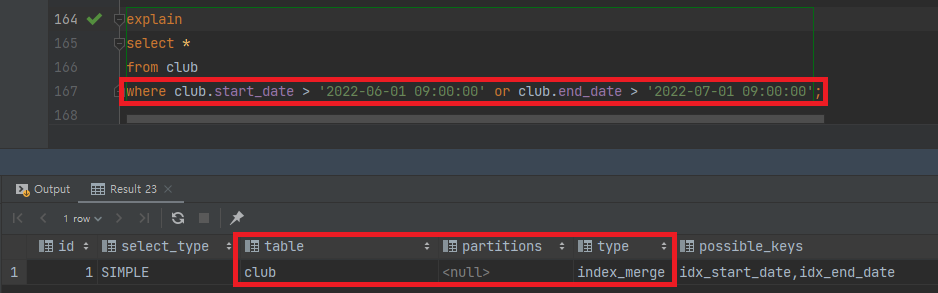
-
start_date컬럼에도 인덱스를 추가했다. -
그리고 실행계획을 확인해봤는데,
index_merge로 여전히 인덱스를 잘 탄다.
or 연산자 사용 시 인덱스를 타지 않는다는 이야기와 내용들을 많이 봤는데,
인덱스를 잘 사용한다.
or 조건이 간단한 경우 또는 DBMS가 다른 경우 등 상황마다 다르다.
직접 실행계획을 확인하거나 성능테스트를 통해서 Best-Practice를 선택하는게 좋다.
우선은 인덱스를 못타서 TFS가 발생한다고 가정하고, or 연산자를 없애기 위해
cursor를 직접 custom해서 만들어 보자
8. Cursor를 custom해서 사용하기
8-1. SQL 작성
select ... ,
CONCAT(
LPAD(DATE_FORMAT(c.end_date, '%Y%m%d%H%i%s'), 20, '0'),
LPAD(c.club_id, 10, '0')
) as curosr
...
where CONCAT(
LPAD(DATE_FORMAT(c.end_date, '%Y%m%d%H%i%s'), 20, '0'),
LPAD(c.club_id, 10, '0')
) > '값'
...-
가독성을 위해 필요한 부분만 남겼다.
-
Custom cursor 생성 부분을 설명하면
-
날짜를 문자열로 변환
-
DATE_FROMAT(값, 원하는 포맷)
-
DATE_FROMAT 함수를 이용해, 대시나 공백문자를 다 제거하고 문자열로 변환했다.
-
-
고정된 길이를 갖도록
-
LPAD(값, 원하는 길이, 남는 공간에 채울 값 지정)
-
end_date 컬럼 값을, 길이 20으로 만든다. (남는공간은 지정한 값 0으로 채운다.)
-
end_date가 길이 20을 넘을일이 없고, id또한 길이 10을 넘을일이 없어서
값이 누락되지 않는다.
-
-
하나의 문자열로
-
CONCAT(값1, 값2)
-
값1과 값2를 하나의 문자열로 만든다.
-
-
8-2. 결과 확인
where (c.end_date = '2022-07-01 09:00:00' and c.club_id > 4)
or c.end_date > '2022-07-01 09:00:00'-
위 where절(Custom cursor를 사용하기 전)에서 사용된 조건데이터를,
Custom cursor로 변환하게 되면000000202207010900000000000004값이 나온다. -
그러면 해당 값으로 조건절을 바꿔보자.
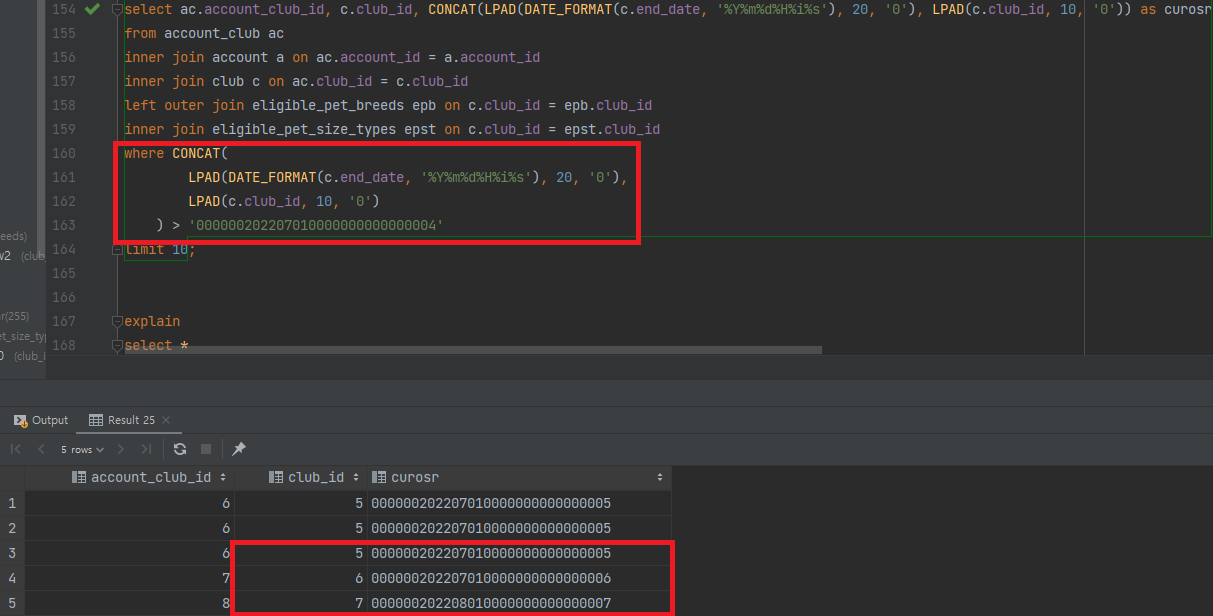
-
결과값이 똑같이 모임5,6,7을 조회하는걸 확인할 수 있다.
-
이제 애플리케이션에서 구현해보자.
8-3. Querydsl로 구현
8-3-1. custom 규칙대로 Curosr 생성
- 위에서 MySQL 내장함수로 만든 값을, 애플리케이션에서도 똑같이 만들어야 한다.
private String generateCustomCursor(LocalDateTime cursorEndDate, Long cursorId){
if (cursorEndDate == null && cursorId == null) { // 1
return null;
}
cursorEndDate = cursorEndDate.minusHours(9); // 2
String customCursorEndDate;
String customCursorId;
customCursorEndDate = cursorEndDate.toString()
.replaceAll("T", "")
.replaceAll("-", "") // 3
.replaceAll(":", "") + "00"; // 4
customCursorEndDate = String.format("%1$" + 20 + "s", customCursorEndDate)
.replace(' ', '0'); // 5
customCursorId = String.format("%1$" + 10 + "s", cursorId)
.replace(' ', '0'); // 5
return customCursorEndDate + customCursorId; // 6
}-
첫 페이지 조회를 위한 null 처리
- 첫 페이지를 조회하는 경우 cursor 데이터는 null값이 들어오므로, null을 리턴해서
where 절에서 해당 조건이 동적으로 제외되도록 한다.
- 첫 페이지를 조회하는 경우 cursor 데이터는 null값이 들어오므로, null을 리턴해서
-
9시간 빼주기
-
DB Timezone은 UTC다.
-
예로 19시 데이터를 저장하면 DB에는 10으로 저장된다.
시간 클래스를 사용하면 상관 없지만
문자열로 변환해서 사용하기 때문에 직접 9시간을 빼줘야 한다.
-
-
필요없는 문자 제거
-
LocalDateTime을 String으로 변환하면
2022-07-01T18:00:15처럼 나온다. -
‘-’ , ‘T’ , ‘:’ 문자를 모두 제거해야 한다.
-
-
초 추가하기
-
2022-07-01 18:00:00처럼 0초 데이터인 경우2022-07-01T18:00와 같이 초를 생략한다. -
그래서 “00”을 직접 추가했다.
-
일단 이 앱에서 모임시간은 최소 단위가 분단위이므로 0초 이외에 값이 들어오지
않아서 별도로 처리를 하지 않았지만, 0초 이외에 값이 들어오는 경우 “00”을
추가하지 않는 처리가 필요할 것이다.
-
-
MySQL의 LPAD 구현
-
앞에 빈공간에 0으로 채워줘야 하는데, 반복문 보다는
String.format()을 이용했다. -
String.format()으로 원하는 자리수만큼 빈공간을 채우고, replace로 빈공간을 0으로 치환
-
-
마무리
- MySQL의 CONCAT은 그냥 문자열 합치는 것이므로, + 연산자로 리턴
8-3-2. Querydsl 구현
@Override
public Page<Club> findClubsByCondition(String customCursor, ClubFindCondition condition,
Account loginAccount, Pageable pageable) {
List<AccountClub> findAccountClubs = queryFactory.selectFrom(accountClub)
...
.where(
customCursor(customCursor),
...
)
.limit(pageable.getPageSize())
.fetch();
...
}
private BooleanExpression customCursor(String customCursor){
if (customCursor == null) { // 1
return null;
}
StringTemplate stringTemplate = Expressions.stringTemplate( // 2
"DATE_FORMAT({0}, {1})",
club.endDate,
ConstantImpl.create("%Y%m%d%H%i%s")
);
return StringExpressions.lpad(stringTemplate, 20, '0')
.concat(StringExpressions.lpad(club.id.stringValue(), 10, '0')) // 3
.gt(customCursor); // 4
}-
첫 페이지 조회를 위한 null 처리
- 첫 페이지를 조회하는 경우 cursor 데이터는 null값이 들어오므로, null을 리턴해서
where 절에서 해당 조건이 동적으로 제외되도록 한다.
- 첫 페이지를 조회하는 경우 cursor 데이터는 null값이 들어오므로, null을 리턴해서
-
MySQL의 DATE_FORMAT 함수

-
위 SQL을 Querydsl로 작성해야 한다.
-
Querydsl에서 DBMS의 함수를 사용하기 위해서
Expressions.stringTemplate()를 사용할 수 있다. -
첫 번째 파라미터에 원하는 템플릿을 명시하고, {0}과 {1} 부분이 다음 파라미터로 치환된다.
-
-
MySQL의 LPAD, CONCAT 함수

- lpad().concat().lpad() 형태로 작성하면 된다.
-
Querydls gt() 메서드
- 위에서 이야기 했지만, 부등호
>연산을 수행한다.
- 위에서 이야기 했지만, 부등호

정리하면 customCursor() 메서드는 위 처럼 where절에 들어가는 부분을 구현한 것이다.
8-3-3. 결과 확인
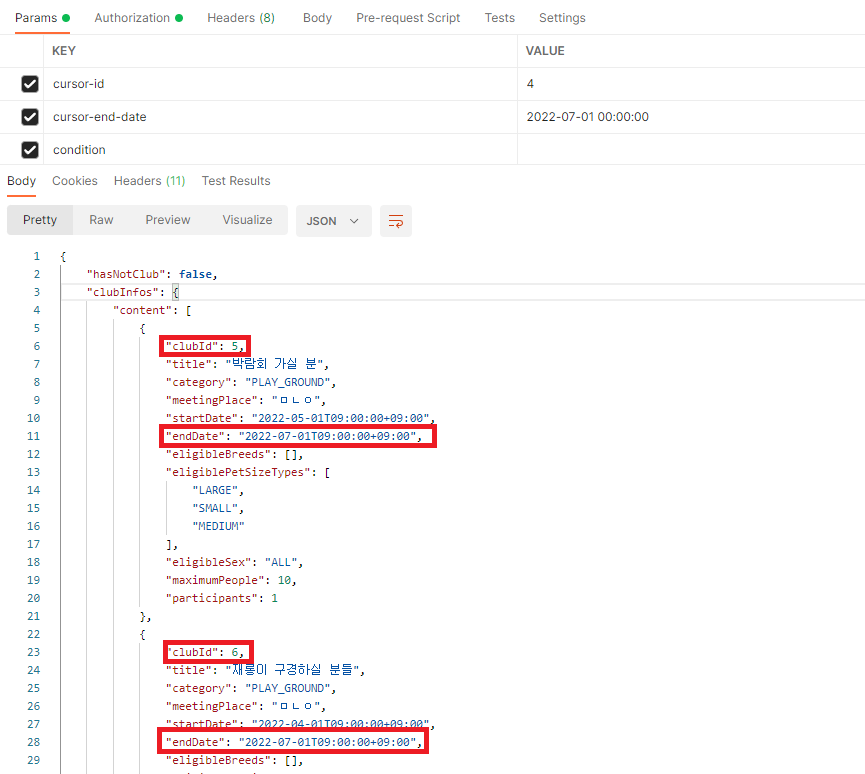
| id | 모임 | 모임 종료 시간 |
|---|---|---|
| 5 | 모임5 | 2022-07-01 00:00:00 |
| 6 | 모임6 | 2022-07-01 00:00:00 |
| 7 | 모임7 | 2022-08-01 00;00:00 |
-
요청값
-
id : 4
-
종료 날짜 : 2022-07-01 00:00:00
-
-
club_id와 종료 날짜를 보면 원하는대로, 종료날짜가 같은 모임이 누락되지 않고 조회된걸 볼 수 있다.
-
테스트도 모두 통과..!

9. 트러블슈팅이라 쓰고 삽질이라 읽는다. + 기타 참고사항
9-1. and 조건을 괄호로 묶기
# 원했던 쿼리
select *
from 모임
...
where (종료날짜 = '2022-07-07' and id > 4) or 종료날짜 > '2022-07-07'
....
# 실제 쿼리
select *
from 모임
...
where 종료날짜 = '2022-07-07' and id > 4 or 종료날짜 > '2022-07-07'
....-
and조건이 괄호로 묶이기를 원했지만, 뭔짓을 해도 원하는대로 동작하지 않았다.
-
하지만 괄호로 묶지 않아도, 즉 아래처럼 쿼리가 나가도 SQL 상에서 연산자 우선순위에 따라 괄호가 묶인것 처럼 동작한다.
9-2. Timezone 이슈
9-2-1. Querydsl
@Override
public Page<Club> findClubsByCondition(Long cursorId, ClubFindCondition condition, Account loginAccount,
Pageable pageable) {
List<AccountClub> findAccountClubs = queryFactory.selectFrom(accountClub)
...
.where(
cursorEndDate(cursorEndDate)),
...
)
.limit(pageable.getPageSize())
.fetch();
...
}
private BooleanExpression cursorEndDate(ZonedDateTime cursorEndDate){
return cursorEndDate == null ? null : club.endDate.gt(cursorEndDate);
}- 누락되는 데이터를 방지하기 위해 where절에 조건들을 추가했는데, 가독성을 위해
임시로 where절에 날짜를 비교하는 코드만 남겨두었다.
9-2-2. 실제 쿼리
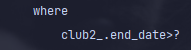
select *
from 모임
...
where c.end_date > '2022-07-01 00:00:00'
...-
실제로 발생는 쿼리는 위와 같다.
-
그런데 end_date가
2022-07-01 00:00:00인 데이터들이 같이 조회가 된다. -
하지만 실제로 DB에 쿼리를 날리면 조회되지 않는다.
9-2-3. Querydsl 탓하기

-
삽질을 하던 중, 한 블로그 글을 보았다.
-
querydsl 문제인가..? 하지만 저 글을 제외하고 어떠한 관련 글도 찾을 수 없었다.
9-2-4. 해결
-
며칠을 삽질하다가 커뮤니티에서 알게된 한 분이 원격으로 도움을 주셨는데
문제는 어이없게도2022년이 아니라2021년으로 조회를 하고 있었다.
그러니 당연히2022년 데이터들이 같이 조회가 됐다..where c.end_date > '2021-07-01 00:00:00' # 2022-07-01인 데이터는 당연히 조회.. -
며칠을 삽질하던게 데이터문제였다니 분노+기쁨+허탈이 공존하던 중 2022년도로
조회했는데 여전히2022-07-01 00:00:00데이터가 조회됐다. -
뭐지 싶었지만 DB timezone은 UTC이다. 한국은 UTC보다 9시간이 빠르다.
DB에 더미 데이터를2022-07-01 00:00:00으로 넣어놨는데
실제로는2022-07-01 09:00:00인 셈이다.
이 상태에서2022-07-01 00:00:00보다 큰 데이터를 주세요 라고 요청했으니 조회가
되는게 당연하다. -
분명 회사에서 일할 땐, 인지하고 있었는데 뭐에 홀렸는지..
9-3. PageableExecutionUtils 사용
return new PageImpl<>(findClubs, pageable, findClubs.size()); // 기존
return PageableExecutionUtils.getPage(findClubs, pageable, findClubs::size); // 변경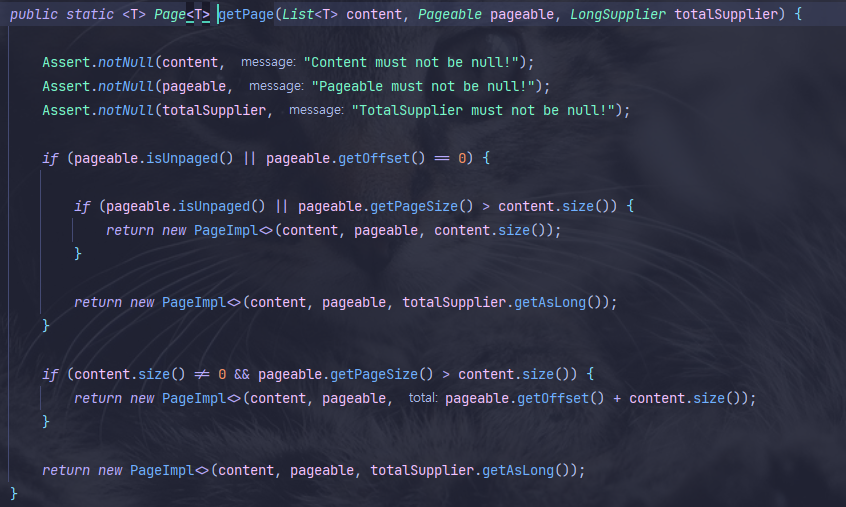
-
PageableExecutionUtils.getPage는 내부적으로 new PageImpl()을 사용한다. -
차이점은 위 if문에서 확인할 수 있듯이, 특정 상황에서 3번째 함수를 실행하지 않는다.
- totalCount가 pageSize보다 작은경우
- 마지막 페이지일 경우
-
기존 코드에서 볼 수 있듯이 나는 count쿼리를 날리는게 아니라서 큰 의미는 없긴하다.
엄청난 최적화를 해주는건 아니지만, new로 직접 생성하는 것 보단 Spring이 래핑해서
제공해주는 기능을 안 쓸 이유 또한 없으니 사용했다.
10. 마치면서
Cursor-based Pagination이 필수는 아니다. 아래와 같은 조건을 모두 만족한다면 Offset-based Pagination을 사용해도 전혀 문제가 없다.
1. 중복데이터가 발생해도 상관 없는 경우
2. 전체 데이터 양이 적은 경우
3. 새로운 데이터 생성이 빈번하지 않은 경우
4. 검색엔진이 색인을 생성하지 않고, 임의의 사용자가 오래된 데이터를 조회하지 않는 경우주관적인 생각으로는 웬만한 서비스는 중복 데이터가 발생하면, 크리티컬 하지는 않지만 분명히
사용자에겐 좋지 못한 경험이다.
또한 신규 서비스를 만들 때는 대규모 트래픽이 발생할 것을 대비하면 당연히 좋다.
물론 대비를 하기 위해서는 추가 비용이 발생하므로 무조건적으로 대비할 순 없다.
오버 스펙이 되버리면 안된다. 하지만 아래와 같은 생각을 해보자.
-
Cursor-based Pagination 구현이 어려운가? →
No- Custom cursor 까지 구현해야 한다면 조금 어려워지긴 한다..
-
추가 비용이 발생하는가? →
No -
Offset-based Pagination 방식에 비해 단점이 존재하는가? →
No
그래서 처음부터 Cursor-based Pagination 방식으로 구현하는게 좋지 않을까? 라는 생각이 들었지만, 다 구현하고 보니 그건 또 아닌 것 같다..
Custom cursor를 구현해야 하는 경우 조금 더 공수가 들어간다.
정말 간단한 백오피스 성격의 서비스라면 Offset-based Pagination 방식이 나을 것 같다.
하지만 그 이외에 경우에는 그래도 처음부터 Cursor-based Pagination 방식으로
구현하는게 좋은 것 같다. 끝
전체 코드 GitHub Repository
Ref
https://velog.io/@minsangk/커서-기반-페이지네이션-Cursor-based-Pagination-구현하기
https://www.eversql.com/faster-pagination-in-mysql-why-order-by-with-limit-and-offset-is-slow/

2개의 댓글

안녕하세요! 좋은 포스팅 잘 읽었습니다.
궁금한 점이 하나 있는데요,
where CONCAT(
LPAD(DATE_FORMAT(c.end_date, '%Y%m%d%H%i%s'), 20, '0'),
LPAD(c.club_id, 10, '0')
) > '값'처럼 where절 작성 시 인덱스를 타지 않아 성능상 부하가 발생하지는 않나요?
데이터 삭제시 문제가 생길 수 있겠네요? 혹시 이 경우에 어떻게 쿼리를 짜셨는지 여쭤봐도 될까요??
방법을 못찾아서 결국 rownum으로 페이지 구성을 했습니다 ㅠ