판다스 시리즈
: 판다스의 시리즈는 일차원 데이터를 관리하는 자료구조로, 데이터와 함께 인덱스(index)라는 것을 사용해서 데이터에 레이블 담아둘 수 있다.
시리즈에서는 데이터에 맵핑되는 레이블을 인덱스라고 부른다.
시리즈는 ndarray를 확장해서 만들어서 ndarray가 지원하는 숫자 인덱싱과 슬라이싱을 사용할 수 있고 브로드캐스팅 또한 사용할 수 있다.
판다스의 다양한 import 방식
시리즈 인덱스
파이썬의 딕셔너리를 사용하면 데이터에 레이블을 붙여서 저장할 수 있는 것처럼
시리즈도 각 데이터에 인덱스를 설정할 수 있다.
from pandas import Series # Series 임포트
data = [1000, 2000, 3000]
s = Series(data)
print(s.index)
print(s.index.to_list())시리즈 맵핑
data = [1000, 2000, 3000] # 리스트 한개 생성
index = ['메로나', '구구콘', '하겐다즈']
s = Series(data=data, index=index) # data. index에 각각의 리스트를 넣어줌
s2 = s.reindex(["메로나", "비비빅", "구구콘"]) # 리스트 두개 생성
print(s2) # 출력출력결과 :
보시는 것처럼 맵핑되어 순서대로 index와 data가 정해졌다.

reindex
data = [1000, 2000, 3000]
index = ['메로나', '구구콘', '하겐다즈']
s = Series(data=data, index=index)
s2 = s.reindex(["메로나", "비비빅", "구구콘"])
print(s2)새로운 값으로 다시 인덱스 해준다.
기존의 비비빅은 없는 데이터이므로 NanN이 뜬다.

딕셔너리를 통해 다음과 같이 표현도 가능하다
data = {
"2019-05-31" : 42500,
"2019-05-30" : 42550,
"2019-05-29" : 41800,
"2019-05-28" : 42550,
"2019-05-27" : 42650
}
s = Series(data)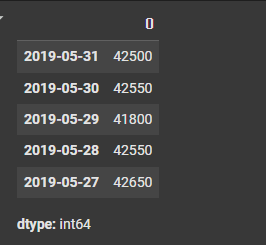
시리즈 인덱싱
자료구조에서 하나의 값에 접근하는 것을
인덱싱이라 한다.
리스트는 인덱스로만인덱싱을 했다면, 시리즈는 행 번호와 인덱스를 사용해서인덱싱할 수 있다.시리즈는 행 번호와 인덱스가 존재하기에 두가지 방법으로 인덱싱할 수 있다.
시리즈 객체의 행 번호를 사용해서 인덱싱할 때iloc연산(속성)을,
인덱스를 사용할 때loc연산을 사용한다.
iloc, loc 연산
data = [1000, 2000, 3000]
index = ["메로나", "구구콘", "하겐다즈"]
s = Series(data=data, index=index)
print(s.iloc[0]) # 속성값으로 인덱싱
print(s.loc['메로나']) # 인덱스 값으로 인덱싱
시리즈 슬라이싱
iloc 슬라이싱 법
from pandas import Series
data = [1000, 2000, 3000]
index = ["메로나", "구구콘", "하겐다즈"]
s = Series(data=data, index=index)
print(s.iloc[0:2]) # 슬라이싱하여 출력0 ~ 2 까지 슬라이싱하여 하겐다즈는 출력하지 않는다

loc 슬라이싱 법
data = [1000, 2000, 3000]
index = ["메로나", "구구콘", "하겐다즈"]
s = Series(data=data, index=index)
print(s.loc['메로나':'구구콘'])메로나 ~ 구구콘까지 출력하여 하겐다즈가 출력되지 않음
따로따로 슬라이싱 법
iloc 법
data = [1000, 2000, 3000]
index = ["메로나", "구구콘", "하겐다즈"]
s = Series(data=data, index=index)
indice = [0, 2]
print(s.iloc[ indice ])
print(s.iloc[ [0, 2] ])loc 법
data = [1000, 2000, 3000]
index = ["메로나", "구구콘", "하겐다즈"]
s = Series(data=data, index=index)
indice = ["메로나", "하겐다즈"]
print(s.loc[ indice ])
print(s.loc[ ["메로나", "하겐다즈"] ])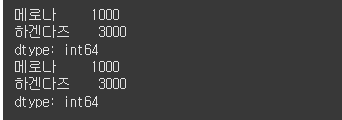

안녕하세요 게임개발을 공부하고 있는 돼지인간 입니다.