미래유망
1.[미래유망 2025-03-25]

파이썬에서의 while while문과 같이 쓰면 좋은 코드 break : while문을 강제로 나가게함 continue : 밑에있는 코드를 건너뛰고 while문 처음으로 파이썬에서의 문자열 관련 함수 isLower() : 문자가 소문자면 True반환 isUpper() : 문자가 대문자면 True반환 lower() : 문자를 소문자로 변환 uppe...
2.[미래유망 2025-03-24]
3.[미래유망 2025-03-26]
함수는 다음과 같이 만든다.매개변수 : 함수에 입력으로 전달된 값을 받는 변수반환값 : 반환할 값입력된 문자열을 역순으로 출력하는 print_reverse 함수를 정의하라my_dict에는 날짜를 키 값으로 OHLC가 리스트로 저장되어 있다.my_dict와 날짜 키 값을
4.[미래유망 2025-03-27]
사람 클래스에서 이름, 나이, 성별을 출력하는 who() 메소드를 추가하세요.사람 클래스에 이름, 나이, 성별을 받는 selfInfo 메소드를 추가히세요.사람 클래스에 "나의 죽음을 알리지 말라"를 출력하는 소멸자를 추가하세요.주식 종목에 대한 정보를 저장하는 Stoc
5.[미래유망 2025-03-28]
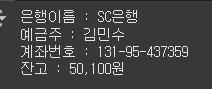
어제 클래스와 관련한 예제를 풀다가 다른 개념을 발견했다.한번 정리해보도록 하겠다.클로저는 간단히 말해 함수 안에 내부 함수를 구현하고 그 내부 함수를 리턴하는 함수를 말한다. 이때 외부 함수는 자신이 가진 변숫값 등을 내부 함수에 전달할 수 있다.또는Account 인
6.[미래유망] 넘파이 #02
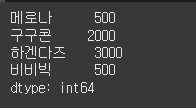
다음 코드는 메로나 인덱스에 저장된 1000이라는 값을 500으로 변경합니다.만약 없는 값을 작성한다면 새로운 값을 추가합니다.drop 메서드는 시리즈의 원본 데이터를 제거하지 않고 새로운 시리즈 객체를 반환합니다.drop 메서드를 호출한 결과를 다시 변수에 바인딩하도
7.[미래유망] 넘파이 #03
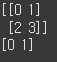
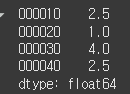
넘파이는 파이썬 리스트를 확장해서 만들었기 때문에 리스트가 제공하는 대부분의 기능을 사용할 수 있다. 인덱싱에 사용하는 인덱스는 리스트와 동일하게 데이터 하나에 하나씩 맵핑됩니다.4행 2열의 ndarray에 sum 메서드를 적용하니 전체 데이터의 합이 계산되는 모습ax
8.[미래유망] 판다스 #02
필터링 Map Map : 반복문 형식으로 시리즈 요소 하나하나 매핑 시켜줌 > Map 응용(작다, 크다 분석) 파라미터 x에는 시리즈에 저장된 값이 차례로 입력되고, 비교 연산의 결과 "크다", "작다"는 문자열이 저장된 시리즈를 반환한다. > 시리즈 필터링
9.[미래유망 2025-04-04(문제풀이)]
10.[미래유망] 판다스 #01
: 판다스의 시리즈는 일차원 데이터를 관리하는 자료구조로, 데이터와 함께 인덱스(index)라는 것을 사용해서 데이터에 레이블 담아둘 수 있다.시리즈에서는 데이터에 맵핑되는 레이블을 인덱스라고 부른다.시리즈는 ndarray를 확장해서 만들어서 ndarray가 지원하는
11.[미래유망 2025-04-07(문제풀이)]
시리즈 객체의 데이터 타입을 숫자 타입으로 변경해보세요.다음과 같은 시리즈 객체가 있을 때 values에서 '세'라는 문자열을 제거한 후 데이터를 'int32' 타입으로 변환해보세요.다음 시리즈 객체의 인덱스를 \['a', 'b', 'c', 'd']로 재정렬하세요.다음
12.[미래유망] 판다스(데이터 프레임) #03 연산법
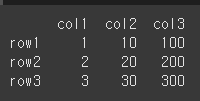
pandas.DataFrame으로 생성된 인스턴스는 크기의 변경이 가능한 2차원 배열입니다. (Series는 1차원)데이터 구조에는 레이블이 지정된 축인 행과 열까지 포함되며, 클래스 매서드를 통해 레이블의 수정이 가능합니다.기본 사용법df.add(other, axi
13.[미래유망] 판다스(데이터 프레임) #03 연산법 - 2
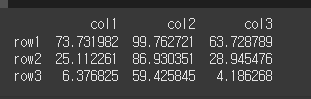
round 함수는 DataFrame 객체 내의 요소를 반올림하는 메서드입니다.df.round(decimals=0, args, kwargs) decimals : 소수 n번째 자리 '까지' 반올림을 합니다. 만약 음수면 10의 n승 자리 까지 반올림 합니다.decimals
14.[미래유망] 판다스(데이터 프레임) #04 함수 적용, 인덱싱

apply 메서드는 DataFrame에 함수를 적용하여 반환하는 메서드 입니다.함수에 전달되는 객체는 Seires형식이며 DataFrame의 index(axis=0)이냐 columns(axis=1)이냐에 따라 다릅니다.최종반환 유형은 적용된 함수에 따라 정해지지만 re
15.[미래유망] 판다스(데이터 프레임) #05 비교, 필터링, 결측 제어
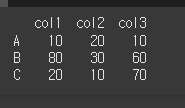
lt, gt, le, ge, eq, ne 메서드는 DataFrame의 크기 비교를 수행하는 메서드입니다.각각 >, <, >=, <=, ==, !=와 용도가 같습니다. 그리고 각 메서드는 사용법이 동일합니다.※각각 less than, grater than, l
16.[미래유망] 판다스(데이터 프레임) #06 정렬, 결합
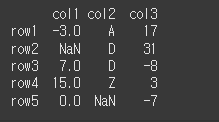
sort_values 메서드는 값을 기준으로 레이블을 정렬하는 메서드입니다.사용법df.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_in
17.[미래유망] 판다스(데이터 프레임) #07 가공

insert 메서드는 DataFrame의 특정 위치에 열을 삽입하는 메서드입니다..DataFrame에 해당 열이 이미 존재 할 경우 allow_duplicates=True가 아니면 Value Errer를 발생시킵니다.사용법 df.insert(loc, column, va
18.[미래유망 2025-04-15(문제풀이)]
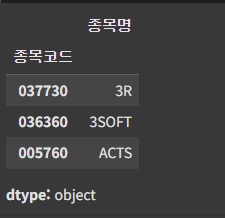
데이터프레임 컬럼 접근 데이터프레임에서 현재가 컬럼만 출력해보세요. > loc 위 데이터프레임에서 "037730" 종목의 데이터를 인덱싱해보세요. > loc 멀티 인덱싱 위 데이터프레임에서 첫 번째와 세 번째 행을 동시에 인덱싱해보세요. > 특정 값 가져오기
19.[미래유망] 판다스(데이터 프레임) #08 정보, 데이터 타입, 확인
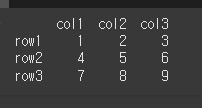
index메서드는 pandas객체의 index(행)를 출력합니다.사용법df.index먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.실행결과는 아래와 같이 Index명과 type이 차례로 출력되는것을 볼 수 있습니다.반환 타입은 pandas의 Index타입임을 사용
20.[미래유망] 판다스(데이터 프레임) #09 축 및 레이블

swapaxes메서드는 행/열을 바꿔주는 메서드입니다. 값들도 교환됩니다.사용법df.swapaxes(axis1, axis2, copy=True)axis1, axis2 : {0 : index / 1 : columns} 교환할 행과 열 입니다.copy : 사본을 생성할지
21.[미래유망] 판다스(데이터 프레임) #10 통계
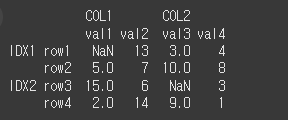
min / max 메서드는 행/열 의 최대값, 최소값을 구하는 메서드 입니다.사용법df.max(axis=None, skipna=None, level=None, numeric_only=None, kwargs)df.min(axis=None, skipna=None, leve
22.[미래유망] 판다스(데이터 프레임) #11 통계(심화)

공분산 (cov)의 개념 : 공분산(covariance)은 두 확률 변수 간의 관계를 나타내는 통계적 개념 두 변수의 값이 어떻게 함께 변하는지를 측정, 서로 양의 방향으로 변하는지, 음의 방향으로 변하는지, 또는 전혀 관계가 없는지를 알 수 있다. Cov cov 메
23.[미래유망 2025-05-07(문제풀이)]
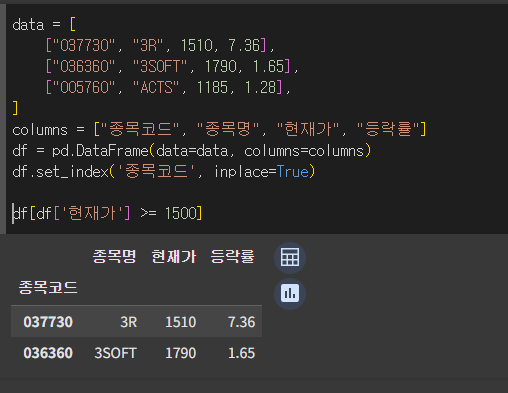
데이터프레임 query 메서드를 사용하여 종가(close)가 시가(open)보다 큰 데이터만 가져오세요.위 데이터프레임에서 종가(close)가 3,000원 이상인 종목만 출력하세요.위 데이터프레임에서 시가(open)가 2,000원 이상이고 종가(close)가 시가(op
24.[미래유망] 판다스(데이터 프레임) #12 시간, 멀티인덱스
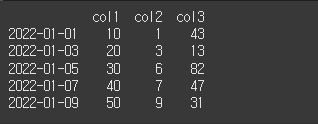
shift메서드는 시계열 데이터의 데이터나 인덱스를 원하는 기간만큼 쉬프트 하는 메서드 입니다.freq 인수를 입력하지 않으면 데이터가 이동하고, 인수값을 입력하게되면 인덱스가 freq값 만큼 이동하게됩니다.사용법df.shift(periods=1, freq=None,
25.[미래유망] 판다스(데이터 프레임) #13 반복, 형식변환
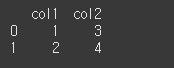
\_iter\_\_ 메서드는 열 인덱스를 map 오브젝트 형태의 반복자(iterator)로 반환하는 메서드입니다.사용법df.\_\_iter\_\_( )먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.기본적으로 df.\_\_iter\_\_( )
26.[미래유망] 판다스(데이터 프레임) #14 형식 변환

to_dict 메서드는 데이터프레임 객체를 dict 형태로 변환하는 메서드 입니다.사용법df.to_dict(orient='dict', into=)orient : 출력할 dict의 형태를 지정합니다. 형태는 아래와 같습니다.into : 반환값의 모든 매핑에 사용되는 co
27.[미래유망] 판다스(데이터 프레임) #15 플로팅

plot 메서드는 matplotlib 라이브러리를 이용해 dataframe 객체를 시각화 하는 메서드 입니다.사용법df.plot(args, kwargs)자세한 다른 함수의 설명은 실습먼저 기본적인 사용법 예시를위하여 두가지 데이터를 만들어 보겠습니다.df는 0~100까
28.[미래유망 2025-05-20(문제풀이)]

위 데이터프레임에서 테마별 PER, PBR의 최대, 최소값을 계산하세요.위 데이터프레임에서 테마별 종목의 개수를 계산하세요.위 데이터프레임을 '테마' 컬럼으로 그룹핑한 후 '2차전지(생산)' 그룹만 가져오세요.위 데이터프레임에서 테마별 PER의 평균을 계산하세요.위 데
29.[미래유망] Plotly #01
지은이 : 위키독스 쭌랩
30.[미래유망] Plotly #02 기본문법

말 그대로 그래프의 제목을 붙이는 작업을 하겠다.Title 설정하기 라는 제목이 생긴것을 볼 수 있다.결과는 위와 같다.udate_layout함수를 통해 이 두가지 방법을 모두 커버할 수 있다.제목의 위치를 지정할 수도 있다.title_x = 가로 축의 좌표로 0은 맨
31.[미래유망] Plotly #05 Plotly 인터렉티브 환경 문법
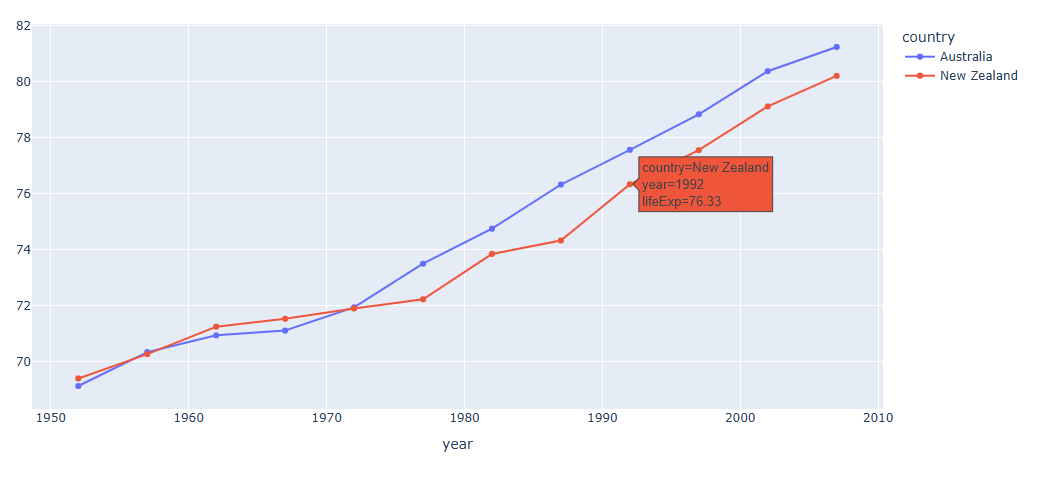
Plotly의 인터렉티브한 시각화 중 하나는 사용자가 마우스 커서를 포인트 위로 이동했을때 설정한 정보가 나타나는 Hover 레이블 기능 입니다.Closest 방법(커서 바로 옆에 생성하기)X or Y 위치(커서와 동일 축의 위치의 그래프정보 생성하기)Unified 모
32.[미래유망] Plotly #05 - 2 Plotly 인터렉티브 환경 문법

함수 안의 내용updatemenus = dict() 형태로 아래의 정보들을 지정합니다.type = "buttons"buttons = ... 버튼의 기능 관련 정보를 각각 dict() 형태로 넣습니다.method= {"restyle", "relayout", "update
33.[미래유망] Plotly 기상청 따라 그래프 만들어보기
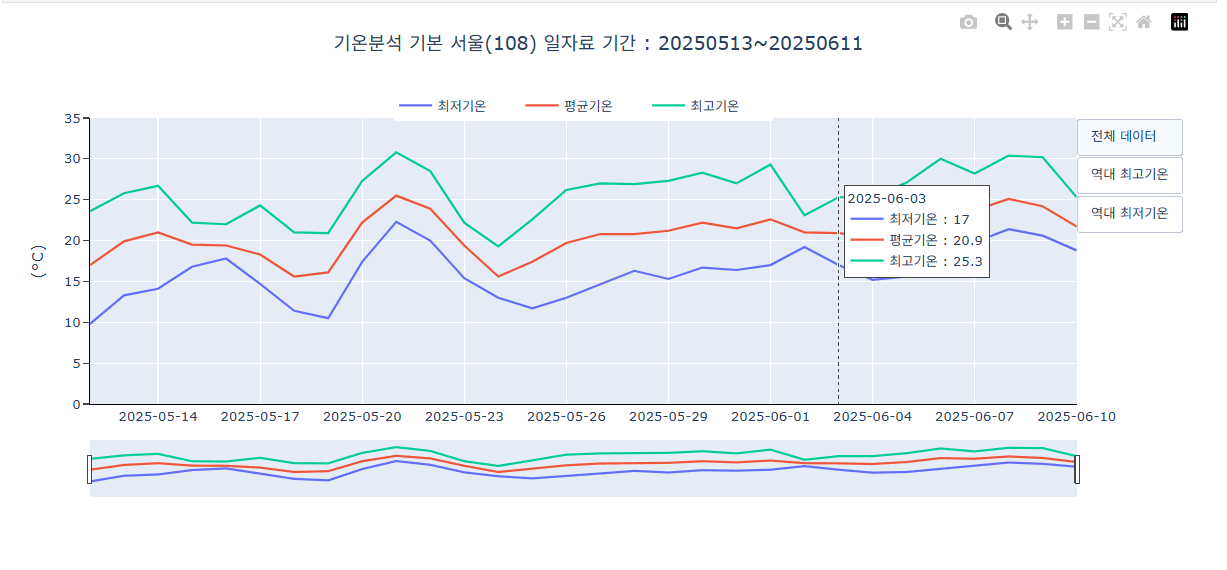
전체 데이터 표시역대 최고 온도 표시역대 최저 온도 표시
34.[미래유망] Plotly #06 - 1 Plotly Basic Chart
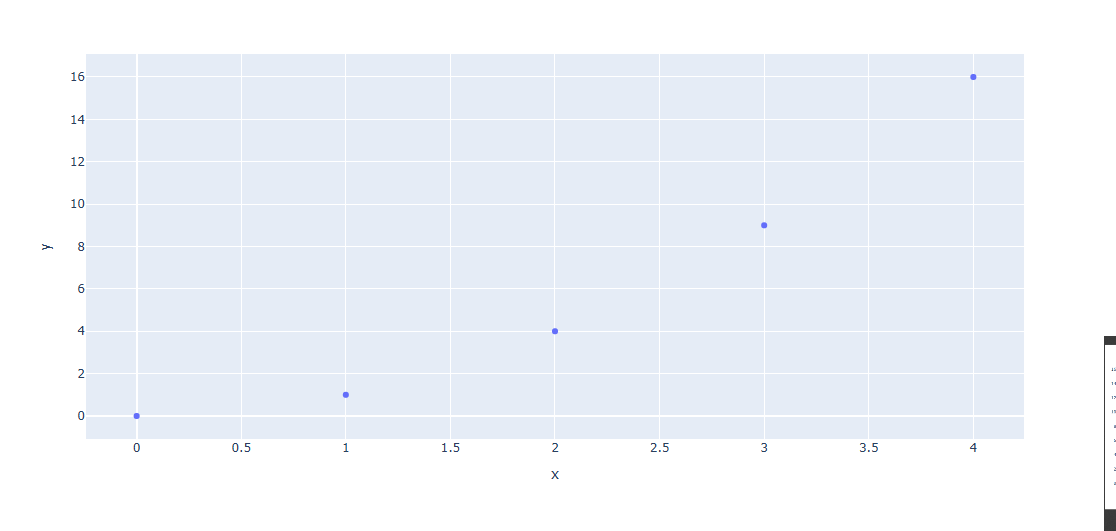
Scattor Plot(산점도)는 두 변수의 상관관계를 점으로 표현한 그래프 입니다.예제 1) 직접 입력 방법예제 2) 데이터 셋을 활용한 방법마커 색으로 데이터 분류하기꽃의 품종에 따라 색깔을 다르게 표시(색을 지정하지 않았기에 기본 팔레트)마커 크기 다르게 표시하기
35.[미래유망] Plotly #06 - 2 Plotly Basic Chart

Bar Plot은 막대 그래프 라고도 하며 범주형 데이터를 직사각형의 막대로 표현하는 그래프 입니다.서울청에서 제일 신고 건수가 높은 것을 확인할 수 있고 두번째는 경기 남부청이다.두 곳이 인구가 다른 지역에 비해 많은 것에 따라 인구가 많으면 범죄 발생 횟수가 높아진
36.Plotly #07 Plotly 통계 차트

Box plot은 상자수염차트, 봉, 캔들 등 다양한 이름을 가진 차트입니다. 데이터의 통계적 의미를 표현할때 자주 사용되는 매우 유용한 차트입니다.음주운전 연령 분포는 20대 후반~40대 중반이 중심이고, 30대 중반~40대가 가장 많은 비중을 차지하는 것을 볼 수
37.[미래유망] Plotly #06 - 3 Plotly Basic Chart
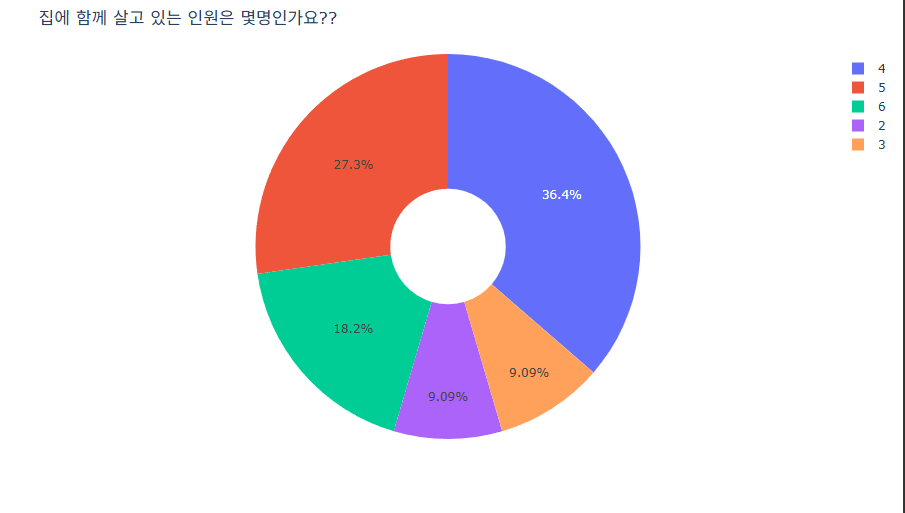
Pie Chart는 파이 차트는 하나의 원을 여러 영역 또는 조각으로 나눈 원그래프입니다. 각 조각은 해당 변수에 대한 한 수준의 관측치 개수 또는 백분율을 나타냅니다.Pie 차트 가운데 구멍이 뚤린 도넛모양의 Pie Chart를 표현하려면 아래의 코드를 추가해야 합니
38.[미래유망] Plotly #08 Scienfitic Chart
Contour Plot Contour Plot은 등치선 또는 등고선 그래프를 뜻합니다. 3차원 데이터를 2차원 공간산에 분포하는 동일한 값을 가지는 인접한 지점을 연속적으로 이어 구성한 선 입니다. 기본 사용법 > Colormap 변경하기 > 컬러맵 커스터마이징하
39.[미래유망] Plotly #09 Financial Chart, 통계 차트 심화
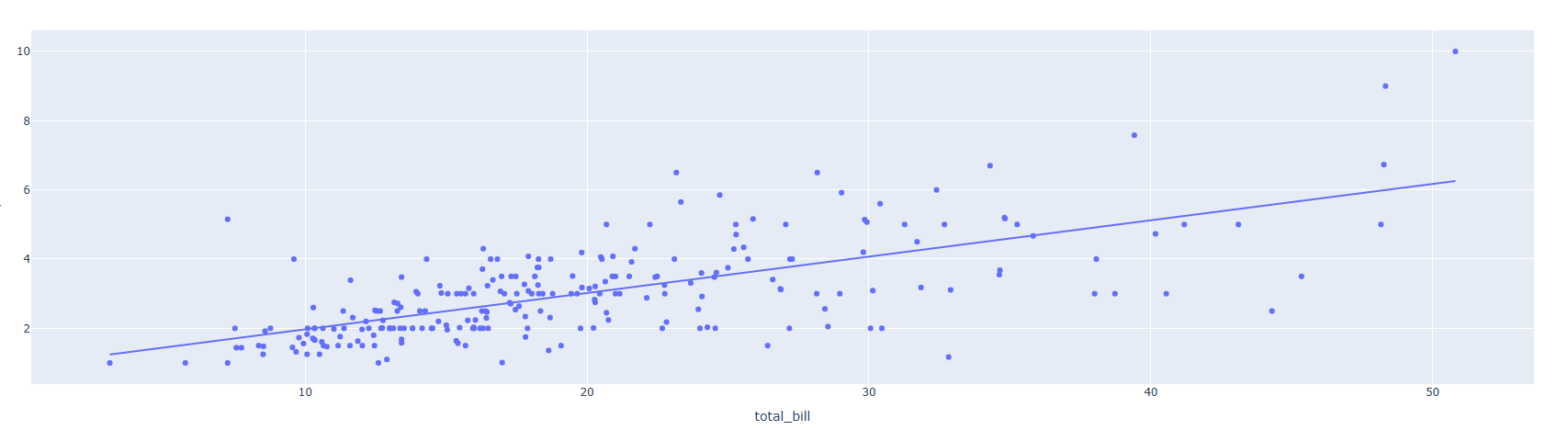
추세선이란 산점도에 나타난 자료의 관계 또는 흐름을 통계적 기법으로 선형 또는 비선형의 선으로 표현한 선 입니다. 보통 경향파악, 미래예측에 사용되며 특히 주식 차트 분석 분야에서 주로 사용됩니다.추세선 기능을 활용하기 위해선 statsmodels 패키지를 추가 설치해
40.[미래유망] Plotly #10 WordCloud

업로드중..
41.[미래유망] Streamlit #01
이 벨로그는 스트림릿(Streamlit) 30일 챌린지(전뇌해커) 님의 위키독스를 보고 작성하였습니다.