
축 기준 (apply)
apply 메서드는 DataFrame에 함수를 적용하여 반환하는 메서드 입니다.
함수에 전달되는 객체는 Seires형식이며 DataFrame의 index(axis=0)이냐
columns(axis=1)이냐에 따라 다릅니다.
최종반환 유형은 적용된 함수에 따라 정해지지만 result_type을 지정하여 변경이 가능합니다.
사용법
df.apply(func, axis=0, raw=False, result_type=None, args=(), kwargs)
function: 각 행이나 열에 적용할 함수 입니다.
axis: {0 : Index / 1 : columns} 함수를 적용할 축 입니다.
row: {True : ndarray / False : Series} 함수에 전달할 축의 형식입니다.
True면 ndarray형태로 전달하고 False면 Series형태로 전달합니다. 기본적으로 Series입니다.
result_type: {expand / reduce / broadcast} 반환값의 형태를 결정합니다. expand이면 배열 형태를
기준으로 열을 확장합니다.(기본 인덱스로), reduce인 경우는 그대로 Serise형태로 반환합니다.
broadcase인 경우 기존 열 형식대로 확장하여 반환합니다.(열의 수가 같아야합니다.)
먼저, 간단한 3x3 객체를 하나 생성하겠습니다.
col = ['col1','col2','col3']
row = ['row1','row2','row3']
data = [[1,2,3],[4,5,6],[7,8,9]]
df = pd.DataFrame(data=data,index=row,columns=col)
print(df)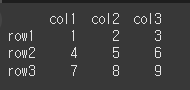
func의 성질에 따른 차이
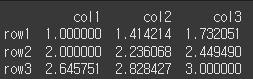
func항목이 np.sqrt처럼 축에대해 계산할 수 없는 형식이라면 아래와 같이 각 요소에 적용됩니다.
print(df.apply(np.sqrt)) # sqrt : 제곱근 계산
축에 대한 계산이 불가능하다.
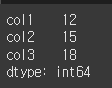
np.sum처럼 축에대해 적용이 가능한경우라면 축 기준으로 연산을 수행합니다.
print(df.apply(np.sum)) # 더하기 연산 적용
축에 대한 계산이 가능하다.
axis에 따른 차이
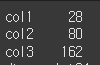
axis가 0인경우 Index(행)에 대해 연산을 수행하고, 1인경우는 columns(열)에 대해 연산을 수행합니다.
print(df.apply(np.prod,axis=0))
행의 0 인덱스끼리 곱하였다.
result_type에 따른 차이
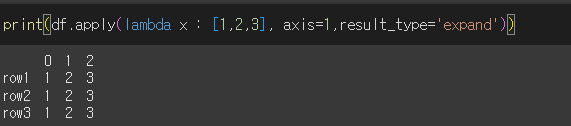
먼저 lamba를 사용하여 기존 DataFrame에 [1,2,3]객체를 apply해보겠습니다.
print(df.apply(lambda x : [1,2,3]))
type에 따라 결과가 다르다.
- expand
- func를 기준으로 확장하여 columns를 지정하게 되는것을 확인할 수 있습니다.
- reduce
- func를 기준으로 축소하여 columns없이 Series 객체로 반환하는것을 확인할 수 있습니다.
- broadcast
- func를 기준으로 확장하되, columns는 기존 DataFrame의 것을 사용하는것을 확인할 수 있습니다.


요소별 (applymap)
applymap 메서드는 객체의 각 요소에 함수를 적용하는 메서드입니다.
즉, apply메서드와는 다르게 DataFrame의 각 요소 하나하나에 함수를 적용하여 스칼라 값을 반환합니다.
사용법
df.apply(func, axis=0, raw=False, result_type=None, args=(), kwargs)
func: 단일 값을 반환하는 함수 입니다.
na_action:{None / 'ignore}NaN의 무시 여부입니다.'ignore'이면NaN을 함수로 전달하지 않습니다.
먼저, pd.NA가 포함된 간단한 3x3 객체를 하나 생성하겠습니다.
col = ['col1','col2','col3']
row = ['row1','row2','row3']
data = [[1,2,3],[4,5,6],[7,pd.NA,9]]
df = pd.DataFrame(data=data,index=row,columns=col)
print(df)
applymap의 적용
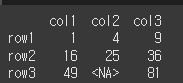
함수 적용시 각 요소에 대해 함수의 연산이 되는것을 확인할 수 있습니다.
print(df.applymap(lambda x : x**2,na_action='ignore'))
제곱을 나타내는 람다식으로 요소가 다 제곱이 되었다.
함수내 함수 연속적용 (pipe)
pipe 메서드는 함수를 연속적으로 사용할 때 유용한 메서드입니다.
특히 함수가 인수를 사용할 때 pipe 메서드를 사용하면 보다 직관적으로 적용할 수 있습니다
사용법
df.pipe(func, args, kwargs)
func: 함수입니다.
arg: 함수의 인수입니다.
kwargs:dict형태의 함수의 인수입니다.
먼저 입력 데이터를 정의해보겠다.
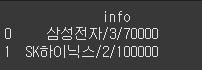
org_data = pd.DataFrame({'info':['삼성전자/3/70000','SK하이닉스/2/100000']})
print(org_data)
일단 입력데이터를 정의하고
함수를 두개 만들겠다.
code_name(data) 는 (종목명/수량/가격)형태인 문자열 data를 입력받아서 각각으로 분리하고 수량과 가격의 dtype을 int로 변경하는 함수 입니다.
def code_name(data):
result=pd.DataFrame(columns=['name','count','price'])
df = pd.DataFrame(list(data['info'].str.split('/'))) # '/ ' 로 구분하여 문자열을 나누어 리스트에 넣음
result['name'] = df[0] # 여기엔 첫번째 값인 이름이 입력
result['count']= df[1] # 여기엔 두번째 값인 수량이 입력
result['price']= df[2] # 여기엔 세번째 값인 가격이 입력
result = result.astype({'count':int,'price':int}) # count와 price를 int로 바꿈(기존str)
return resultvalue_cal(data,unit=' ')은 가격과 수량을 곱한다음에 단위로 unit arg를 붙이는 함수입니다.
def value_cal(data,unit=''):
result = pd.DataFrame(columns=['name','value'])
result['name'] =data['name'] # 이름은 기존거를 가져옴
result['value']=data['count']*data['price'] # value는 count * price를 입력함
result = result.astype({'value':str}) # value를 str로 변경(단위를 붙이기 위함)
result['value']=result['value']+unit # 단위를 붙임
return(result)
input=code_name(org_data)
print(value_cal(input, '원'))
pipe메서드를 사용한다면 아래와같이 직관적으로 나타낼 수 있다.
print(org_data.pipe(code_name).pipe(value_cal,'원'))
함수연속적용_축별 (aggregate, agg)
agg메서드는 apply와 비슷하게 함수를 적용하는 메서드이지만,
여러개의 함수를 동시에 적용할 수 있다는 장점이 있습니다.
그리고 __name__를통해 사용자정의 함수명을 따로 설정할경우 그 이름을 사용한다는 점을 활용하여
함수를 사용한 DataFrame을 보다 깔끔하게 정리하는데도 용이하게 쓸 수 있습니다.
먼저 간단한 3x3짜리 데이터를 만들어보겠다.
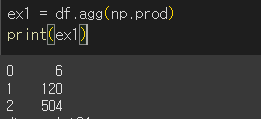
df = pd.DataFrame([[1,4,7],[2,5,8],[3,6,9]])
print(df)
입력되는 함수의 형태
입력함수로는 먼저 np.함수 형태나 그냥 문자열 형태로의 입력이 가능합니다.
- np함수의 경우
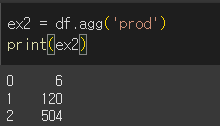
- 문자열인 경우
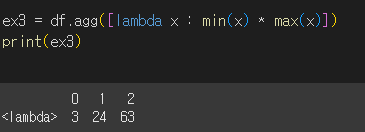
lambda함수나 사용자 정의 함수를사용할 수도 있습니다.
- lambda함수를 사용할 경우 열 명칭은
<lambda>가 됩니다.
- 사용자정의 함수를 사용하게되면 기본적으로 함수명 열 이름으로 설정이 됩니다.
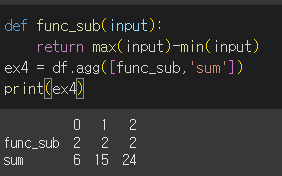
- 만약 함수명을
__name__메서드를 통해 따로 설정해주면 그 이름이 쓰입니다.
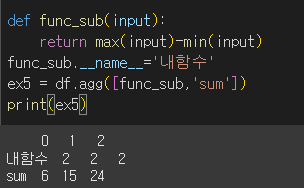
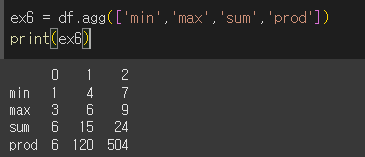
여러 함수를 동시에 적용하는 경우
list나 dict형태로 func값을 입력하는 경우 여러 함수를 동시에 적용할 수 있습니다.
- list로 입력하는 경우
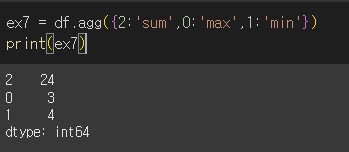
- dict를 이용하는 경우 순서를 변경하는것도 가능합니다.
함수연속적용_요소별 (transform)
transform메서드는 agg와 비슷하게 함수를 적용하는 메서드이지만,
단일 요소별로 함수를 동시에 적용할 수 있다는 장점이 있습니다. 마치 apply와 applymap의 차이와 비슷합니다.
사용법
df.transform(func, axis=0, args, kwargs)
func: 함수입니다.
axis:{0 : index(row) / 1 : columns} 축입니다 0은 행, 1은 열 입니다.
arg: 함수의 인수 입니다.
kwargs: dict 형태의 함수의 인수입니다.
먼저 간단한 3x3짜리 데이터를 만들어보겠다.
col = ['col1','col2','col3']
row = ['row1','row2','row3']
df = pd.DataFrame(data=[[10,40,70],[20,50,80],[30,60,90]],index=row,columns=col)
print(df)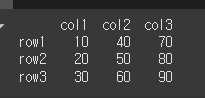
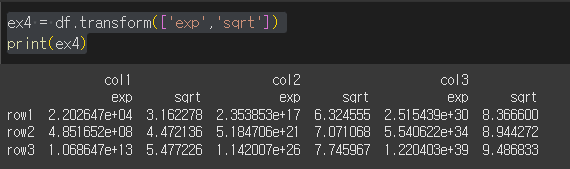
여러 함수를 동시에 적용하는 경우
list나 dict형태로 func값을 입력하는 경우 여러 함수를 동시에 적용할 수 있습니다.
list로 입력하는 경우 마치 multi index처럼 multi columns가 생성됩니다.
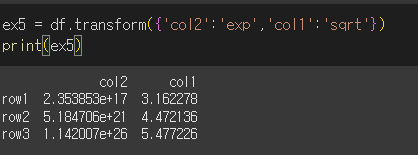
dict를 이용하는 경우 순서를 변경하는것도 가능합니다.
문자열 형식의 계산식 적용 (eval)
eval메서드는 파이썬의 eval 메서드와 사용목적이 동일합니다. 문자열로 된 계산식을 적용합니다.
사용법
df.eval(expr, inplace=False, kwargs)
expr: 문자열 형태의 계산식입니다.
inplace: {True / False} 계산된 값이 원본을 변경할지의 여부입니다. 기본적으로 원본은 변경되지 않습니다.
먼저 기본적인 3x3 DataFrame을 만들겠다.
data = [[1,2,3],[4,5,6],[7,8,9]]
col = ['col1','col2','col3']
row = ['row1','row2','row3']
df = pd.DataFrame(data = data, index = row, columns= col)
print(df)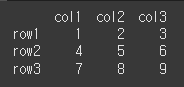
기본적인 사용법
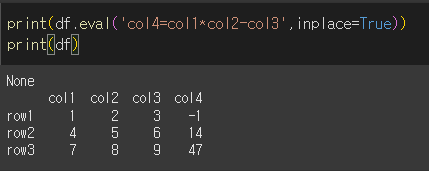
col1*col2-col3의 값을 갖는 col4를 만들어보겠습니다. 'col4'='col1'+'col2'-'col3'를 문자열 그대로 사용합니다.
계산이 적용된 col4열이 생성된 것을 확인할 수 있습니다.
inplace = True인 경우
Inplace = True로 할 경우 원본이 변경되는것을 확인할 수 있습니다.
레이블기반_스칼라 (at)
at 함수는 loc 함수와 같이 레이블 기반으로 인덱싱을 하지만,
DataFrame과 Series에 상관없이 하나의 스칼라값에 접근한다는 차이가 존재합니다.
사용법
값 가져오기 :result = df.at['행', '열']
값 설정하기 :df.at['행', '열'] = value
먼저 아래와 같이 기본적인 2x2 행렬을 만듭니다.
df = pd.DataFrame([[1,2], [3,4]], index=['row1', 'row2'], columns=['col1', 'col2'])
print(df)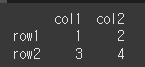
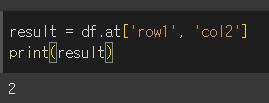
값 가져오기
행, 열 값을 인수로 입력하여 변수에 할당함으로써 값을 가져올 수 있습니다.
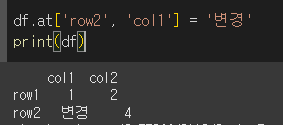
값 설정하기
행, 열 값을 인수로 지정 후 값을 할당하여 값을 설정할 수 있습니다.
기타
loc 메서드를 이용해 Series로 추출한 뒤 at메서드를 이용해 스칼라값을 얻는 방식으로 활용이 가능합니다.
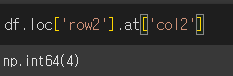
레이블기반_데이터 (loc)
loc 함수는 at 함수와 같이 레이블 기반으로 인덱싱을 합니다. DataFrame이나 Series형식으로의 반환이 필요하면 loc를 사용합니다.
사용법
값 가져오기 :result = df.loc['행', '열']
값 설정하기 :df.loc['행', '열'] = value
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3'])
print(df)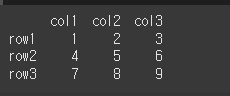
단일 레이블 인덱싱
단일 행: df.loc['row1'] → Series 반환.
단일 열: df.loc[:, 'col1'] → Series 반환.
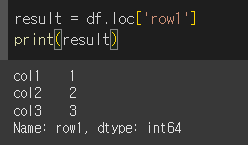
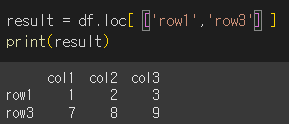
여러 레이블 인덱싱
여러 행: df.loc[ ['row1', 'row3'] ] → DataFrame 반환.
여러 열: df.loc[:, ['col1', 'col2']] → DataFrame 반환.
행, 열, 값 설정
특정 값 접근: df.loc['row2', 'col2'] → 특정 값 반환.
값 변경: df.loc[['row1'], ['col3']] = 'A' → 특정 값 변경.
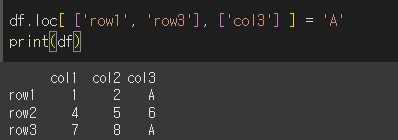
슬라이싱
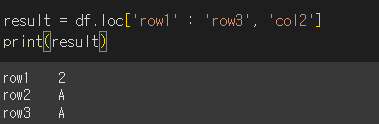
범위 지정: df.loc['row1' : 'row3', 'col2'] → 범위에 맞는 값 선택.
정수기반_스칼라 (iat)
정수기반 조회 메서드입니다. 행/열 한쌍에 대한 단일 값에 엑세스합니다.
사용법
값 가져오기 :result = df.iat['행', '열']
값 설정하기 :df.iat['행', '열'] = value
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3'])
print(df)값 가져오기
정수기반 조회 메서드이기 때문에, 행/열 쌍을 정수로 입력해야합니다.
아래의 경우 [rows=1,columns=2] 를 출력하는 것으로, 0부터 시작하기 때문에 [row2, col3]의 값인 6을 출력하게 됩니다.
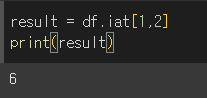
값 설정하기
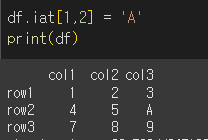
마찬가지로 정수값을 지정하여 해당 행/열의 값을 바꿀 수 있습니다.
앞에서 n행 인덱싱 (head)
head함수는 Dataframe 객체를 위에서부터 n열 반환하는 함수입니다.
기본값은 5입니다.
사용법
df.head(n=5)
먼저, head 함수의 사용을 위해 np.random함수로 10x10 난수 DataFrame를 만들어 보겠습니다.
data = np.random.randint(10,size=(10,10))
df = pd.DataFrame(data=data)
print(df)
n=양수 n이 0보다 크면 위에서부터 n까지 열을 반환합니다
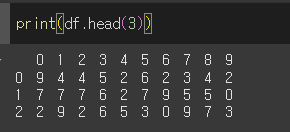
n=음수 n이 0보다 작으면 DataFrame의 끝에서부터 n개열을 제외하고 반환합니다.

