열 삽입 (insert)
insert 메서드는 DataFrame의 특정 위치에 열을 삽입하는 메서드입니다..
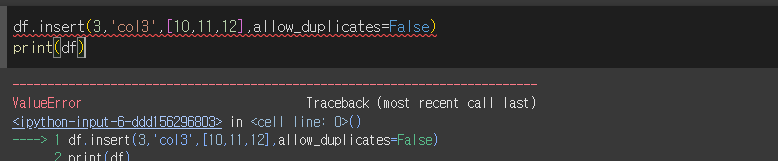
DataFrame에 해당 열이 이미 존재 할 경우 allow_duplicates=True가 아니면 Value Errer를 발생시킵니다.
사용법
df.insert(loc, column, value, allow_duplicates=False)
loc: 삽입될 열의 위치
column: 삽입될 열의 이름
val: 삽입될 열의 값
allow_duplicates: {True or False} 기본값은 False로 True일경우 중복 열의 삽입을 허용합니다.
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
data = [[1,2,3],[4,5,6],[7,8,9]]
col = ['col1','col2','col3']
row = ['row1','row2','row3']
df = pd.DataFrame(data=data,index=row,columns=col)
print(df)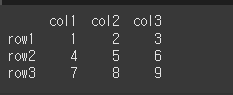
기본적인 사용법
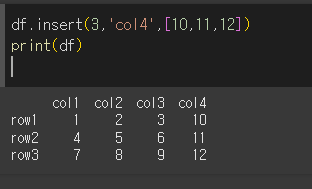
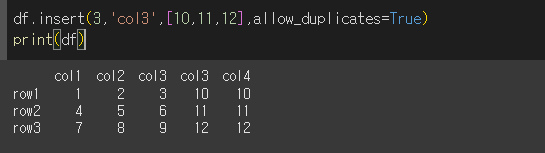
loc=3으로해서 4열로 설정, column을 통해 이름을 col4로하고 value로 값을 설정하여 열을 추가해보겠습니다.
이미 추가되어있는 'col3'을 추가하면 오류를 발생시키게 됩니다.
여기서 allow_duplicates=True하면 중복된 이름으로 col3이 추가되는것을 확인 할 수 있습니다.
열 꺼내기(pop)
pop메서드는 DataFrame에서 열 레이블을 꺼냅니다. 즉, 원본 DataFrame에서 해당 열이 제거됩니다.
사용법
df.pop(item)
item: 꺼낼 열의 이름입니다.
먼저, 아래와 같이 기본적인 4x4 행렬을 만듭니다.
data = [[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]]
col = ['col1','col2','col3','col4']
row = ['row1','row2','row3','row4']
df = pd.DataFrame(data=data,index=row,columns=col)
print(df)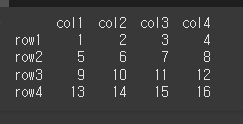
기본적인 사용법
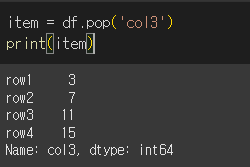
item에 col3을 입력하여 열을 꺼내보겠습니다.
pop한 것을 변수에 넣어 출력해 보면 해당 열이 출력 되는것을 확인 할 수 있습니다.
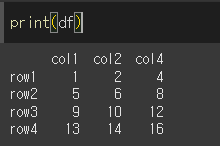
pop함수는 원본에서 꺼낸다는 의미이기 때문에, col3이 원본에서 삭제된것을 알 수 있습니다.
복사 (copy)
Pandas객체를 복사합니다. deep copy와 shallow copy기능을 지원합니다.
사용법
df.copy(deep=True)
deep: {True or False} 기본값 True
deep = True인 경우를 deep copy라고 하며 원본과는 완전하게 별개인 복사본이 생성됩니다. 사본과 원본의 수정은 서로에게 영향을 끼치지 않습니다.
deep = False인 경우를 shallow copy라고 하며 원본의 데이터 및 인덱스를 복사하지않고 새 객체를 호출합니다.
즉, 원본의 데이터가 수정되면 사본의 데이터도 수정되며, 그 반대도 마찬가지 입니다.
먼저, 아래와 같이 series객체를 하나 만들고, deep copy본과 shallow copy본인 객체를 생성해봅니다.
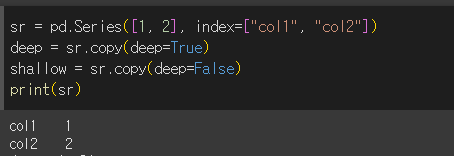
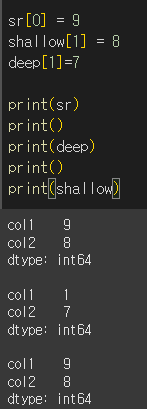
이제 원본인 sr과 deep copy본인 deep, shallow copy본인 shallow의 요소를 변경하고 다시 출력해보겠습니다.
sr은 shallow와 sr자체를 수정했기 때문에 바뀌고
deep에서 복사 후 바꿨을땐 안 바뀐것을 확인할 수 있다.
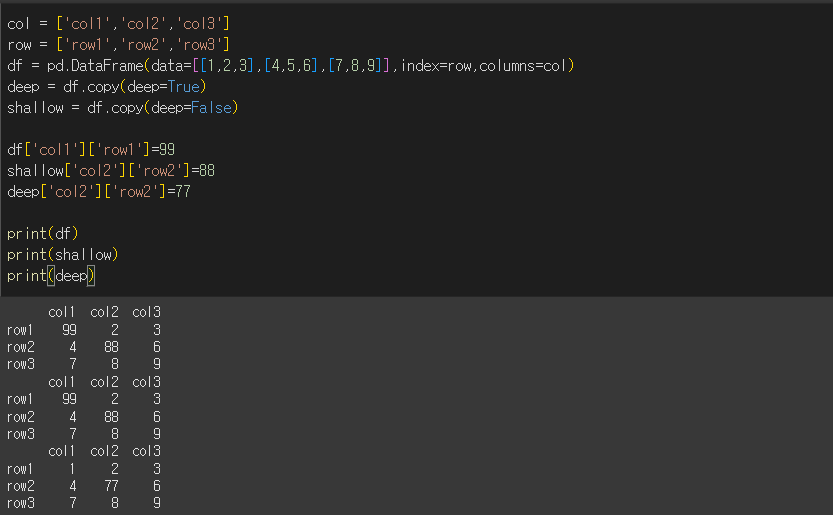
DataFrame의 경우
데이터프레임의 경우도 마찬가지다
행/열 삭제 (drop)
drop메서드는 데이터프레임에서 열을 삭제하는 메서드입니다.
pop메서드와는 다르게 원본이 변경되지 않습니다.
사용법
df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
labels: 삭제할 레이블명입니다. axis를 지정해주어야합니다.
axis: {0 : index / 1 : columns} labels인수를 사용할경우 지정할 축입니다.
index: 인덱스명을 입력해서 바로 삭제를 할 수 있습니다.
columns: 컬럼명을 입력해서 바로 삭제를 할 수 있습니다.
level: 멀티인덱스의 경우 레벨을 지정해서 진행할 수 있습니다.
inplace: 원본을 변경할지 여부입니다. True일경우 원본이 변경됩니다.
errors: 삭제할 레이블을 찾지 못할경우 오류를 띄울지 여부입니다. ignore할 경우 존재하는 레이블만 삭제됩니다.
※ axis=0 + labels 는 index인수와 역할이 같고 axis=1 + labels는 columns와 역할이 같습니다.
먼저, 아래와 같이 간단한 3x3 객체를 만들어 보겠습니다.
row = ['row1','row2','row3']
col = ['col1','col2','col3']
data = [[1,2,3],[4,5,6],[7,8,9]]
df = pd.DataFrame(data=data, index=row, columns=col)
print(df)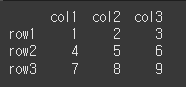
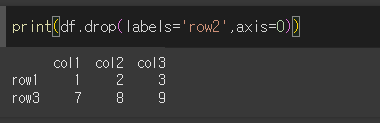
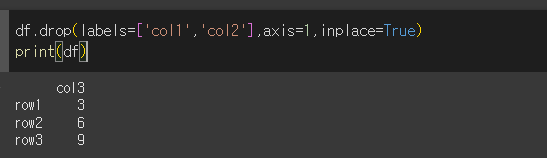
labels인수와 axis인수로 삭제
labels인수로 삭제할 레이블명을 지정해주게되면, axis인수를 통해 해당 레이블(축)을 지정해주어야합니다.
row2 를 삭제해보겠습니다.
row2가 삭제된것을 볼 수 있다.
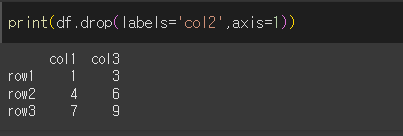
axis를 1로 하였을때는 열을 삭제할 수 있다.
index인수와 columns 인수로 삭제
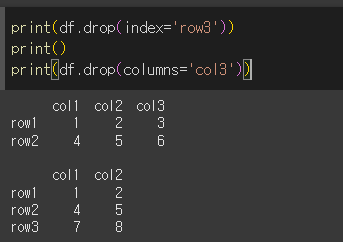
index인수와 columns인수를 사용하면 labels인수와 axis 사용 없이 삭제가 가능합니다.
index를 사용해서 row3을 삭제해보겠습니다.
index로 하였을때는 행을
colums로 하였을때는 열을 삭제한 것을 알 수 있다.
errors 인수 예시
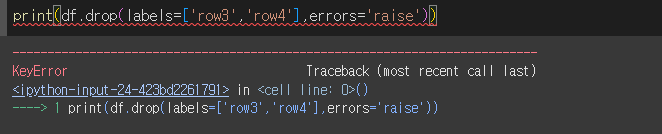
삭제하고자하는 레이블이 존재하지 않으면 오류가 발생하게됩니다. errors='ignore'로 설정하면 오류를 발생하지 않습니다.
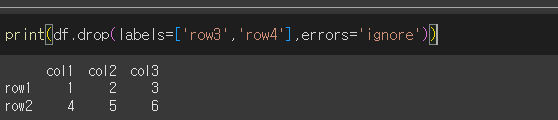
row3, row4를 삭제해보겠습니다.(row4는 존재하지 않음)
하지만 errors='ignore'로 실행한다면
오류없이 존재하는 row3이 삭제된 것을 확인할 수 있습니다.
inplace인수로 원본 변경
inplace인수는 Pandas객체의 공통사항으로 원본의 변경여부를 의미합니다.
True일 경우 반환값 없이 원본이 변경됩니다.
행 추가 (append)
append 메서드는 데이터프레임에 행을 추가하는 메서드입니다.
두 데이터프레임 객체를 행 기준으로 합치는 개념입니다.
사용법
self.append(other, ignore_index=False, verify_integrity=False, sort=False)
other: self 객체에 행 기준으로 합칠 객체입니다.
ignore_index: 기존 인덱스를 사용할지 여부 입니다. False로 할 경우 0,1,2,..,n 이 부여됩니다.
verify_integrity: 합칠 때 이름이 중복되는 인덱스가 있을 경우 오류를 발생시킬지 여부 입니다.
sort: 열을 사전적으로 정렬할 지 여부입니다.
먼저, 아래와 같이 간단한 2x2 객체를 만들어 보겠습니다.
df = pd.DataFrame(data=[[1,2],[3,4]], index=['row1','row2'], columns=['col1','col3'])
print(df)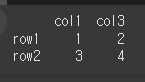
기본적인 사용법(+sort, ignore_index)
먼저 간단한 df2를 만들어 append로 df와 합쳐보겠습니다.
df2 = pd.DataFrame(data=[[5,6]],index=['row3'],columns=['col2','col4'])
print(df2)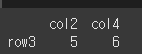
row3이 행추가 되었고 기존df에는 없던 col2과 col4가 생성된것을 확인할 수 있습니다.
sort인수를 사용하면 열을 사전적으로 정렬 할 수 있습니다.
sort를 사용해 정렬한 것을 확인할 수 있다.
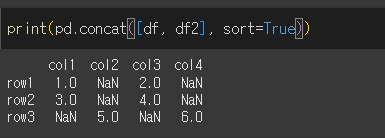
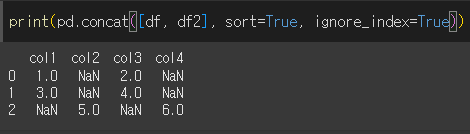
ignore_index인수를 사용하면 기존 index를 무시할 수 있습니다.
기존 index를 무시하고 0, 1, 2로 바뀐것을 확인할 수 있다.
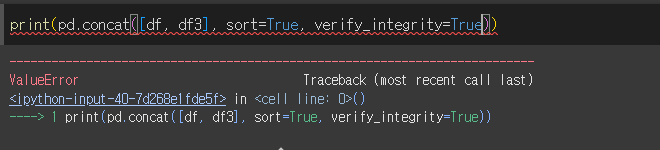
verify_integrity인수의 사용
verify_integrity 인수를 True로 설정하면 이름이 중복되는 인덱스가 존재할 경우 오류를 발생시킵니다.
먼저 중복되는 인덱스가 있는 2x2 객체를 하나 생성하겠습니다.
df3 = pd.DataFrame(data=[[7,8],[9,0]], index=['row2','row3'], columns=['col1','col3'])
print(df3)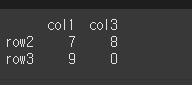
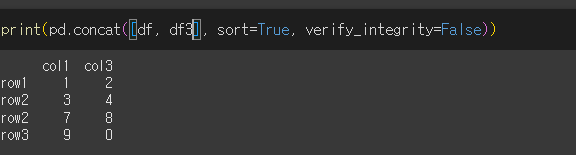
verify_integrity가 False일 경우 (기본값)
verify_integrity가 True일 경우
자르기 (truncate)
turncate메서드는 행이나 열에 대해서 앞뒤를 자르는 메서드 입니다.
사용법
df.truncate(before=None, after=None, axis=None, copy=True)
before: 이 기준 이전을 삭제합니다.
after: 이 기준 이후를 삭제합니다.
axis: 자를 축 입니다.
copy: 사본을 생성할지 여부입니다.
먼저, 아래와 같이 간단한 4x4 객체를 만들어 보겠습니다.
row = ['row1','row2','row3','row4']
col = ['col1','col2','col3','col4']
data = [[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]]
df = pd.DataFrame(data=data, index=row, columns=col)
print(df)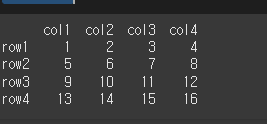
기본적인 사용법
before, after, axis를 이용하여 앞뒤를 잘라보겠습니다.
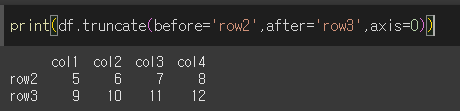
행 자르기 (row2 이전, row3이후 자르기)
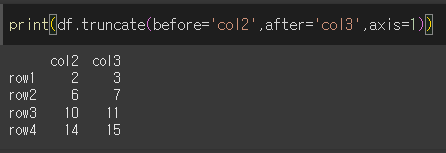
열 자르기 (col2 이전, col3이후 자르기)
중복행 제거 (drop_duplicates)
drop_duplicates메서드는 내용이 중복되는 행을 제거하는 메서드입니다.
사용법
df.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
subset: 중복값을 검사할 열 입니다. 기본적으로 모든 열을 검사합니다.
keep: {first / last} 중복제거를할때 남길 행입니다. first면 첫값을 남기고 last면 마지막 값을 남깁니다.
inplace: 원본을 변경할지의 여부입니다.
ignore_index: 원래 index를 무시할지 여부입니다. True일 경우 0,1,2, ... , n으로 부여됩니다.
먼저, 아래와 같이 간단한 5x3 객체를 만들어 보겠습니다.
col = ['col1','col2','col3']
data = [['A','x','-'],['A','x','-'],['B','x','앞'],['B','y','-'],['B','y','뒤']]
df = pd.DataFrame(data=data, columns=col)
print(df)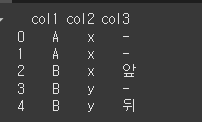
기본적인 사용법
subset에 입력된 컬럼명을 기준으로 해당 컬럼의 중복값을 검사하게됩니다.
subset이 따로 입력되지 않는 경우는 모든 열에대해 값이 중복인 행을 제거합니다.
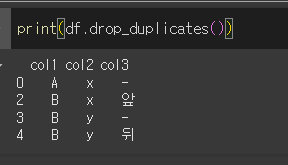
subset에 특정 컬럼명만 입력할 경우, 해당 열에대해서만 중복값 검사를 수행합니다.
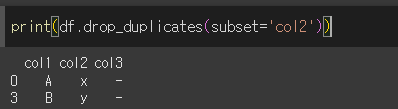
subset에 리스트를 입력할 경우 해당 열들에대해서 모두 중복인 경우만 삭제를 진행합니다.
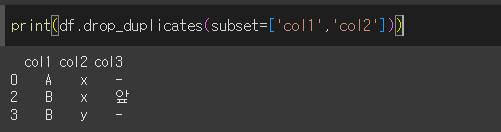
keep인수를 통해 남길 행 선택
keep인수를 통해서 중복값을 제거하고 남길 행을 선택할 수 있습니다.
keep='first'인 경우 처음 값을 남깁니다. (기본값)
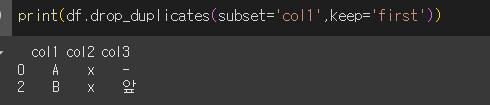
keep='last'인 경우 마지막 값을 남깁니다.
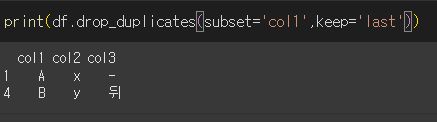
추가로 ignore_index=True로 할 경우 결과값의 인덱스를 0, 1, 2, ... , n으로 설정합니다.

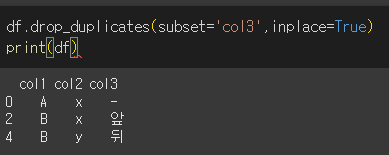
inplace 인수의 사용
Pandas 공통사항으로 inplace인수를 사용할 경우 원본에 변경이 적용됩니다.
차원축소, 스칼라 변환 (squeeze)
squeeze메서드는 차원을 축소(압축)하는 메서드입니다. 예를들어 한개의 행이나 열만 있는 DataFrame을 squeeze하면 Series 객체가 되며, 1개 인덱스만 있는 Series를 squeeze하면 스칼라값이 됩니다. 마찬가지로 1행,1열만 있는 DataFrame 객체를 squeeze하면 스칼라 값이 됩니다.
사용법
df.squeeze(axis=None)
axis: 압축을 진행할 축 입니다.
먼저, 아래와 같이 간단한 2x2 객체를 만들어 보겠습니다.
df=pd.DataFrame(data=[[1,2],[3,4]],index=['row1','row2'],columns=['col1','col2'])
print(df)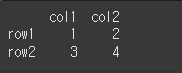
DataFrame을 Series로
1개의 열이나 1개의 행만 있는 DataFrame객체를 squeeze하면 Series 객체가 됩니다.
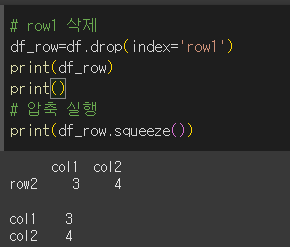
먼저 row1을 drop하여 1행짜리 DataFrame을 만들고 squeeze하겠습니다.
결과값이 Series객체로 변환된 것을 확인할 수 있습니다.
DataFrame을 스칼라 값으로 압축
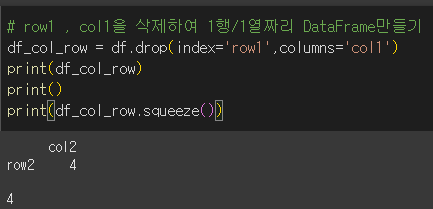
col1과 row1을 삭제해서 요소1개짜리 DataFrame을 생성하고, squeeze를 실행하면 스칼라값이 반환됩니다.
압축할 수 없는 경우
압축할 수 없는경우 원본을 반환합니다.
피벗변환 (pivot)
pivot메서드는 데이터의 열을 기준으로 피벗테이블로 변환시키는 메서드 입니다.
사용법
df.pivot(index=None, columns=None, values=None)
index: 인덱스로 사용될 열입니다.
columns: 열로 사용될 열 입니다.
values: 값으로 입력될 열 입니다.
※ index나 columns에 리스트를 입력 할 경우 멀티 인덱스로 피벗테이블이 생성됩니다.
values에 리스트를 입력 할 경우 각 값에 대한 테이블이 연속적으로 생성됩니다.
먼저, 아래와 같이 간단한 6x4 객체를 만들어 보겠습니다.
col = ['Machine','Country','Price','Brand']
data = [['TV','Korea',1000,'A'],
['TV','Japan',1300,'B'],
['TV','China',300,'C'],
['PC','Korea',2000,'A'],
['PC','Japan',3000,'E'],
['PC','China',450,'F']]
df = pd.DataFrame(data=data, columns=col)
print(df)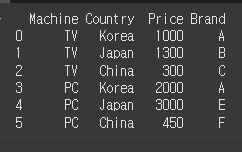
기본적인 사용법
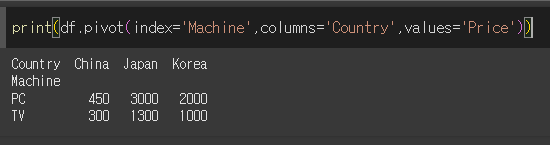
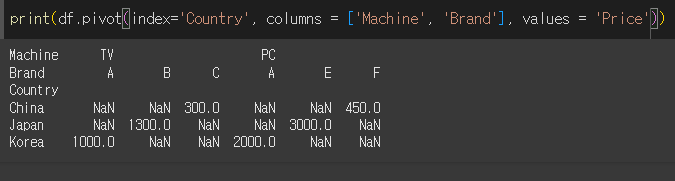
index를 Machine으로 columns를 Country로, values를 Price로 피벗 테이블을 생성해보겠습니다.
values값이 list형태일 경우 피벗테이블이 옆쪽으로 연속으로 생성됩니다.
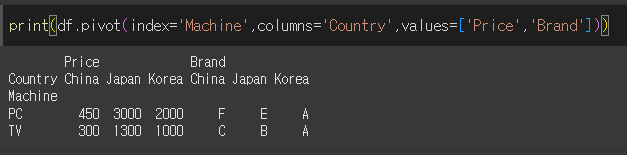
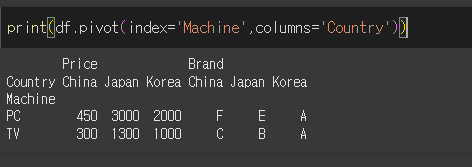
참고로, values를 따로 입력하지 않으면 남은 모든 열이 values에 입력되어 연속으로 출력됩니다.
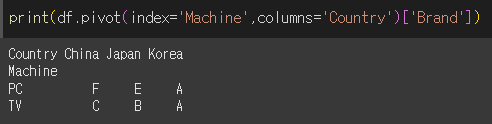
그 상태에서 [열 이름] 형태를 붙여서 원하는 values만 출력할 수 있습니다.
Multi index로 피벗 변환
index나 columns에 list형태의 데이터를 입력할 경우 멀티 인덱스 형식으로 피벗 테이블이 생성됩니다.
index가 list형태일 경우
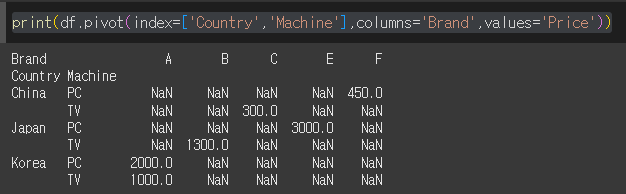
columns가 list형태일 경우
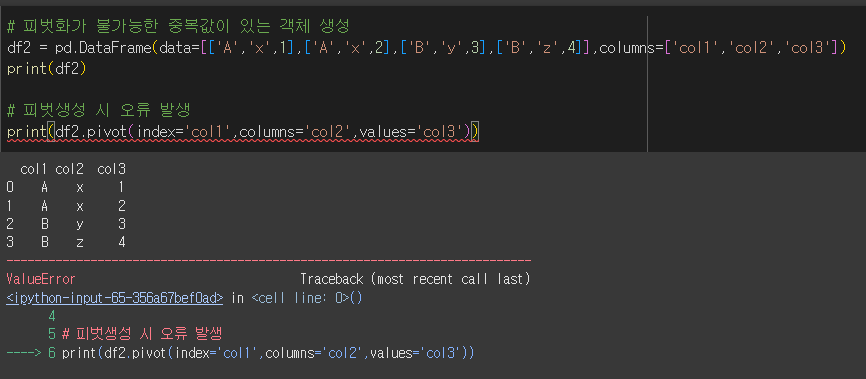
피벗변환이 불가한 경우
중복값으로인해 피벗테이블의 생성이 불가능한 경우 오류를 반환합니다.
피벗생성_스프레드시트 기반 (pivot_table)
pivot_table메서드는 데이터를 스프레드시트 기반 피벗 테이블로 변환하는 메서드입니다.
엑셀 스프레드시트 피벗 테이블과 유사한 기능을 합니다.
사용법
df.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
values: 값으로 입력될 열 입니다.
index: 인덱스로 사용될 열입니다.
columns: 열로 사용될 열 입니다.
aggfunc: 결과로 출력될 함수 입니다.
fill_value: 결측치를 채워넣을 값입니다.
margins: 합계를 표시할지 여부입니다. True일 경우 새 열을 생성하여 합계를 출력합니다.
dropna: 항목이 모두 결측치인 열을 포함할지 여부입니다. 기본값은 True로 포함하지 않습니다.
margins_name: margins가 True일 경우 해당 열의 이름입니다.
observed: 범주형 그룹에 대해 관찰된 값만 표시할지 여부 입니다.
sort: 각 범주들을 사전적으로 정리할지 여부입니다. 기본값은 True로 정렬이 수행됩니다.
먼저, 아래와 같이 간단한 9x5 객체를 만들어 보겠습니다.
col = ['Machine','Country','Grade','Price','Count']
data = [['TV','Korea','A',1000,3],
['TV','Korea','B', 800,8],
['TV','Korea','B', 800,2],
['TV','Japan','A',1300,5],
['TV','Japan','A',1300,1],
['PC','Korea','B',1500,6],
['PC','Korea','A',2000,9],
['PC','Japan','A',3000,3],
['PC','Japan','B',2500,3]]
df = pd.DataFrame(data=data, columns=col)
print(df)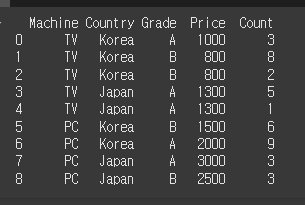
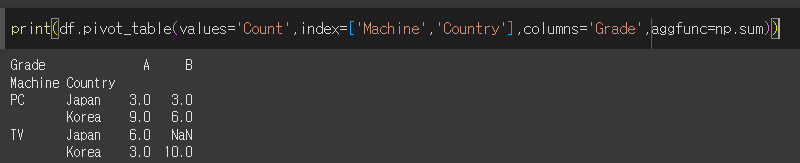
기본적인 사용법
index를 Machine, Country로 하고 columns를 Grade로 설정하고 Count값들을 np.sum으로 합계를 계산하여 스프레드 시트로 출력해보겠습니다.
sort인수의 사용
결과는 기본적으로 사전적으로 정렬이 되어있습니다. PC와 TV, Japan과 Korea는 알파벳순서로 정렬되어있습니다.
sort를 False로하면 기존 입력 순서대로 출력이 됩니다.

여러 값에 대해 여러 함수 적용
엑셀의 피벗테이블과 유사하게 여러 값에 대해서 여러 값(values)에 대해 여러 함수(aggfunc)를 설정할 수 있습니다.
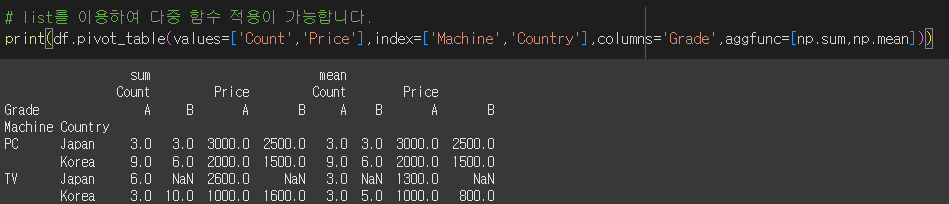
dict를 이용할 경우 각 값에 대해서 특정 함수의 적용이 가능합니다.

fill_value를 이용한 결측치 제거
fill_value에 값을 입력하므로서 결측치를 해당 값으로 대체할 수 있습니다.

margines / margines_name 인수의 사용
margines를 이용해서 총계를 출력할 수 있으며 margines_name을 이용해서 해당 레이블의 이름을 지정할 수 있습니다.
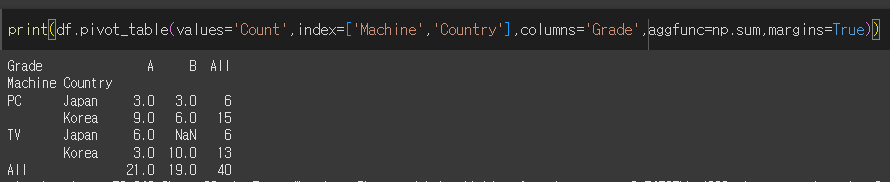
All로 출력된 행/열의 이름을 변경해보겠습니다.

피벗해제 (melt)
melt 메서드는 피벗 형태의 DataFrame을 기존 형태로 해체하는 메서드입니다.
사용법
df.melt(id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
id_vars: 기준이 될 열 입니다.
value_vars: 기준열에 대한 하위 카테고리를 나열할 열을 선택합니다.
var_name: 카테고리들이 나열된 열의 이름을 설정합니다.
value_name: 카테고리들의 값이 나열될 열의 이름을 설정합니다.
col_level: multi index의 경우 melt를 수행할 레벨을 설정합니다.
ignore_index: 인덱스를 1,2,3, ... , n으로 설정할지 여부입니다. 기본적으로 True로 1,2,3, ... , n으로 설정됩니다.
먼저, 아래와 같이 간단한 4x4 객체를 만들어 보겠습니다.
col = ['Country','Machine','Price','Brand']
data = [['Korea','TV',1000,'A'],
['Japan','TV',1300,'B'],
['Korea','PC',2000,'A'],
['Japan','PC',3000,'E']]
df = pd.DataFrame(data=data, columns=col)
print(df)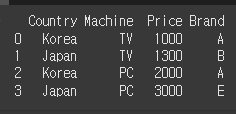
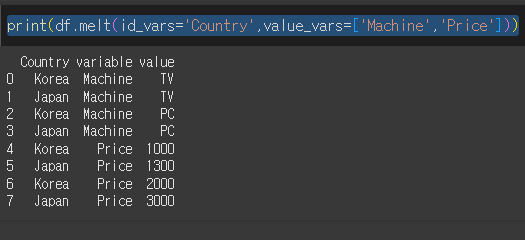
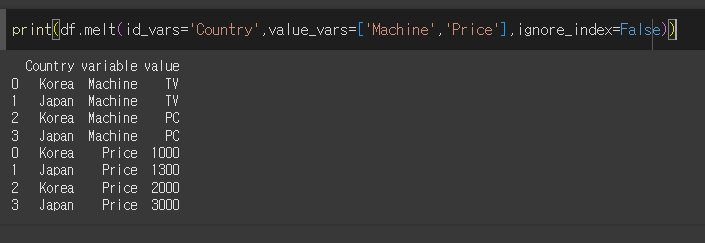
기본적인 사용법
Country를 기준으로하여 Machine과 Price의 값을 하위 카데고리로 melt를 수행해보겠습니다.
ignore_index를 False로 할 경우 기존 인덱스를 사용하게 됩니다.
var_name과 value_name을 지정함으로써 열 이름의 기본값인 variable과 value를 원하는 값으로 변경할 수 있습니다.

Multi-Index의 경우
Multi-Index(Multi-Columns)의 경우에는 인수들을 리스트-튜플로 설정하거나 col_level을 지정해줌으로써 원하는대로 출력이 가능합니다.
먼저 기존의 Country열을 좀더 세분화하여 Country-City로 Multi-Columns을 생성해보겠습니다.
col2 = [['Area','Area','Value','Value','Value'],['Country','City','Machine','Price','Brand']]
data2 =[['Korea','Seoul','TV',1000,'A'],
['Japan','Tokyo','TV',1300,'B'],
['Korea','Jeju','PC',2000,'A'],
['Japan','Kyoto','PC',3000,'E']]
df2=pd.DataFrame(data=data2, columns=col2)
print(df2)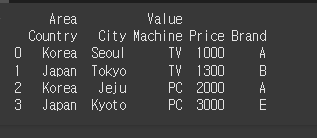
이제 City에대해서 Price만 출력해보겠습니다.
하위 레벨에대해 출력할 경우 튜플을 이용해서 ('Area','City')로, ('Value','Price')로 세부설정을 입력하여 출력할 수 있습니다.
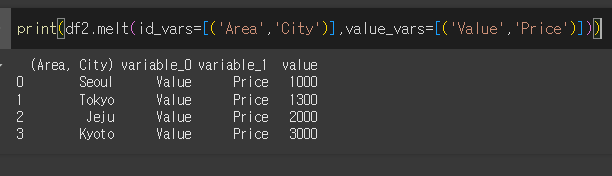
col_level을 설정해 줄 경우 보다 간단하게 하위 카테고리의 출력이 가능합니다.

새 열 할당 (assign)
assign메서드는 DataFrame에 새 열을 할당하는 메서드입니다.
할당할 새 열이 기존열과 이름이 같을경우 덮어씌워집니다.
사용법
df.assign(kwargs)
kwargs: 새열이름 = 내용 형식으로 입력되는 키워드입니다. 콤마(,)를 통해 여러개를 입력할 수 있습니다.
먼저, 아래와 같이 간단한 3x1 객체를 만들어 보겠습니다.
df = pd.DataFrame(index=['row1','row2','row3'],data={'col1':[1,2,3]})
print(df)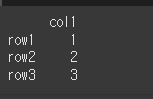
기본적인 사용법
lambda를 이용해 col1에 +2를 한 값으로 col2를 생성해보겠습니다.
col1의 2를 더한 값이 col2로 추가된 것을 볼 수 있다.
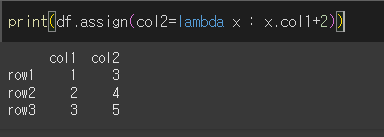
lambda를 사용하지 않고 아래와같이 새 열을 추가할 수 있다.

동시에 여러열 할당
쉼표로 구분을 지으면서 여러개의 열을 할당할 수 있습니다.
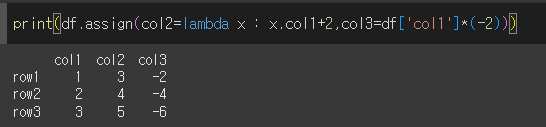
열이 중복될 경우
만약 추가할 새 열의 이름이 기존열과 중복된다면, 새 값으로 덮어씌워집니다.
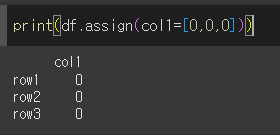
값 변경 (replace)
replace메서드는 객체 내 값을 다른 값으로 변경하는 메서드입니다.
사용법
df.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad')
to_replace: 변경전 기존 값입니다.
value: 변경될 값입니다.
inplace: 원본을 변경할지 여부입니다.
limit: method 사용시 변경 될 갯수 입니다.
regex: regex 문법을 이용하여 변경값을 정합니다.
먼저, 아래와 같이 간단한 4x4 객체를 만들어 보겠습니다.
col = ['col1','col2','col3','col4']
row = ['row1','row2','row3','row4']
data = [['A','w',1,'alpha'],['B','x',2,'beta'],['C','y',3,'gamma'],['D','z',4,'delta']]
df = pd.DataFrame(data=data, index=row, columns=col)
print(df)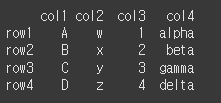
기본적인 사용법
객체 전체에서 1을 99로 변경해보겠습니다.
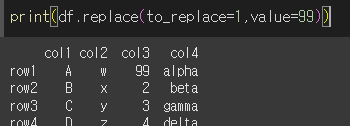
to_replace값이 list형태이고 value값이 단일값이면 전체가 동일하게 변경됩니다.
A, B, y, z를 -로 변경해보겠습니다.
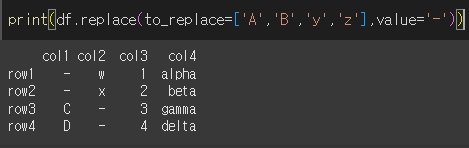
to_replace값과 value값이 모두 같은 길이의 list형태일 경우 각각 같은 순서의 값으로 변경됩니다.
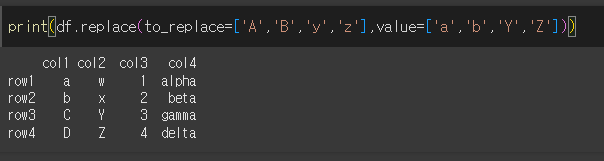
A, B, y, z를 각각 a, b, Y, Z로 변경해보겠습니다.
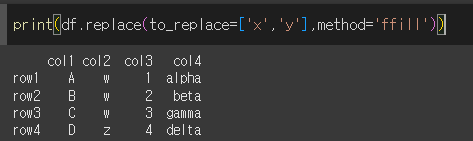
method와 limit인수의 사용
method가 ffill일 경우 to_replace값을 바로 위 값으로 변경하며, bfill일 경우 to_replace값을 바로 아래 값으로 변경합니다.
method가 ffill인 경우
method가 bfill인 경우
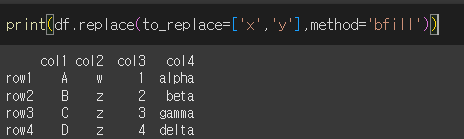
method인수를 사용할때 limit인수를 통해 변경될 갯수를 지정할 수 있습니다. limit=1을 통해 1개만 변경해보겠습니다.
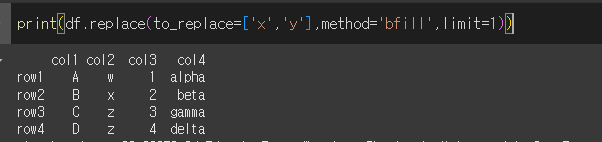
dict형식의 사용
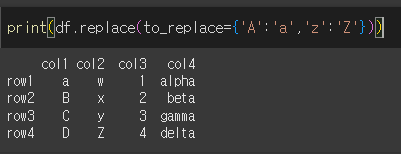
to_replace에 dict형태를 입력하여 value값 설정 없이 변경이 가능합니다.
A를 a로, z를 Z로 변경해보겠습니다.
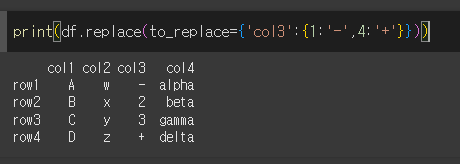
dict안에 dict를 넣음으로써 특정 열의 특정값을 원하는 값으로 변경 할 수 있습니다.
col3을 대상으로 1을 -로, 4를 +로 변경해보겠습니다.
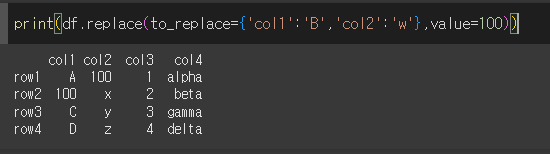
dict를 통해 각 열의 변경 원하는 값을 지정 후 value를 통해 변경이 가능합니다.
col1열에서 B를, col2열에서 w를 100으로 변경해보겠습니다.
regex의 사용
regex를 사용할 경우 정규표현식으로 원하는 값을 지정해서 변경 할 수 있습니다.
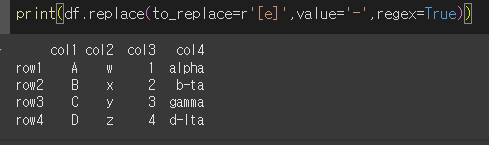
to_replace를 r'[e]'로 지정하고value를-로 하여 문자열에e가 포함될 경우-로 바꿔보겠습니다.
※이때 regex=True로 해서 활성화를 진행해주어야 합니다.
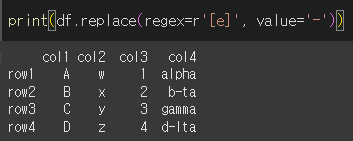
to_replace를 사용하지 않고 단순히 regex에 정규표현식을 입력하여도 동일한 결과를 얻을 수 있습니다.
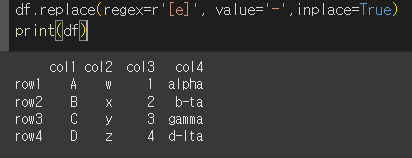
inplace를 통한 원본의 변경
Pandas 공통사항으로 inplcace=True일 경우 원본을 변경하게 됩니다.
리스트 형태의 값 전개 (explode)
explode 메서드는 리스트형태의 값을 여러 행으로 전개하는 메서드 입니다
사용법
df.explode(column, ignore_index=False)
column: 전개할 리스트형태의 데이터가 있는 열 입니다.
ignore_index: True일 경우 기존 인덱스를 무시하고 0,1,2, ... , n 형태의 인덱스로 변환됩니다.
먼저 기본적인 사용법 예시를위하여 리스트 형태의 데이터가 포함된 3x3짜리 데이터를 만들어보겠습니다.
data= [[[1,2,3],0,['a','b','c']],[4,[],3],[5,2,['x','y','z']]]
idx = ['row1','row2','row3']
col = ['col1','col2','col3']
df = pd.DataFrame(data = data, index = idx, columns = col)
print(df)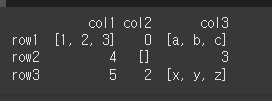
기본적인 사용법
리스트형태의 데이터가 있는 열을 지정함으로써 해당 리스트를 여러행으로 전개할 수 있습니다.
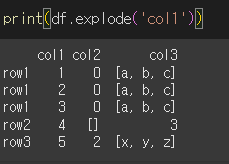
col1열을 전개해보겠습니다.
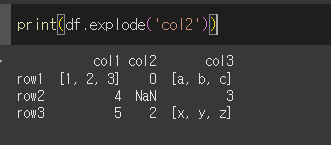
빈 리스트의 경우 NaN이 반환됩니다.
행에 여러개의 리스트 형태의 데이터가 있을 경우 모두 전개합니다.

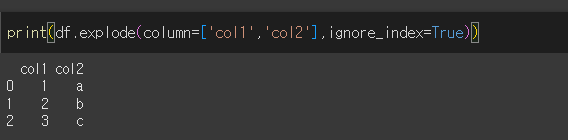
여러 열을 동시에 전개할 경우
여러 열을 동시에 전개하려면 해당 열의 같은 행에 있는 리스트 형태의 데이터가 같은 길이를 가져야 합니다.
먼저, 해당 예시를 만족하는 데이터를 만들어 보겠습니다.
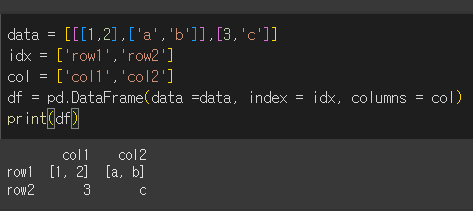
row1에 같은 길이를 갖는 리스트 형태의 데이터가 있습니다.
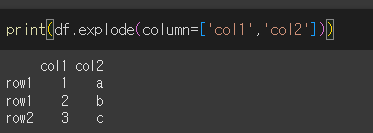
ignore_index인수의 사용
ignore_index=True인 경우 기존 인덱스는 무시되고 0, 1, 2, ... , n 형태의 인덱스로 변경됩니다.