인덱스 (Index)
index메서드는 pandas객체의 index(행)를 출력합니다.
사용법
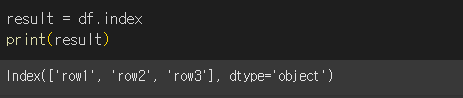
df.index
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3'])
print(df)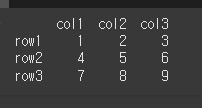
실행 결과
실행결과는 아래와 같이 Index명과 type이 차례로 출력되는것을 볼 수 있습니다.
반환 타입은 pandas의 Index타입임을 사용에 참고 바랍니다.
열 (Columns)
columns메서드는 pandas객체의 columns(열)을 출력합니다.
사용법
df.columns
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3'])
print(df)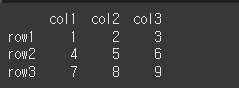
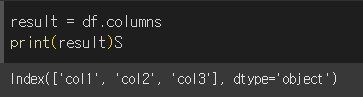
실행 결과
실행결과는 아래와 같이 columns명과 type이 차례로 출력되는것을 볼 수 있습니다. 반환 타입은 index함수에서와 같이 pandas의 Index타입임을 사용에 참고 바랍니다.
데이터 타입 (dtype)
dtypes 메서드는 열에 포함된 데이터들의 type을 Series형태로 반환합니다.
반환된 Series의 index는 원래 DataFrame 객체의 columns(열)에 해당됩니다.
사용법
df.dtypes
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,'A',3.1], [4,'B',6.2], [7,'C',9.3]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3'])
print(df)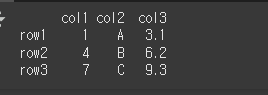
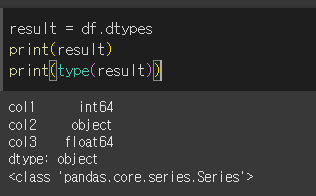
실행 결과
아래와 같이 실행 시 각 columns에 대해 dtypes를 반환합니다. 만약 type이 혼합되어있는경우
object 타입으로 반환합니다
축 (axes)
axes메서드는 DataFrame 객체의 축(axes) 레이블 정보를 list형태로 반환합니다.
list의 첫 번째 요소는 행(row), 두 번째 요소는 열(columns)로 반환되며, 각각의 type은 index입니다.
추가로 요소의 type이 함께 출력됩니다.
사용법
df.axes
먼저, 아래와 같이 기본적인 4x2 행렬을 만듭니다.
df = pd.DataFrame(data=[[1,2],[3,4],[5,6],[7,8]],index=['row1','row2','row3','row4'],columns=['col1','col2'])
print(df)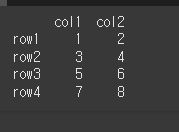
실행 결과
df.axes실행시 아래와 같이 list형태로 축의 정보가 출력되는것을 확인할 수 있습니다.
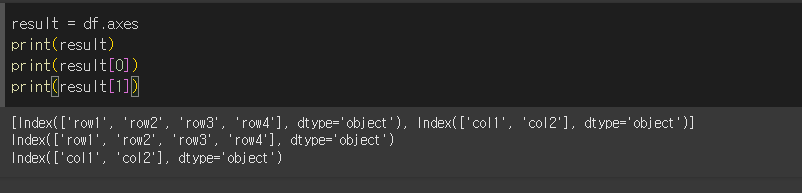
차원 (ndim)
ndim메서드는 데이터의 차원(축의 수)를 반환합니다. Series일경우 1차원, DataFrame이면 2차원이므로
데이터의 종류 파악에 사용할 수 있습니다.
사용법
df.ndim
간단히 Series객체와 DataFrame객체를 만들어 보겠습니다.
# 시리즈
df1 = pd.Series({'idx1':1,'idx2':2,'idx2':2})
print(df1)
print()
# 데이터 프레임
df2 = pd.DataFrame(data=[[1,2],[3,4]],index=['row1','row2'],columns=['col1','col2'])
print(df2)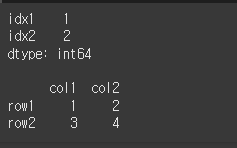
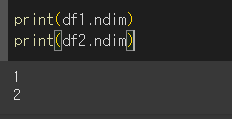
ndim 함수
사용시, Series의 경우 1을 반환하고 DataFrame의 경우 2를 반환하는것을 확인할 수 있습니다.
요소의 갯수(size)
size메서드는 데이터의 총 수의 갯수를 구합니다. 즉, Series일 경우 행의 수를 반환하고
DataFrame의 경우 행의수 x 열의수 를 반환합니다.
사용법
df.size
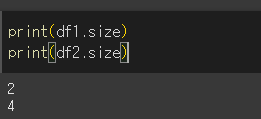
간단히 Series객체와 DataFrame객체를 만들어 보겠습니다.
df1 = pd.Series({'idx1':1,'idx2':2,'idx2':2})
print(df1)
print()
df2 = pd.DataFrame(data=[[1,2],[3,4]],index=['row1','row2'],columns=['col1','col2'])
print(df2)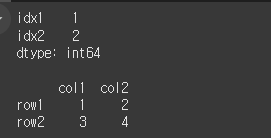
size 함수
사용시, 요소의 수를 반환 한 것을 확인 할 수 있습니다.
차원의 형태 (shape)
shape 메서드는 DataFrame 객체의 차원의 형태를(레이블 정보)를 튜플의 형식으로 반환합니다.
즉, 3행 2열의 객체의 경우 (3,2)를 반환합니다.
사용법
df.shape
간단히 1x4 객체와, 3x3 객체를 만들어서 확인해보겠습니다.
data1= [[1,2,3],[4,5,6],[7,8,9]]
df1 = pd.DataFrame(data = data1, index = ['row1', 'row2', 'row3'], columns=['col1','col2','col3'])
print(df1)
print()
data2 = [[1,2,3,4]]
df2 = pd.DataFrame(data =data2, index = ['row1'], columns=['col1','col2','col3','col4'])
print(df2)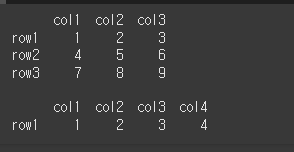
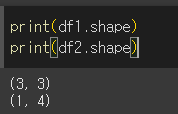
shape 함수
사용 시, 아래와 같이 3행3열, 1행4열의 정보가 튜플 형태로 반환된 것을 확인할 수 있습니다.
정보축 (keys)
keys 메서드는 'info axis(정보축)' 값을 가져옵니다.
여기서 정보축이란 Series에서는 index, DataFrame에서는 열을 말합니다.
사용법
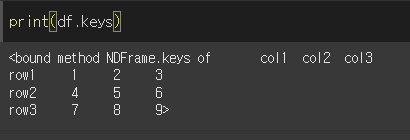
df.keys( )
먼저 3x3 의 기본적인 DataFrame객체를 하나 만들어보겠습니다.
data = [[1,2,3],[4,5,6],[7,8,9]]
col = ['col1','col2','col3']
row = ['row1','row2','row3']
df = pd.DataFrame(data=data,index=row,columns=col)
print(df)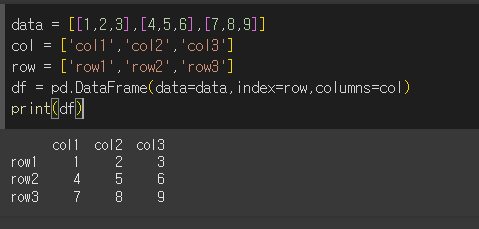
DataFrame
객체이기 때문에 key 메서드를 사용할 경우 열의 값을 가져옵니다.
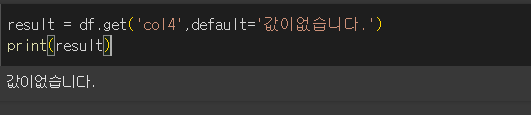
키값(열의 요소) 반환 (get)
get 메서드는 pandas객체에서 key값(예: DataFrame에서 열)을 검색해서 요소를 가져옵니다.
찾는게 없을경우 default 값을 반환합니다.
사용법
df.get(key, default=None)
먼저 3x3 의 기본적인 DataFrame객체를 하나 만들어보겠습니다.
data = [[1,2,3],[4,5,6],[7,8,9]]
col = ['col1','col2','col3']
row = ['row1','row2','row3']
df = pd.DataFrame(data=data,index=row,columns=col)
print(df)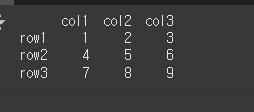
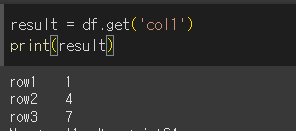
반환
key='col1'로 해서 col1의 요소를 반환해보겠습니다.
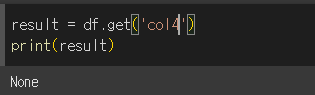
key='col4'로 해서 존재하지 않는 col4를 반환하면 default 값인 None을 반환하게 됩니다.
default값을 설정해줌으로써 원하는 반환을 설정할 수 있습니다.
비교 (compare)
compare 메서드는 두 객체의 요소의 차이를 반환합니다.
사용법
self.compare(other, align_axis=1, keep_shape=False, keep_equal=False)
other: 원본과 비교할 데이터입니다. align_axis : {0 : index / 1 : columns} self와 other를 정렬할 축입니다.
keep_shape: 원본의 모양을 유지할지 여부입니다. False인 경우 차이가 있는 행만 출력합니다.
keep_equal: 값이 같은경우 값을 출력할지 여부입니다. 기본값은 False로 NaN을 출력합니다.
먼저 일부 값이 다른 4x3짜리 데이터프레임 두개를 생성하겠습니다.
idx = ['row1','row2','row3','row4']
col = ['col1','col2','col3']
data1 = [['A',1,11],['B',2,12],['C',3,13],['D',4,14]]
data2 = [['X',1,11],['B','Y',12],['C',3,13],['D',4,'Z']]
df1 = pd.DataFrame(data1, idx, col)
print(df1)
print()
df2 = pd.DataFrame(data2, idx, col)
print(df2)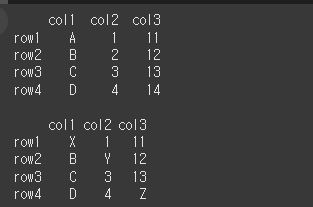
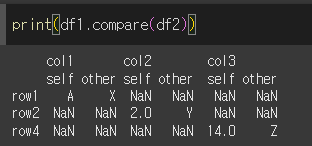
기본적인 사용법
compare메서드를 이용해서 단순히 df1과 df2를 비교할 경우 아래와 같이 self와 other이 multi columns로 추가되며 차이가 있는 행만 출력하고, 동일한 값은 NaN을 출력하게 됩니다.
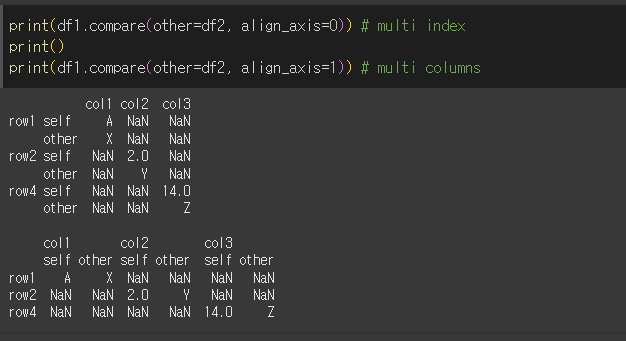
align_axis인수의 사용
align_axis인수를 사용하여 self와 other 카테고리가 multi index로 반환될지 multi columns로 반환될지 지정할 수 있습니다.
align_axis=0일 경우 multi index로 출력됩니다.
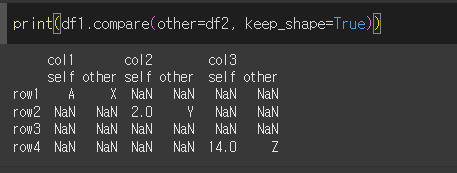
keep_shape인수의 사용
keep_shape=True로 사용할 경우 기존 열을 모두 출력하게되고, keep_shape=False일 경우(기본값) 차이가 있는 열만 출력하게 됩니다.
False면 row3이 제거되어 출력됨
keep_equal인수의 사용
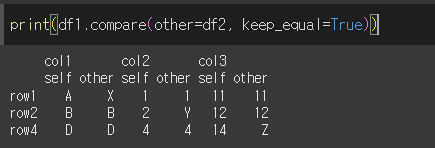
keep_equal인수를 사용할 경우 같은값을 출력할지 아니면 NaN으로 출력할지 지정할 수 있습니다.
keep_eaual=True인 경우 같은값도 출력합니다.
False면 Nan으로 출력됨
고유한 행의 수 (value_counts)
value_counts메서드는 고유한 행의 갯수를 반환합니다.
고유한 행이란 구성요소의 값이 완전히 동일한 경우를 말합니다.
사용법
df.value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)
subset: 기준으로 삼을 열 입니다. list형태로도 입력이 가능합니다.
normalize: 갯수가 아니라 비율로 출력합니다.
sort: 빈도 순서로 정렬할지 여부입니다. 기본값은 True입니다.
ascending: 오름차순으로 정렬할지 여부입니다.
dropna: 결측치를 제외할지 여부입니다. 기본값은 True로 결측값은 제외됩니다.
먼저 5x3짜리 데이터 객체를 하나 만들어보겠습니다.
n=np.nan
idx = ['row1','row2','row3','row4','row5']
col = ['col1','col2','col3']
data = [['A','Z',3,],['D','Y',n],['B','Z',3],['C','Y',8],['A','Z',3]]
df = pd.DataFrame(data, idx, col)
print(df)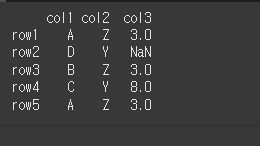
기본적인 사용법(+subset)
요소로 아무값도 입력하지 않는 경우 행의 모든 값을 대상으로 완전히 같은 행의 갯수를 우측에 출력하게됩니다.

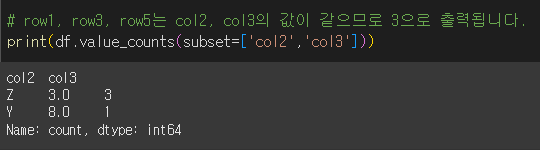
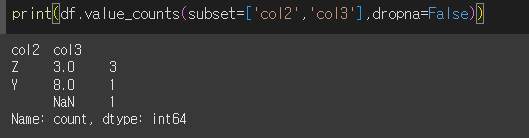
subset에 값을 입력해 줄경우 입력된 열의 값에 대해서만 동일성 검증을 진행하게 됩니다.
col2, col3에 대해서만 실행해보겠습니다.
normalize인수의 사용
normalize인수를 사용할 경우 동일한 행의 갯수가 아닌 전체에서 차지하는 비율로 출력됩니다.
normalize=False인 경우(기본값)
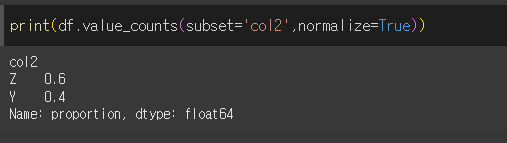
normalize가 true 인 경우
sort와 ascending인수의 사용
sort인수를 사용할 경우 최빈값부터 정렬하게되고, ascending을 사용할 경우 오름차순으로 정렬하게 됩니다.
먼저 비교를 위해 sort=False이고 ascending=False으로 출력해보겠습니다.
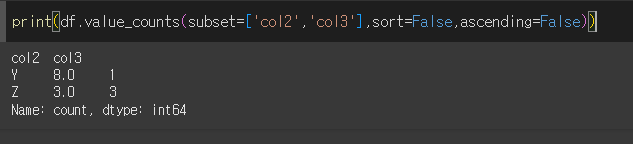
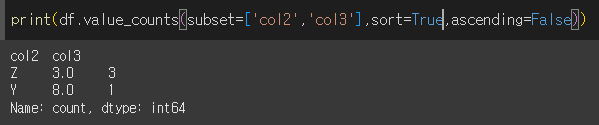
sort=True인 경우(기본값) 제일 고유값의 갯수가 많은 행부터 정렬됩니다.
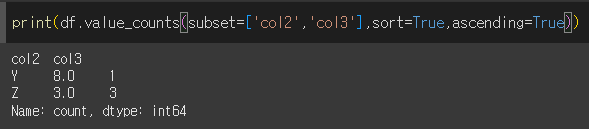
ascending=True인 경우 오름차순으로 정렬됩니다.
dropna의 사용(결측치 포함 여부)
dropna=True인 경우(기본값) 결측치가 포함된 행은 계산하지 않습니다. False인 경우 포함하게됩니다.
고유한 요소의 수 (nunique)
nunique메서드는 선택된 축에 대해서 고유한 요소의 수를 구하는 메서드입니다.
사용법
df.nunique(axis=0, dropna=True)
axis: 기준이 되는 축 입니다.
dropna: 결측치를 무시할지 여부 입니다. False일경우 하나의 요소로 간주합니다.
먼저 3x3짜리 데이터 객체를 하나 만들어보겠습니다.
idx = ['row1','row2','row3']
col = ['col1','col2','col3']
data = [[1,1,n],[1,2,6],[1,3,n]]
df = pd.DataFrame(data, idx, col)
print(df)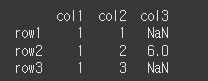
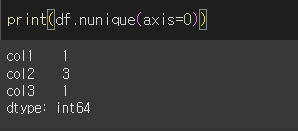
기본적인 사용법
기본값인 axis=0으로 실행할 경우 각 축에 대해서 고유값의 갯수를 출력합니다.
즉, 각 열에 대해서 값의 종류의 수를 반환합니다.
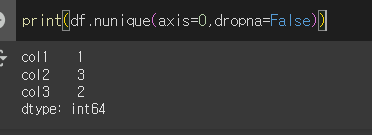
만약 dropna=False로 할 경우 NaN도 하나의 요소로 간주합니다.
axis=1로 하면 행 기준으로 메서드가 실행됩니다.
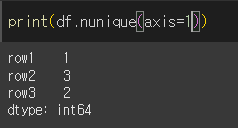
dtype변경 (astype)
astype 메서드는 열의 요소의 dtype을 변경하는함수 입니다.
사용법
df.astype(dtype, copy=True, errors='raies')
dtype: 변경할 type입니다.
copy: 사본을 생성할지 여부입니다.
errors: {'raies', 'ignore'} : 변경불가시 오류를 발생시킬 여부입니다.
먼저, 아래와 같이 기본적인 4x4 행렬을 만듭니다. col1은 int64, col2는 object, col3은 float64, col4는 bool의 dtype을 가집니다.
col1 = [1, 2, 3, 4]
col2 = ['one', 'two', 'three', 'four']
col3 = [1.5, 2.5, 3.5, 4.5]
col4 = [True, False, False, True]
index = ['row1','row2','row3','row4']
df = pd.DataFrame(index=index, data={"col1": col1, "col2": col2, "col3": col3, "col4": col4})
print(df)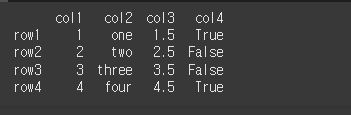
한개의 열만 type 변경
열의 dtype 변경 시 딕셔너리 형태로 {'열이름' : '변경 dtype'}와 같이 입력해줍니다.
int64 였던 col1의 dtype이 int32로 변경된 것을 확인할 수 있습니다.
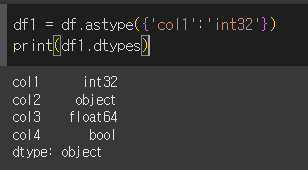
다수의 열의 dtype 변경
다수의 열의 변경도 딕셔너리 형식을 이용하면 됩니다.
int64 였던 col1의 dtype이 int32로 변경되고 float64였던 col3의 dtype의 값이 int64로 변경된 것을 확인할 수 있습니다.
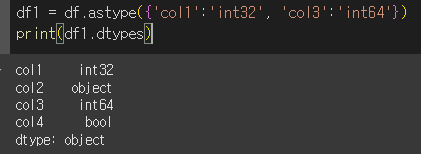
모든 열의 dtype 변경
모든열의 변경을 하고자하는 경우 dtype 인수에 원하는 dtype을 입력해주는 것만으로도 가능합니다.
col2 : object형식은 int64형태로 변경할 수가 없기 때문에 오류가 발생합니다. 변경 가능한 열만 변경하려면, 아래와 같이 errors 인수를 기본값인 'raise' 에서 'ignore'로 변경하면 됩니다.
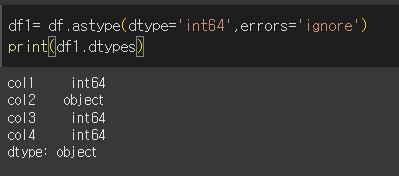
열의 dtype통일 (convert_dtypes)
convert_dtypes 메서드는 열의 요소가 혼합된 dtype일 경우, 열의 요소를 같은 dtype으로 통일할 수 있는 가장 합리적인 형식을 갖는 pd.NA로 변환합니다.
사용법
df.convert_dtypes(infer_objects=True, convert_string=True, convert_integer=True, convert_boolean=True, convert_floating=True)
infer_object: dtype이 object인 경우 적절한 type으로 변경 할지의 여부입니다. 기본적으로 True이며, 이 경우 열의 요소를 확인해서 가장 적절한 dtype을 가진 pd.NA를 반환합니다.
convert_string, convert_integer, convert_boolean, convert_floating : 해당 유형으로의 pd.NA를 설정할지의 여부입니다.
기본적으로 True이기 때문에, 가능한 모든 dtype에 대해서 적절한 값을 반환합니다.
먼저, 아래와 같이 NaN이 포함된 3x4 행렬을 만듭니다.
col1은 string, col2는 bool, col3, col4는 dtype을 가지지만, NaN 을 포함하기 때문에
col1과 col2는 object 형식을 갖는것을 볼 수 있습니다.
col1 = ['a','b',np.nan]
col2 = [True, np.nan, False]
col3 = [np.nan, 2, 4]
col4 = [1.4, np.nan, 2.5]
df = pd.DataFrame(data={'col1':col1,'col2':col2,'col3':col3,'col4':col4},index=['row1','row1','row3'])
print(df)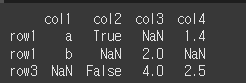
이제 df.convert_dtype를 실행해서 가장 적절한 dtype으로 만들 수 있는
np.NA를 추가해보겠습니다.
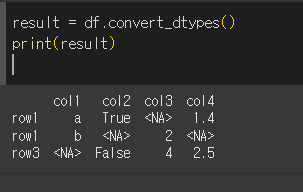
위와 같이 기존 NaN들이 NA 형태로 변경된 것을 확인 할 수 있습니다.
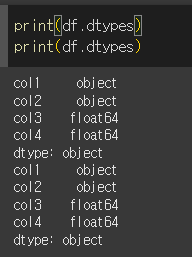
그럼 이어서 dtype또한 변경되었는지 확인해보겠습니다.
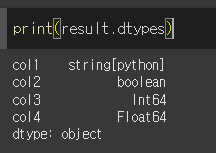
각 열의 dtype또한 기돈 object type에서 string, boolean, int64, float64로
각각에 맞게 변경된 것을 확인할 수 있습니다.
object 열의 적절 dtype추론(infer_objects)
infer_object메서드는 dtype이 object인 열에 대해서 적당한 dtype을 추론합니다.
사용법
df.infer_object( )
먼저 str과 int가 혼합된 col1을 가진 DataFrame 객체를 만들어 dtype이 object인 열을 만들어 보겠습니다.
col1 = ['a','b', 3, 4]
df = pd.DataFrame({'col1':col1},index=['row1','row2','row3','row4'])
print(df)
print(df.dtypes)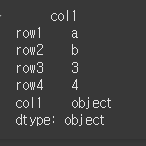
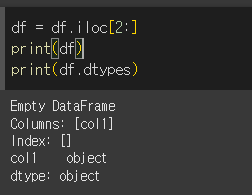
이제 df에서 형식이 int인 행만 남겨서 인덱싱을 한 뒤. dtype을 살펴보면, 여전히 dtype이 object인 것을 확인 할 수 있습니다.
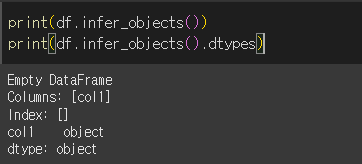
이런 경우에 대해 infer_object는 가장 적당한 dtype을 제안하는 기능을 합니다.
최대/최소값이 포함된 행/열 (idxmax / idxmin)
idxmax와 idxmin은 각각 축에서 최대/최소값의 인덱스를 반환하는 메서드입니다.
사용법
df.idxmax(axis=0, skipna=True)
df.idxmin(axis=0, skipna=True)
axis: {0 : index / 1:columns} 기준이 될 축입니다.
skipna: 결측치의 무시 여부입니다. True면 결측치가 포함된 열은 무시하고 False면 NaN를 출력합니다.
먼저 3x3짜리 객체를 만들어보겠습니다..
n=np.nan
idx = ['row1','row2','row3']
col = ['col1','col2','col3']
data = [[1,2,200],[100,5,6],[7,300,n]]
df = pd.DataFrame(data, idx, col)
print(df)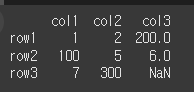
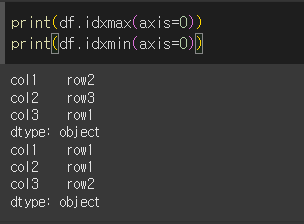
기본적인 사용법
axis=0인경우(기본값) 열에서 최대/최소 값에 해당되는 행을 출력합니다.
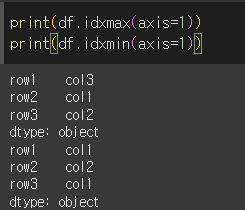
axis=1인경우 행에서 최대/최소 값에 해당되는 열을 출력합니다.
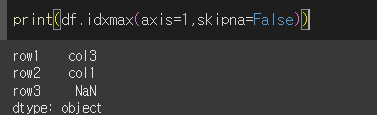
skipna인수의 사용
skipna인수는 기본값이 True로 결측값이 포함된 행/열을 연산에서 무시합니다. False일 경우 NaN를 출력하게됩니다.
비어있는지 확인 (empty)
empty메서드는 DataFrame이 비어있는지 여부를 bool 형식으로 반환합니다.
여기서 비어있다는것은 정말 완전히 비어있는 상태를 말하는 것으로,
공백 문자열("")이나 Nan의 경우조차 허용하지 않는것을 말합니다.
즉, 축이 존재하지 않는 경우를 말합니다.
사용법
df.empty
공백으로 이루어진 객체, Nan으로 이루어진 객체, 행이 없는 객체, 열이 없는객체로 확인해보겠습니다.
공백으로 이루어진 객체
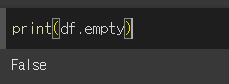
공백으로 이루어져있지만 df.empty 가 False로 출력됩니다.
""으로 차있기 때문입니다.

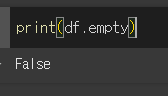
NaN으로 이루어진 객체
NaN으로 이루어진 객체 또한, 어쨌던 Nan으로 채워져 있기 때문에 df.empty값을 False로 반환합니다.
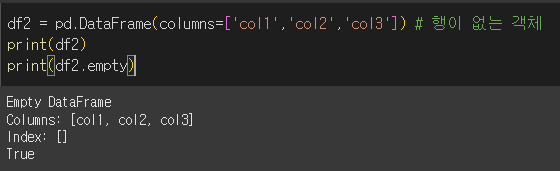
행이나 열이 없는 객체
열이없는 경우
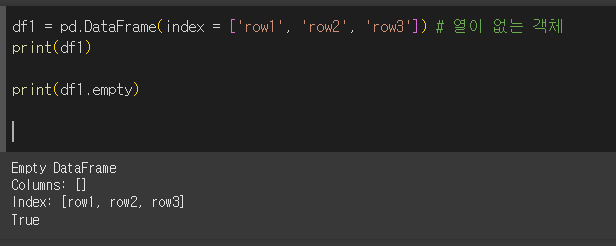
행이 없는 경우
일치하는 요소 확인 (isin)
isin메서드는 DataFrame객체의 각 요소가 values값과 일치하는지 여부를 bool형식으로 반환합니다.
사용법
df.isin(values)
value: Iterable, Series, DataFrame, dict등이 올 수 있습니다.
Series일 경우 : Index가 일치해야 합니다.
DataFrame일 경우 : Index와 열 레이블이 일치해야 합니다.
Dict일 경우 : key는 열 레이블 입니다.
먼저 3x3 의 기본적인 DataFrame객체를 하나 만들어보겠습니다.
data = [[1,1,1],[2,3,4],[5,3,6]]
col = ['col1','col2','col3']
row = ['row1','row2','row3']
df = pd.DataFrame(data=data,index=row,columns=col)
print(df)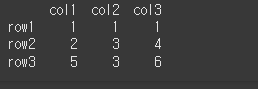
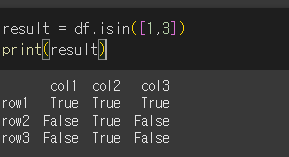
list의 사용
리스트를 이용하여 1과 3이 포함된 요소를 확인해보겠습니다.
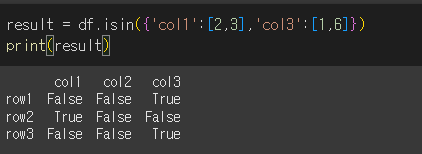
dict의 사용
dict를 사용해서 col1에서는 2,3인 경우, col3에서는 1,6이 포함된 요소를 확인해보겠습니다.
Series 와 DataFrame의 사용
DataFrame객체를 사용하기위해 match_df라는 DataFrame객체를 하나 만들어보겠습니다.
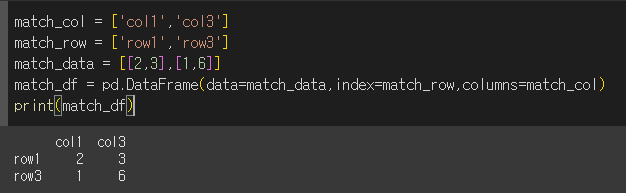
이제 이 match_df를 value로 isin 메서드를 사용해보겠습니다.
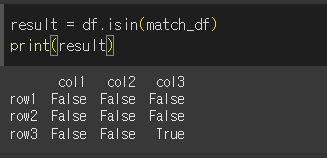
요소의 True/False 확인 (all / any)
all/any는 축의 값들의 True/False여부를 판단하는 메서드입니다.
all은 축의 값이 전부 True이면 True반환, 하나라도 False가 있으면 False를 반환합니다.
any는 축의 값이 하나라도 True가 있으면 True반환, 전부 False이면 False를 반환합니다.
사용법
df.all(axis=0, bool_only=None, skipna=True, level=None, kwargs)
df.any(axis=0, bool_only=None, skipna=True, level=None, kwargs)
axis: {0 : index / 1:columns} 기준이 될 축입니다.
bool_only: True면 축의 모든 값이 bool인 경우에만 계산을 수행합니다. None면 모든 경우를 고려합니다.
예를들어 0과 공백()은 False로 고려되고 결측값(pd.NA)은 True로 고려되는 등 입니다.
skipna: 결측치의 무시 여부입니다. True면 결측치가 포함된 열은 무시됩니다.
level: Multi Index에서 레벨의 선택입니다.
kwargs: 추가 키워드는 효과가 없지만 NumPy와의 호환성을 위해 허용될 수 있습니다.
먼저 4x6짜리 객체를 만들어보겠습니다.
[N,T,F]=[pd.NA,True,False]
idx = ['row1','row2','row3','row4']
data = {'col1':[T,T,T,T], 'col2':[F,F,F,F],'col3':[F,T,T,T],'col4':[T,N,T,T],'col5':[T,T,'',T],'col6':[T,T,T,0]}
df = pd.DataFrame(data=data, index=idx)
print(df)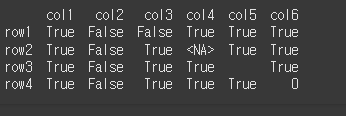
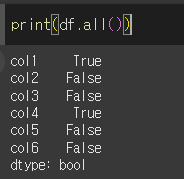
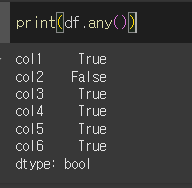
기본적인 사용법(all과 any 비교)
all은 축의 값이 전부 True면 True를 반환하고 any는 하나라도 True면 True를 반환합니다.
0과 공백()은 False로, 결측값(pd.NA)은 True로 분류됩니다.
any의 경우 하나라도True면 True를 반환
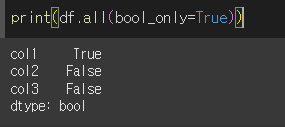
bool_only인수의 사용
bool_only=True일 경우 모든 요소가 bool형식인 경우만 계산됩니다.
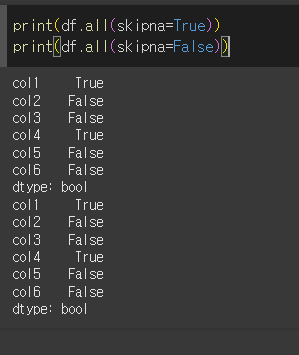
skipna인수의 사용
skipna=True인 경우 결측치는 True로서 계산되며, skipna=False인 경우 결측치가 포함된 축이 계산에서 제외됩니다.
결측값이 아닌 요소의 수 (count)
count메서드는 각 행/열에 결측치가 아닌 요소의 갯수를 구합니다.
사용법
df.count(axis=0, level=None, numeric_only=False)
axis: 적용할 축입니다.
level: Multi Index의 경우 레벨을 설정할 수 있습니다.
numeric_only: True일 경우 int, float, bool 형태인 경우만 출력합니다.
먼저 4x4짜리 객체를 만들어보겠습니다..
[N,T,F]=[pd.NA,True,False]
idx = ['row1','row2','row3','row4']
data = {'col1':[1,N,N,4.0],'col2':['A','B','C',N],'col3':[N,N,N,7],'col4':[1,2.4,3.6,4]}
df = pd.DataFrame(data,idx)
print(df)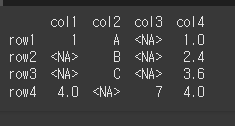
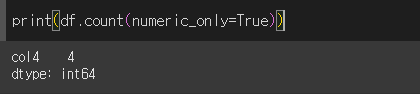
기본적인 사용법
axis에 대해서 기본값은 0으로 열에 대해서 결측치가 아닌 값의 갯수를 구합니다.
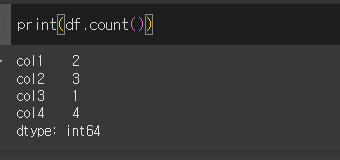
axis=1인 경우 행에 대해서 결측치가 아닌 값의 갯수를 구합니다.
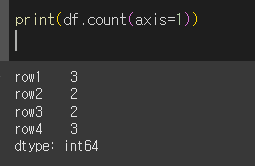
numeric_only인수의 사용
numeric_only=True인 경우 int, float, bool로 구성된 행/열에 대해서만 계산값을 반환합니다.
일치 여부 (equals)
equals메서드는 두 객체가 완벽하게 동일한지를 확인하는 메서드입니다.
사용법
df.equals(other)
other: df와 일치하는지 비교할 객체입니다.
먼저 2x2짜리 객체를3개 만들어보겠습니다.
df1과 df2는 완벽하게 같고, df3는 3의 값이 3.0으로 type이 다릅니다.
df1 = pd.DataFrame(data=[[1,N],[3,T]])
df2 = pd.DataFrame(data=[[1,N],[3,T]])
print(df1)
df3 = pd.DataFrame(data=[[1,N],[3.0,T]])
print(df3)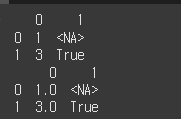
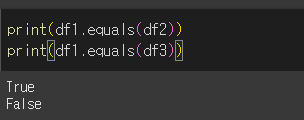
기본적인 사용법
두 객체가 완벽히 같을경우 True를 반환하며 다를경우 False를 반환합니다. 요소의 type이 다르더라도 False를 반환합니다.
1칸 객체의 bool 확인 (bool)
bool 메서드는 1칸짜리 Series나 DataFrame에 대해서 bool 값의 True or False여부를 확인합니다.
값이 bool이 아니거나 1칸이 아니라면 Value Error를 발생시킵니다
사용법
df.bool( )
먼저 1x1짜리 이며 값이 bool인 DataFrame객체를 2개 만들어보겠습니다.
df1은 True, df2는 False입니다.
df1 = pd.DataFrame([True],['row'],['col'])
print(df1)
df2 = pd.DataFrame([False],['row'],['col'])
print(df2)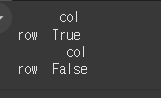
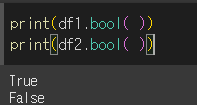
기본적인 사용법
1칸짜리 객체의 bool값을 그대로 반환하게 됩니다.
중복행 확인 (duplicated)
duplicated 메서드는 중복되는 행을 확인하는 메서드입니다.
행의 모든 요소가 동일한 행이 이미 존재할경우 해당 행은 True로 반환됩니다.
사용법
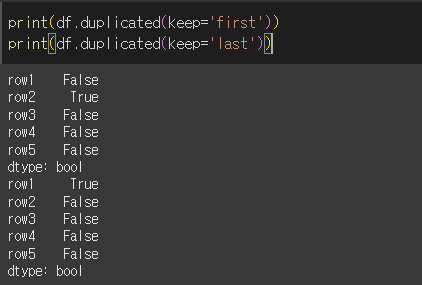
df.duplicated(subset=None, keep='first')
subset: 특정 열만을 대상으로 할 수 있습니다. list의 사용도 가능합니다.
keep: {first : 위부터 검사 / last : 아래부터 검사} 검사 순서를 정합니다. first일 경우 위부터 확인해서 중복행이 나오면 True를 반환하며, last일 경우 아래부터 확인합니다.
먼저 5x3짜리 객체를 만들어보겠습니다.
idx = ['row1','row2','row3','row4','row5']
col = ['col1','col2','col3']
data= [['A','가',1],['A','가',1],['A','나',2],['B','나',3],['B','다',4]]
df = pd.DataFrame(data, idx, col)
print(df)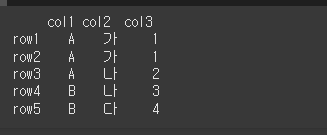
기본적인 사용법
기본적으로 keep='first'이며 위에서부터 행을 확인하여 중복인 행이 나오면 True를 반환합니다.
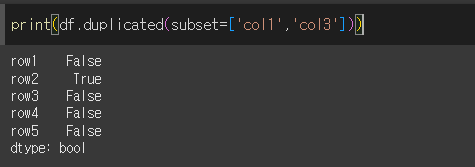
subset으로 특정 열만 확인
subset을 이용하여 특정 열을 대상으로만 중복행의 확인이 가능합니다.