
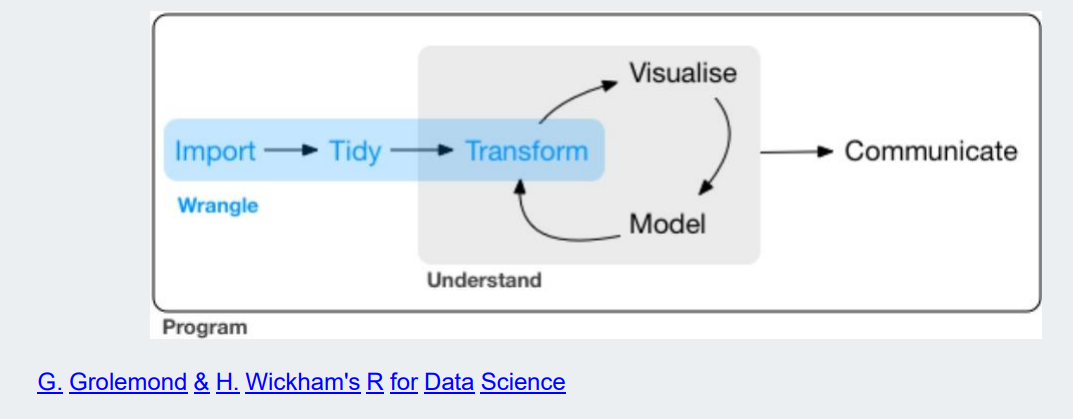
what is data wrangling?
*data wrangling: "data janitor work"(데이터 정리,정돈하는 작업)
->cf.) r package는 'dplyr' 패키지를 사용한다.1.importing data
2.cleaning data
3.changing shape of data
4.fixing errors and poorly formatted data elements
5.transforming columns and rows
6.filtering,subsetting
cf.) 파일 경로는 절대 경로(전체 경로)가 아닌 상대 경로(현재 위치 기준의 경로)로 사용할 것!

cf.) r studio 단축키 설명

Tibbles
Data frames vs tibbles(chapter 3장에도 이 내용이 나오니 참고 바람)
*data frame: 2차원 행렬 형태(테이블 형태)의 데이터 구조
*tibble: a tibble is a data frame but with perks.(티블은 데이터프레임이지만, 특별한 기능을 갖춘 데이터 프레임이다.)
->출력을 더욱 깔끔하게 보여주는 기능 or 행 이름을 자동으로 정리하는 등의 'perks'를 가진다.
->추후에 나오는 'tidyverse'의 데이터 분석 작업에서 편리하게 사용된다.

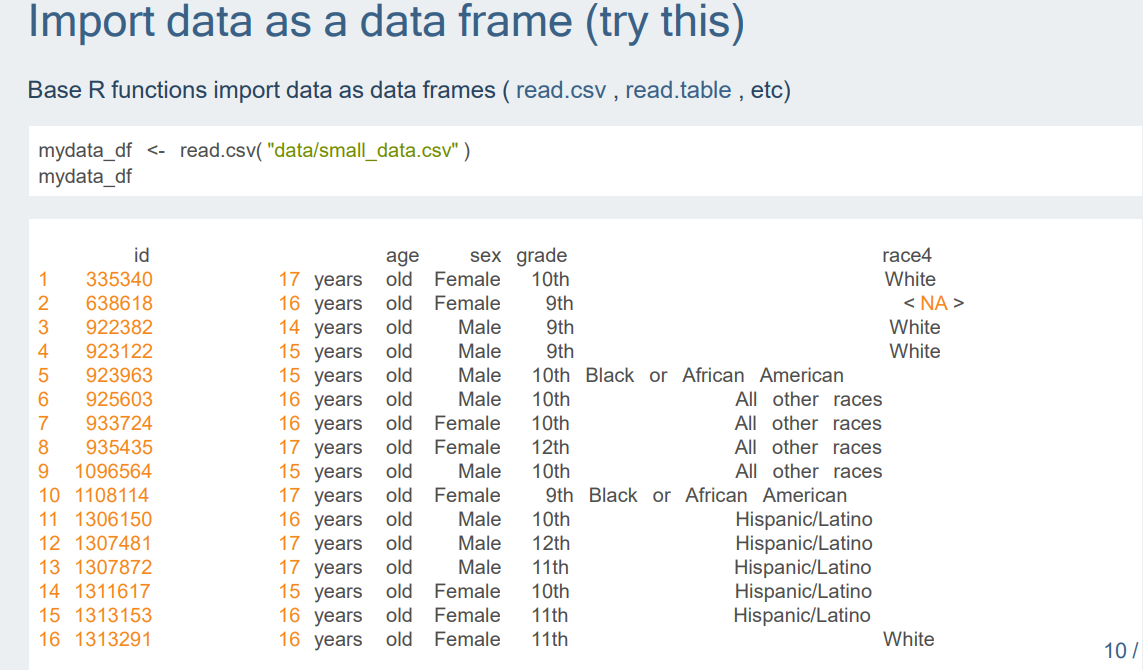
*data frame 함수: read.csv(),read.table(),etc...
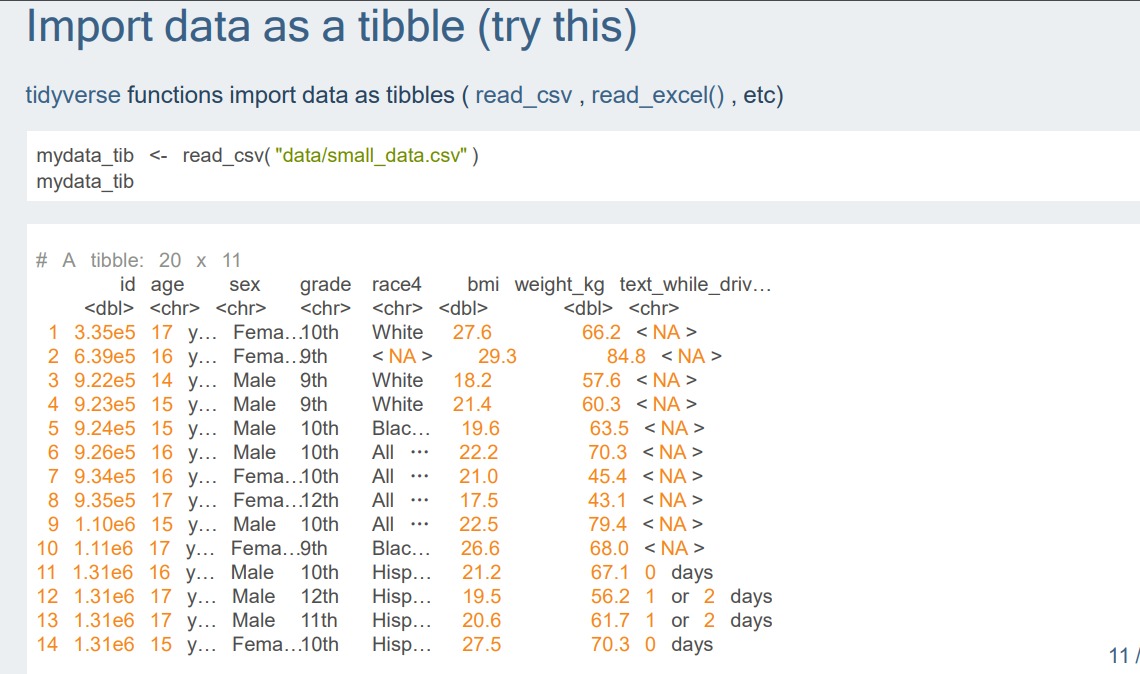
*tibble 함수: read_csv(),read_excel(),etc...
*직접 r 코드를 실행해보았다.
*다음은 코드 결과들이다.
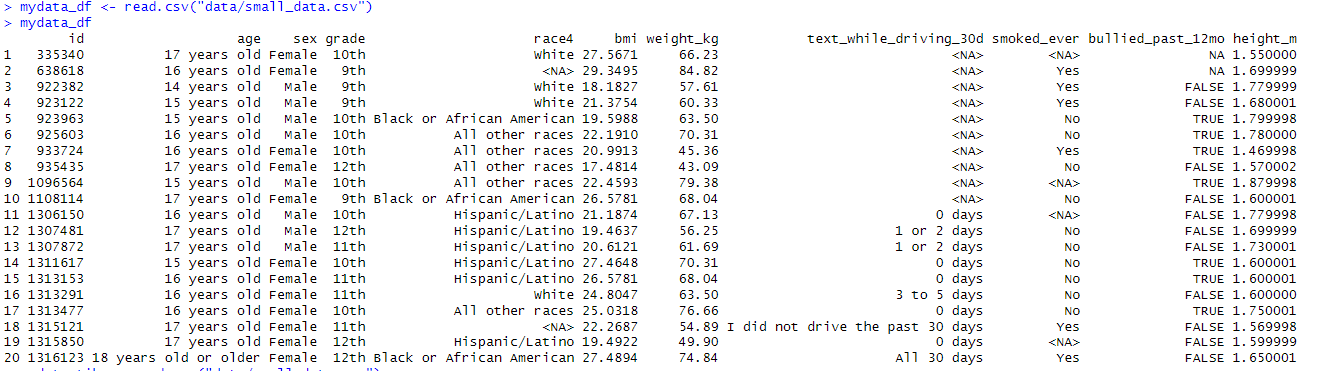
*data frame의 glimpse,str,head,summary,class 부분.
->단어 뜻 그대로 '흘끗보는 것'이다. 즉, 데이터 구조를 간략하게 살펴보는 함수이다. 결과를 보면 알다시피, 변수와 해당 변수 타입 및 값을 알 수 있다.
-> 이 역시 structure를 의미하는 str로서, 데이터 구조를 보여주는 함수이다. glimpse와는 큰 차이가 없음을 볼 수 있다.
->head는 원래 상위 5개 출력인데, 여기서는 6개 출력을 함.
-> 말 그대로 요약하는 것이다. 최소값,1사분위값,중앙값,평균,3사분위값,최대값 등등을 보여준다.
-> 해당 클래스가 뭔지를 출력한다.
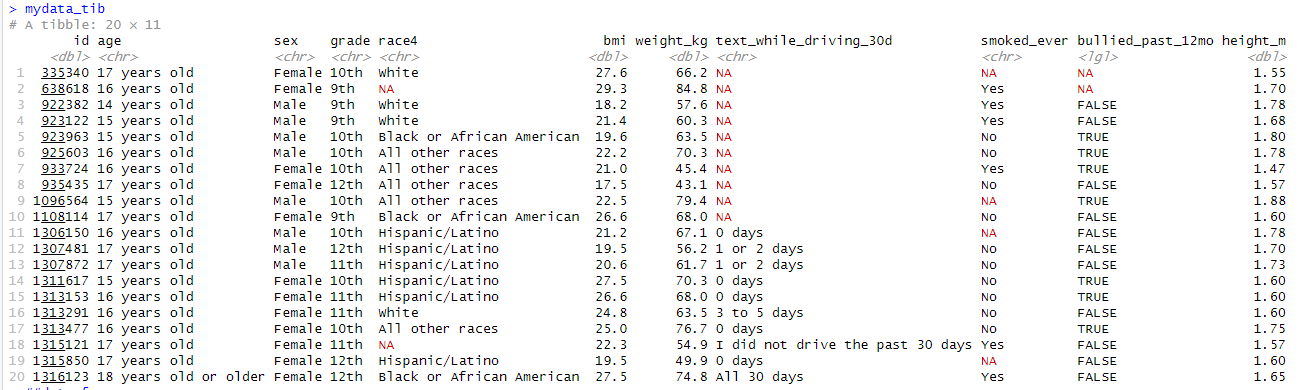
*tibble의 glimpse,str,head,summary,class 부분.
데이터프레임과 티블은 큰 차이는 없는데, 차이라고 한다면, 1. tibble의 str 부분에서 행렬을 20x11로 표현해서 각 변수의 요소개수를 리스트 형식[1:20]으로 나타낸 점과 2. head 부분에서 tibble은 변수 밑에 타입이 나온다는 점, 3.클래스의 차이 정도이다.
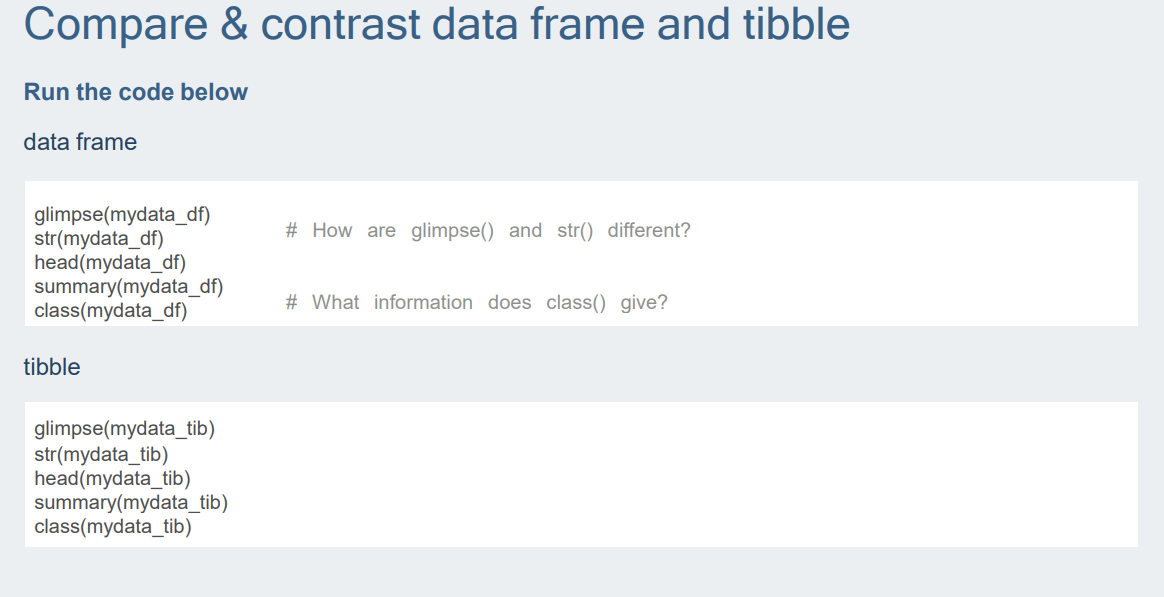

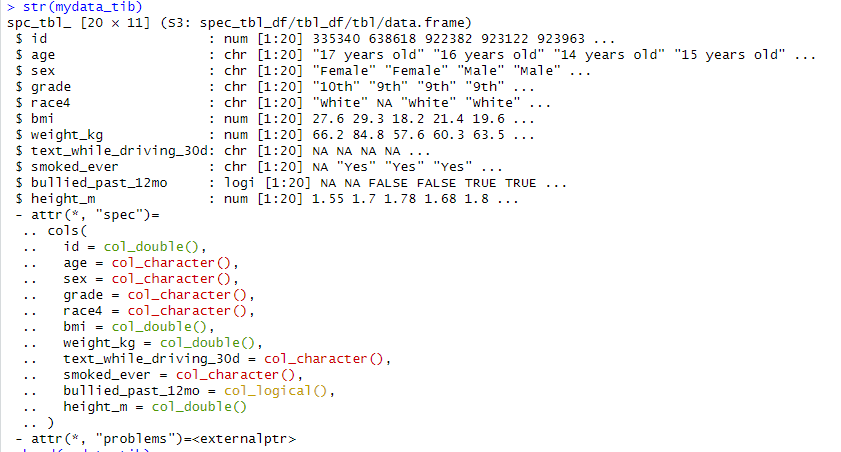


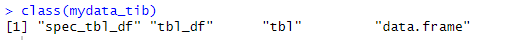
*Viewing tibbles:
1.다양한 변수타입 제공
2.데이터를 더 쉽게 보기 위해 제한된 수의 행열만 표시한다.(행과 열이 너무 많으면 한눈에 보기 어려우니 이렇게 함.)*Other perks:
1.티블은 데이터 프레임이 필요한 어느 곳에서 사용 가능하다.
2.read*()(read_ 다음에 오는 모든 function들)는 문자로 표현된 열들을 factor로 읽지 않는다.
-> factor는 범주형 데이터를 나타내는데 사용된다.(범주형 데이터는 정수로 표현하지만, 이는 숫자형 데이터가 아니다. ex) as.factor() 함수를 이용해서 범주형으로 변환하면, 남성 -> 1, 여성 -> 2로 범주형 정수로 변환한다.)
->이 문장의 의미는 문자열 열을 자동으로 factor로 변환하지 않는다는 소리이다. factor로 변환하려면, as.factor() 함수를 이용해서 수동으로 변환해야 한다는 소리이다.


글 잘 봤습니다.